Erros e software andavam de mãos dadas desde o início da era da programação de computadores. Com o tempo, os desenvolvedores desenvolveram um conjunto de práticas para programas de teste e depuração antes de serem implantadas, mas essas práticas não são mais adequadas para sistemas modernos com aprendizado profundo. Hoje, a principal prática no campo do aprendizado de máquina pode ser chamada de treinamento em um conjunto de dados específico, seguido de verificação em outro conjunto. Dessa forma, você pode calcular a eficiência média dos modelos, mas também é importante garantir confiabilidade, ou seja, eficiência aceitável no pior dos casos. Neste artigo, descrevemos três abordagens para identificar e eliminar com precisão os erros em modelos preditivos treinados: teste de adversidade, aprendizado robusto e
verificação formal .
Sistemas com MOs não são, por definição, estáveis. Mesmo sistemas que vencem uma pessoa em uma determinada área podem não ser capazes de lidar com a solução de problemas simples ao fazer diferenças sutis. Por exemplo, considere o problema de perturbar imagens: uma rede neural que pode classificar imagens melhor do que as pessoas pode facilmente fazer com que acredite que a preguiça é um carro de corrida, adicionando uma pequena fração do ruído cuidadosamente calculado à imagem.
 A entrada competitiva quando sobreposta a uma imagem regular pode confundir a IA. Duas imagens extremas diferem em não mais que 0,0078 para cada pixel. O primeiro é classificado como preguiça, com uma probabilidade de 99%. O segundo é como um carro de corrida com 99% de probabilidade.
A entrada competitiva quando sobreposta a uma imagem regular pode confundir a IA. Duas imagens extremas diferem em não mais que 0,0078 para cada pixel. O primeiro é classificado como preguiça, com uma probabilidade de 99%. O segundo é como um carro de corrida com 99% de probabilidade.Este problema não é novo. Os programas sempre tiveram erros. Durante décadas, os programadores vêm ganhando uma variedade impressionante de técnicas, desde testes de unidade até verificação formal. Nos programas tradicionais, esses métodos funcionam bem, mas a adaptação dessas abordagens para testes rigorosos dos modelos MO é extremamente difícil devido à escala e falta de estrutura nos modelos que podem conter centenas de milhões de parâmetros. Isso sugere a necessidade de desenvolver novas abordagens para garantir a confiabilidade dos sistemas MO.
Do ponto de vista do programador, um bug é qualquer comportamento que não atenda às especificações, ou seja, a funcionalidade planejada do sistema. Como parte de nossa pesquisa de IA, estamos estudando técnicas para avaliar se os sistemas MO atendem aos requisitos não apenas nos conjuntos de treinamento e teste, mas também na lista de especificações que descrevem as propriedades desejadas do sistema. Entre essas propriedades, pode haver resistência a mudanças razoavelmente pequenas nos dados de entrada, restrições de segurança que evitam falhas catastróficas ou conformidade das previsões com as leis da física.
Neste artigo, discutiremos três questões técnicas importantes que a comunidade MO enfrenta ao trabalhar para tornar os sistemas MO robustos e atender de forma confiável às especificações desejadas:
- Verificação efetiva da conformidade com as especificações. Estamos estudando maneiras eficazes de verificar se os sistemas MO correspondem às suas propriedades (por exemplo, estabilidade e invariância) exigidas pelo desenvolvedor e pelos usuários. Uma abordagem para encontrar casos em que um modelo pode se afastar dessas propriedades é procurar sistematicamente os piores resultados do trabalho.
- Treinamento de modelos MO de acordo com as especificações. Mesmo se houver uma quantidade suficientemente grande de dados de treinamento, os algoritmos MO padrão podem produzir modelos preditivos cuja operação não atende às especificações desejadas. Somos obrigados a revisar os algoritmos de treinamento para que eles não apenas funcionem bem nos dados de treinamento, mas também atendam às especificações desejadas.
- Prova formal da conformidade dos modelos MO com as especificações desejadas. Algoritmos devem ser desenvolvidos para confirmar que o modelo atende às especificações desejadas para todos os dados de entrada possíveis. Embora o campo da verificação formal tenha estudado esses algoritmos por várias décadas, apesar de seu progresso impressionante, essas abordagens não são fáceis de dimensionar para os sistemas modernos de MO.
