
Descriptografia da 2ª parte do Tesla Autonomy Investor Day. Ciclo de treinamento do piloto automático, infraestrutura de coleta de dados, identificação automática de dados, imitação de drivers humanos, detecção de distância de vídeo, supervisão de sensor e muito mais.A primeira parte é o desenvolvimento do Full Self-Driving Computer (FSDC) .Anfitrião: O FSDC pode trabalhar com redes neurais muito complexas para processamento de imagens. É hora de falar sobre como obtemos imagens e como as analisamos. Temos um diretor sênior de IA da Tesla, Andrei Karpaty, que explicará tudo isso a você.
Andrei: Treino em redes neurais há cerca de dez anos e agora há 5-6 anos para uso industrial. Incluindo instituições conhecidas como Stanford, Open AI e Google. Esse conjunto de redes neurais não é apenas para processamento de imagens, mas também para linguagem natural. Projetei arquiteturas que combinam essas duas modalidades para minha tese de doutorado.
Em Stanford, ministrei um curso sobre redes neurais deconvolucionárias. Eu era o professor principal e desenvolvi todo o currículo para ele. No começo, eu tinha cerca de 150 alunos. Nos dois ou três anos seguintes, o número de alunos aumentou para 700. Este é um curso muito popular, um dos maiores e mais bem-sucedidos cursos de Stanford no momento.
Ilon: Andrey é realmente um dos melhores especialistas em visão de máquina do mundo. Talvez o melhor.
Andrew: Obrigado. Olá pessoal. Pete falou sobre um chip que desenvolvemos especificamente para redes neurais em um carro. Minha equipe é responsável por treinar essas redes neurais. Isso inclui coleta de dados, treinamento e, em parte, implantação.
O que as redes neurais em um carro fazem. Existem oito câmeras no carro que gravam vídeo. As redes neurais assistem a esses vídeos, os processam e fazem previsões sobre o que veem. Estamos interessados em marcações nas estradas, participantes no trânsito, outros objetos e suas distâncias, estradas, semáforos, sinais de trânsito etc.

Minha apresentação pode ser dividida em três partes. Primeiro, apresentarei brevemente as redes neurais e como elas funcionam e como são treinadas. Isso deve ser feito para que, na segunda parte, fique claro por que é tão importante que tenhamos uma enorme frota de carros Tesla (frota). Por que esse é um fator chave no treinamento de redes neurais que funcionam eficientemente na estrada? Na terceira parte, falarei sobre visão de máquina, lidar e como estimar a distância usando apenas vídeo.
Como as redes neurais funcionam?
(Não há muito novo aqui, você pode pular e ir para o próximo título)A principal tarefa que as redes resolvem no carro é o reconhecimento de padrões. Para nós, humanos, essa é uma tarefa muito simples. Você olha as imagens e vê um violoncelo, barco, iguana ou tesoura. Muito fácil e simples para você, mas não para o computador. O motivo é que essas imagens de computador são apenas uma matriz de pixels, em que cada pixel é o valor de brilho nesse ponto. Em vez de apenas ver a imagem, o computador recebe um milhão de números em uma matriz.
Ilon: Matrix, se você quiser. Realmente matriz.
 Andrew:
Andrew: Sim. Precisamos passar dessa grade de pixels e valores de brilho para conceitos de nível superior, como iguana e assim por diante. Como você pode imaginar, esta imagem de uma iguana possui um padrão de brilho específico. Mas as iguanas podem ser representadas de diferentes maneiras, em diferentes poses, em diferentes condições de iluminação, em um fundo diferente. Você pode encontrar muitas imagens diferentes da iguana e devemos reconhecê-la em qualquer condição.
A razão pela qual você e eu podemos lidar facilmente com isso é que temos uma enorme rede neural dentro que processa imagens. A luz entra na retina e é enviada para a parte posterior do cérebro, para o córtex visual. O córtex cerebral consiste em muitos neurônios que estão conectados entre si e realizam o reconhecimento de padrões.
Nos últimos cinco anos, abordagens modernas para processamento de imagens usando computadores também começaram a usar redes neurais, mas, neste caso, redes neurais artificiais. As redes neurais artificiais são uma aproximação matemática grosseira do córtex visual. Também há neurônios aqui, eles estão conectados um ao outro. Uma rede neural típica inclui dezenas ou centenas de milhões de neurônios, e cada neurônio possui milhares de links.
Podemos pegar uma rede neural e mostrar imagens, como a nossa iguana, e a rede fará uma previsão. Primeiro, as redes neurais são inicializadas completamente por acidente, todos os pesos das conexões entre os neurônios são números aleatórios. Portanto, a previsão da rede também será aleatória. Pode acontecer que a rede pense que é provavelmente um barco. Durante o treinamento, sabemos e observamos que a iguana está na imagem. Simplesmente dizemos que gostaríamos que a probabilidade de uma iguana aumentasse essa imagem e a probabilidade de todo o resto diminuir. Em seguida, é utilizado um processo matemático chamado método de propagação reversa. Descida de gradiente estocástico, que nos permite propagar o sinal ao longo dos links e atualizar seus pesos. Atualizaremos um pouco o peso de cada um desses compostos e, assim que a atualização for concluída, a probabilidade de uma iguana para esta imagem aumentará um pouco e a probabilidade de outras respostas diminuirá.
Obviamente, fazemos isso com mais de uma única imagem. Temos um grande conjunto de dados marcados. Normalmente, são milhões de imagens, milhares de tags ou mais. O processo de aprendizado é repetido várias vezes. Você mostra uma imagem ao computador, ela diz a sua opinião, depois diz a resposta correta e a rede está ligeiramente configurada. Você repete isso milhões de vezes, às vezes exibindo a mesma imagem centenas de vezes. O treinamento geralmente leva várias horas ou vários dias.
Agora, algo contra-intuitivo sobre o trabalho das redes neurais. Eles realmente precisam de muitos exemplos. Não se encaixa apenas na sua cabeça, mas eles realmente começam do zero, eles não sabem de nada. Aqui está um exemplo - um cachorro fofo, e você provavelmente não conhece a raça dela. Este é um spaniel japonês. Estamos olhando para esta foto e vemos um spaniel japonês. Podemos dizer: "OK, eu entendo, agora eu sei como é o spaniel japonês". Se eu mostrar mais algumas imagens de outros cães, você poderá encontrar outros spaniels japoneses entre eles. Você só precisa de um exemplo, mas os computadores não podem. Eles precisam de muitos dados sobre spaniels japoneses, milhares de exemplos, em poses diferentes, diferentes condições de iluminação, em diferentes contextos etc. Você precisa mostrar ao computador a aparência do spaniel japonês sob diferentes pontos de vista. E ele realmente precisa de todos esses dados, caso contrário, o computador não poderá aprender o modelo desejado.
