Um bom serviço de reserva de táxi deve ser seguro, confiável e rápido. O usuário não entrará em detalhes: é importante que ele clique no botão Pedido e receba um carro o mais rápido possível, o que o levará do ponto A ao ponto B. Se não houver carros por perto, o serviço deve informar imediatamente sobre isso para que o cliente não evoluiu falsas expectativas. Mas se a placa “Sem carros” for exibida com muita frequência, é lógico que uma pessoa simplesmente pare de usar esse serviço e saia para um concorrente.
Neste artigo, quero falar sobre como, com a ajuda do aprendizado de máquina, resolvemos o problema de encontrar carros em um território com baixa densidade (em outras palavras, onde, à primeira vista, não há carros). E o que veio disso?
Antecedentes
Para chamar um táxi, o usuário dá alguns passos simples e o que acontece nas entranhas do serviço?
Sobre o
ETA no alfinete , já escrevemos o
cálculo do preço e a
escolha do driver mais adequado . E esta é uma história sobre como encontrar motoristas. Quando um pedido é criado, a pesquisa ocorre duas vezes: no alfinete e no pedido. A pesquisa no pedido ocorre em duas etapas: recrutamento de candidatos e classificação. Primeiro, existem motoristas candidatos gratuitos que acompanham o gráfico da estrada. Em seguida, os bônus e a filtragem são aplicados. Os candidatos restantes são classificados e o vencedor recebe uma oferta do pedido. Se ele concordar, é atribuído ao pedido e vai para o ponto de entrega. Se ele recusar, então a oferta chega à próxima. Se não houver mais candidatos, a pesquisa será iniciada novamente. Isso não dura mais de três minutos, após o qual o pedido é cancelado - esgotado.