Verifique a conformidade do modelo com as especificações desejadas
A resistência a exemplos competitivos é um problema bastante bem estudado de defesa civil. Uma das principais conclusões feitas é a importância de avaliar as ações da rede como resultado de ataques fortes e o desenvolvimento de modelos transparentes que podem ser analisados com bastante eficácia. Juntamente com outros pesquisadores, descobrimos que muitos modelos são resistentes a exemplos fracos e competitivos. No entanto, eles fornecem quase 0% de precisão para exemplos competitivos mais fortes (
Athalye et al., 2018 ;
Uesato et al., 2018 ;
Carlini e Wagner, 2017 ).
Embora a maior parte do trabalho se concentre em falhas raras no contexto do ensino com um professor (e isso é principalmente uma classificação de imagens), é necessário expandir a aplicação dessas idéias para outras áreas. Em um trabalho recente com uma abordagem competitiva para encontrar falhas catastróficas, aplicamos essas idéias para testar redes treinadas com reforço e projetadas para serem usadas em locais com altos requisitos de segurança. Um dos desafios do desenvolvimento de sistemas autônomos é que, como um erro pode ter sérias conseqüências, mesmo uma pequena probabilidade de falha não é considerada aceitável.
Nosso objetivo é projetar um "rival" que ajude a reconhecer esses erros antecipadamente (em um ambiente controlado). Se um adversário puder efetivamente determinar os piores dados de entrada para um determinado modelo, isso nos permitirá capturar casos raros de falhas antes de implantá-lo. Assim como acontece com os classificadores de imagem, avaliar como trabalhar com um oponente fraco fornece uma falsa sensação de segurança durante a implantação. Essa abordagem é semelhante ao desenvolvimento de software com a ajuda da "equipe vermelha" [equipe vermelha - envolvendo uma equipe de desenvolvimento de terceiros que assume o papel de atacantes para detectar vulnerabilidades / aprox. transl.], no entanto, vai além da busca por falhas causadas por invasores e também inclui erros que ocorrem naturalmente, por exemplo, devido à generalização insuficiente.
Desenvolvemos duas abordagens complementares para testes competitivos de redes de aprendizado reforçadas. No primeiro, usamos a otimização sem derivativos para minimizar diretamente a recompensa esperada. No segundo, aprendemos uma função de valor contraditório, que por experiência prevê em quais situações a rede pode falhar. Em seguida, usamos essa função aprendida para otimização, concentrando-nos na avaliação dos dados de entrada mais problemáticos. Essas abordagens formam apenas uma pequena parte do espaço rico e crescente de algoritmos em potencial, e estamos muito interessados no desenvolvimento futuro dessa área.
Ambas as abordagens já estão mostrando melhorias significativas em relação aos testes aleatórios. Usando nosso método, em alguns minutos é possível detectar falhas que antes tinham que ser pesquisadas durante todo o dia ou talvez não pudessem ser encontradas (
Uesato et al., 2018b ). Também descobrimos que os testes contraditórios podem revelar um comportamento qualitativamente diferente das redes em comparação com o que seria esperado de uma avaliação em um conjunto de testes aleatórios. Em particular, usando nosso método, descobrimos que as redes que executavam a tarefa de orientação em um mapa tridimensional, e geralmente lidam com isso no nível humano, não conseguem encontrar o alvo em labirintos inesperadamente simples (
Ruderman et al., 2018 ). Nosso trabalho também enfatiza a necessidade de projetar sistemas seguros contra falhas naturais, e não apenas rivais.
 Ao realizar testes em amostras aleatórias, quase nunca vemos cartões com alta probabilidade de falha, mas testes competitivos mostram a existência desses cartões. A probabilidade de falha permanece alta mesmo após a remoção de muitas paredes, ou seja, simplificação de mapas em comparação com os originais.
Ao realizar testes em amostras aleatórias, quase nunca vemos cartões com alta probabilidade de falha, mas testes competitivos mostram a existência desses cartões. A probabilidade de falha permanece alta mesmo após a remoção de muitas paredes, ou seja, simplificação de mapas em comparação com os originais.Treinamento do modelo de especificação
Testes competitivos tentam encontrar um contra-exemplo que viole as especificações. Muitas vezes, superestima a consistência dos modelos com essas especificações. Do ponto de vista matemático, a especificação é um tipo de relacionamento que deve ser mantido entre os dados de entrada e saída da rede. Pode assumir a forma de um limite superior e inferior ou alguns dos principais parâmetros de entrada e saída.
Inspirados por essa observação, vários pesquisadores (
Raghunathan et al., 2018 ;
Wong et al., 2018 ;
Mirman et al., 2018 ;
Wang et al., 2018 ), incluindo nossa equipe da DeepMind (
Dvijotham et al., 2018 ;
Gowal et al., 2018 ), trabalharam em algoritmos invariantes a testes competitivos. Isso pode ser descrito geometricamente - podemos limitar (
Ehlers 2017 ,
Katz et al. 2017 ,
Mirman et al., 2018 ) a pior violação de especificação, limitando o espaço de dados de saída com base em um conjunto de entradas. Se esse limite for diferenciável por parâmetros de rede e puder ser calculado rapidamente, ele poderá ser usado durante o treinamento. Em seguida, o limite original pode se propagar através de cada camada da rede.
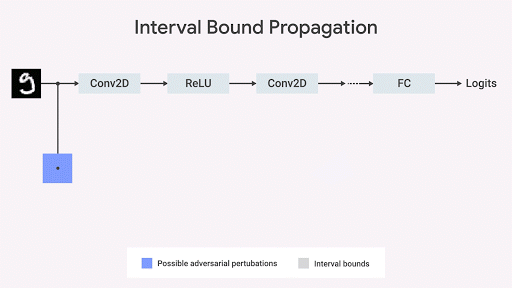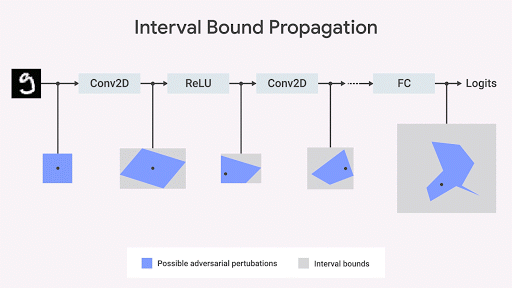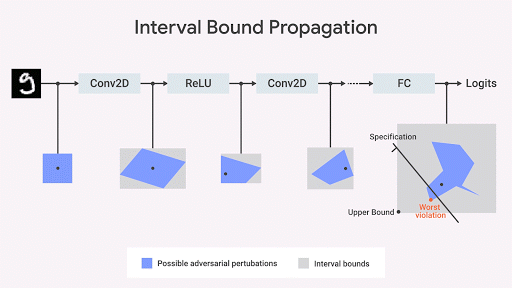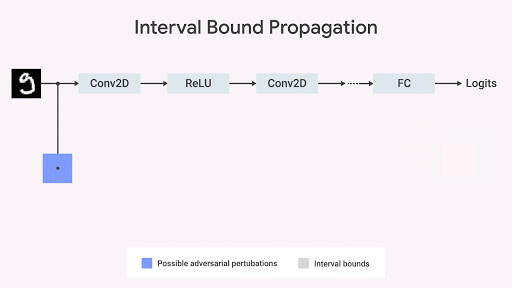
Mostramos que a propagação da fronteira do intervalo é rápida, eficiente e - ao contrário do que se pensava anteriormente - fornece bons resultados (
Gowal et al., 2018 ). Em particular, mostramos que é possível reduzir o número de erros (isto é, o número máximo de erros que qualquer oponente pode causar) em comparação com os classificadores de imagem mais avançados em conjuntos dos bancos de dados MNIST e CIFAR-10.
O próximo objetivo será estudar as abstrações geométricas corretas para calcular aproximações excessivas do espaço de saída. Também queremos treinar redes para que funcionem de maneira confiável com especificações mais complexas que descrevam o comportamento desejado, como a invariância mencionada anteriormente e a conformidade com as leis físicas.
Verificação formal
Testes e treinamentos completos podem ser de grande ajuda na criação de sistemas MO confiáveis. No entanto, testes formalmente arbitrariamente volumosos não podem garantir que o comportamento do sistema corresponda aos nossos desejos. Em modelos de grande escala, enumerar todas as opções de saída possíveis para um determinado conjunto de entradas (por exemplo, pequenas alterações na imagem) parece difícil de implementar devido ao número astronômico de possíveis alterações na imagem. No entanto, como no caso do treinamento, pode-se encontrar abordagens mais eficazes para definir restrições geométricas no conjunto de dados de saída. A verificação formal é objeto de pesquisa em andamento no DeepMind.
A comunidade MO desenvolveu algumas idéias interessantes para calcular os limites geométricos exatos do espaço de saída da rede (Katz et al. 2017,
Weng et al., 2018 ;
Singh et al., 2018 ). Nossa abordagem (
Dvijotham et al., 2018 ), baseada em otimização e dualidade, consiste em formular o problema de verificação em termos de otimização, que está tentando encontrar a maior violação da propriedade que está sendo testada. A tarefa se torna computável se idéias da dualidade são usadas na otimização. Como resultado, obtemos restrições adicionais que especificam os limites calculados ao mover o limite do intervalo [propagação do limite do intervalo] usando os chamados planos de corte. Essa é uma abordagem confiável, mas incompleta: pode haver casos em que a propriedade de nosso interesse é satisfeita, mas o limite calculado por esse algoritmo não é suficientemente rígido para que a presença dessa propriedade possa ser formalmente comprovada. No entanto, tendo recebido a fronteira, obtemos uma garantia formal da ausência de violações dessa propriedade. Na fig. Abaixo desta abordagem é ilustrada graficamente.

Essa abordagem nos permite expandir a aplicabilidade dos algoritmos de verificação em redes de uso geral (funções de ativador, arquiteturas), especificações gerais e modelos GO mais complexos (modelos generativos, processos neurais etc.) e especificações que vão além da confiabilidade competitiva (
Qin , 2018 ).
Perspectivas
A implantação de MOs em situações de alto risco tem seus próprios desafios e dificuldades, e isso requer o desenvolvimento de tecnologias de avaliação que garantem a detecção de erros improváveis. Acreditamos que o treinamento consistente em especificações pode melhorar significativamente o desempenho em comparação com os casos em que as especificações surgem implicitamente dos dados de treinamento. Esperamos ansiosamente os resultados de estudos de avaliação competitiva em andamento, modelos de treinamento robustos e verificação de especificações formais.
Muito mais trabalho será necessário para que possamos criar ferramentas automatizadas que garantam que os sistemas de IA no mundo real "façam tudo certo". Em particular, estamos muito satisfeitos por progredir nas seguintes áreas:
- Treinamento para avaliação e verificação competitivas. Com o dimensionamento e a complicação dos sistemas de IA, está se tornando cada vez mais difícil projetar algoritmos competitivos de avaliação e verificação que sejam suficientemente adaptados ao modelo de IA. Se pudermos usar todo o poder da IA para avaliação e verificação, esse processo poderá ser escalado.
- Desenvolvimento de ferramentas publicamente disponíveis para avaliação e verificação competitivas: é importante fornecer aos engenheiros e outras pessoas que usam AI IA ferramentas fáceis de usar que lançam luz sobre os possíveis modos de falha do sistema de IA antes que essa falha leve a extensas consequências negativas. Isso exigirá alguma padronização de avaliações competitivas e algoritmos de verificação.
- Expandir o espectro de exemplos competitivos. Até o momento, grande parte do trabalho em exemplos competitivos se concentrou na estabilidade dos modelos a pequenas mudanças, geralmente na área da imagem. Isso se tornou um excelente campo de teste para o desenvolvimento de abordagens para avaliações competitivas, treinamento e verificação confiáveis. Começamos a estudar várias especificações para propriedades diretamente relacionadas ao mundo real, e estamos ansiosos pelos resultados de pesquisas futuras nessa direção.
- Especificações de treinamento. As especificações que descrevem o comportamento "correto" dos sistemas de IA costumam ser difíceis de formular com precisão. À medida que criamos sistemas cada vez mais inteligentes capazes de comportamento complexo e trabalhamos em um ambiente não estruturado, precisaremos aprender a criar sistemas que possam usar especificações parcialmente formuladas e obter especificações adicionais a partir do feedback.
A DeepMind está comprometida com o impacto positivo na sociedade através do desenvolvimento e implantação responsáveis de sistemas MO. Para garantir que a contribuição dos desenvolvedores seja positiva, precisamos lidar com muitos obstáculos técnicos. Pretendemos contribuir com essa área e estamos felizes em trabalhar com a comunidade para resolver esses problemas.