Layout da imagem para o piloto automático
Então, como isso tudo se relaciona à direção autônoma? Não estamos muito preocupados com raças de cães. Talvez eles se importem no futuro. Mas agora estamos interessados em marcações de estradas, objetos na estrada, onde eles estão, para onde podemos ir e assim por diante. Agora, não temos apenas rótulos como iguana, mas temos imagens da estrada e estamos interessados em, por exemplo, marcações na estrada. Uma pessoa olha para a imagem e a marca com o mouse.

Temos a oportunidade de entrar em contato com carros da Tesla e pedir ainda mais fotos. Se você solicitar fotos aleatórias, obterá imagens em que, via de regra, o carro passa pela estrada. Este será um conjunto de dados aleatórios e os marcaremos.
Se você marcar apenas conjuntos aleatórios, sua rede aprenderá uma situação de tráfego simples e comum e funcionará bem apenas nela. Quando você mostra a ela um exemplo um pouco diferente, digamos a imagem de uma estrada virando em uma área residencial. Sua rede pode dar o resultado errado. Ela dirá "bem, eu já vi muitas vezes, a estrada segue em frente".

Claro, isso é completamente falso. Mas não podemos culpar a rede neural. Ela não sabe se a árvore à esquerda, o carro à direita ou os edifícios ao fundo são importantes. A rede não sabe nada sobre isso. Todos sabemos que a linha de marcação é importante e o fato de ela virar um pouco para o lado. A rede deve levar isso em consideração, mas não existe um mecanismo pelo qual possamos simplesmente dizer à rede neural que esses traços das marcações da estrada realmente são importantes. A única ferramenta em nossas mãos são dados rotulados.

Nós capturamos imagens nas quais a rede está errada e as marcamos corretamente. Nesse caso, marcamos a marcação de viragem. Então você precisa transferir muitas imagens semelhantes para a rede neural. E com o tempo, ela acumulará conhecimento e aprenderá a entender esse padrão, a entender que essa parte da imagem não desempenha um papel, mas essa marcação é muito importante. A rede aprenderá como encontrar a pista corretamente.
Não é apenas importante o tamanho do conjunto de dados de treinamento. Precisamos de mais do que milhões de imagens. Muito trabalho precisa ser feito para cobrir o espaço de situações que um carro pode encontrar na estrada. Você precisa ensinar um computador a trabalhar à noite e na chuva. A estrada pode refletir a luz como um espelho, a iluminação pode variar dentro de limites amplos, as imagens terão uma aparência muito diferente.

Devemos ensinar ao computador como lidar com sombras, garfos e objetos grandes que ocupam a maior parte da imagem. Como trabalhar com túneis ou em uma área de reparo de estradas. E em todos esses casos, não há mecanismo direto para dizer à rede o que fazer. Temos apenas um grande conjunto de dados. Podemos capturar imagens, marcar e treinar a rede até que ela comece a entender sua estrutura.
Conjuntos de dados grandes e diversos ajudam as redes a funcionarem muito bem. Esta não é a nossa descoberta. Experiências e pesquisas do Google, Facebook, Baidu, Deepmind do alfabeto. Todos mostram resultados semelhantes - as redes neurais realmente gostam de dados, como quantidade e variedade. Adicione mais dados e a precisão das redes neurais está aumentando.
Você terá que desenvolver um piloto automático para simular o comportamento dos carros em uma simulação
Vários especialistas apontam que poderíamos usar a simulação para obter os dados necessários na escala correta. Na Tesla, fizemos repetidamente essa pergunta. Nós temos nosso próprio simulador. Utilizamos amplamente a simulação para desenvolver e avaliar software. Nós o usamos para treinar com bastante sucesso. Mas, no final, quando se trata de treinar dados para redes neurais, nada pode substituir os dados reais. As simulações têm problemas com a modelagem da aparência, física e comportamento dos participantes.

O mundo real nos lança um monte de situações inesperadas. Condições difíceis com neve, árvores, vento. Vários artefatos visuais difíceis de modelar. Áreas de reparo de estradas, arbustos, sacolas plásticas ao vento. Pode haver muitas pessoas, adultos, crianças e animais misturados. Modelar o comportamento e a interação de tudo isso é uma tarefa absolutamente insolúvel.

Não se trata do movimento de um pedestre. É sobre como os pedestres reagem um ao outro, e como os carros reagem um ao outro, como eles reagem a você. Tudo isso é muito difícil de simular. Você precisa desenvolver um piloto automático primeiro, apenas para simular o comportamento dos carros em uma simulação.
Isso é realmente difícil. Pode ser cães, animais exóticos e, às vezes, nem é algo que você não pode fingir ser, é algo que simplesmente nunca passa pela sua cabeça. Eu não sabia que um caminhão pode transportar um caminhão que transporta um caminhão que transporta outro caminhão. Mas no mundo real, isso e muitas outras coisas estão acontecendo e são difíceis de encontrar. A variedade que vejo nos dados provenientes dos carros é insana em relação ao que temos no simulador. Embora tenhamos um bom simulador.
Ilon: Simulação é como se você estivesse inventando sua própria lição de casa. Se você sabe que vai fingir, tudo bem, é claro que vai lidar com isso. Mas como Andrei disse, você não sabe o que não sabe. O mundo é muito estranho, tem milhões de casos especiais. Se alguém criar uma simulação de direção que reproduza fielmente a realidade, isso por si só será uma conquista monumental para a humanidade. Mas ninguém pode fazer isso. Simplesmente não há como.
A frota é uma fonte de dados essencial para o treinamento
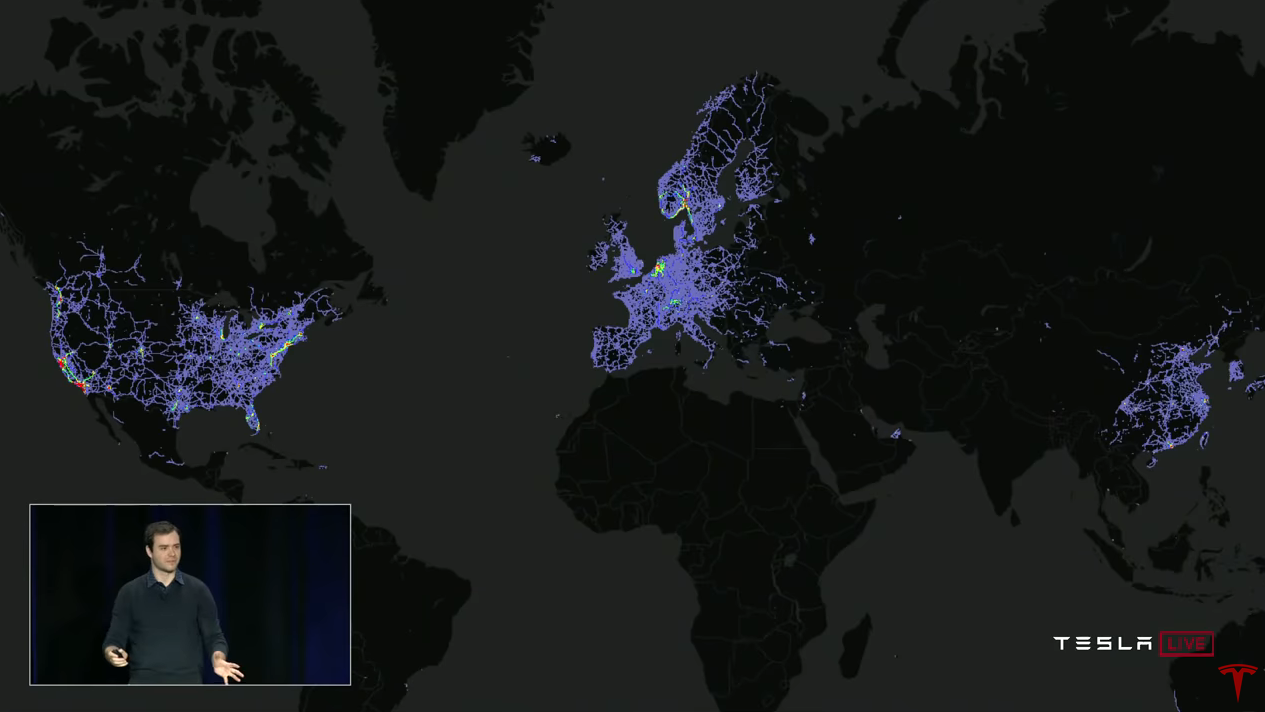 Andrei:
Andrei: Para que as redes neurais funcionem bem, você precisa de um conjunto de dados grande, diversificado e real. E se você tiver uma, poderá treinar sua rede neural e ela funcionará muito bem. Então, por que a Tesla é tão especial nesse sentido? A resposta, é claro, é a frota (frota, frota Tesla). Podemos coletar dados de todos os veículos da Tesla e usá-los para treinamento.
Vejamos um exemplo específico de melhoria da operação de um detector de objetos. Isso lhe dará uma idéia de como treinamos redes neurais, como as usamos e como elas melhoram com o tempo.
A detecção de objetos é uma das nossas tarefas mais importantes. Precisamos destacar as dimensões dos carros e outros objetos para rastreá-los e entender como eles podem se mover. Podemos pedir às pessoas para marcar as imagens. As pessoas dirão: "aqui estão carros, aqui estão bicicletas" e assim por diante. E podemos treinar a rede neural nesses dados. Mas, em alguns casos, a rede fará previsões incorretas.

Por exemplo, se tropeçarmos em um carro ao qual uma bicicleta está presa na parte de trás, nossa rede neural detectará 2 objetos - um carro e uma bicicleta. Foi assim que ela trabalhou quando cheguei. E, à sua maneira, está certo, porque esses dois objetos estão realmente presentes aqui. Mas o planejador do piloto automático não se importa com o fato de que essa bicicleta é um objeto separado que se move com o carro. A verdade é que esta bicicleta está rigidamente presa ao carro. Em termos de objetos na estrada, este é um objeto - um carro.

Agora gostaríamos de marcar muitos objetos semelhantes como "um carro". Nossa equipe usa a seguinte abordagem. Tomamos essa imagem ou várias imagens nas quais esse modelo está presente. E temos um mecanismo de aprendizado de máquina com o qual podemos solicitar à frota que nos forneça exemplos com a mesma aparência. E a frota envia imagens em resposta.

Aqui está um exemplo de seis imagens recebidas. Todos eles contêm bicicletas ligadas a carros. Nós os marcaremos corretamente e nosso detector funcionará melhor. A rede começará a entender quando a bicicleta está conectada ao carro e se trata de um objeto. Você pode treinar a rede nisso, desde que tenha exemplos suficientes. E é assim que resolvemos esses problemas.
Eu falo muito sobre obter dados de carros da Tesla. E quero dizer imediatamente que desenvolvemos esse sistema desde o início, levando em conta a confidencialidade. Todos os dados que usamos para treinamento são anonimizados.
A frota nos envia não apenas bicicletas em carros. Estamos constantemente à procura de muitos modelos diferentes. Por exemplo, estamos à procura de barcos - a frota envia imagens de barcos nas estradas. Queremos imagens das áreas de reparo de estradas, e a frota nos envia muitas imagens de todo o mundo. Ou, por exemplo, lixo na estrada, isso também é muito importante. A frota nos envia imagens de pneus, cones, sacolas plásticas e similares na estrada.

Podemos obter imagens suficientes, marcá-las corretamente e a rede neural aprenderá como trabalhar com elas no mundo real. Precisamos da rede neural para entender o que está acontecendo e responder corretamente.
A incerteza da rede neural desencadeia a coleta de dados
O procedimento, que repetimos várias vezes para treinar a rede neural, é o seguinte. Começamos com um conjunto aleatório de imagens recebidas da frota. Marcamos as imagens, treinamos a rede neural e carregamos nos carros. Temos mecanismos pelos quais detectamos imprecisões na operação do piloto automático. Se percebermos que a rede neural não tem certeza ou há intervenção do driver ou outros eventos, os dados para os quais isso aconteceu são automaticamente enviados.

Por exemplo, as marcações do túnel são pouco reconhecidas. Percebemos que há um problema nos túneis. As imagens correspondentes caem em nossos testes de unidade, para que o problema não possa ser repetido posteriormente. Agora, para corrigir o problema, precisamos de muitos exemplos de treinamento. Pedimos à frota que nos envie mais imagens dos túneis, marque-as corretamente, adicione-as ao conjunto de treinamento, treine novamente a rede e depois carregue-as nos carros. Este ciclo se repete repetidamente. Chamamos esse processo iterativo de mecanismo de dados (mecanismo de dados? Mecanismo de dados?). Ativamos a rede no modo de sombra, detectamos imprecisões, solicitamos mais dados e os incluímos no conjunto de treinamento. Fazemos isso para todos os tipos de previsões de nossas redes neurais.
Marcação automática de dados
Eu falei muito sobre marcação manual de imagens. Este é um processo oneroso, a tempo e financeiramente. Pode ser muito caro. Eu quero falar sobre como você pode usar a frota aqui. A marcação manual é um gargalo. Nós apenas queremos transferir os dados e marcá-los automaticamente. E existem vários mecanismos para isso.
Como exemplo, um de nossos projetos recentes é a reconstrução da detecção.
