
O RabbitMQ é um intermediário de mensagens escrito em Erlang que permite organizar um cluster de failover com replicação completa de dados para vários nós, onde cada nó pode atender a solicitações de leitura e gravação. Com muitos clusters Kubernetes em produção, suportamos um grande número de instalações RabbitMQ e somos confrontados com a necessidade de migrar dados de um cluster para outro sem tempo de inatividade.
Essa operação foi necessária para nós em pelo menos dois casos:
- Transferindo dados de um cluster RabbitMQ, que não está no Kubernetes, para um novo cluster que já está "desligado" (ou seja, funcionando nos pods K8s).
- Migração do RabbitMQ no Kubernetes de um espaço para nome (por exemplo, se os caminhos forem delimitados por espaços para nome, transfira a infraestrutura de um caminho para outro).
A receita proposta neste artigo é focada em situações (mas não limitadas a elas), nas quais existe um cluster RabbitMQ antigo (por exemplo, de 3 nós), localizado nos K8s ou em alguns servidores antigos. Um aplicativo hospedado no Kubernetes trabalha com ele (já existe ou no futuro):

... e enfrentamos o desafio de migrá-lo para uma nova produção em Kubernetes.
Primeiro, será descrita uma abordagem geral da própria migração e, depois disso, detalhes técnicos de sua implementação.
Algoritmo de migração
A primeira etapa preliminar antes de qualquer ação é verificar se o modo de alta disponibilidade (
HA ) está ativado na instalação antiga do RabbitMQ. O motivo é óbvio - não queremos perder nenhum dado. Para executar essa verificação, você pode ir ao painel de administração do RabbitMQ e, na guia Admin → Políticas, verifique se o valor
ha-mode: all :

O próximo passo é criar um novo cluster RabbitMQ nos pods do Kubernetes (no nosso caso, por exemplo, consistindo em 3 nós, mas seu número pode ser diferente).
Depois disso, mesclamos os clusters RabbitMQ antigos e novos, obtendo um único cluster (de 6 nós):
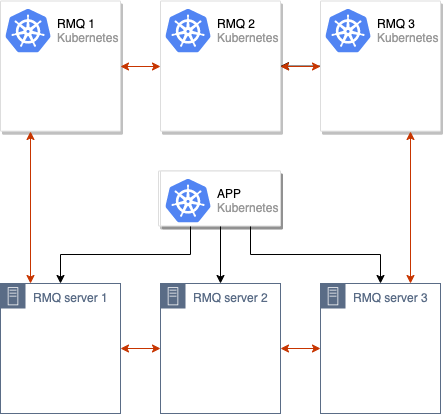
O processo de sincronização de dados entre os clusters RabbitMQ antigos e novos é iniciado. Depois que todos os dados são sincronizados entre todos os nós no cluster, podemos alternar o aplicativo para usar o novo cluster:
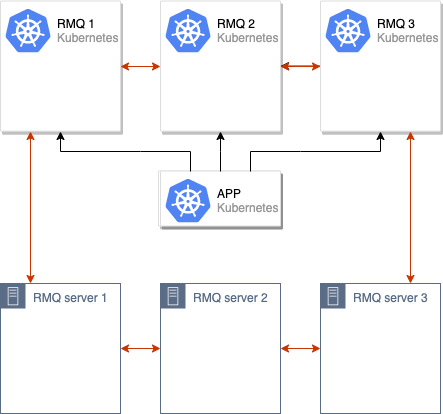
Após essas operações, é suficiente remover os nós antigos do cluster RabbitMQ e a movimentação pode ser considerada concluída:

Usamos repetidamente esse esquema em nossa produção. No entanto, para sua própria conveniência, o implementamos no âmbito de um sistema especializado que distribui configurações típicas de RMQ em conjuntos de clusters Kubernetes
(para quem está curioso: estamos falando de addon-operator , sobre o qual falamos recentemente ) . A seguir, são apresentadas instruções individuais que qualquer pessoa pode aplicar em suas instalações para experimentar a solução proposta em ação.
Tentamos na prática
Exigências
Os detalhes são muito simples:
- Cluster Kubernetes (o minikube também é adequado);
- Cluster RabbitMQ (pode ser implantado no bare metal e criado como um cluster regular no Kubernetes a partir do gráfico oficial do Helm).
Para o exemplo descrito abaixo, implantei o RMQ no Kubernetes e o nomeei
rmq-old .
Preparação do estande
1. Faça o download do gráfico Helm e edite-o um pouco:
helm fetch --untar stable/rabbitmq-ha
Por conveniência, definimos uma senha,
ErlangCookie e definimos a política
ha-all para que, por padrão, as filas sejam sincronizadas entre todos os nós do cluster RMQ:
rabbitmqPassword: guest rabbitmqErlangCookie: mae9joopaol7aiVu3eechei2waiGa2we definitions: policies: |- { "name": "ha-all", "pattern": ".*", "vhost": "/", "definition": { "ha-mode": "all", "ha-sync-mode": "automatic", "ha-sync-batch-size": 81920 } }
2. Defina o gráfico:
helm install . --name rmq-old --namespace rmq-old
3. Vá para o painel de administração do RabbitMQ, crie uma nova fila e adicione algumas mensagens. Eles serão necessários para que, após a migração, possamos garantir que todos os dados foram salvos e que não perdemos nada:

