Existem várias abordagens para entender uma máquina de fala coloquial: a abordagem clássica de três componentes (inclui um componente de reconhecimento de fala, um componente de compreensão de linguagem natural e um componente responsável por uma certa lógica de negócios) e uma abordagem End2End que envolve quatro modelos de implementação: direto, colaborativo, multiestágio e multitarefa. . Vamos considerar todos os prós e contras dessas abordagens, incluindo os baseados nos experimentos do Google, e analisar detalhadamente por que a abordagem End2End resolve os problemas da abordagem clássica.

Damos a palavra ao principal desenvolvedor do centro de AI MTS Nikita Semenov.
Oi Como prefácio, quero citar os renomados cientistas Jan Lekun, Joshua Benjio e Jeffrey Hinton - esses são três pioneiros da inteligência artificial que recentemente receberam um dos prêmios de maior prestígio no campo da tecnologia da informação - o Turing Award. Em uma das edições da revista Nature em 2015, eles lançaram um artigo muito interessante "Aprendizado profundo", no qual havia uma frase interessante: "O aprendizado profundo veio com a promessa de sua capacidade de lidar com sinais brutos sem a necessidade de recursos artesanais". É difícil traduzi-lo corretamente, mas o significado é algo assim: "O aprendizado profundo veio com a promessa da capacidade de lidar com sinais brutos sem a necessidade de criação manual de sinais". Na minha opinião, para os desenvolvedores, esse é o principal motivador de todos os existentes.
Abordagem clássica
Então, vamos começar com a abordagem clássica. Quando falamos em entender como falar com uma máquina, queremos dizer que temos uma certa pessoa que deseja controlar alguns serviços com sua voz ou sente a necessidade de algum sistema responder a seus comandos de voz com alguma lógica.
Como esse problema é resolvido? Na versão clássica, é utilizado um sistema que, como mencionado acima, consiste em três grandes componentes: um componente de reconhecimento de fala, um componente para entender uma linguagem natural e um componente responsável por uma certa lógica de negócios. É claro que, a princípio, o usuário cria um certo sinal sonoro, que cai sobre o componente de reconhecimento de fala e passa do som para o texto. Em seguida, o texto entra no componente de compreensão da linguagem natural, a partir da qual é retirada uma certa estrutura semântica, necessária para o componente responsável pela lógica de negócios.
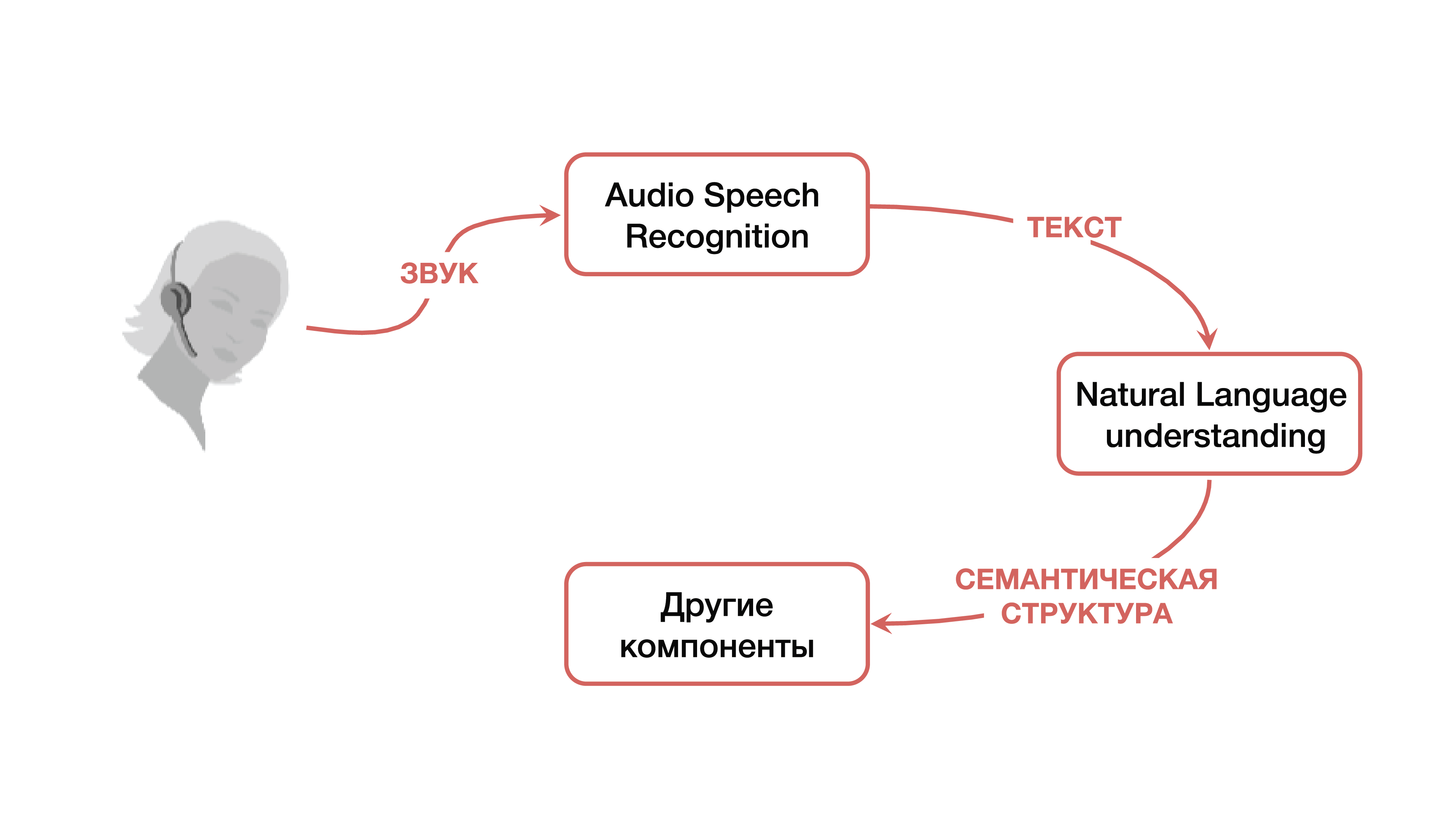