Você está dirigindo na estrada, alguém está dirigindo à esquerda ou à direita e está reconstruindo a sua faixa. Aqui está um vídeo em que o piloto automático detecta uma reconstrução. Obviamente, gostaríamos de descobrir o mais rápido possível. A abordagem para resolver esse problema é que não escrevemos códigos como: o indicador de direção esquerda está aceso, o indicador de direção certa está aceso, se o carro se moveu horizontalmente ao longo do tempo. Em vez disso, usamos o aprendizado automático baseado em frota.Como isso funciona? Pedimos à frota que nos envie dados sempre que uma reconstrução em nossa pista for registrada. Depois, retrocedemos o tempo e observamos automaticamente que este carro será reconstruído à sua frente em 1,3 segundos. Esses dados podem ser usados para treinar a rede neural. Assim, a própria rede neural extrairá os sinais necessários. Por exemplo, um carro está vasculhando e depois reconstruindo ou tem um sinal de mudança de direção ligado. A rede neural aprende sobre tudo isso a partir de exemplos rotulados automaticamente.
Aqui está um vídeo em que o piloto automático detecta uma reconstrução. Obviamente, gostaríamos de descobrir o mais rápido possível. A abordagem para resolver esse problema é que não escrevemos códigos como: o indicador de direção esquerda está aceso, o indicador de direção certa está aceso, se o carro se moveu horizontalmente ao longo do tempo. Em vez disso, usamos o aprendizado automático baseado em frota.Como isso funciona? Pedimos à frota que nos envie dados sempre que uma reconstrução em nossa pista for registrada. Depois, retrocedemos o tempo e observamos automaticamente que este carro será reconstruído à sua frente em 1,3 segundos. Esses dados podem ser usados para treinar a rede neural. Assim, a própria rede neural extrairá os sinais necessários. Por exemplo, um carro está vasculhando e depois reconstruindo ou tem um sinal de mudança de direção ligado. A rede neural aprende sobre tudo isso a partir de exemplos rotulados automaticamente.Shadow Check
Pedimos à frota que nos envie automaticamente os dados. Podemos coletar meio milhão de imagens ou mais, e as reconstruções serão marcadas em todas. Treinamos a rede e a carregamos na frota. Mas até ativá-lo completamente, mas execute-o no modo de sombra. Nesse modo, a rede constantemente faz previsões: "ei, acho que esse carro será reconstruído". E estamos procurando previsões erradas. Aqui está um exemplo de um clipe que obtivemos no modo sombra. Aqui a situação não é um pouco óbvia, e a rede achou que o carro à direita estava prestes a ser reconstruído. E você pode notar que ele está flertando um pouco com a linha de marcação. A rede reagiu a isso e sugeriu que o carro logo estaria em nossa pista. Mas isso não aconteceu.A rede opera no modo sombra e faz previsões. Entre eles estão falsos positivos e falsos negativos. Às vezes, a rede reage erroneamente e, às vezes, pula eventos. Todos esses erros acionam a coleta de dados. Os dados são marcados e incorporados ao treinamento sem esforço adicional. E não colocamos em risco as pessoas nesse processo. Nós treinamos novamente a rede e usamos o modo sombra novamente. Podemos repetir isso várias vezes, avaliando alarmes falsos em condições reais de tráfego. Quando os indicadores nos convêm, simplesmente clicamos no botão e deixamos a rede controlar o carro.Lançamos uma das primeiras versões do detector de reconstrução, cerca de três meses atrás. Se você perceber que a máquina se tornou muito melhor na detecção da reconstrução, isso é treinar com a frota em ação. E nenhuma pessoa ficou ferida nesse processo. É apenas muito treinamento de redes neurais baseadas em dados reais, usando o modo de sombra e analisando os resultados.Ilon: De fato, todos os motoristas treinam constantemente a rede. Não importa se o piloto automático está ativado ou desativado. A rede está aprendendo. Cada milha percorrida por uma máquina com equipamento HW2.0 ou superior educa a rede.
Aqui está um exemplo de um clipe que obtivemos no modo sombra. Aqui a situação não é um pouco óbvia, e a rede achou que o carro à direita estava prestes a ser reconstruído. E você pode notar que ele está flertando um pouco com a linha de marcação. A rede reagiu a isso e sugeriu que o carro logo estaria em nossa pista. Mas isso não aconteceu.A rede opera no modo sombra e faz previsões. Entre eles estão falsos positivos e falsos negativos. Às vezes, a rede reage erroneamente e, às vezes, pula eventos. Todos esses erros acionam a coleta de dados. Os dados são marcados e incorporados ao treinamento sem esforço adicional. E não colocamos em risco as pessoas nesse processo. Nós treinamos novamente a rede e usamos o modo sombra novamente. Podemos repetir isso várias vezes, avaliando alarmes falsos em condições reais de tráfego. Quando os indicadores nos convêm, simplesmente clicamos no botão e deixamos a rede controlar o carro.Lançamos uma das primeiras versões do detector de reconstrução, cerca de três meses atrás. Se você perceber que a máquina se tornou muito melhor na detecção da reconstrução, isso é treinar com a frota em ação. E nenhuma pessoa ficou ferida nesse processo. É apenas muito treinamento de redes neurais baseadas em dados reais, usando o modo de sombra e analisando os resultados.Ilon: De fato, todos os motoristas treinam constantemente a rede. Não importa se o piloto automático está ativado ou desativado. A rede está aprendendo. Cada milha percorrida por uma máquina com equipamento HW2.0 ou superior educa a rede.Enquanto estiver dirigindo, você está realmente marcando os dados
 Andrei: Outro projeto interessante que usamos no esquema de treinamento de frotas está prevendo o caminho. Ao dirigir, você está realmente marcando os dados. Você nos diz como dirigir em diferentes situações de direção. Aqui está um dos motoristas que virou à esquerda no cruzamento. Temos um vídeo completo de todas as câmeras e sabemos o caminho que o motorista escolheu. Também sabemos qual era a velocidade e o ângulo de rotação do volante. Reunimos tudo e entendemos o caminho que uma pessoa escolheu nessa situação de trânsito. E podemos usar isso como ensino com um professor. Nós apenas obtemos a quantidade necessária de dados da frota, treinamos a rede nessas trajetórias e, depois disso, a rede neural pode prever o caminho.Isso se chama imitação de aprendizado. Pegamos as trajetórias de pessoas do mundo real e tentamos imitá-las. E, novamente, podemos adotar nossa abordagem iterativa.Aqui está um exemplo de previsão de um caminho em condições difíceis da estrada. No vídeo, cobrimos a previsão da rede. Verde marca o caminho que a rede se moveria.