A bancada de testes está pronta: temos o RabbitMQ "antigo" com os dados que precisam ser transferidos.
Migração de Cluster RabbitMQ
1. Primeiro, implante o novo RabbitMQ em um espaço para nome
diferente com
o mesmo ErlangCookie e senha para o usuário. Para fazer isso, executamos as operações descritas acima, alterando o comando de instalação RMQ final para o seguinte:
helm install . --name rmq-new --namespace rmq-new
2. Agora você precisa mesclar o novo cluster com o antigo. Para fazer isso, vá para cada um dos pods do
novo RabbitMQ e execute os comandos:
export OLD_RMQ=rabbit@rmq-old-rabbitmq-ha-0.rmq-old-rabbitmq-ha-discovery.rmq-old.svc.cluster.local && \ rabbitmqctl stop_app && \ rabbitmqctl join_cluster $OLD_RMQ && \ rabbitmqctl start_app
A variável
OLD_RMQ endereço de um dos nós do cluster RMQ
antigo .
Esses comandos irão parar o nó atual do
novo cluster RMQ, conectá-lo ao cluster antigo e reiniciá-lo.
3. O cluster RMQ de 6 nós está pronto:

Você deve esperar até que as mensagens sejam sincronizadas entre todos os nós. É fácil adivinhar que o tempo de sincronização das mensagens depende da potência do ferro no qual o cluster está implantado e do número de mensagens. No cenário descrito, existem apenas 10 deles, portanto os dados foram sincronizados instantaneamente, mas com um número suficientemente grande de mensagens, a sincronização pode levar horas.
Portanto, o status da sincronização:

Aqui,
+5 significa que as mensagens
já estão em
outros 5 nós (exceto o que é especificado no campo
Node ). Assim, a sincronização foi bem sucedida.
4. Resta apenas mudar o endereço RMQ no aplicativo para o novo cluster (as ações específicas aqui dependem da pilha de tecnologia que você está usando e de outros detalhes do aplicativo), após o qual você pode se despedir do antigo.
Para a última operação (ou seja,
depois de alternar o aplicativo para um novo cluster), vamos a cada nó do cluster
antigo e executamos os comandos:
rabbitmqctl stop_app rabbitmqctl reset
O cluster "esqueceu" os nós antigos: é possível excluir o RMQ antigo, que concluirá a movimentação.
Nota : Se você usar o RMQ com certificados, basicamente nada mudará - o processo de mudança será realizado exatamente da mesma maneira.Conclusões
O esquema descrito é adequado para quase todos os casos em que precisamos transferir o RabbitMQ ou simplesmente mudar para um novo cluster.
No nosso caso, as dificuldades ocorreram apenas uma vez, quando o RMQ foi acessado de muitos lugares, e não tivemos a oportunidade de alterar o endereço do RMQ para um novo. Em seguida, lançamos um novo RMQ no mesmo namespace com os mesmos rótulos, para que ele se enquadrasse nos serviços e no ingresso existentes e, quando iniciamos o pod, manipulamos os rótulos com as mãos, excluindo-os no início, para que as solicitações não caíssem em um RMQ vazio, e adicionando-os novamente após a sincronização da mensagem.
Usamos a mesma estratégia ao atualizar o RabbitMQ para uma nova versão com uma configuração modificada - tudo funcionava como um relógio.
PS
Como continuação lógica deste material, estamos preparando artigos sobre o MongoDB (migração de um servidor iron para o Kubernetes) e o MySQL (uma das opções para "preparar" este DBMS no Kubernetes). Eles serão publicados nos próximos meses.
PPS
Leia também em nosso blog: