Os logs são uma parte importante do sistema, permitindo que você entenda que ele funciona (ou não), conforme o esperado. Nas condições da arquitetura de microsserviço, o trabalho com logs se torna uma disciplina separada de uma Olimpíada especial. Você precisa resolver imediatamente um monte de perguntas:
- como escrever logs do aplicativo;
- onde escrever logs;
- como entregar logs para armazenamento e processamento;
- como processar e armazenar logs.
O uso de tecnologias de contêiner, agora popular, adiciona areia ao rake ao campo de opções para resolver o problema.
Apenas sobre esta decodificação do relatório de Yuri Bushmelev "Ancinho de mapa no campo da coleta e entrega de toras"
Quem se importa, por favor, debaixo do gato.
Meu nome é Yuri Bushmelev. Eu trabalho na Lazada. Hoje vou falar sobre como fizemos nossos logs, como os coletamos e o que escrevemos lá.

De onde nós somos? Quem somos Lazada é a loja on-line número 1 em seis países do sudeste asiático. Todos esses países são distribuídos por data centers. Agora existem 4 data centers.Por que isso é importante? Porque algumas decisões se devem ao fato de haver um elo muito fraco entre os centros. Temos uma arquitetura de microsserviço. Fiquei surpreso ao descobrir que já temos 80 microsserviços. Quando iniciei a tarefa com logs, havia apenas 20. Além disso, há uma parte bastante grande do legado do PHP, com o qual você também precisa conviver e aguentar. Tudo isso gera para nós no momento mais de 6 milhões de mensagens por minuto em todo o sistema como um todo. Além disso, mostrarei como estamos tentando viver com isso e por que é assim.

De alguma forma, precisamos viver com esses 6 milhões de mensagens. O que devemos fazer com eles? 6 milhões de mensagens necessárias:
- enviar da aplicação
- aceite para entrega
- entregue para análise e armazenamento.
- analisar
- de alguma forma armazenar.

Quando três milhões de mensagens apareceram, eu tinha a mesma aparência. Porque começamos com alguns centavos. É claro que os logs do aplicativo são gravados lá. Por exemplo, não consegui conectar ao banco de dados, consegui conectar ao banco de dados, mas não consegui ler algo. Além disso, cada um dos nossos microsserviços também grava um log de acesso. Cada solicitação que chega a um microsserviço cai no log. Por que estamos fazendo isso? Os desenvolvedores querem poder rastrear. Em cada log de acesso, há um campo de rastreamento, ao longo do qual uma interface especial desenrola ainda mais toda a cadeia e exibe lindamente o rastreamento. O rastreamento mostra como foi a solicitação e isso ajuda nossos desenvolvedores a lidar rapidamente com qualquer lixo não identificado.

Como viver com isso? Agora vou descrever brevemente o campo de opções - como, em geral, esse problema é resolvido. Como resolver o problema de coleta, transferência e armazenamento de logs.

Como escrever a partir da aplicação? É claro que existem maneiras diferentes. Em particular, há boas práticas, como os camaradas da moda nos dizem. Há uma velha escola de duas formas, como disseram os avós. Existem outras maneiras.

Com a coleção de logs sobre a mesma situação. Não há muitas opções para resolver esta parte específica. Já existem mais, mas não tantos.

Mas com entrega e análise subseqüente - o número de variações começa a explodir. Não vou descrever cada opção agora. Eu acho que as principais opções são ouvidas por todos que estavam interessados no tópico.

Vou mostrar como fizemos na Lazada e como tudo começou.

Há um ano, vim para Lazada e eles me enviaram para um projeto sobre logs. Foi assim. O log do aplicativo foi gravado em stdout e stderr. Eles fizeram tudo de uma maneira elegante. Mas então os desenvolvedores jogaram fora dos fluxos padrão, e então os especialistas em infraestrutura resolverão isso de alguma maneira. Entre especialistas em infraestrutura e desenvolvedores, também há lançamentos que dizem: “uh ... bem, vamos envolvê-los em um arquivo com um shell, só isso.” E como tudo isso está no contêiner, eles o embrulharam no próprio contêiner, baixaram o catálogo e o colocaram lá. Eu acho que é aproximadamente óbvio para todos o que veio disso.

