Olá Habr! Apresento a vocês um post que é uma adaptação em texto do desempenho da
Stella Cotton no RailsConf 2018 e uma tradução do artigo
“Construindo uma arquitetura orientada a serviços com Rails e Kafka” por Stella Cotton.
Recentemente, a transição de projetos da arquitetura monolítica para microsserviços é claramente visível. Neste guia, aprenderemos os conceitos básicos do Kafka e como uma abordagem orientada a eventos pode melhorar seu aplicativo Rails. Também falaremos sobre os problemas de monitoramento e escalabilidade de serviços que funcionam por meio de uma abordagem orientada a eventos.
O que é Kafka?
Tenho certeza de que você deseja obter informações sobre como seus usuários acessaram sua plataforma ou quais páginas visitam, em quais botões clicam etc. Um aplicativo verdadeiramente popular pode gerar bilhões de eventos e enviar uma enorme quantidade de dados aos serviços de análise, o que pode ser um sério desafio para o seu aplicativo.
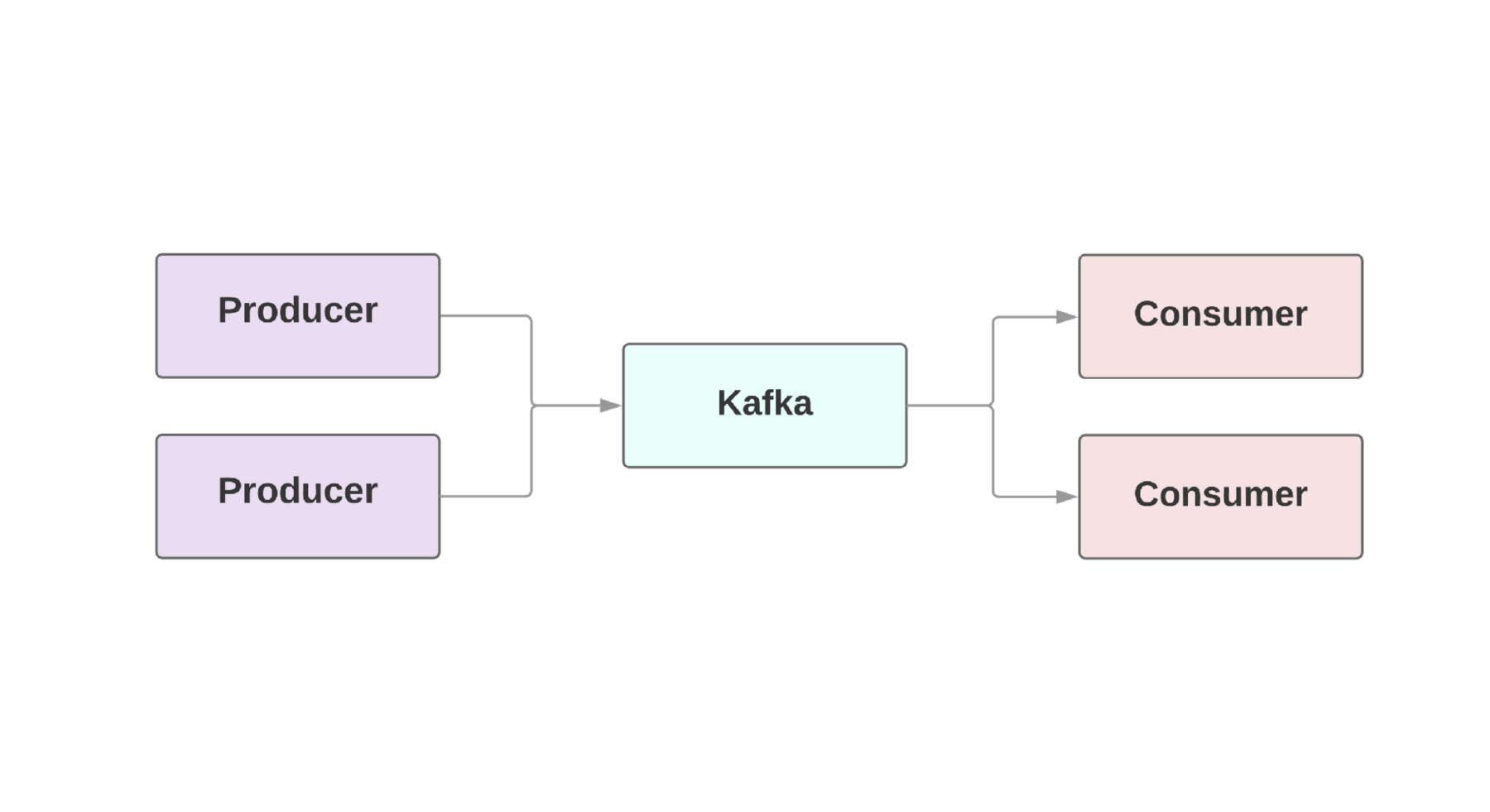
Como regra, uma parte integrante dos aplicativos da Web requer o chamado
fluxo de dados em tempo real . Kafka fornece uma conexão tolerante a falhas entre
produtores , aqueles que geram eventos e
consumidores , aqueles que recebem esses eventos. Pode até haver vários produtores e consumidores em um aplicativo. No Kafka, todos os eventos existem por um determinado período, para que vários consumidores possam ler o mesmo evento repetidamente. O cluster Kafka inclui vários intermediários que são instâncias Kafka.
Um recurso importante do Kafka é a alta velocidade do processamento de eventos. Os sistemas tradicionais de enfileiramento, como o AMQP, possuem uma infraestrutura que monitora os eventos processados para cada consumidor. Quando o número de consumidores cresce para um nível decente, o sistema dificilmente começa a lidar com a carga, porque precisa monitorar um número crescente de condições. Além disso, existem grandes problemas com a consistência entre o processamento do consumidor e do evento. Por exemplo, vale a pena marcar imediatamente uma mensagem como enviada assim que é processada pelo sistema? E se um consumidor cair do outro lado sem receber uma mensagem?
