
Os desenvolvedores são loucos pelas coisas mais estranhas. Todos nós preferimos nos considerar seres super-racionais, mas quando se trata de escolher uma tecnologia específica, caímos em uma espécie de loucura, passando de um comentário no HackerNews para um post de blog e agora, como se estivéssemos esquecidos, somos impotentes estamos navegando em direção à fonte mais brilhante de luz e nos curvamos obedientemente, tendo esquecido completamente o que estávamos procurando originalmente.
Não é assim que pessoas racionais tomam decisões. Mas exatamente para que os desenvolvedores decidam usar, por exemplo, o MapReduce.
Como Joe Hellerstein observou em sua palestra sobre bancos de dados para estudantes de graduação (aos 54 minutos):
O fato é que existem aproximadamente 5 empresas no mundo que realizam tarefas tão ambiciosas. Quanto a todos os outros ... eles gastam recursos incríveis para fornecer um sistema tolerante a falhas que eles realmente não precisam. As pessoas tinham uma espécie de "googleing" na década de 2000: "faremos tudo exatamente como o Google, porque também gerenciamos o maior serviço de processamento de dados do mundo ..." [ironicamente balança a cabeça e espera risadas da platéia]

Quantos andares no prédio do seu data center? O Google decidiu ficar em quatro, pelo menos neste data center específico localizado em Mays County, Oklahoma.
Sim, seu sistema é mais resistente do que você precisa, mas pense no que isso pode custar. O ponto não é apenas a necessidade de processar grandes quantidades de dados. Você provavelmente está trocando um sistema completo - com transações, índices e otimização de consultas - por algo relativamente fraco. Este é um passo significativo para trás. Quantos usuários do Hadoop fazem isso conscientemente? Quantos deles tomam uma decisão realmente equilibrada?
O MapReduce / Hadoop é um exemplo muito simples. Até os seguidores do Cargo Cult já perceberam que os aviões não resolveriam todos os seus problemas. No entanto, o uso do MapReduce permite fazer uma generalização importante: se você usa a tecnologia criada para uma grande corporação, mas ao mesmo tempo resolve pequenos problemas, pode estar agindo sem pensar. Mesmo assim, é mais provável que você seja guiado por idéias místicas que, imitando gigantes como Google e Amazon, atingirão as mesmas alturas.

Sim, este artigo é outro oponente do culto à carga. Mas espere, eu tenho uma lista de verificação útil para você, que você pode usar para tomar decisões mais informadas.
Estrutura legal: UNPHAT
Na próxima vez que você pesquisar no Google alguma nova técnica interessante para (re) moldar seu sistema, peço que você pare e use a estrutura UNPHAT :
- Nem tente pensar em possíveis soluções antes de entender o problema (Compreender) . Seu principal objetivo é "resolver" o problema em termos do problema, não em termos de soluções.
- Listar (eNumerar) várias soluções possíveis. Não há necessidade de apontar imediatamente o dedo para sua opção favorita.
- Considere uma solução separada e leia a documentação (papel) , se houver.
- Defina o contexto histórico em que esta solução foi criada.
- Combine vantagens com falhas. Analise o que os tomadores de decisão tiveram que sacrificar para atingir seu objetivo.
- Pense (pense) ! Com seriedade e seriedade, considere quão bem essa solução é adequada para atender às suas necessidades. O que exatamente precisa mudar para você mudar de idéia? Por exemplo, quanto menos dados devem existir, para que você prefira não usar o Hadoop?
Você não é amazon
Usar o UNPHAT é fácil. Lembre-se da minha recente conversa com uma empresa que decidiu apressadamente usar o Cassandra para um intenso processo de leitura de dados baixados à noite.
Como eu já estava familiarizado com a documentação do Dynamo e sabia que o Cassandra é um sistema derivado, entendi que nesses bancos de dados o foco principal estava na capacidade de gravar (a Amazon precisava fazer a ação "adicionar ao carrinho" nunca não falhou). Também apreciei que os desenvolvedores sacrificassem a integridade dos dados - e, de fato, todos os recursos inerentes ao RDBMS tradicional. Mas, afinal, a empresa com a qual conversei, a capacidade de gravar não era uma prioridade. Honestamente, o projeto significava criar um grande recorde por dia.