Vamos ver um pouco mais longe. Como entregamos esses logs. Alguém escolheu o agente td, que é realmente fluente, mas não muito fluente. Ainda não entendi a relação desses dois projetos, mas eles parecem ter a mesma coisa. E esse fluente, escrito em Ruby, leu arquivos de log, os analisou em JSON por alguns períodos regulares. Então ele os enviou para Kafka. E em Kafka para cada API, tínhamos 4 tópicos separados. Por que 4? Porque existe ao vivo, há preparação e porque há stdout e stderr. Os desenvolvedores dão à luz e engenheiros de infraestrutura devem criá-los em Kafka. Além disso, Kafka era controlado por outro departamento. Portanto, era necessário criar um ticket para que eles criassem 4 tópicos para cada API lá. Todo mundo esqueceu. Em geral, havia lixo e fumaça.
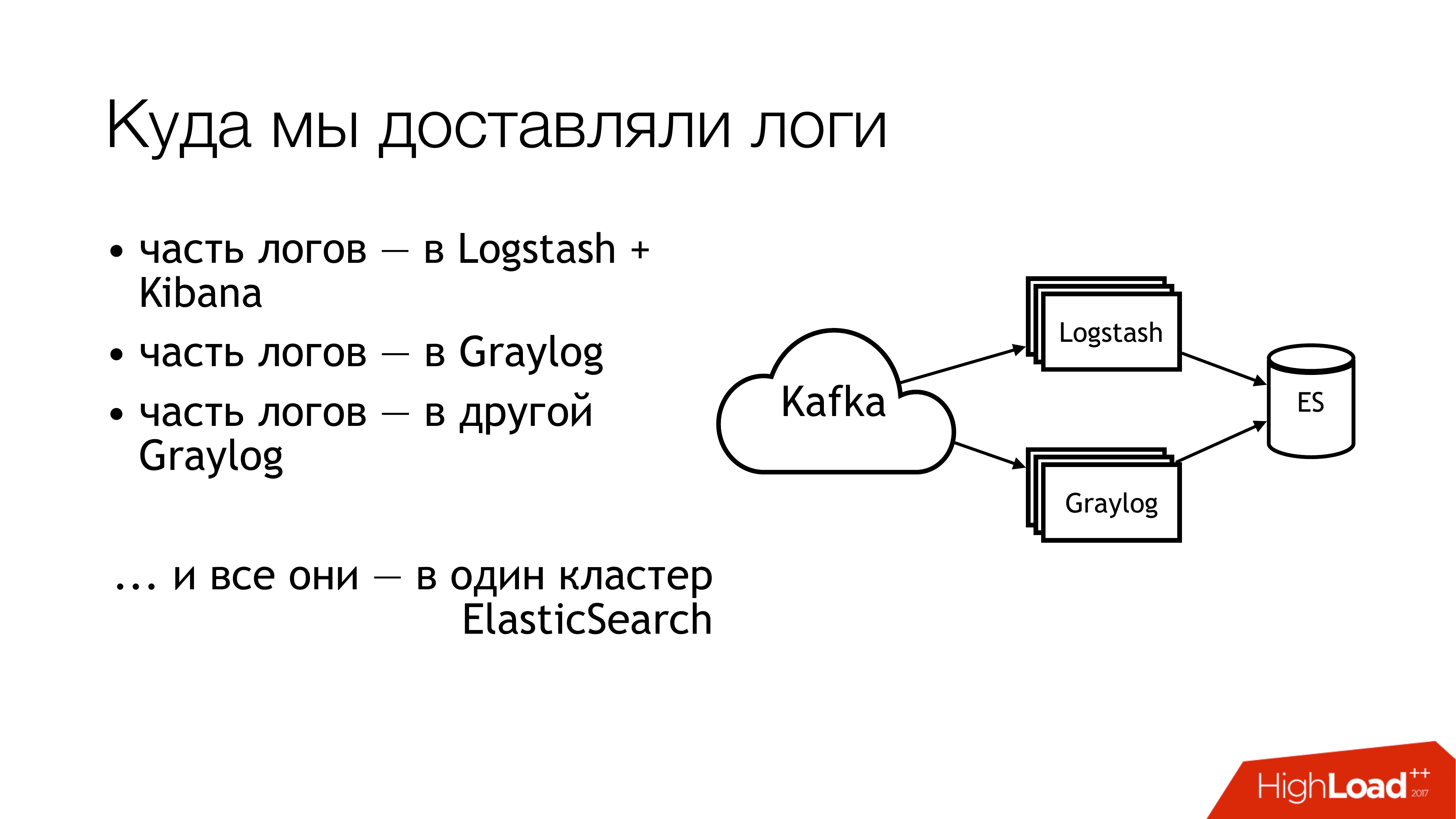
O que fizemos a seguir com isso? Nós o enviamos para kafka. Mais longe de Kafka, metade dos toros voou para Logstash. A outra metade dos logs foi compartilhada. Parte voou em um Graylog, parte - em outro Graylog. Como resultado, tudo isso se transformou em um cluster do Elasticsearch. Ou seja, toda essa bagunça acabou por cair lá. Você não precisa fazer isso!

