Em pouco tempo, nossa equipe passou de uma dezena de funcionários para uma unidade inteira de quase 200 pessoas e queremos compartilhar alguns marcos desse caminho. Além disso, discutiremos quem exatamente é necessário em big data no momento e qual é o limite real de entrada.

Receita para o sucesso em um novo campo
Trabalhar com big data é uma área tecnológica relativamente nova, que, como tudo, passa pelo ciclo de crescimento à medida que se desenvolve.
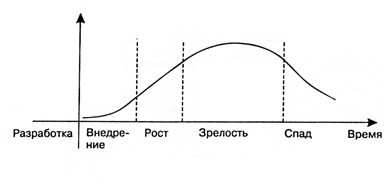
Do ponto de vista de um especialista em particular, o trabalho no campo tecnológico em cada estágio deste ciclo tem suas vantagens e desvantagens.
Etapa 1. ImplementaçãoNo primeiro estágio, essa é uma criação de unidades de P&D, que ainda não fornece lucro real.
Dos profissionais: muito dinheiro é investido nele. Juntamente com os investimentos, crescem as esperanças de resolver tarefas anteriormente inacessíveis e retornar investimentos.
Contras: qualquer tecnologia, por mais promissora que pareça, tem suas próprias limitações: não pode ser usada para eliminar todos os problemas existentes. Esses limites são revelados à medida que são realizadas experiências com uma nova idéia, o que leva a um arrefecimento do interesse pela tecnologia após o chamado "pico de altas expectativas".
Estágio 2. CrescimentoA verdadeira decolagem será apenas para a tecnologia que superará o vazio subsequente de decepção devido às suas reais capacidades, e não ao ruído do marketing.
Prós: nesta fase, a tecnologia atrai investimentos de longo prazo: não apenas dinheiro, mas o tempo de especialistas no mercado de trabalho. Quando fica claro que isso não é apenas exagero, mas uma nova abordagem ou mesmo um segmento de mercado, é hora de os especialistas se integrarem à “tendência”. Este é o momento ideal para dominar tecnologias promissoras em termos de decolagem de carreira.
Contras: nesta fase, a tecnologia ainda está mal documentada.
Etapa 3. MaturidadeA tecnologia madura é o verdadeiro cavalo de batalha do mercado.
Prós: à medida que você envelhece, o volume de documentação acumulada aumenta, os treinamentos e cursos aparecem, torna-se mais fácil entrar na tecnologia.
Contras: Ao mesmo tempo, a concorrência no mercado de trabalho está crescendo.
Etapa 4. RecessãoO estágio de declínio (pôr do sol) ocorre em todas as tecnologias, embora elas continuem funcionando.
Prós: neste momento, a tecnologia já está totalmente descrita, os limites são claros, uma enorme quantidade de documentação, cursos estão disponíveis.
Contras: do ponto de vista da aquisição de novos conhecimentos e perspectivas, não é mais tão atraente. De fato, este é um acompanhamento.
O estágio de crescimento é o mais atraente para todos que desejam começar a trabalhar em um novo campo tecnológico: tanto para jovens profissionais quanto para profissionais já estabelecidos de segmentos afins.
O desenvolvimento de big data está agora neste estágio. Altas expectativas ficaram para trás. Os negócios já provaram que o big data pode gerar lucro e, portanto, há um platô de produtividade pela frente. Esse momento oferece uma excelente oportunidade para especialistas no mercado de trabalho.
Nossa história de big dataA introdução da tecnologia em uma única empresa repete essencialmente o ciclo geral de crescimento. E a nossa experiência aqui é bastante típica.
Começamos a construir nossa equipe de big data no X5 há um ano e meio. Então havia apenas um pequeno grupo de especialistas-chave e agora existem quase 200 de nós.
Nossas equipes de projeto passaram por vários estágios evolutivos, durante os quais obtivemos uma compreensão mais profunda dos papéis e tarefas. Como resultado, temos nosso próprio formato de equipe. Nós decidimos pela abordagem ágil. A idéia principal é que a equipe tenha todas as competências para resolver o problema e como exatamente elas são distribuídas entre os especialistas não é tão importante. Com base nisso, a composição dos papéis das equipes foi formada gradualmente, inclusive levando em consideração o crescimento da tecnologia. E agora temos:
- Dono do produto (proprietário do produto) - possui um entendimento da área de assunto, formula uma ideia geral do negócio e prevê como ela pode ser monetizada.
