Teste comparativo de caches multithread implementados em C / C ++ e uma descrição de como o cache LRU / MRU da série O (n) Cache ** RU é organizado
Ao longo das décadas, muitos algoritmos de cache foram desenvolvidos: LRU, MRU, ARC e outros .... No entanto, quando um cache era necessário para o trabalho multithread, o google sobre esse tópico oferecia uma opção e meia, e a pergunta no StackOverflow geralmente permanecia sem resposta. Encontrei uma solução do Facebook que depende de contêineres seguros para threads do repositório Intel TBB . O último também possui um cache LRU multiencadeado ainda em teste beta e, portanto, para usá-lo, você deve especificar explicitamente no projeto:
#define TBB_PREVIEW_CONCURRENT_LRU_CACHE true
Caso contrário, o compilador mostrará um erro, pois há uma verificação no código Intel TBB:
#if ! TBB_PREVIEW_CONCURRENT_LRU_CACHE #error Set TBB_PREVIEW_CONCURRENT_LRU_CACHE to include concurrent_lru_cache.h #endif
Eu queria comparar de alguma forma o desempenho dos caches - qual escolher? Ou escreva o seu? Antes, quando comparava caches de thread único ( link ), recebi ofertas para tentar outras condições com outras chaves e percebi que era necessária uma bancada de teste extensível mais conveniente. Para tornar mais conveniente adicionar algoritmos concorrentes aos testes, decidi envolvê-los na interface padrão:
class IAlgorithmTester { public: IAlgorithmTester() = default; virtual ~IAlgorithmTester() { } virtual void onStart(std::shared_ptr<IConfig> &cfg) = 0; virtual void onStop() = 0; virtual void insert(void *elem) = 0; virtual bool exist(void *elem) = 0; virtual const char * get_algorithm_name() = 0; private: IAlgorithmTester(const IAlgorithmTester&) = delete; IAlgorithmTester& operator=(const IAlgorithmTester&) = delete; };
Da mesma forma, as interfaces são agrupadas: trabalhando com o sistema operacional, obtendo configurações, casos de teste, etc. As fontes são dispostas no repositório . Existem dois casos de teste no estande: insira / pesquise até 1.000.000 elementos com uma chave de números gerados aleatoriamente e até 100.000 elementos com uma chave de cadeia (extraída de 10Mb de linhas wiki.train.tokens). Para estimar o tempo de execução, cada cache de teste é primeiro aquecido no volume de destino sem medições de tempo e, em seguida, o semáforo libera os fluxos da cadeia para adicionar e pesquisar dados. O número de encadeamentos e configurações de caso de teste são definidos em assets / settings.json . Instruções de compilação passo a passo e uma descrição das configurações JSON são descritas no repositório WiKi . O tempo é rastreado desde o momento em que o semáforo é liberado até o último encadeamento parar. Aqui está o que aconteceu:
Caso de teste1 - uma chave na forma de uma matriz de números aleatórios uint64_t keyArray [3]:
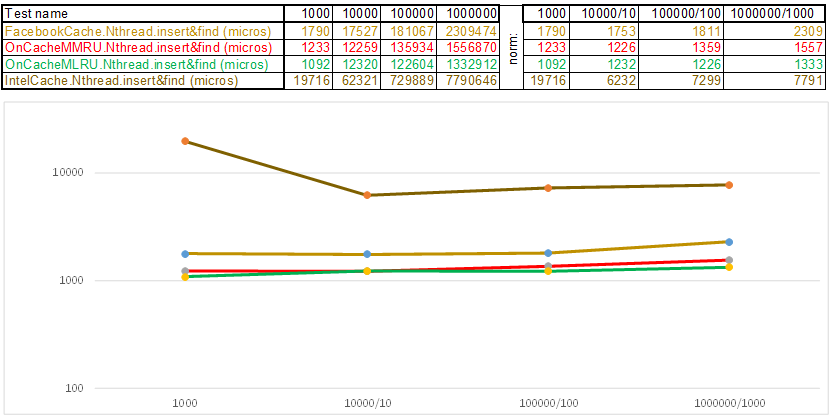
Teste case2 - chave como uma string:
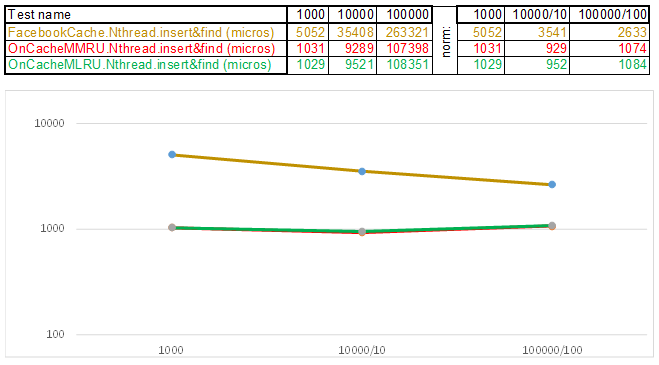
Observe que o volume de dados inseridos / pesquisados em cada etapa do caso de teste aumenta 10 vezes. Então, o tempo gasto no processamento do próximo volume, divido por 10, 100, 1000, respectivamente ... Se o algoritmo se comportar como O (n) na complexidade do tempo, a linha do tempo permanecerá aproximadamente paralela ao eixo X. A seguir, revelarei o conhecimento sagrado, conforme consegui obtenha uma superioridade de 3-5 vezes sobre o cache do Facebook nos algoritmos da série O (n) Cache ** RU ao trabalhar com uma chave de cadeia:
- A função hash, em vez de ler cada letra da string, simplesmente lança um ponteiro para os dados da string em uint64_t keyArray [3] e conta a soma dos números inteiros. Ou seja, funciona como o programa "Adivinhe a melodia" - e acho que a melodia com 3 notas ... 3 * 8 = 24 letras se for latina, e isso já permite que você espalhe as linhas razoavelmente bem em cestas de hash. Sim, muitas linhas podem ser coletadas em uma cesta de hash, e aqui o algoritmo começa a acelerar:
- A Lista de Ignorar em cada cesta permite saltar rapidamente primeiro em hashes diferentes (id da cesta = número de hash% de cestas, para que diferentes hashes possam aparecer em uma cesta) e, em seguida, no mesmo hash ao longo dos vértices:
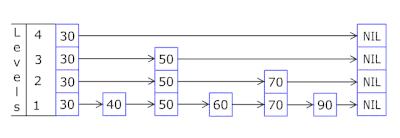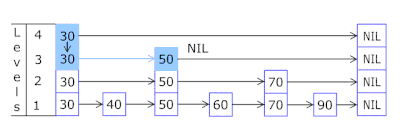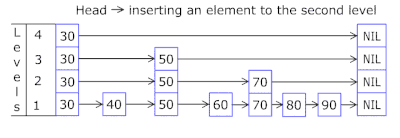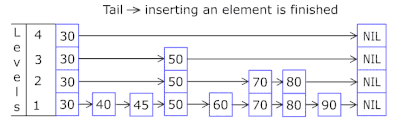
- Os nós nos quais as chaves e os dados são armazenados são obtidos da matriz de nós alocada anteriormente; o número de nós coincide com a capacidade do cache. O identificador atômico indica qual nó seguir - se chegar ao final do conjunto de nós, começará com 0 = para que o alocador entre em círculo substituindo os nós antigos ( cache LRU no OnCacheMLRU ).
No caso em que é necessário que os elementos mais populares nas consultas de pesquisa sejam armazenados no cache, a segunda classe OnCacheMMRU é criada , o algoritmo é o seguinte: além da capacidade do cache, o construtor da classe também passa o segundo parâmetro uint32_t inutilidade, o limite de popularidade é se o número de solicitações de pesquisa que desejam o nó atual do pool cíclico for menor Se os limites forem inutilidade, o nó será reutilizado para a próxima operação de inserção (será despejado). Se neste círculo a popularidade do nó (std :: atomic <uint32_t> usado {0}) for alta, no momento de solicitar o alocador do pool cíclico, o nó poderá sobreviver, mas o contador de popularidade será redefinido para 0. Portanto, haverá outro círculo na passagem do alocador em um conjunto de nós e terá a chance de recuperar a popularidade para continuar a existir. Ou seja, é uma mistura dos algoritmos MRU (onde os mais populares ficam no cache para sempre) e MQ (onde a vida útil é rastreada). O cache é atualizado constantemente e, ao mesmo tempo, funciona muito rapidamente - em vez de 10 servidores, você pode colocar 1 ..
Em geral, o algoritmo de armazenamento em cache gasta tempo com o seguinte:
- Manutenção da infraestrutura de cache (contêineres, alocadores, rastreando a vida útil e a popularidade dos elementos)
- Operações de cálculo de hash e comparação de chaves ao adicionar / pesquisar dados
- Algoritmos de pesquisa: Árvore vermelho-preta, Tabela de hash, Lista de pulos, ...
Era apenas necessário reduzir o tempo de operação de cada um desses itens, considerando que o algoritmo mais simples é temporalmente complexo e geralmente o mais eficiente, já que qualquer lógica requer ciclos de CPU. Ou seja, o que quer que você escreva, essas são operações que devem render a tempo em comparação com o método simples de enumeração: enquanto a próxima função é chamada, a enumeração terá que passar por outras centenas ou dois nós. Sob essa luz, os caches multithread sempre perdem no modo single-thread, pois a proteção de cestas através de std :: shared_mutex e nós através de std :: atomic_flag in_use não é livre. Portanto, para emitir no servidor, eu uso o cache de thread único OnCacheSMRU no thread principal do servidor Epoll (apenas operações longas no trabalho com o DBMS, disco e criptografia são realizadas em fluxos de trabalho paralelos). Para uma avaliação comparativa, é usada uma versão de thread único de casos de teste:
Caso de teste1 - uma chave na forma de uma matriz de números aleatórios uint64_t keyArray [3]:

Teste case2 - chave como uma string:
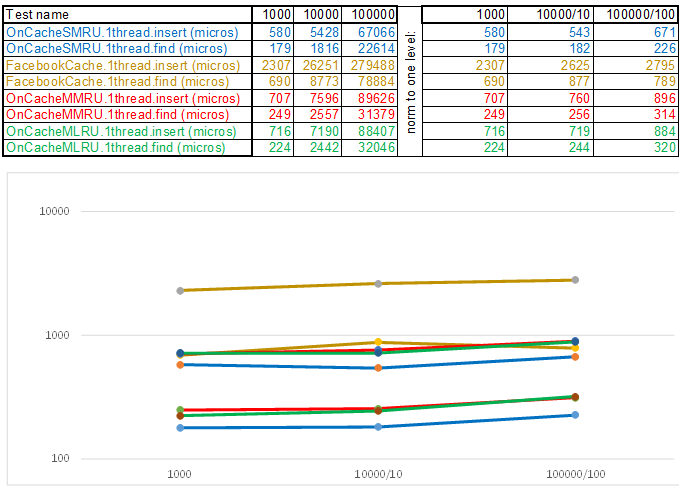
Em conclusão, quero dizer o que mais interessante pode ser extraído das fontes da bancada de testes:
- A biblioteca de análise JSON, que consiste em um único arquivo specjson.h, é um algoritmo rápido simples e pequeno para aqueles que não desejam arrastar alguns megabytes do código de outra pessoa para o projeto para analisar o arquivo de configurações ou o JSON de entrada de um formato conhecido.
- Uma abordagem para injetar a implementação de operações específicas da plataforma no formulário (classe LinuxSystem: public ISystem {...}) em vez do tradicional (#ifdef _WIN32). É mais conveniente agrupar, por exemplo, semáforos, trabalhar com bibliotecas, serviços conectados dinamicamente - nas classes há apenas código e cabeçalhos de um sistema operacional específico. Se você precisar de outro sistema operacional, injete outra implementação (classe WindowsSystem: public ISystem {...}).
- O estande vai para o CMake - é conveniente abrir o projeto CMakeLists.txt no Qt Creator ou no Microsoft Visual Studio 2017. Trabalhar com o projeto através do CmakeLists.txt permite automatizar algumas operações preparatórias - por exemplo, copiar arquivos de casos de teste e arquivos de configuração no diretório de instalação:
- Para aqueles que estão dominando os novos recursos do C ++ 17, este é um exemplo de trabalho com std :: shared_mutex, std :: alocador <std :: shared_mutex>, thread_local estático em modelos (existem nuances - onde alocar?), Iniciando um grande número de testes em threads de maneiras diferentes com a medição do tempo de execução:
- Instruções passo a passo sobre como compilar, configurar e executar este banco de testes - WiKi .
Se você ainda não possui instruções passo a passo para um sistema operacional conveniente, ficarei grato pela contribuição ao repositório pela implementação do ISystem e pelas instruções de compilação passo a passo (para o WiKi) ... Ou apenas me escreva - tentarei encontrar tempo para aumentar a máquina virtual e descrever as etapas para a montagem.