É assim que parece se você olhar remotamente de cima. Não faça isso! Aqui, os números indicam imediatamente as áreas problemáticas. Na verdade, existem mais deles, mas 6 são realmente bastante problemáticos, com os quais você precisa fazer alguma coisa. Eu vou falar sobre eles separadamente agora.

Aqui (1,2,3) estamos escrevendo arquivos e, consequentemente, aqui estão três rakes ao mesmo tempo.
O primeiro (1) é que precisamos escrevê-los em algum lugar. Nem sempre eu gostaria de dar à API a capacidade de gravar diretamente em um arquivo. É desejável que a API seja isolada no contêiner e, melhor ainda, que seja somente leitura. Como sou administrador de sistemas, tenho uma visão um pouco alternativa dessas coisas.
O segundo ponto (2,3) - temos muitas solicitações chegando à API. A API grava muitos dados em um arquivo. Arquivos estão crescendo. Nós precisamos rotacioná-los. Porque, caso contrário, não há como obter discos. A rotação deles é ruim porque eles são redirecionados através do shell para um diretório. Não podemos movê-lo de nenhuma maneira. Um aplicativo não pode ser solicitado para redescobrir descritores. Porque os desenvolvedores olharão para você como um tolo: “Quais são os descritores? Geralmente escrevemos para stdout. ” Os engenheiros de infraestrutura fizeram cópias em logrotate, o que faz apenas uma cópia do arquivo e transcreve o original. Assim, entre esses processos de cópia, o espaço em disco geralmente termina.
(4) Tínhamos formatos diferentes e estávamos em APIs diferentes. Eles eram um pouco diferentes, mas o regexp tinha que ser escrito de maneira diferente. Como tudo isso era controlado por Puppet, havia um grande grupo de classes com suas baratas. Além disso, o agente td na maioria das vezes podia comer memória, estúpido, poderia apenas fingir que funciona e não fazer nada. Lá fora, era impossível entender que ele não estava fazendo nada. Na melhor das hipóteses, ele cairá e alguém o buscará mais tarde. Mais precisamente, o alerta chegará e alguém passará com as mãos.

(6) E o máximo de lixo e desperdício - era a pesquisa elástica. Porque era uma versão antiga. Porque, na época, não tínhamos mestres dedicados. Tínhamos logs heterogêneos nos quais os campos podiam se cruzar. Logs diferentes de aplicativos diferentes podem ser gravados com os mesmos nomes de campo, mas ao mesmo tempo pode haver dados diferentes. Ou seja, um log vem com Inteiro no campo, por exemplo, nível. Outro log vem com String no campo level. Na ausência de mapeamento estático, uma coisa tão maravilhosa é obtida. Se, após a rotação do índice na elasticsearch, a primeira mensagem com uma string chegar, viveremos normalmente. E se chegou primeiro com Inteiro, todas as mensagens subseqüentes que chegaram com String são simplesmente descartadas. Porque o tipo de campo não corresponde.

Começamos a fazer essas perguntas. Decidimos não procurar os culpados.

Mas algo precisa ser feito! O óbvio é estabelecer padrões. Nós já tínhamos alguns padrões. Alguns temos um pouco mais tarde. Felizmente, um formato de log uniforme para todas as APIs já havia sido aprovado naquele momento. Está escrito diretamente nos padrões para a interação dos serviços. Dessa forma, aqueles que desejam receber logs devem gravá-los neste formato. Se alguém não gravar registros nesse formato, não garantimos nada.
Além disso, gostaria de estabelecer um padrão único para os métodos de registro, entrega e coleta de logs. Na verdade, onde escrevê-los e como entregá-los. A situação ideal é quando os projetos usam a mesma biblioteca. Aqui está uma biblioteca de log separada para Go, há uma biblioteca separada para PHP. Todos que temos - todos devem usá-los. No momento, eu diria que conseguimos 80%. Mas alguns continuam a comer cactos.
E lá (no slide) mal apareceu "SLA para entrega de logs". Ele ainda não está lá, mas estamos trabalhando nisso. Como é muito conveniente quando a infra diz que, se você escreve em um formato tal e tal em tal e tal lugar e não mais que N mensagens por segundo, é provável que entregemos tal e qual lá. Isso alivia um monte de dores de cabeça. Se houver um SLA, isso é maravilhoso!

Como começamos a resolver o problema? O rake principal foi com o td-agent. Não estava claro para onde os logs estavam indo. Eles são entregues? Eles estão indo? Onde eles estão? Portanto, o primeiro item foi decidido para substituir o td-agent. Esbocei brevemente as opções para substituí-lo.
Fluente Primeiro, me deparei com ele em um emprego anterior, e ele também periodicamente caiu lá. Em segundo lugar, é o mesmo, apenas no perfil.
Filebeat. Como foi conveniente para nós? O fato de ele estar no Go, e temos muita experiência no Go. Portanto, se isso, poderíamos, de alguma forma, adicioná-lo por nós mesmos. Portanto, nós não aceitamos. De modo que nem mesmo a tentação começou a reescrevê-lo para si mesmo.
A solução óbvia para o sysadmin é todos os syslogs nessa quantidade (syslog-ng / rsyslog / nxlog).
Ou escreva algo de nossa autoria, mas deixamos de lado, assim como a batida de arquivo. Se você escrever algo, é melhor escrever algo útil para os negócios. Para a entrega de logs, é melhor levar algo pronto.
Portanto, a escolha realmente se resumiu à escolha entre syslog-ng e rsyslog. Ele se inclinou para o rsyslog simplesmente porque já tínhamos aulas para o rsyslog no Puppet, e eu não encontrei nenhuma diferença óbvia entre eles. O que é syslog, o que é syslog. Sim, alguém tem documentação pior, alguém tem melhor. Ele sabe como, e ele - de uma maneira diferente.

E um pouco sobre o rsyslog. Primeiro, é legal porque tem muitos módulos. Possui RainerScript legível por humanos (uma linguagem de configuração moderna). O bônus impressionante é que poderíamos emular o comportamento do agente td usando seus meios regulares, e nada mudou para os aplicativos. Ou seja, estamos mudando td-agent para rsyslog, mas não estamos tocando em tudo o mais. E imediatamente recebemos uma entrega de trabalho. Em seguida, mmnormalize é uma coisa impressionante no rsyslog. Permite analisar logs, mas não usando Grok e regexp. Ela cria uma árvore de sintaxe abstrata. Ele analisa os logs aproximadamente, conforme o compilador analisa os códigos-fonte. Isso permite que você trabalhe muito rapidamente, coma pouca CPU e, em geral, é uma coisa muito legal. Existem toneladas de outros bônus. Eu não vou parar sobre eles.