Kafka também tem uma arquitetura à prova de falhas. O sistema é executado como um cluster em um ou mais servidores, que podem ser dimensionados horizontalmente adicionando novas máquinas. Todos os dados são gravados no disco e copiados para vários intermediários. Para entender as possibilidades de escalabilidade, vale a pena dar uma olhada em empresas como Netflix, LinkedIn, Microsoft. Todos eles enviam trilhões de mensagens por dia através de seus grupos Kafka!
Configurando o Kafka no Rails
O Heroku fornece um
complemento de cluster Kafka que pode ser usado para qualquer ambiente. Para aplicações em rubi, recomendamos o uso da
gema ruby-kafka . A implementação mínima é mais ou menos assim:
Depois de configurar a configuração, você pode usar a gema para enviar mensagens. Graças ao envio assíncrono de eventos, podemos enviar mensagens de qualquer lugar:
class OrdersController < ApplicationController def create @comment = Order.create!(params) $kafka_producer.produce(order.to_json, topic: "user_event", partition_key: user.id) end end
Falaremos sobre os formatos de serialização abaixo, mas, por enquanto, usaremos o bom e velho JSON. O argumento do
topic refere-se ao log no qual Kafka grava esse evento. Os tópicos estão espalhados em seções diferentes, que permitem dividir os dados de um tópico específico em diferentes intermediários para melhor escalabilidade e confiabilidade. E é realmente uma boa ideia ter duas ou mais seções para cada tópico, porque se uma delas cair, seus eventos serão gravados e processados de qualquer maneira. Kafka garante que os eventos sejam entregues na ordem da fila na seção, mas não no tópico inteiro. Se a ordem dos eventos for importante, o envio de partition_key garantirá que todos os eventos de um tipo específico sejam armazenados na mesma partição.
Kafka pelos seus serviços
Alguns dos recursos que tornam o Kafka uma ferramenta útil também o tornam um RPC de failover entre serviços. Veja um exemplo de aplicativo de comércio eletrônico:
def create_order create_order_record charge_credit_card
Quando o usuário
create_order um pedido, a função
create_order é
create_order . Isso cria um pedido no sistema, deduz dinheiro do cartão e envia um email com confirmação. Como você pode ver, as duas últimas etapas são executadas em serviços separados.
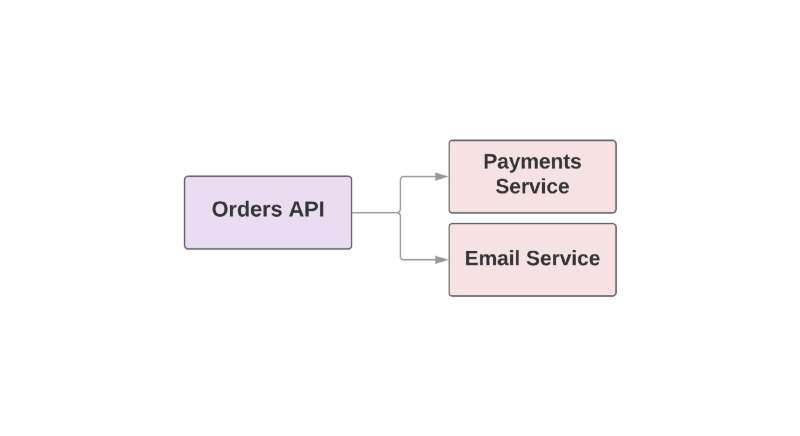
Um dos problemas dessa abordagem é que o serviço superior na hierarquia é responsável por monitorar a disponibilidade do serviço downstream. Se o serviço de envio de cartas tiver sido um dia ruim, o serviço mais alto precisará saber sobre ele. E se o serviço de envio estiver indisponível, você precisará repetir um determinado conjunto de ações. Como Kafka pode ajudar nessa situação?
Por exemplo:
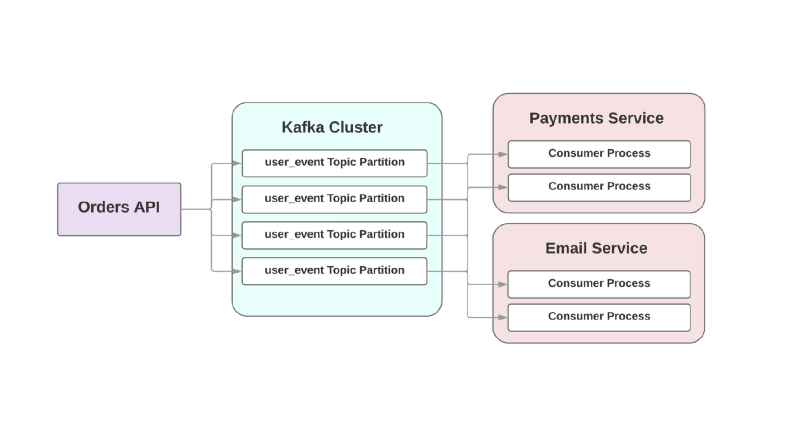
Nessa abordagem orientada a eventos, um serviço superior pode registrar em Kafka um evento em que um pedido foi criado. Devido à chamada abordagem
pelo menos uma vez , o evento será registrado em Kafka pelo menos uma vez e estará disponível para leitura dos consumidores a jusante. Se o serviço de envio de cartas persistir, o evento aguardará no disco até que o consumidor suba e o leia.
Outro problema com a arquitetura orientada a RPC está nos sistemas de crescimento rápido: a adição de um novo serviço downstream acarreta mudanças no upstream. Por exemplo, você gostaria de adicionar mais uma etapa depois de criar um pedido. Em um mundo orientado a eventos, você precisará adicionar outro consumidor para lidar com um novo tipo de evento.

Integrando Eventos à Arquitetura Orientada a Serviços
Uma postagem intitulada “
O que você quer dizer com“ Orientada a Eventos ” ” por Martin Fowler discute a confusão em torno de aplicativos orientados a eventos. Quando os desenvolvedores discutem esses sistemas, eles estão realmente falando sobre um grande número de aplicativos diferentes. Para fornecer uma compreensão geral da natureza de tais sistemas, Fowler definiu vários padrões arquiteturais.