A pesquisa no pino é semelhante à pesquisa no pedido, apenas o pedido não é criado e a pesquisa em si é realizada apenas uma vez. Além disso, são usadas configurações simplificadas para o número de candidatos e o raio da pesquisa. Tais simplificações são necessárias, porque há uma ordem de magnitude maior que pinos e a busca é uma operação bastante difícil.
O momento chave da nossa história: se durante a pesquisa preliminar no alfinete não havia candidatos adequados, não permitimos fazer um pedido. Pelo menos costumava ser.
Aqui está o que o usuário viu no aplicativo:
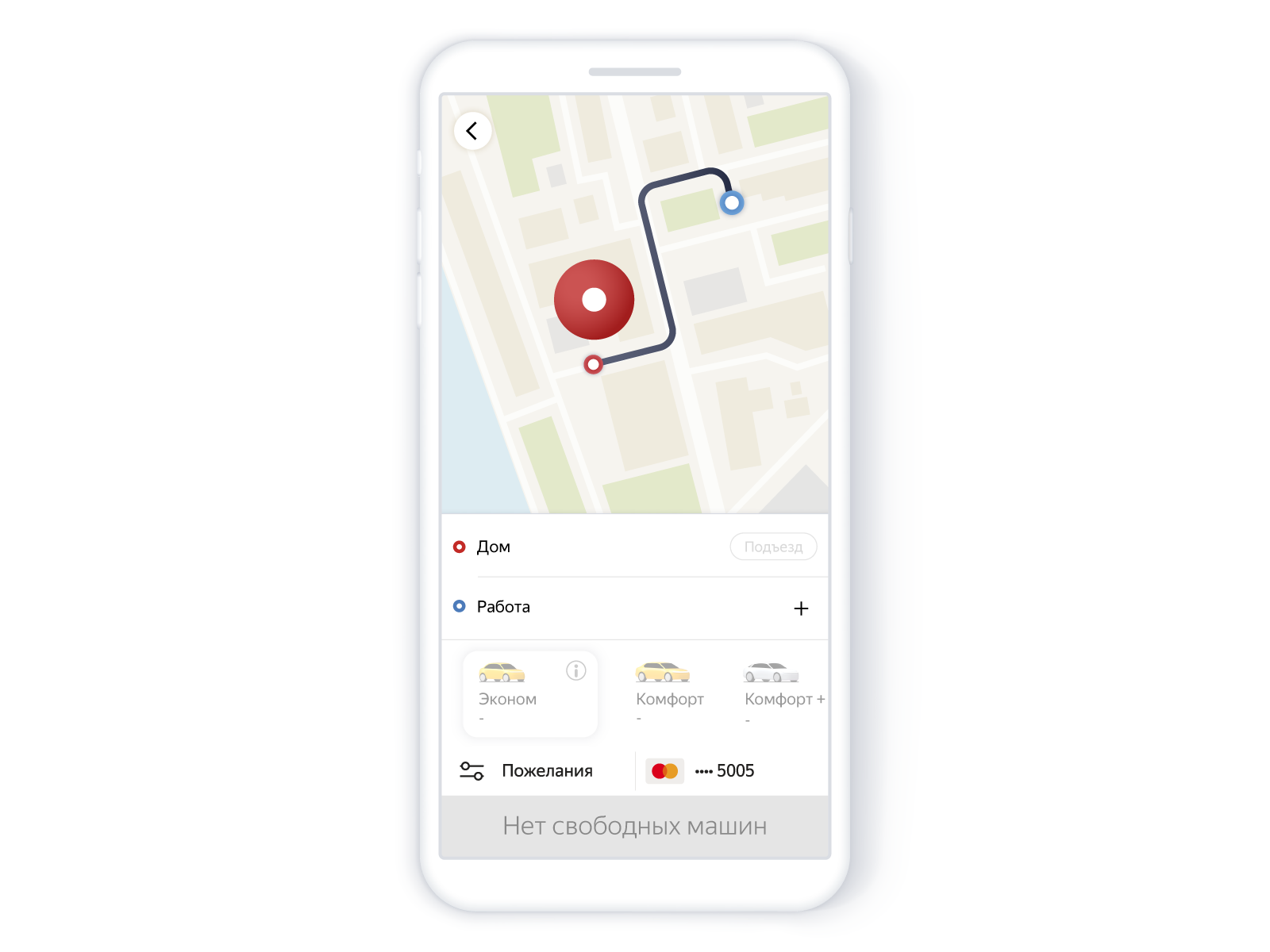
Procure carros sem carros
Uma vez que tivemos uma hipótese: talvez, em alguns casos, o pedido ainda possa ser concluído, mesmo que não houvesse carros no alfinete. De fato, passa algum tempo entre o pino e a ordem, e a pesquisa na ordem é mais completa e algumas vezes é repetida várias vezes: durante esse período, drivers gratuitos podem aparecer. Também sabíamos o contrário: se os drivers foram encontrados em um pino, não é fato que eles serão encontrados ao fazer o pedido. Às vezes eles desaparecem ou todos recusam o pedido.
Para testar essa hipótese, lançamos um experimento: paramos de verificar a presença de máquinas durante uma busca de pinos por um grupo de usuários de teste, ou seja, eles tiveram a oportunidade de fazer um “pedido sem máquinas”. O resultado foi bastante inesperado:
se o carro não estava no pino, em 29% dos casos foi mais tarde - ao procurar um pedido! Além disso, os pedidos sem carros não diferiram muito dos pedidos em termos de taxas de cancelamento, classificações e outros indicadores de qualidade. O número de pedidos sem carros foi de 5% de todos os pedidos, mas pouco mais de 1% de todas as viagens bem-sucedidas.