O Rsyslog ainda tem um monte de falhas. Eles são quase os mesmos que bônus. Os principais problemas - você precisa ser capaz de cozinhá-lo e selecionar a versão.
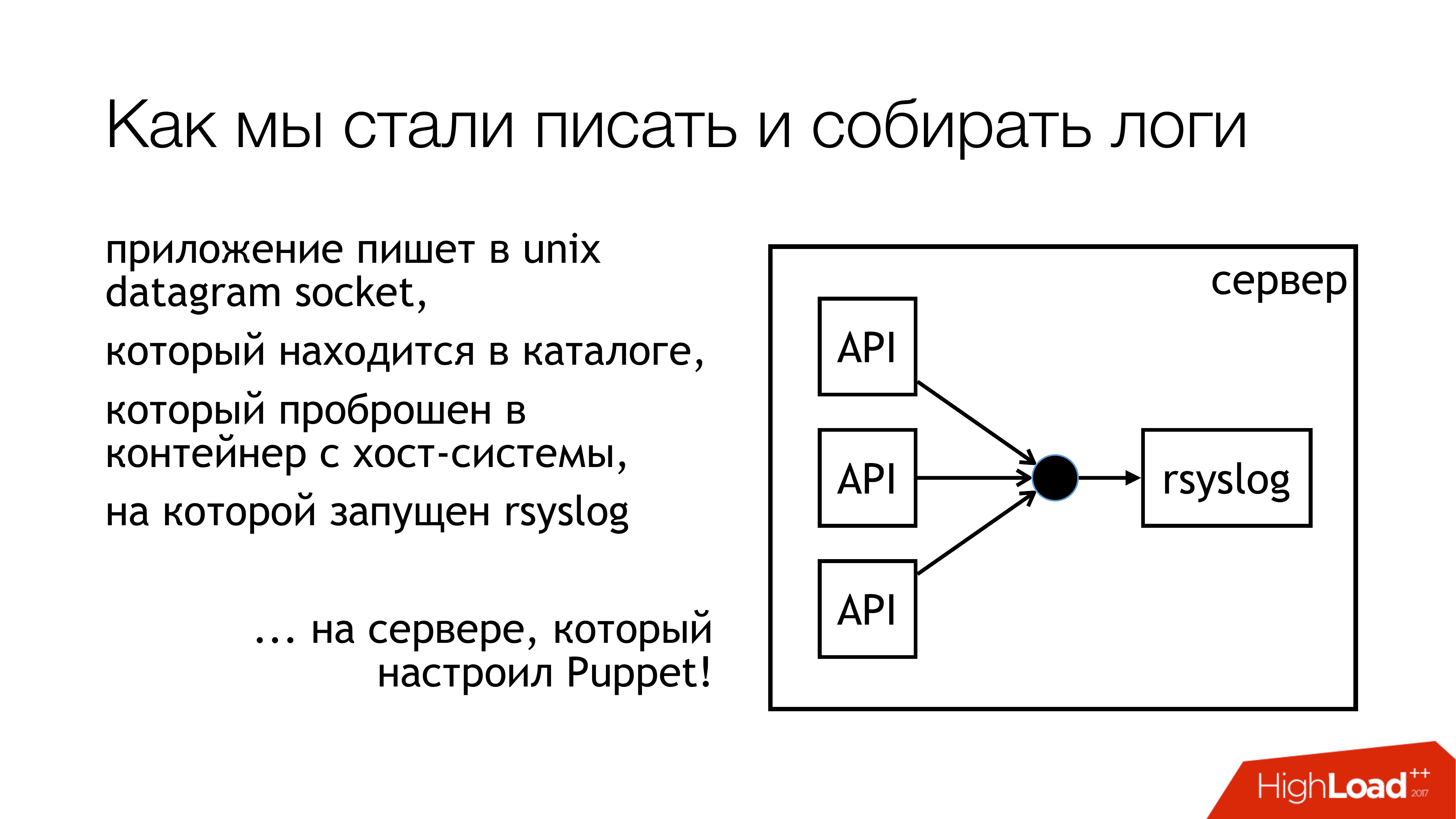
Decidimos que escreveríamos logs no soquete unix. E não no / dev / log, porque temos mingau nos logs do sistema, existe um diário nesse pipeline. Então, vamos escrever para um soquete personalizado. Nós o anexamos a um conjunto de regras separado. Nós não vamos interferir. Tudo será transparente e claro. Então nós realmente fizemos. O diretório com esses soquetes é padronizado e encaminhado para todos os contêineres. Os contêineres podem ver o soquete de que precisam, abrir e gravá-lo.
Por que não um arquivo? Como todo mundo leu um artigo sobre Badushechka que tentou encaminhar o arquivo para o docker, descobriu-se que, após o rsyslog reiniciar, o descritor de arquivo é alterado, e o docker perde esse arquivo. Ele mantém algo mais aberto, mas não o mesmo espaço onde eles escrevem. Decidimos que contornávamos esse problema e, ao mesmo tempo, contornávamos o problema de bloqueio.

O Rsyslog executa as ações indicadas no slide e envia os logs para a retransmissão ou para Kafka. Kafka corresponde à maneira antiga. Relé - Tentei usar o rsyslog puro para entregar logs. Sem fila de mensagens, ferramentas rsyslog padrão. Basicamente, funciona.

Mas existem nuances de como colocá-las posteriormente nesta parte (Logstash / Graylog / ES). Esta parte (rsyslog-rsyslog) é usada entre data centers. Aqui está um link tcp compactado, que permite economizar largura de banda e, consequentemente, aumentar a probabilidade de recebermos algum tipo de log de outro data center em condições em que o canal está cheio. Porque temos a Indonésia, na qual tudo está ruim. É aqui que está esse problema constante.

Pensamos em como realmente monitoramos, com que probabilidade os logs que gravamos do aplicativo atingem esse fim? Decidimos obter as métricas. O Rsyslog possui seu próprio módulo de coleta de estatísticas, que possui algum tipo de contador. Por exemplo, ele pode mostrar o tamanho da fila ou quantas mensagens vieram em uma ação dessas. Algo já pode ser tirado deles. Além disso, possui contadores personalizados que podem ser configurados e mostrará, por exemplo, o número de mensagens que alguma API gravou. Em seguida, escrevi o rsyslog_exporter em Python e enviamos tudo para Prometheus e plotamos. As métricas do Graylog realmente queriam, mas até agora não tivemos tempo para configurá-las.

Quais são os problemas? Surgiram problemas com o fato de descobrirmos (SUDDENLY!) Que nossas APIs ativas gravam 50 mil mensagens por segundo. Esta é apenas uma API ao vivo sem preparação. E o Graylog mostra apenas 12 mil mensagens por segundo. E surgiu uma pergunta razoável, mas onde estão as sobras? A partir do qual concluímos que Graylog simplesmente não pode lidar. Eles pareciam e, de fato, o Graylog da Elasticsearch não dominava esse fluxo.
Além disso, outras descobertas que fizemos no processo.
A gravação no soquete está bloqueada. Como isso aconteceu? Quando usei o rsyslog para entrega, em algum momento nosso canal entre os data centers quebrou. Entrega subiu em um lugar, entrega subiu em outro lugar. Tudo isso chegou a uma máquina com APIs que gravam no soquete rsyslog. Havia uma fila. Em seguida, a fila para gravar no soquete unix foi preenchida, cujo padrão é 128 pacotes. E a próxima gravação () no aplicativo está bloqueada. Quando examinamos a biblioteca que usamos nos aplicativos Go, foi escrito lá que a gravação no soquete ocorre no modo sem bloqueio. Tínhamos certeza de que nada está bloqueando. Porque lemos um artigo sobre Badushechka que escreveu sobre isso. Mas há um momento. Ao redor dessa ligação, ainda havia um ciclo interminável, no qual era feita uma tentativa constante de empurrar a mensagem para o soquete. Nós não percebemos isso. Eu tive que reescrever a biblioteca. Desde então, ele mudou várias vezes, mas agora nos livramos dos bloqueios em todos os subsistemas. Portanto, você pode parar o rsyslog e nada cairá.
É necessário monitorar o tamanho das filas, o que ajuda a não pisar nesse rake. Primeiro, podemos monitorar quando começamos a perder mensagens. Em segundo lugar, podemos monitorar que, em princípio, temos problemas de entrega.
E outro momento desagradável - amplificação 10 vezes na arquitetura de microsserviços - é muito fácil. Não temos muitas solicitações de entrada, mas, devido ao gráfico em que essas mensagens são executadas, devido aos logs de acesso, aumentamos realmente a carga nos logs uma vez a cada dez. Infelizmente, não tive tempo para calcular os números exatos, mas os microsserviços - eles são. Isso deve ser lembrado. Acontece que, no momento, o subsistema de coleta de logs é o mais carregado no Lazada.