Vamos dar uma olhada em quais são esses padrões. Se você quiser saber mais, aconselho a ler o
relatório dele no GOTO Chicago 2017.
Notificação de evento
O primeiro padrão Fowler é chamado de
Notificação de Eventos . Nesse cenário, o serviço do produtor notifica os consumidores do evento com uma quantidade mínima de informações:
{ "event": "order_created", "published_at": "2016-03-15T16:35:04Z" }
Se os consumidores precisarem de mais informações sobre o evento, solicitam ao produtor e obtêm mais dados.
Transferência de estado realizada por evento
O segundo modelo é chamado
de transferência de estado transportada por evento . Nesse cenário, o produtor fornece informações adicionais sobre o evento e o consumidor pode armazenar uma cópia desses dados sem fazer chamadas adicionais:
{ "event": "order_created", "order": { "order_id": 98765, "size": "medium", "color": "blue" }, "published_at": "2016-03-15T16:35:04Z" }
Origem do evento
Fowler chamou o terceiro modelo
Origem do Evento e é bastante arquitetônico. A liberação do modelo envolve não apenas a comunicação entre seus serviços, mas também a preservação da apresentação do evento. Isso garante que, mesmo se você perder o banco de dados, ainda poderá restaurar o estado do aplicativo simplesmente executando o fluxo de eventos salvo. Em outras palavras, cada evento salva um determinado estado do aplicativo em um determinado momento.
O grande problema dessa abordagem é que o código do aplicativo sempre muda e, com ela, o formato ou a quantidade de dados que o produtor fornece pode mudar. Isso torna problemático a restauração do estado do aplicativo.
Segregação de responsabilidade de consulta de comando
E o último modelo é
Segregação de Responsabilidade de Consulta de Comando , ou CQRS. A ideia é que as ações que você aplica ao objeto, por exemplo: criar, ler, atualizar, sejam divididas em diferentes domínios. Isso significa que um serviço deve ser responsável pela criação, outro pela atualização etc. Nos sistemas orientados a objetos, tudo geralmente é armazenado em um serviço.
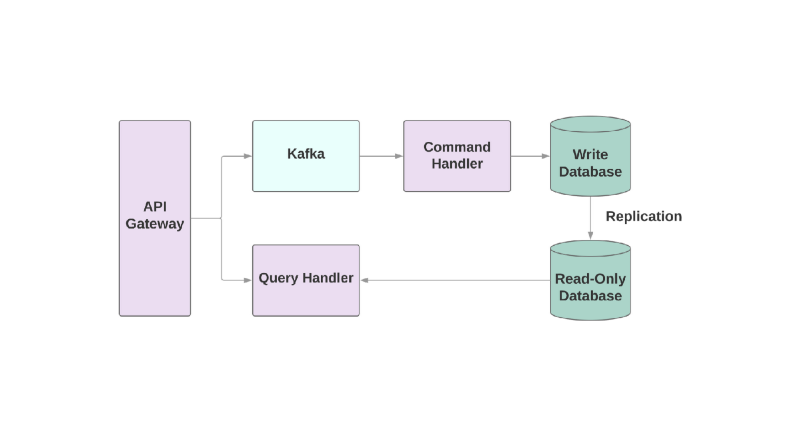
Um serviço que grava no banco de dados lê o fluxo de eventos e comandos de processo. Mas quaisquer solicitações ocorrem apenas no banco de dados somente leitura. Dividir a lógica de leitura e gravação em dois serviços diferentes aumenta a complexidade, mas permite otimizar o desempenho separadamente para esses sistemas.
Os problemas
Vamos falar sobre alguns dos problemas que você pode encontrar ao integrar o Kafka ao seu aplicativo orientado a serviços.