Para entender de onde vêm os executores dessas ordens, vejamos seus status durante a pesquisa no alfinete:
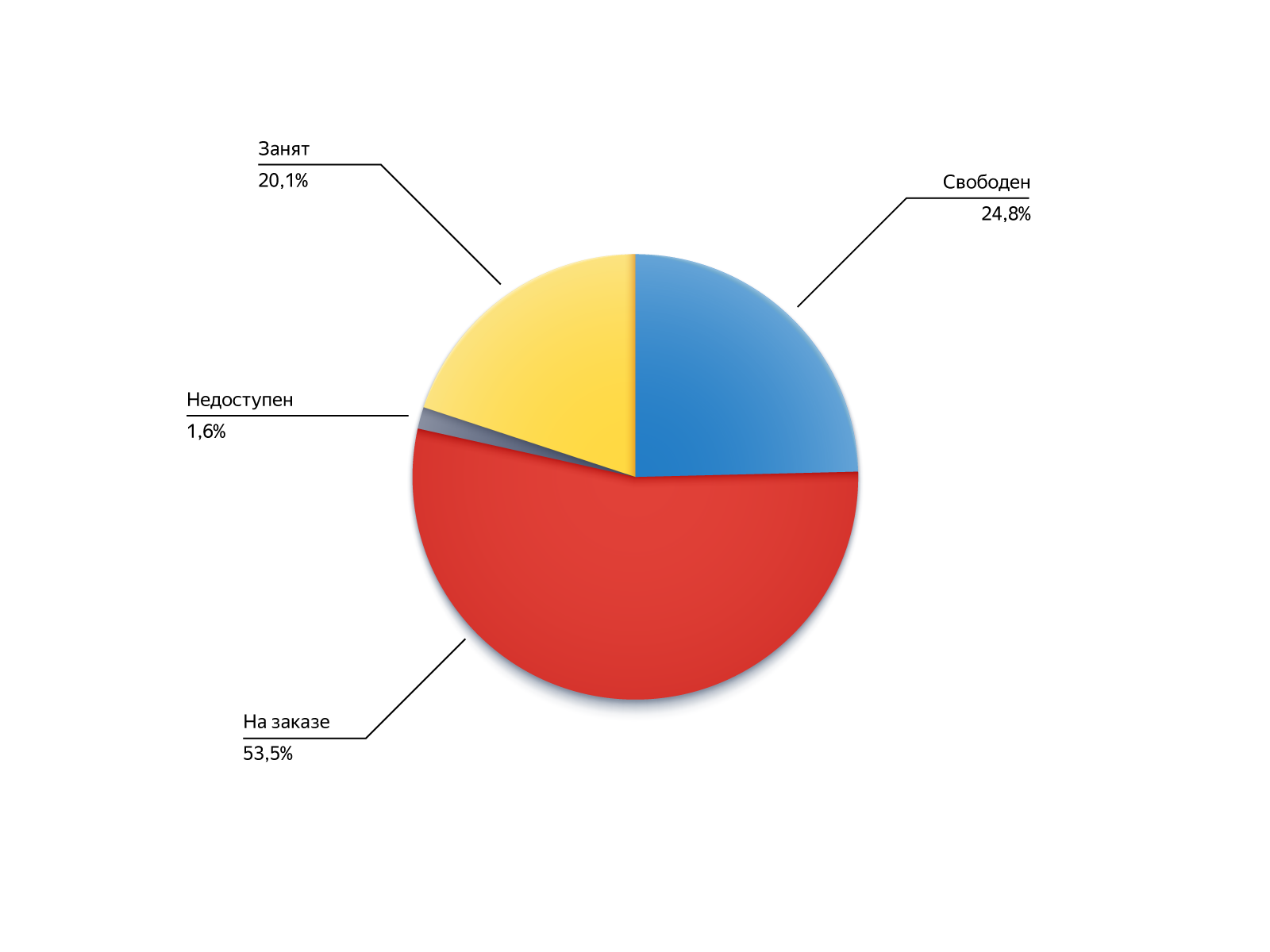
- Gratuito: estava disponível, mas por algum motivo não entrou nos candidatos, por exemplo, estava muito longe;
- No pedido: ele estava ocupado, mas conseguiu se libertar ou se tornar disponível para pedidos ao longo da cadeia ;
- Ocupado: a capacidade de receber pedidos foi desativada, mas o motorista retornou à fila;
- Não disponível: o motorista não estava online, mas ele apareceu.
Adicione confiabilidade
Pedidos adicionais são ótimos, mas 29% das pesquisas bem-sucedidas significam que em 71% dos casos o usuário está esperando há muito tempo e, como resultado, não sai de lugar nenhum. Embora, do ponto de vista da eficiência do sistema, isso não seja terrível, mas, na verdade, o usuário recebe uma falsa esperança e gasta tempo, após o que fica chateado e (possivelmente) para de usar o serviço. Para resolver esse problema, aprendemos a prever a probabilidade de uma máquina ser encontrada no pedido.
O esquema é o seguinte:
- O usuário coloca um alfinete.
- Procurando no alfinete.
- Se não houver carros, prevemos: talvez eles apareçam.
- E, dependendo da probabilidade, damos ou não um pedido, mas alertamos que a densidade de carros nessa área é pequena no momento.