Andrei: Outro projeto interessante que usamos no esquema de treinamento de frotas está prevendo o caminho. Ao dirigir, você está realmente marcando os dados. Você nos diz como dirigir em diferentes situações de direção. Aqui está um dos motoristas que virou à esquerda no cruzamento. Temos um vídeo completo de todas as câmeras e sabemos o caminho que o motorista escolheu. Também sabemos qual era a velocidade e o ângulo de rotação do volante. Reunimos tudo e entendemos o caminho que uma pessoa escolheu nessa situação de trânsito. E podemos usar isso como ensino com um professor. Nós apenas obtemos a quantidade necessária de dados da frota, treinamos a rede nessas trajetórias e, depois disso, a rede neural pode prever o caminho.Isso se chama imitação de aprendizado. Pegamos as trajetórias de pessoas do mundo real e tentamos imitá-las. E, novamente, podemos adotar nossa abordagem iterativa.Aqui está um exemplo de previsão de um caminho em condições difíceis da estrada. No vídeo, cobrimos a previsão da rede. Verde marca o caminho que a rede se moveria. Ilon: A loucura é que a rede prevê um caminho que ela nem consegue ver. Com uma precisão incrivelmente alta. Ela não vê o que está ao redor da curva, mas acredita que a probabilidade dessa trajetória é extremamente alta. E acaba por estar certo. Hoje você verá isso em carros, incluiremos visão aumentada para que você possa ver as marcações e projeções da trajetória sobreposta no vídeo.Andrei: De fato, sob o capô, o máximo está acontecendo, eIlon: Na verdade, é um pouco assustador (Andrey ri).Andrew: Claro, sinto falta de muitos detalhes. Você pode não querer usar todos os drivers seguidos para marcar, mas sim o melhor. E usamos várias maneiras de preparar esses dados. Curiosamente, essa previsão é realmente tridimensional. Este é um caminho no espaço tridimensional que exibimos em 2D. Mas a rede tem informações sobre a inclinação, e isso é muito importante para dirigir.Prevendo a maneira como atualmente funciona nos carros. A propósito, quando você passou pelo cruzamento na estrada, cerca de cinco meses atrás, seu carro não conseguiu lidar com isso. Agora pode. Esta é a previsão do caminho, em ação, em seus carros. Nós o ativamos há um tempo atrás. E hoje você pode ver como isso funciona nos cruzamentos. Uma parte significativa do treinamento para superar interseções é obtida pela marcação automática de dados.Consegui falar sobre os principais componentes do treinamento em redes neurais. Você precisa de um conjunto grande e diversificado de dados reais. Em Tesla, conseguimos isso usando a frota. Usamos o mecanismo de dados, o modo sombra e o particionamento automático de dados usando a frota. E podemos escalar essa abordagem.
Ilon: A loucura é que a rede prevê um caminho que ela nem consegue ver. Com uma precisão incrivelmente alta. Ela não vê o que está ao redor da curva, mas acredita que a probabilidade dessa trajetória é extremamente alta. E acaba por estar certo. Hoje você verá isso em carros, incluiremos visão aumentada para que você possa ver as marcações e projeções da trajetória sobreposta no vídeo.Andrei: De fato, sob o capô, o máximo está acontecendo, eIlon: Na verdade, é um pouco assustador (Andrey ri).Andrew: Claro, sinto falta de muitos detalhes. Você pode não querer usar todos os drivers seguidos para marcar, mas sim o melhor. E usamos várias maneiras de preparar esses dados. Curiosamente, essa previsão é realmente tridimensional. Este é um caminho no espaço tridimensional que exibimos em 2D. Mas a rede tem informações sobre a inclinação, e isso é muito importante para dirigir.Prevendo a maneira como atualmente funciona nos carros. A propósito, quando você passou pelo cruzamento na estrada, cerca de cinco meses atrás, seu carro não conseguiu lidar com isso. Agora pode. Esta é a previsão do caminho, em ação, em seus carros. Nós o ativamos há um tempo atrás. E hoje você pode ver como isso funciona nos cruzamentos. Uma parte significativa do treinamento para superar interseções é obtida pela marcação automática de dados.Consegui falar sobre os principais componentes do treinamento em redes neurais. Você precisa de um conjunto grande e diversificado de dados reais. Em Tesla, conseguimos isso usando a frota. Usamos o mecanismo de dados, o modo sombra e o particionamento automático de dados usando a frota. E podemos escalar essa abordagem.Percepção de profundidade por vídeo
 Na próxima parte do meu discurso, falarei sobre a percepção da profundidade através da visão. Você provavelmente sabe que os carros usam pelo menos dois tipos de sensores. Uma é a de câmeras de vídeo de brilho e a outra é o lidar, usado por muitas empresas. Lidar fornece medições pontuais da distância ao seu redor.Gostaria de observar que todos vocês vieram aqui usando apenas sua rede e visão neurais. Você não disparou com lasers dos seus olhos e ainda acabou aqui.É claro que a rede neural humana extrai a distância e percebe o mundo como tridimensional exclusivamente através da visão. Ela usa uma série de truques. Vou falar brevemente sobre alguns deles. Por exemplo, temos dois olhos, para que você tenha duas imagens do mundo à sua frente. Seu cérebro combina essas informações para obter uma estimativa das distâncias, isso é feito triangulando pontos em duas imagens. Em muitos animais, os olhos estão localizados nos lados e seu campo de visão é ligeiramente cruzado. Esses animais usam estrutura (movimento). Eles movem suas cabeças para obter muitas imagens do mundo de diferentes pontos e também podem aplicar triangulação.
Na próxima parte do meu discurso, falarei sobre a percepção da profundidade através da visão. Você provavelmente sabe que os carros usam pelo menos dois tipos de sensores. Uma é a de câmeras de vídeo de brilho e a outra é o lidar, usado por muitas empresas. Lidar fornece medições pontuais da distância ao seu redor.Gostaria de observar que todos vocês vieram aqui usando apenas sua rede e visão neurais. Você não disparou com lasers dos seus olhos e ainda acabou aqui.É claro que a rede neural humana extrai a distância e percebe o mundo como tridimensional exclusivamente através da visão. Ela usa uma série de truques. Vou falar brevemente sobre alguns deles. Por exemplo, temos dois olhos, para que você tenha duas imagens do mundo à sua frente. Seu cérebro combina essas informações para obter uma estimativa das distâncias, isso é feito triangulando pontos em duas imagens. Em muitos animais, os olhos estão localizados nos lados e seu campo de visão é ligeiramente cruzado. Esses animais usam estrutura (movimento). Eles movem suas cabeças para obter muitas imagens do mundo de diferentes pontos e também podem aplicar triangulação. Mesmo com um olho fechado e completamente imóvel, você mantém um certo senso de percepção da distância. Se você fechar um olho, não lhe parecerá que me tornei dois metros mais perto ou cem metros mais adiante. Isso ocorre porque existem muitas técnicas monoculares poderosas que seu cérebro também aplica. Por exemplo, uma ilusão de ótica comum, com duas faixas idênticas no fundo do trilho. Seu cérebro avalia a cena e espera que uma delas seja maior que a outra devido ao desaparecimento das linhas ferroviárias. Seu cérebro faz muito disso automaticamente, e redes neurais artificiais também podem fazer isso.Vou dar três exemplos de como você pode alcançar a percepção de profundidade no vídeo. Uma abordagem clássica e duas baseadas em redes neurais.
Mesmo com um olho fechado e completamente imóvel, você mantém um certo senso de percepção da distância. Se você fechar um olho, não lhe parecerá que me tornei dois metros mais perto ou cem metros mais adiante. Isso ocorre porque existem muitas técnicas monoculares poderosas que seu cérebro também aplica. Por exemplo, uma ilusão de ótica comum, com duas faixas idênticas no fundo do trilho. Seu cérebro avalia a cena e espera que uma delas seja maior que a outra devido ao desaparecimento das linhas ferroviárias. Seu cérebro faz muito disso automaticamente, e redes neurais artificiais também podem fazer isso.Vou dar três exemplos de como você pode alcançar a percepção de profundidade no vídeo. Uma abordagem clássica e duas baseadas em redes neurais. Podemos gravar um videoclipe em alguns segundos e recriar o ambiente em 3D usando métodos de triangulação e visão estéreo. Aplicamos métodos semelhantes no carro. O principal é que o sinal realmente tenha as informações necessárias, a única questão é extraí-lo.
Podemos gravar um videoclipe em alguns segundos e recriar o ambiente em 3D usando métodos de triangulação e visão estéreo. Aplicamos métodos semelhantes no carro. O principal é que o sinal realmente tenha as informações necessárias, a única questão é extraí-lo.Marcando distância usando radar
Como eu disse, as redes neurais são uma ferramenta de reconhecimento visual muito poderosa. Se quiser que eles reconheçam a distância, marque as distâncias e a rede aprenderá como fazê-lo. Nada restringe as redes em sua capacidade de prever a distância, além de marcar dados.Usamos um radar direcionado para frente. Esse radar mede e marca a distância dos objetos que a rede neural vê. Em vez de dizer às pessoas "este carro está a cerca de 25 metros de distância", você pode marcar os dados muito melhor usando sensores. O radar funciona muito bem a essa distância. Você marca os dados e treina a rede neural. Se você tiver dados suficientes, uma rede neural será muito boa em prever a distância. Nesta imagem, os círculos mostram os objetos recebidos pelo radar e os cuboides são os objetos recebidos pela rede neural. E se a rede funcionar bem, então, na vista superior, as posições dos cuboides devem coincidir com a posição dos círculos, que observamos. As redes neurais se saem muito bem com a previsão de distância. Eles podem aprender o tamanho de diferentes veículos e, de acordo com o tamanho da imagem, determinar com precisão a distância.
Nesta imagem, os círculos mostram os objetos recebidos pelo radar e os cuboides são os objetos recebidos pela rede neural. E se a rede funcionar bem, então, na vista superior, as posições dos cuboides devem coincidir com a posição dos círculos, que observamos. As redes neurais se saem muito bem com a previsão de distância. Eles podem aprender o tamanho de diferentes veículos e, de acordo com o tamanho da imagem, determinar com precisão a distância.Auto-supervisão
O último mecanismo, sobre o qual falarei brevemente, é um pouco mais técnico. Existem apenas alguns artigos, principalmente nos últimos um ou dois anos, sobre essa abordagem. É chamado de auto-supervisão. O que está acontecendo aqui. Você carrega vídeos não rotulados não processados na rede neural. E a rede ainda pode aprender a reconhecer a distância. Sem entrar em detalhes, a ideia é que uma rede neural preveja a distância em cada quadro deste vídeo. Não temos tags para verificação, mas existe uma consistência objetivo-tempo. Independentemente da distância prevista pela rede, ela deve ser consistente ao longo do vídeo. E a única maneira de ser consistente é prever a distância corretamente. A rede prevê automaticamente a profundidade de todos os pixels. Conseguimos reproduzi-lo e funciona muito bem.
O que está acontecendo aqui. Você carrega vídeos não rotulados não processados na rede neural. E a rede ainda pode aprender a reconhecer a distância. Sem entrar em detalhes, a ideia é que uma rede neural preveja a distância em cada quadro deste vídeo. Não temos tags para verificação, mas existe uma consistência objetivo-tempo. Independentemente da distância prevista pela rede, ela deve ser consistente ao longo do vídeo. E a única maneira de ser consistente é prever a distância corretamente. A rede prevê automaticamente a profundidade de todos os pixels. Conseguimos reproduzi-lo e funciona muito bem.—
Para resumir.
As pessoas usam a visão, sem lasers. Quero enfatizar que o reconhecimento visual poderoso é absolutamente essencial para a direção autônoma. Precisamos de redes neurais que realmente entendam o meio ambiente. Os dados do lidar são muito menos saturados de informações. Esta silhueta está na estrada, é uma sacola plástica ou um pneu? Lidar simplesmente fornecerá alguns pontos, enquanto a visão pode dizer o que é. Esse cara está de bicicleta olhando para trás, está tentando mudar de faixa ou está indo direto? Na zona de reparação de estradas, o que significam esses sinais e como devo me comportar aqui? Sim, toda a infraestrutura viária foi projetada para consumo visual. Todos os sinais, semáforos, tudo à vista, é onde estão todas as informações. E devemos usá-lo.Essa garota é apaixonada pelo telefone, ela vai pisar na estrada? As respostas para essas perguntas podem ser encontradas apenas com a ajuda da visão e são necessárias para o piloto automático nível 4-5. E é isso que estamos desenvolvendo na Tesla. Fazemos isso por meio de treinamento em rede neural em larga escala, nosso mecanismo de dados e assistência à frota.Nesse sentido, o lidar é uma tentativa de abrir caminho. Contorna a tarefa fundamental da visão de máquina, cuja solução é necessária para a condução autônoma. Dá uma falsa sensação de progresso. Lidar é bom apenas para demonstrações rápidas.
Os dados do lidar são muito menos saturados de informações. Esta silhueta está na estrada, é uma sacola plástica ou um pneu? Lidar simplesmente fornecerá alguns pontos, enquanto a visão pode dizer o que é. Esse cara está de bicicleta olhando para trás, está tentando mudar de faixa ou está indo direto? Na zona de reparação de estradas, o que significam esses sinais e como devo me comportar aqui? Sim, toda a infraestrutura viária foi projetada para consumo visual. Todos os sinais, semáforos, tudo à vista, é onde estão todas as informações. E devemos usá-lo.Essa garota é apaixonada pelo telefone, ela vai pisar na estrada? As respostas para essas perguntas podem ser encontradas apenas com a ajuda da visão e são necessárias para o piloto automático nível 4-5. E é isso que estamos desenvolvendo na Tesla. Fazemos isso por meio de treinamento em rede neural em larga escala, nosso mecanismo de dados e assistência à frota.Nesse sentido, o lidar é uma tentativa de abrir caminho. Contorna a tarefa fundamental da visão de máquina, cuja solução é necessária para a condução autônoma. Dá uma falsa sensação de progresso. Lidar é bom apenas para demonstrações rápidas.O progresso é proporcional à frequência de colisões com situações complexas no mundo real.