Como resolver o problema de elasticsearch? Se você precisar obter rapidamente os logs em um único local, para não percorrer todas as máquinas e não coletá-las, use o armazenamento de arquivos. Isso é garantido para o trabalho. É feito de qualquer servidor. Você só precisa colar os discos lá e colocar o syslog. Depois disso, você terá todos os logs em um só lugar. Além disso, já será possível ajustar lentamente a elasticsearch, graylog, outra coisa. Mas você já terá todos os logs e, além disso, poderá armazená-los o máximo possível de matrizes de disco.

Na época do meu relatório, o circuito começou a ficar assim. Nós praticamente paramos de gravar no arquivo. Agora, provavelmente, vamos desligar as sobras. Em máquinas locais executando a API, pararemos de gravar em arquivos. Em primeiro lugar, existe um armazenamento de arquivos que funciona muito bem. Em segundo lugar, o local nessas máquinas acaba constantemente, é necessário monitorá-lo constantemente.
Essa parte do Logstash e do Graylog realmente aumenta. Portanto, devemos nos livrar disso. Você tem que escolher uma coisa.

Decidimos jogar Logstash e Kibana. Porque nós temos um departamento de segurança. Qual é a conexão? A conexão é que o Kibana sem o X-Pack e sem o Shield não permite diferenciar os direitos de acesso aos logs. Portanto, eles pegaram Graylog. Ele tem tudo. Eu não gosto dele, mas funciona. Compramos ferro novo, colocamos Graylog fresco lá e movemos todos os logs com formatos rígidos para um Graylog separado. Resolvemos o problema com diferentes tipos de campos idênticos organizacionalmente.

O que exatamente está incluído no novo Graylog. Acabamos de gravar tudo na janela de encaixe. Pegamos vários servidores, lançamos três instâncias Kafka, 7 servidores Graylog versão 2.3 (porque eu queria o Elasticsearch versão 5). Tudo isso em ataques do HDD levantados. Vimos uma taxa de indexação de até 100 mil mensagens por segundo. Vimos a figura de 140 terabytes de dados por semana.

E novamente um ancinho! Duas vendas estão chegando. Mudamos para 6 milhões de mensagens. Em nós, Graylog não tem tempo para mastigar. De alguma forma, temos que sobreviver novamente.

Nós sobrevivemos assim. Adicionamos mais alguns servidores e SSDs. No momento, vivemos dessa maneira. Agora já estamos mastigando 160 mil mensagens por segundo. Ainda não atingimos o limite, portanto ainda não está claro o quanto realmente podemos obter disso.

Esses são nossos planos para o futuro. Destes, realmente, o mais importante é provavelmente a alta disponibilidade. Ainda não o temos. Vários carros são configurados da mesma forma, mas até agora tudo está passando por um carro. , failover .
Graylog.
rate limit , API, bandwidth .
, - SLA c , . , .
.