No aplicativo, era assim:
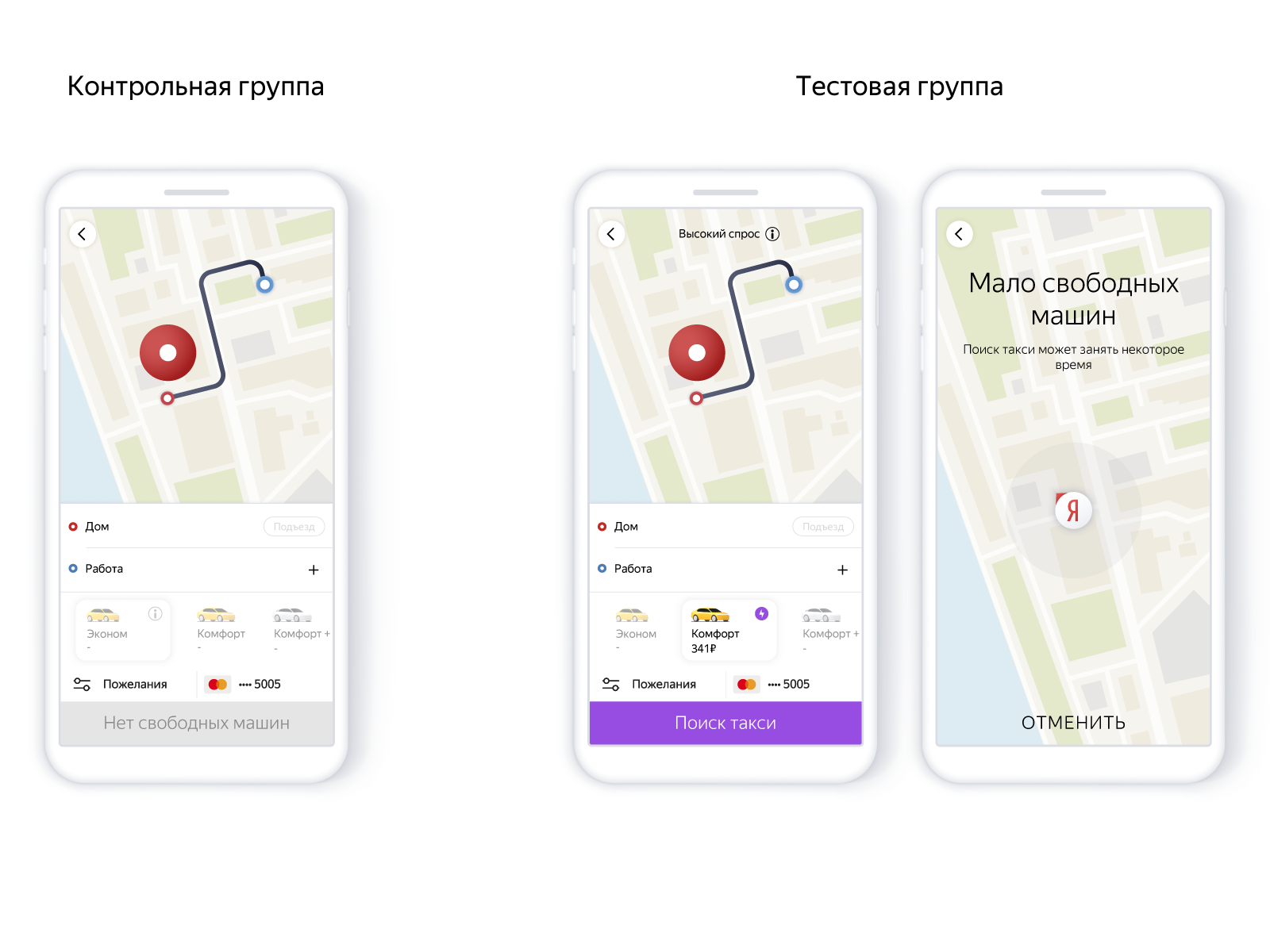
O uso do modelo permite criar novos pedidos com cuidado, para não tranquilizar uma pessoa em vão. Ou seja, para ajustar a taxa de confiabilidade e o número de pedidos sem máquinas usando o modelo de recall de precisão. A confiabilidade do serviço afeta o desejo de continuar usando o produto, ou seja, no final, tudo se resume ao número de viagens.