- Analista de negócios (analista de negócios) - está trabalhando nessa tarefa.
- Qualidade dos dados (especialista em qualidade dos dados) - verifica se os dados existentes podem ser usados para resolver o problema.
- Diretamente Data Science / Data Analyst (cientista de dados / analista de dados) - cria modelos matemáticos (existem diferentes subespécies, incluindo aquelas que funcionam apenas com planilhas).
- Gerentes de teste.
- Desenvolvedores
No nosso caso, a infraestrutura e os dados são usados por todas as equipes e as seguintes funções são implementadas para equipes como serviços: - Infra-estrutura
- ETL (comando de carregamento de dados).
 Como chegamos ao time dos sonhos
Como chegamos ao time dos sonhos
Sonhe, não sonhe, mas, como eu disse, a composição das equipes mudou devido à maturidade da análise de big data e sua penetração no cotidiano do X5 e de nossas redes de distribuição.
"Início rápido" - funções mínimas, velocidade máxima
A primeira equipe incluiu apenas duas funções:
- O Dono do Produto propôs um modelo, fez recomendações.
- Analista de dados - estatísticas coletadas com base nos dados existentes.
Tudo foi rapidamente planejado e implementado manualmente nos negócios.
"Achamos que sim?" - aprendemos a entender o negócio e a produzir o resultado mais útil
Novas funções surgiram para interagir com os negócios:
- Analista de negócios - requisitos de processo descritos.
- Qualidade dos dados - realizou uma verificação da consistência dos dados.
- Dependendo da tarefa, o Data Analyst / Data Scientist analisou as estatísticas dos dados / executou o cálculo do modelo na estação de trabalho local.
“Precisa de mais recursos” - as tarefas de cálculo local foram movidas para o cluster e começaram a tocar em sistemas externos
Para suportar o dimensionamento necessário:
- A infraestrutura que gerou o servidor HADOOP.
- Desenvolvedores - eles implementaram a integração com sistemas de TI externos e verificaram as interfaces do usuário nesse estágio.
Agora, o Data Analyst / Data Scientist pode verificar várias opções para calcular o modelo no cluster, embora a implementação manual nos negócios ainda seja preservada.
“As cargas continuam a crescer” - novos dados são exibidos, novas capacidades são necessárias para processá-los
Essas mudanças não puderam ser refletidas na equipe:
- A infraestrutura desenvolveu o cluster HADOOP sob cargas crescentes.
- A equipe ETL começou downloads e atualizações regulares de dados.
- Apareceu o teste funcional.
"Automação em tudo" - a tecnologia se enraizou, é hora de automatizar a implementação dos negócios
Nesse estágio, o DevOps apareceu na equipe, que configurou a montagem automática, o teste e a instalação da funcionalidade.
Principais reflexões sobre o desenvolvimento de equipes1. Não é fato que tudo daria certo se não tivéssemos os especialistas certos desde o início, em torno dos quais poderíamos formar uma equipe. Este é o esqueleto no qual os músculos começaram a crescer.
2. O mercado de big data é completamente verde; portanto, não há especialistas "prontos" suficientes para cada uma das funções. Obviamente, seria muito conveniente recrutar uma divisão inteira de seniores, mas, obviamente, essas equipes "estrela" não podem ser muito construídas. Decidimos não perseguir apenas pessoal "pronto". Como mencionamos, aderindo à agilidade, devemos cuidar apenas que a equipe como um todo tenha as competências para resolver um problema específico. Em outras palavras, podemos levar (e levar) em uma equipe profissionais e iniciantes com uma certa base técnica e matemática, para que juntos eles formem um conjunto de competências necessárias para alcançar os resultados desejados.
3. Cada uma das funções implica uma compreensão dos princípios de trabalho com big data, exigindo, no entanto, a profundidade dessa compreensão. A maior variabilidade de papéis que têm analogias diretas no desenvolvimento clássico - testadores, analistas etc. Para eles, há tarefas em que pertencer a big data é quase invisível e tarefas nas quais você precisa se aprofundar um pouco mais. De uma forma ou de outra, para iniciar uma carreira, uma certa experiência, um entendimento de TI, um desejo de aprender e algum conhecimento teórico sobre as ferramentas utilizadas (que podem ser obtidas através da leitura dos artigos) é suficiente.
4. A prática demonstrou que, apesar de a tecnologia ser bem conhecida e muitos gostariam de fazer isso, nem todo especialista que seria adequado para iniciar uma carreira em big data (e gostaria de trabalhar no coração) realmente tenta vir aqui .
Muitos candidatos excelentes acreditam que trabalhar em equipes BigData é estritamente Data Science. O que é uma mudança cardinal de atividade com um alto limite de entrada. No entanto, eles subestimam suas competências ou simplesmente não sabem que pessoas de vários perfis estão em demanda em big data, e seria mais fácil iniciar uma carreira em uma função alternativa - qualquer uma das opções acima.
a. De fato, para começar a trabalhar em uma equipe mista em várias funções, você não precisa de uma educação especializada restrita no campo de big data.
b. Expandimos ativamente a equipe, aderindo à ideia de construir unidades estruturais mistas. E o mais interessante é que as pessoas que vieram para nossas tarefas, que nunca haviam trabalhado com big data, se enraizaram perfeitamente na empresa, tendo lidado com as tarefas. Eles foram capazes de aprender rapidamente a prática do big data.
5. Sem ter muita experiência, você pode se aprofundar, aprender as linguagens e ferramentas necessárias, motivado a crescer nesse segmento, a fim de lidar com tarefas mais estratégicas dentro do projeto. E a experiência acumulada ajuda a mudar para as funções em que o conhecimento é necessário em big data e a compreensão da lógica dessa direção. A propósito, nesse sentido, uma equipe mista ajuda muito a acelerar o desenvolvimento.
Como entrar no BigData?
No nosso caso, a idéia de equipes equilibradas de especialistas de diferentes níveis “decolou” - o grupo já implementou mais de um projeto interno. Parece-me que, com a escassez de pessoal pronto e o aumento da necessidade comercial dessas equipes, outras empresas chegarão ao mesmo cenário.
Se você realmente deseja escolher essa direção, mergulhar no Data Sciense - Kaggle, ODS e outros recursos especializados o ajudará. Além disso, se no futuro próximo você não se encontrar no papel de cientista de dados, mas estiver interessado na direção em si, ainda será necessário no Big Data!
Para aumentar seu valor:
- atualize seu conhecimento de matemática. Para resolver problemas comuns de big data, não é necessário um doutorado, mas ainda é necessário conhecimento básico em matemática superior. Compreendendo os mecanismos subjacentes às estatísticas, será mais fácil você estar ciente dos processos;
- Escolha as funções mais próximas à sua especialidade atual. Descubra quais desafios você enfrentará nessa função (e em uma empresa específica, para onde deseja ir). E se você já resolveu problemas semelhantes antes, eles devem ser enfatizados no currículo;
- ferramentas específicas para a função selecionada são muito importantes, mesmo que pareça que isso não seja relevante para o big data. Por exemplo, ao desenvolver nossa solução interna, descobrimos que precisamos de muitos desenvolvedores de front-end que trabalham com interfaces complexas;
- lembre-se de que o mercado está se desenvolvendo ativamente. Alguém está construindo e bombeando equipes para dentro, enquanto alguém espera encontrar especialistas prontos no mercado de trabalho. Se você é iniciante, tente entrar em uma equipe forte, onde haverá uma oportunidade de adquirir conhecimento adicional.
PS A propósito, agora continuamos a crescer ativamente e estamos procurando um
engenheiro de dados ,
especialista em testes ,
desenvolvedor de React e
especialista em UI / UX . Nos dias 10 e 11 de maio, discutiremos a inclusão do trabalho em # bigdatax5 com todos em nosso estande no
DataFest .