A Amazon vende muito de tudo. Se a função "adicionar à cesta" de repente parasse de funcionar, eles perderiam muito dinheiro. Você tem um problema da mesma ordem?
Essa empresa decidiu usar o Cassandra porque demorou alguns minutos para concluir a consulta do PostgreSQL em questão, e eles decidiram que essas eram limitações técnicas por parte do hardware. Depois de esclarecer alguns pontos, percebemos que a tabela consistia em aproximadamente 50 milhões de linhas de 80 bytes cada. Levaria cerca de 5 segundos para lê-lo no SSD se você tivesse que passar por isso completamente. Isso é lento, mas ainda é duas ordens de magnitude mais rápido que a velocidade de execução da consulta naquele momento.
Nesse estágio, eu tinha muitas perguntas (U = entendi, entendi o problema!) E comecei a ponderar cerca de 5 estratégias diferentes que poderiam resolver o problema original (N = eNumerate, liste algumas soluções possíveis!), Mas de qualquer forma já estava claro no momento que o uso de Cassandra era fundamentalmente a decisão errada. Tudo o que eles precisavam era de um pouco de paciência para configurar, provavelmente um novo design para o banco de dados e, possivelmente (embora improvável), a escolha de uma tecnologia diferente ... Mas definitivamente não é um armazenamento de dados de valor-chave com gravação intensiva que a Amazon criou para sua cesta!
Você não é o LinkedIn
Fiquei muito surpreso ao descobrir que uma startup estudantil decidiu construir sua arquitetura em torno de Kafka. Isso foi incrível. Até onde eu sabia, os negócios deles realizavam apenas algumas dezenas de operações muito grandes por dia. Talvez algumas centenas nos dias de maior sucesso. Com essa largura de banda, o principal armazém de dados pode ser entradas manuscritas em um livro comum.
Para comparação, lembre-se de que o Kafka foi criado para lidar com todos os eventos analíticos no LinkedIn. Esta é apenas uma enorme quantidade de dados. Até alguns anos atrás, eram cerca de 1 trilhão de eventos por dia , com um pico de carga de 10 milhões de mensagens por segundo. Claro, eu entendo que Kafka pode ser usado para trabalhar com cargas mais baixas, mas com 10 pedidos a menos?

O Sol, sendo um objeto muito massivo, é apenas 6 ordens de magnitude mais pesadas que a Terra.
Talvez os desenvolvedores tenham tomado uma decisão deliberada, com base nas necessidades esperadas e um bom entendimento do objetivo do Kafka. Mas acho que eles foram alimentados pelo entusiasmo (geralmente justificado) da comunidade por Kafka e quase nunca se perguntaram se essa era realmente a ferramenta de que precisavam. Imagine ... 10 pedidos!
Eu já disse isso? Você não é amazon
Ainda mais popular que o data warehouse distribuído da Amazon, é a abordagem de desenvolvimento arquitetônico que lhes proporcionou escalabilidade: uma arquitetura orientada a serviços. Como Werner Vogels observou em uma entrevista de 2006 com Jim Gray, a Amazon percebeu em 2001 que eles estavam tendo dificuldades em dimensionar a parte do front-end e que uma arquitetura orientada a serviços poderia ajudá-los. Essa idéia infectou um desenvolvedor após o outro, enquanto as startups, compostas por apenas alguns desenvolvedores e quase nenhum cliente, não começaram a dividir seu software em nanosserviços.
Quando a Amazon decidiu mudar para SOA (arquitetura orientada a serviços), eles tinham cerca de 7.800 funcionários e suas vendas excederam US $ 3 bilhões .

A sala de concertos Bill Graham Auditorium, em São Francisco, acomoda 7.000 pessoas. A Amazon tinha cerca de 7.800 funcionários quando mudaram para SOA.
Isso não significa que você deve adiar a transição para SOA até que sua empresa atinja o nível de 7800 funcionários ... apenas pense sempre com sua própria cabeça . Esta é realmente a melhor solução para sua tarefa? Qual é exatamente a tarefa diante de você e existem outras maneiras de resolvê-la?
Se você me disser que o trabalho da sua organização, que consiste em 50 desenvolvedores, simplesmente aumenta sem uma SOA, então me pergunto por que tantas empresas grandes simplesmente trabalham maravilhosamente usando um aplicativo único, mas bem organizado.
Mesmo o Google não é o Google.
Exemplos de uso de sistemas para processar fluxos de dados altamente carregados (Hadoop ou Spark) podem realmente ser desconcertantes. Muitas vezes, os DBMSs tradicionais são mais adequados para a carga e, às vezes, a quantidade de dados é tão pequena que até a memória disponível seria suficiente para eles. Você sabia que pode comprar 1 TB de RAM em algum lugar por US $ 10.000? Mesmo se você tivesse um bilhão de usuários, ainda seria capaz de fornecer a cada um deles 1 KB de RAM.
Talvez isso não seja suficiente para a sua carga, porque você precisará ler e gravar no disco. Mas você realmente precisa de vários milhares de discos para ler e escrever? Aqui está a quantidade de dados que você tem de fato? O GFS e o MapReduce foram criados para resolver problemas de computação na Internet ... por exemplo, para recalcular o índice de pesquisa na Internet .
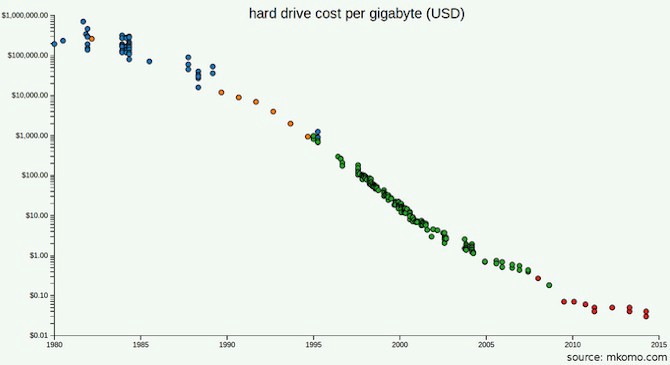
Os preços dos discos rígidos estão agora muito mais baixos do que em 2003, quando a documentação do GFS foi publicada.
Talvez você tenha lido a documentação do GFS e do MapReduce e percebido que um dos problemas do Google não era a quantidade de dados, mas a largura de banda (velocidade de processamento): eles usavam armazenamento distribuído porque demorava muito tempo para transferir bytes dos discos. Mas qual será a largura de banda dos dispositivos que você usará este ano? Como você nem precisa de tantos dispositivos quanto o Google precisa, seria melhor comprar apenas unidades mais modernas? Quanto vai custar para usar um SSD?
Talvez você queira considerar a escalabilidade antecipadamente. Você já fez todos os cálculos necessários? Você acumulará dados mais rapidamente do que os preços do SSD? Quantas vezes a sua empresa precisará crescer para que todos os dados disponíveis não caibam mais em um dispositivo? A partir de 2016, o Stack Exchange processava 200 milhões de consultas por dia com suporte para apenas 4 servidores SQL : o principal para Stack Overflow, mais um para todo o resto e duas cópias.
Novamente, você pode recorrer ao UNPHAT e ainda decidir usar o Hadoop ou Spark. E a decisão pode até estar certa. O principal é que você realmente usa a tecnologia certa para resolver seu problema . A propósito, isso é bem conhecido no Google: quando eles decidiram que o MapReduce não era adequado para indexação, eles pararam de usá-lo.
Primeiras coisas primeiro, entender o problema
Minha mensagem pode não ser algo novo, mas pode ser dessa forma que ela responderá a você ou talvez seja fácil lembrar da UNPHAT e aplicá-la na vida. Caso contrário, você poderá assistir ao discurso de Rich Hickey no Hammock Driven Development , ou no livro de Paul , How to Solve it , ou em Hamming , The Art of Doing Science and Engineering . Porque a principal coisa que todos pedimos é pensar!
E realmente entenda o problema que você está tentando resolver. Nas palavras inspiradoras de Paulo:
“ É tolice responder a uma pergunta que você não entende. É triste lutar por uma meta que você não deseja alcançar. "
Tradução para o russo
Tradução: Alexander Tregubov
Editado por Alexey Ivanov (@ponchiknews)
Comunidade: @ponchiknews
Figura: Equipe de conteúdo do LucidChart