Um pouco sobre recall de precisãoUma das tarefas básicas do aprendizado de máquina é o problema de classificação: atribua um objeto a uma das duas classes. Nesse caso, o resultado da operação do algoritmo de aprendizado de máquina geralmente se torna uma estimativa numérica de pertencer a uma das classes, por exemplo, uma estimativa de probabilidade. No entanto, as ações executadas são geralmente binárias: se temos um carro, damos a ordem e, se não, então não. Por definição, chamamos o modelo de algoritmo que fornece uma classificação numérica e o classificador - uma regra que se refere a uma das duas classes (1 ou –1). Para fazer um classificador com base na avaliação do modelo, você precisa selecionar um limite de avaliação. Como exatamente - é altamente dependente da tarefa.
Suponha que façamos um teste (classificador) para alguma doença rara e perigosa. Com base nos resultados do teste, enviamos o paciente para um exame mais detalhado ou dizemos: "Saudável, vá para casa". Para nós, enviar uma pessoa doente para casa é muito pior do que examinar uma pessoa saudável em vão. Ou seja, queremos que o teste funcione para o maior número possível de pessoas doentes. Este valor é chamado recall =
. O recall ideal do classificador é 100%. Uma situação degenerada é enviar todos para exame, e a lembrança também será de 100%.
Isso acontece e vice-versa. Por exemplo, criamos um sistema de teste para estudantes e ele possui um detector de trapaça. Se de repente uma verificação não funcionar em alguns casos de trapaça, isso é desagradável, mas não crítico. Por outro lado, é extremamente ruim culpar injustamente os alunos pelo que eles não fizeram. Ou seja, é importante para nós que, dentre as respostas positivas do classificador, haja tantas respostas corretas quanto possível, possivelmente em detrimento de seu número. Então você precisa maximizar a precisão =
. Se as operações começarem a ocorrer em todos os objetos, a precisão será igual à frequência da classe determinada na amostra.
Se o algoritmo fornecer um valor numérico de probabilidade, escolhendo diferentes limites, você poderá obter valores diferentes de recuperação de precisão.
Em nossa tarefa, a situação é a seguinte. Lembre-se é o número de pedidos que podemos oferecer, a precisão é a confiabilidade desses pedidos. Aqui está a curva de precisão de recuperação do nosso modelo:
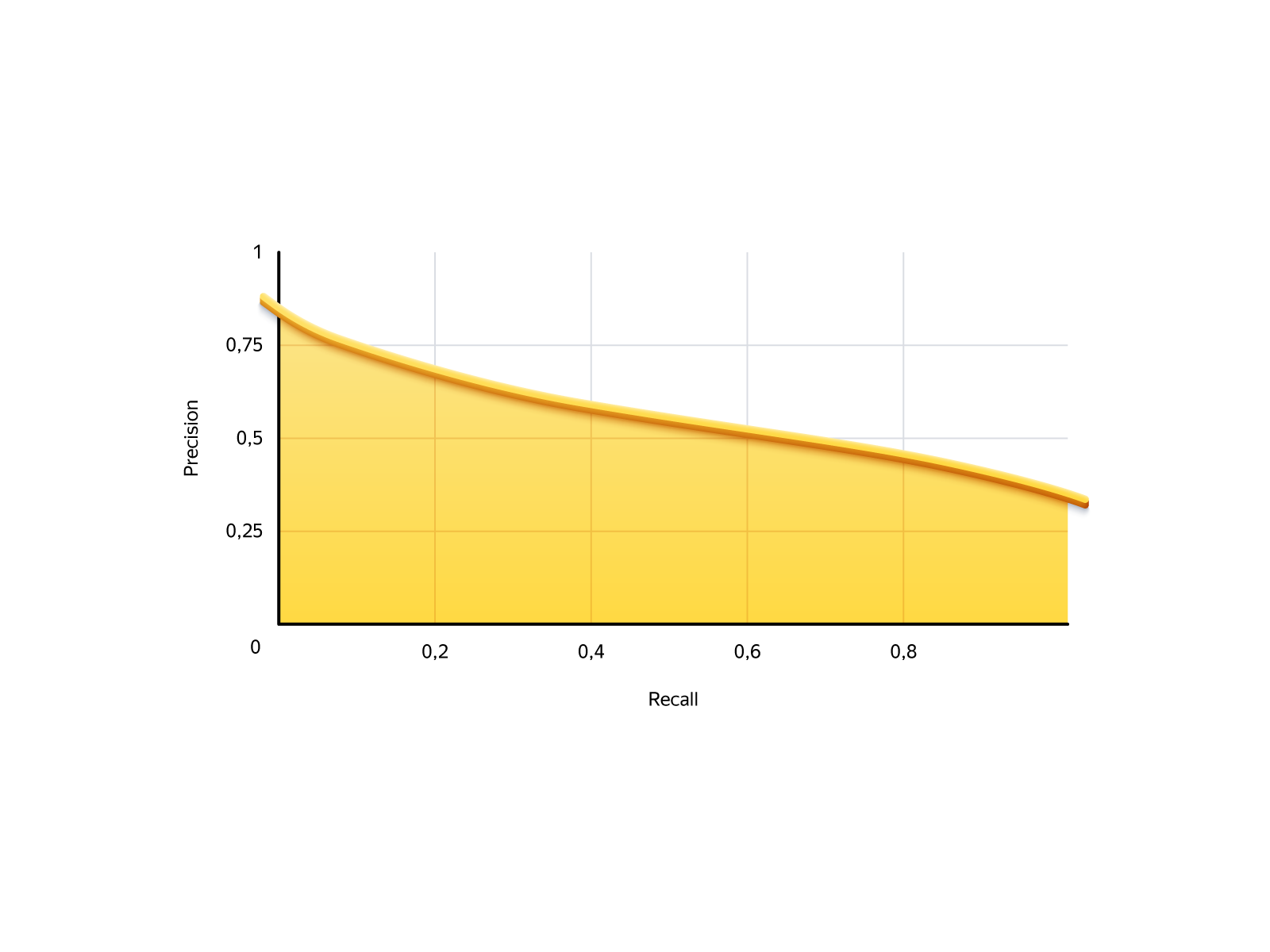
Existem dois casos extremos: não permita que ninguém solicite e permita que todos solicitem. Se você não permitir ninguém, o recall será 0: não criamos pedidos, mas nenhum deles falhará. Se você permitir a todos, o recall será de 100% (receberemos todos os pedidos possíveis) e precisão - 29%, ou seja, 71% dos pedidos serão ruins.
Como sinais, usamos vários parâmetros do ponto de partida:
- Hora / local.
- Status do sistema (número de carros ocupados de todas as tarifas e pinos nas proximidades).
- Parâmetros de pesquisa (raio, número de candidatos, restrições).
Detalhes sobre os sintomas
Conceitualmente, queremos distinguir entre duas situações:
- "Floresta morta" - não há carros aqui no momento.
- "Azarado" - existem carros, mas não havia carros adequados ao pesquisar.
Um exemplo de "azarado" é se houver alta demanda no centro na sexta-feira à noite. Existem muitos pedidos, muitos querem muito, não há motoristas suficientes. Pode acontecer desta maneira: não há drivers adequados no pino. Mas, literalmente, em segundos eles aparecem, porque neste momento há muitos drivers e seu status muda constantemente.
Portanto, vários recursos do sistema nas proximidades do ponto A acabaram sendo bons:
- O número total de carros.
- O número de carros no pedido.
- O número de máquinas indisponíveis para pedido no status "Ocupado".
- O número de usuários.
Afinal, quanto mais carros existem, maior a probabilidade de que algum deles fique disponível.
De fato, é importante para nós não apenas ter carros, mas também fazer viagens bem-sucedidas. Portanto, foi possível prever a probabilidade de uma viagem bem-sucedida. Mas decidimos não fazer isso, porque esse valor é altamente dependente do usuário e do driver.
O CatBoost foi usado como algoritmo de aprendizado de modelo. Para o treinamento, usamos os dados obtidos no experimento. Após a implementação, foi necessário coletar dados de treinamento, às vezes permitindo que um pequeno número de usuários fizesse um pedido contrário à decisão do modelo.
Sumário
Os resultados do experimento foram esperados: o uso do modelo permite aumentar significativamente o número de viagens bem-sucedidas devido a pedidos sem carros, mas ao mesmo tempo não reduzir a confiabilidade.
No momento, o mecanismo é lançado em todas as cidades e países e, com ele, cerca de 1% das viagens bem-sucedidas ocorrem. Além disso, em algumas cidades com baixa densidade de carros, a participação dessas viagens chega a 15%.
Outras publicações sobre tecnologia de táxi