Se eu quisesse encaixar tudo o que foi dito em um slide, ficaria assim. Precisamos de sistemas de nível 4-5 que possam lidar com todas as situações possíveis em 99,9999% dos casos. A busca dos últimos nove será difícil e muito difícil. Isso exigirá um sistema de visão de máquina muito poderoso.
Aqui são mostradas as imagens que você pode encontrar no caminho para as casas decimais estimadas. No começo, você só tem carros avançando, então esses carros começam a parecer um pouco incomuns, as bicicletas aparecem neles, carros nos carros. Então você se depara com eventos realmente raros, como carros invertidos ou mesmo carros em um salto. Reunimos muito de tudo nos dados provenientes da frota.
E vemos esses eventos raros com muito mais frequência do que nossos concorrentes. Isso determina a velocidade com a qual podemos obter dados e corrigir problemas através do treinamento de redes neurais. A velocidade do progresso é proporcional à frequência com que você se depara com situações difíceis no mundo real. E nos deparamos com eles com mais frequência do que qualquer outra pessoa. Portanto, nosso piloto automático é melhor que outros. Obrigada
Perguntas e Respostas
Pergunta: Quantos dados você coleta em média de cada carro?
Andrew: Não se trata apenas da quantidade de dados, mas de diversidade. Em algum momento, você já tem imagens suficientes de direção ao longo da rodovia, a rede as entende, não é mais necessário. Portanto, estamos estrategicamente focados na obtenção dos dados corretos. E nossa infraestrutura, com uma análise bastante complicada, permite obter os dados de que precisamos agora. Não se trata de grandes quantidades de dados, trata-se de dados muito bem selecionados.
Pergunta: Gostaria de saber como você resolverá o problema de mudar de faixa. Sempre que tento reconstruir um fluxo denso, eles me cortam. O comportamento humano está se tornando irracional nas estradas de Los Angeles. O piloto automático quer dirigir com segurança, e você quase precisa fazê-lo inseguro.
Andrew: Falei sobre o mecanismo de dados no treinamento de redes neurais. Mas fazemos o mesmo no nível do software. Todos os parâmetros que afetam a escolha, por exemplo, quando reconstruir, quão agressivo. Também os alteramos no modo de sombra e observamos como eles funcionam e ajustamos a heurística. De fato, projetar essas heurísticas para o caso geral é uma tarefa difícil. Acho que teremos que usar o treinamento da frota para tomar essas decisões. Quando as pessoas mudam de faixa? Em quais cenários? Quando eles acham que mudar de faixa não é seguro? Vamos analisar uma grande quantidade de dados e ensinar o classificador de aprendizado de máquina a distinguir quando a reconstrução é segura. Esses classificadores poderão escrever um código muito melhor do que as pessoas, porque contam com uma enorme quantidade de dados sobre o comportamento dos drivers.
Ilon: Provavelmente, teremos o modo "tráfego em Los Angeles". Em algum lugar após o modo Mad Max. Sim, Mad Max teria dificuldade em Los Angeles.
Andrei terá que se comprometer. Você não deseja criar situações inseguras, mas quer chegar em casa. E as danças que as pessoas realizam ao mesmo tempo, é muito difícil programar. Eu acho que o caminho certo é o aprendizado de máquina. Onde apenas observamos as várias maneiras pelas quais as pessoas fazem isso e tentamos imitá-las.
Ilon: Agora somos um pouco conservadores e, à medida que nossa confiança aumenta, será possível escolher um regime mais agressivo. Os usuários poderão escolher. Nos modos agressivos, ao tentar mudar de faixa em um engarrafamento, há uma pequena chance de enrugar a asa. Sem risco de um acidente grave. Você terá a opção de concordar com uma chance diferente de zero de esmagar a asa. Infelizmente, esta é a única maneira de ficar preso no trânsito na estrada.
Pergunta: Poderia acontecer em um desses nove após o ponto decimal que o lidar será útil? A segunda pergunta é: se os lidares são realmente inúteis, o que acontecerá com aqueles que tomarem suas decisões sobre eles?
Ilon: Todos eles vão se livrar dos lidares, esta é a minha previsão, você pode escrever. Devo dizer que não odeio lidar tanto quanto parece. O SpaceX Dragon usa o lidar para ir para a ISS e atracar. A SpaceX desenvolveu seu próprio lidar a partir do zero para isso. Eu liderei pessoalmente esse projeto porque o lidar faz sentido nesse cenário. Mas em carros é estúpido. É caro e não é necessário. E, como Andrei disse, assim que você manipular o vídeo, o lidar se tornará inútil. Você terá equipamentos caros que são inúteis para o carro.
Temos um radar para a frente. É barato e útil, especialmente em condições de baixa visibilidade. Nevoeiro, poeira ou neve, o radar pode ver através deles. Se você for usar a geração ativa de fótons, não use o comprimento de onda da luz visível. Porque, com óptica passiva, você já cuidou de tudo no espectro visível. Agora é melhor usar um comprimento de onda com boas propriedades de penetração, como radar. Lidar é simplesmente a geração ativa de fótons no espectro visível. Deseja gerar fótons ativamente, faça fora do espectro visível. Usando 3,8 mm versus 400-700 nm, você poderá ver em más condições climáticas. Portanto, temos um radar. Bem como doze sensores ultrassônicos para o ambiente imediato. O radar é mais útil na direção do movimento, porque é diretamente que você está se movendo muito rápido.
Já levantamos a questão dos sensores muitas vezes. Existem o suficiente deles? Temos tudo o que precisamos? Precisa adicionar mais alguma coisa? Hummm. Chega.
Pergunta: Parece que os carros estão fazendo algum tipo de cálculo para determinar quais informações enviar. Isso é feito em tempo real ou com base nas informações armazenadas?
Andrey: Os cálculos são feitos em tempo real nos próprios carros. Transmitimos as condições que nos interessam e os carros fazem todos os cálculos necessários. Se eles não fizessem isso, teríamos que transferir todos os dados em uma linha e processá-los em nosso back-end. Nós não queremos fazer isso.
Ilon: Temos quatrocentos e vinte e cinco mil carros com o HW2.0 +. Isso significa que eles têm oito câmeras, um radar, sensores ultrassônicos e pelo menos um computador nVidia. Basta calcular quais informações são importantes e quais não são. Eles compactam informações importantes e as enviam para a rede para treinamento. Este é um enorme grau de compactação de dados do mundo real.
Pergunta: Você tem essa rede de centenas de milhares de computadores, que se assemelha a um poderoso data center distribuído. Você vê a aplicação para outros fins que não o piloto automático?
Ilon: Suponho que isso possa ser usado para outra coisa. Enquanto nos concentramos no piloto automático. Assim que o colocamos no nível certo, podemos pensar em outros aplicativos. Até então, serão milhões ou dezenas de milhões de carros com HW3.0 ou FSDC.