O que é uma estrutura semântica? Este é um tipo de generalização / agregação de várias tarefas em uma - para facilitar a compreensão. A estrutura inclui três partes importantes: a classificação do domínio (uma certa definição do tópico), a classificação da intenção (entendendo o que precisa ser feito) e a alocação das entidades nomeadas para preencher os cartões necessários para tarefas comerciais específicas no próximo estágio. Para entender o que é uma estrutura semântica, considere um exemplo simples, que o Google cita com mais frequência. Temos um pedido simples: "Por favor, toque uma música de algum artista".

O domínio e o assunto nesta solicitação são música; intenção - tocar uma música; atributos do cartão "tocar uma música" - que tipo de música, que tipo de artista. Essa estrutura é o resultado da compreensão de uma linguagem natural.
Se falamos em resolver um problema complexo e de vários estágios para entender o discurso coloquial, então, como eu disse, ele consiste em dois estágios: o primeiro é o reconhecimento de fala, o segundo é o entendimento da linguagem natural. A abordagem clássica envolve uma separação completa desses estágios. Como primeiro passo, temos um determinado modelo que recebe um sinal acústico na entrada e na saída, usando linguagem e modelos acústicos e um léxico, determina a hipótese verbal mais provável desse sinal acústico. Esta é uma história completamente probabilística - pode ser decomposta de acordo com a conhecida fórmula de Bayes e obter uma fórmula que permita escrever a função de probabilidade da amostra e usar o método de máxima verossimilhança. Temos uma probabilidade condicional do sinal X, desde que a sequência de palavras W seja multiplicada pela probabilidade dessa sequência de palavras.

A primeira etapa pela qual passamos - obtemos uma hipótese verbal a partir do sinal sonoro. Em seguida, vem o segundo componente, que pega essa hipótese muito verbal e tenta extrair a estrutura semântica descrita acima.
Temos a probabilidade da estrutura semântica S, desde que a sequência verbal W esteja na entrada.

Qual é a coisa ruim da abordagem clássica, consistindo desses dois elementos / etapas, ensinados separadamente (ou seja, primeiro treinamos o modelo do primeiro elemento e depois o modelo do segundo)?
- O componente de compreensão da linguagem natural trabalha com as hipóteses verbais de alto nível que o ASR gera. Esse é um grande problema, porque o primeiro componente (o próprio ASR) trabalha com dados brutos de baixo nível e gera uma hipótese verbal de alto nível, e o segundo componente toma a hipótese como entrada - não os dados brutos da fonte primária, mas a hipótese que o primeiro modelo fornece - e constrói sua hipótese sobre a hipótese do primeiro estágio. Esta é uma história bastante problemática, porque se torna "condicional" demais.