O primeiro problema pode ser lento para o consumidor. Em um sistema orientado a eventos, seus serviços devem poder processar eventos instantaneamente quando são recebidos de um serviço superior. Caso contrário, eles simplesmente serão interrompidos sem nenhum alerta sobre o problema ou o tempo limite. O único lugar onde você pode definir tempos limite é uma conexão de soquete com os agentes Kafka. Se o serviço não manipular o evento com rapidez suficiente, a conexão poderá ser interrompida por tempo limite, mas a restauração do serviço exigirá tempo adicional, pois a criação desses soquetes é cara.
Se o consumidor estiver lento, como você pode aumentar a velocidade do processamento de eventos? No Kafka, você pode aumentar o número de consumidores em um grupo, para que mais eventos possam ser processados em paralelo. Mas pelo menos 2 consumidores serão necessários para um serviço: no caso de um cair, as seções danificadas podem ser reatribuídas.
Também é muito importante ter métricas e alertas para monitorar a velocidade do processamento de eventos.
O ruby-kafka pode trabalhar com alertas do ActiveSupport, também possui módulos StatsD e Datadog, que são ativados por padrão. Além disso, a gema fornece uma
lista de métricas recomendadas para monitoramento.
Outro aspecto importante da construção de sistemas com o Kafka é o design de consumidores com capacidade de lidar com falhas. Kafka é garantido para enviar um evento pelo menos uma vez; excluiu o caso em que a mensagem não foi enviada. Mas é importante que os consumidores estejam preparados para lidar com eventos recorrentes. Uma maneira de fazer isso é sempre usar o
UPSERT para adicionar novos registros ao banco de dados. Se o registro já existir com os mesmos atributos, a chamada estará essencialmente inativa. Além disso, você pode adicionar um identificador exclusivo a cada evento e simplesmente pular eventos que já foram processados anteriormente.
Formatos de dados
Uma das surpresas ao trabalhar com Kafka pode ser sua simples atitude em relação ao formato dos dados. Você pode enviar qualquer coisa em bytes e os dados serão enviados ao consumidor sem nenhuma verificação. Por um lado, oferece flexibilidade e permite que você não se importe com o formato dos dados. Por outro lado, se o produtor decidir alterar os dados que estão sendo enviados, há uma chance de que algum consumidor acabe quebrando.
Antes de construir uma arquitetura orientada a eventos, selecione um formato de dados e analise como ele ajudará no futuro a registrar e desenvolver esquemas.
Um dos formatos recomendados para uso, é claro, é o JSON. Este formato é legível por humanos e é suportado por todas as linguagens de programação conhecidas. Mas existem armadilhas. Por exemplo, o tamanho dos dados finais em JSON pode se tornar assustadoramente grande. O formato é necessário para armazenar pares de valores-chave, que são flexíveis o suficiente, mas os dados são duplicados em cada evento. Alterar o esquema também é uma tarefa difícil, porque não há suporte interno para sobrepor uma chave à outra, se você precisar renomear o campo.
A equipe que criou o Kafka aconselha a
Avro como um sistema de serialização. Os dados são enviados em formato binário, e este não é o formato mais legível por humanos, mas por dentro há um suporte mais confiável para circuitos. A entidade final no Avro inclui o esquema e os dados. O Avro também suporta tipos simples, como números e complexos: datas, matrizes, etc. Além disso, permite incluir documentação dentro do esquema, o que permite entender o objetivo de um campo específico no sistema e contém muitas outras ferramentas internas para trabalhar com o esquema.
O avro-builder é uma gema criada pelo Salsify que oferece uma DSL semelhante a rubi para a criação de esquemas. Você pode ler mais sobre o Avro
neste artigo .
Informações Adicionais
Se você estiver interessado em hospedar o Kafka ou como ele é usado no Heroku, existem vários relatórios que podem ser do seu interesse.
Jeff Chao no DataEngConf SF '17 "
Além de 50.000 partições: como o Heroku opera e aumenta os limites de Kafka em escala "
Pavel Pravosud na Dreamforce '16 “
Dogfooding Kafka: como construímos a conferência em
tempo real da Heroku Platform Event Stream ”
Tenha uma bela vista!