Pergunta: Calculando tráfego?
Ilon: Sim, talvez. pode ser algo como AWS (Amazon Web Services).
Pergunta: Sou motorista de modelo 3 em Minnesota, onde há muita neve. A câmera e o radar não podem ver as marcações da estrada na neve. Como você vai resolver esse problema? Você vai usar GPS de alta precisão?
Andrew: Hoje, o piloto automático se comporta muito bem em uma estrada com neve. Mesmo quando as marcações estão ocultas, desgastadas ou cobertas de água sob chuva forte, o piloto automático ainda se comporta relativamente bem. Ainda não lidamos com a estrada com neve com nosso mecanismo de dados. Mas tenho certeza de que esse problema pode ser resolvido. Porque em muitas imagens de uma estrada com neve, se você perguntar a uma pessoa onde as marcações devem estar, ela a mostrará. As pessoas concordam em onde desenhar linhas de marcação. E embora as pessoas possam concordar e marcar seus dados, a rede neural poderá aprender isso e funcionará bem. A única questão é se há informações suficientes no sinal original. O suficiente para um anotador de pessoa? Se a resposta for sim, a rede neural funcionará perfeitamente.
Ilon: Existem várias fontes importantes de informação no sinal da fonte. Então, marcação, este é apenas um deles. A fonte mais importante é a entrada de automóveis. Onde você pode ir e onde não pode. Mais importante que a marcação. O reconhecimento da estrada funciona muito bem. Eu acho que, especialmente após o próximo inverno, funcionará incrivelmente. Vamos nos perguntar como isso pode funcionar tão bem. Isso é loucura.
Andrew: Não é nem a capacidade das pessoas marcarem. Contanto que você, uma pessoa, possa superar esse trecho da estrada. A frota aprenderá com você. Nós sabemos como você dirigiu aqui. E você obviamente usou a visão para isso. Você não viu a marcação, mas usou a geometria de toda a cena. Você vê como a estrada se curva, como outros carros estão localizados ao seu redor. A rede neural destacará automaticamente todos esses padrões; você só precisa obter dados suficientes sobre como as pessoas superam essas situações.
Ilon: É muito importante não se ater ao GPS. O erro de GPS pode ser muito significativo. E a situação real do tráfego pode ser imprevisível. Pode ser um reparo ou desvio de estrada. Se o carro depende muito do GPS, esta é uma situação ruim. Você está pedindo problemas. GPS é bom para usar apenas como uma dica.
Pergunta: Alguns de seus concorrentes falam sobre como eles usam mapas de alta definição para melhorar a percepção e o planejamento do caminho. Você usa algo semelhante no seu sistema, vê algum benefício nisso? Existem áreas em que você gostaria de obter mais dados, não da frota, mas algo como cartões?
Ilon: Eu acho que mapas de alta resolução são uma péssima idéia. O sistema se torna extremamente instável. Não foi possível adaptar-se às alterações se você estiver conectado ao GPS e a mapas de alta resolução e não der prioridade à visão. Visão é a coisa que deve fazer tudo. Veja, a marcação é apenas uma diretriz, não a coisa mais importante. Tentamos usar cartões de marcação e rapidamente percebemos que esse era um grande erro. Nós os abandonamos completamente.
Pergunta: Entender onde estão os objetos e como os carros estão se movendo é muito útil. Mas e o aspecto da negociação? Durante o estacionamento, nas rotatórias e em outras situações em que você interage com outros carros que as pessoas dirigem. É mais uma arte do que uma ciência.
Ilon: Funciona muito bem. Se você observar situações com rearranjos etc., o piloto automático normalmente aguenta.
Andrew: Agora usamos muito aprendizado de máquina para criar uma idéia do mundo real. Além disso, temos um agendador e controlador e muitas heurísticas sobre como dirigir, como levar em consideração outros carros e assim por diante. E, assim como no reconhecimento de padrões, há muitos casos fora do padrão aqui, é como um jogo de falcões e pombos, que você joga com outras pessoas. Estamos confiantes de que, em última análise, usaremos o treinamento baseado em frota para resolver esse problema. A heurística de escrita manual repousa rapidamente em um platô.
Pergunta: Você tem um modo de pelotão? O sistema é capaz disso?
Andrei: Estou absolutamente certo de que poderíamos fazer esse regime. Mas, novamente, se você apenas treinar a rede para imitar as pessoas. As pessoas se apegam e dirigem na frente do carro e a rede se lembra desse comportamento. Há um tipo de mágica, tudo acontece por si só. Problemas diferentes se resumem a um: basta coletar o conjunto de dados e usá-lo para treinar a rede neural.
Ilon: Três etapas para a condução autônoma. O primeiro é simplesmente implementar essa funcionalidade. O segundo é trazê-lo a tal ponto que uma pessoa em um carro não precisa prestar atenção à estrada. E a terceira é mostrar o nível de confiabilidade que convence os reguladores. Estes são três níveis. Esperamos alcançar o primeiro nível este ano. E esperamos, em algum momento do segundo trimestre do próximo ano, alcançar um nível de confiança quando uma pessoa não precisar mais manter as mãos no volante e olhar para a estrada. Depois disso, esperamos aprovação regulatória em pelo menos algumas jurisdições até o final do próximo ano. Essas são minhas expectativas.
Para caminhões, é provável que o regime de comboios seja aprovado pelos reguladores mais cedo do que qualquer outra coisa. Talvez para viagens longas você possa usar um motorista no carro da frente e 4 caminhões Semi atrás dele no modo comboio.
Pergunta: Estou muito impressionado com a melhoria do piloto automático. Na semana passada, eu estava dirigindo na faixa direita da rodovia e havia uma entrada. Meu modelo 3 foi capaz de detectar dois carros entrando na estrada e diminuiu a velocidade, de modo que um carro fosse silenciosamente construído na minha frente e o outro atrás de mim. Então eu pensei, caramba, isso é loucura, eu não sabia que meu modelo 3 é capaz disso.
Mas naquela mesma semana eu estava dirigindo novamente na faixa da direita e houve um estreitamento, minha faixa da direita se fundiu com a esquerda. E meu modelo 3 não foi capaz de reagir corretamente, tive que intervir. Você pode dizer como a Tesla pode resolver esse problema?
Andrew: Eu falei sobre a infraestrutura de coleta de dados. Se você interveio, provavelmente obtivemos este clipe. Ele entrou nas estatísticas, por exemplo, com que probabilidade fluímos corretamente no fluxo. Observamos esses números, observamos os clipes e vemos o que está errado. E estamos tentando corrigir o comportamento para obter melhorias em comparação com os benchmarks.
Ilon: Bem, temos outra apresentação sobre software. Fizemos uma apresentação sobre equipamentos com Pete, depois redes neurais com Andrey e agora o software com Stuart.
...