, , . -, . -, syslog — . -, rsyslog , . .
.
: - … (filebeat?)
: . . API , , . pipe. : « , , »? , , : « , ».
: HDFS?
: . , , , , long term solution.
: .
: . "" .
: rsyslog. TCP, UDP. UDP, ?
: . , , . , : « , - , - », «! , , , .» . , ? , ? best effort. , 100% . . .
: API - , , ? - .
: , . . , . , API . rsyslog . API , , timestamp . Graylog, timestamp. .
: Timestamp .
: Timestamp API. , , . NTP. API timestamp . rsyslog .
: . , . ? ?
: . - . , . . Log Relay. Rsyslog . . . . . . , (), Graylog. storage. , , . . .
: ?
: ( ) .
: , ?
: , . . , Go API, . , socket. . . socket. , . . , . prometheus, Grafana . . , .
: elasticsearch . ?
: .
: ?
: . .
: rsyslog - ?
: unix socket. 128 . . . , 128 . , , , , . , . .
c : JSON?
: JSON relay, . Graylog, JSON . , , rsyslog. issue, .
c : Kafka? RabbitMQ? Graylog ?
: Graylog . Graylog . . . , , . rsyslog elasticsearch Kibana. . , Graylog Kibana. Logstash . , rsyslog. elasticsearch. Graylog - . . .
Kafka. . , , . . , , . RabbitMQ… c RabbitMQ. RabbitMQ . , . , . . . Graylog AMQP 0.9, rsyslog AMQP 1.0. , , . . Kafka. . omkafka rsyslog, , , rsyslog. .
Pergunta : Você usa Kafka porque o tinha? Não é utilizado para outros fins?
Resposta : Kafka, que foi usado pela equipe do Data Sience. Este é um projeto completamente separado, sobre o qual, infelizmente, não posso dizer nada. Eu não sei Ela foi administrada pela equipe de ciência de dados. Quando os logs começaram, eles decidiram usá-lo, para não colocar seus próprios. Agora, atualizamos o Graylog e perdemos a compatibilidade, porque existe uma versão antiga do Kafka. Nós tivemos que conseguir o nosso. Ao mesmo tempo, nos livramos desses quatro tópicos para cada API. Criamos um tópico amplo para todos ao vivo, um tópico amplo para todos os estágios e apenas marcamos tudo lá. Graylog ajusta tudo isso em paralelo.
Pergunta : Por que esse xamanismo com soquetes é necessário? Você já tentou usar o driver de log syslog para contêineres?
Resposta : No momento em que fizemos essa pergunta, tínhamos um relacionamento tenso com a janela de encaixe. Era docker 1.0 ou 0.9. Docker em si era estranho. Em segundo lugar, se você também enfiar os logs nele ... tenho uma suspeita não confirmada de que ele passa todos os logs por si mesmo, através do demônio estivador. Se temos uma API enlouquecendo, o restante das APIs fica preso no fato de que elas não podem enviar stdout e stderr. Não sei aonde isso vai levar. Suspeito que você não precise usar o driver syslog do docker neste local. Nosso departamento de testes funcionais possui seu próprio cluster Graylog com logs. Eles usam drivers de log do docker e tudo parece estar bem lá. Mas eles imediatamente escrevem GELF para Graylog. Nós, naquele momento em que tudo isso estava acontecendo, precisávamos que funcionasse. Talvez mais tarde, quando alguém vier e disser que está funcionando normalmente há cem anos, tentaremos.
Pergunta : Você entrega entre os datacenters no rsyslog. Por que não no Kafka?
Resposta : Estamos fazendo as duas coisas, e assim, na realidade. Por duas razões. Se o canal estiver completamente inoperante, todos os logs, mesmo que compactados, não serão rastreados. E o kafka permite que eles simplesmente se percam no processo. Dessa maneira, nos livramos de colar esses logs. Nós apenas usamos Kafka neste caso diretamente. Se temos um bom canal e queremos liberá-lo, usamos o rsyslog deles. Mas, na verdade, você pode configurá-lo para que ele mesmo elimine o que não foi rastreado. No momento, estamos apenas em algum lugar usando a entrega do rsyslog diretamente, em algum lugar do Kafka.