- O próximo problema: não podemos estabelecer nenhuma conexão entre a importância das palavras necessárias para construir a própria estrutura semântica e o que o primeiro componente prefere ao construir nossa hipótese verbal. Ou seja, se você reformular, entendemos que a hipótese já foi construída. É construído com base em três componentes, como eu disse: a parte acústica (a que entrou na entrada e é de alguma forma modelada), a parte da linguagem (modela completamente qualquer engraxamento da linguagem - a probabilidade de fala) e o léxico (pronúncia das palavras). Essas são três grandes partes que precisam ser combinadas e algumas hipóteses encontradas nelas. Mas não há como influenciar a escolha da mesma hipótese, de modo que essa hipótese seja importante para o próximo estágio (que, em princípio, é o ponto em que aprendem completamente separadamente e não se afetam de maneira alguma).
Abordagem End2End
Entendemos qual é a abordagem clássica, que problemas ela tem. Vamos tentar resolver esses problemas usando a abordagem End2End.
Por End2End, queremos dizer um modelo que combinará os vários componentes em um único componente. Modelaremos usando modelos que consistem na arquitetura codificador-decodificador contendo módulos de atenção (atenção). Tais arquiteturas são frequentemente usadas em problemas de reconhecimento de fala e em tarefas relacionadas ao processamento de uma linguagem natural, em particular a tradução automática.
Existem quatro opções para a implementação de tais abordagens que poderiam resolver o problema colocado à nossa frente pela abordagem clássica: são modelos diretos, colaborativos, de vários estágios e multitarefas.
Modelo direto
O modelo direto assume os atributos brutos de baixo nível de entrada, ou seja, sinal de áudio de baixo nível e, na saída, obtemos imediatamente uma estrutura semântica. Ou seja, obtemos um módulo - a entrada do primeiro módulo da abordagem clássica e a saída do segundo módulo da mesma abordagem clássica. Apenas uma "caixa preta". A partir daqui, existem algumas vantagens e desvantagens. O modelo não aprende a transcrever completamente o sinal de entrada - essa é uma vantagem clara, porque não precisamos coletar marcações grandes e grandes, não precisamos coletar muito sinal de áudio e depois transmiti-lo aos acessadores para marcação. Nós apenas precisamos deste sinal de áudio e da estrutura semântica correspondente. E isso é tudo. Isso muitas vezes reduz o trabalho envolvido na marcação de dados. Provavelmente, o maior ponto negativo dessa abordagem é que a tarefa é muito complicada para uma "caixa preta", que está tentando resolver imediatamente, condicionalmente, dois problemas. Primeiro, dentro de si, ele tenta construir algum tipo de transcrição e, a partir dessa transcrição, revela a própria estrutura semântica. Isso levanta uma tarefa bastante difícil - aprender a ignorar partes da transcrição. E é muito difícil. Esse fator é um sinal menos amplo e colossal dessa abordagem.
Se falamos de probabilidades, esse modelo resolve o problema de encontrar a estrutura semântica mais provável S a partir do sinal acústico X com os parâmetros do modelo θ.
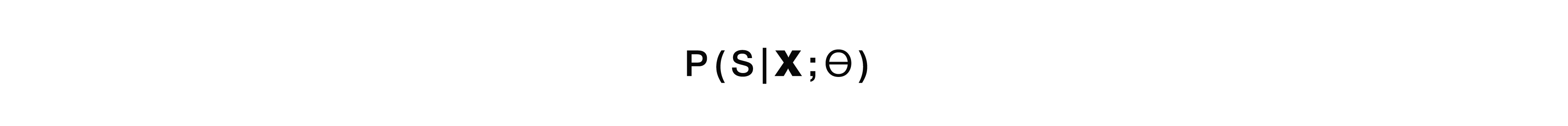
Modelo comum
Qual é a alternativa? Este é um modelo colaborativo. Ou seja, algum modelo é muito semelhante a uma linha reta, mas com uma exceção: a saída para nós já consiste em sequências verbais e uma estrutura semântica é simplesmente concatenada para eles. Ou seja, na entrada temos um sinal sonoro e um modelo de rede neural, que na saída já fornece transcrição verbal e estrutura semântica.
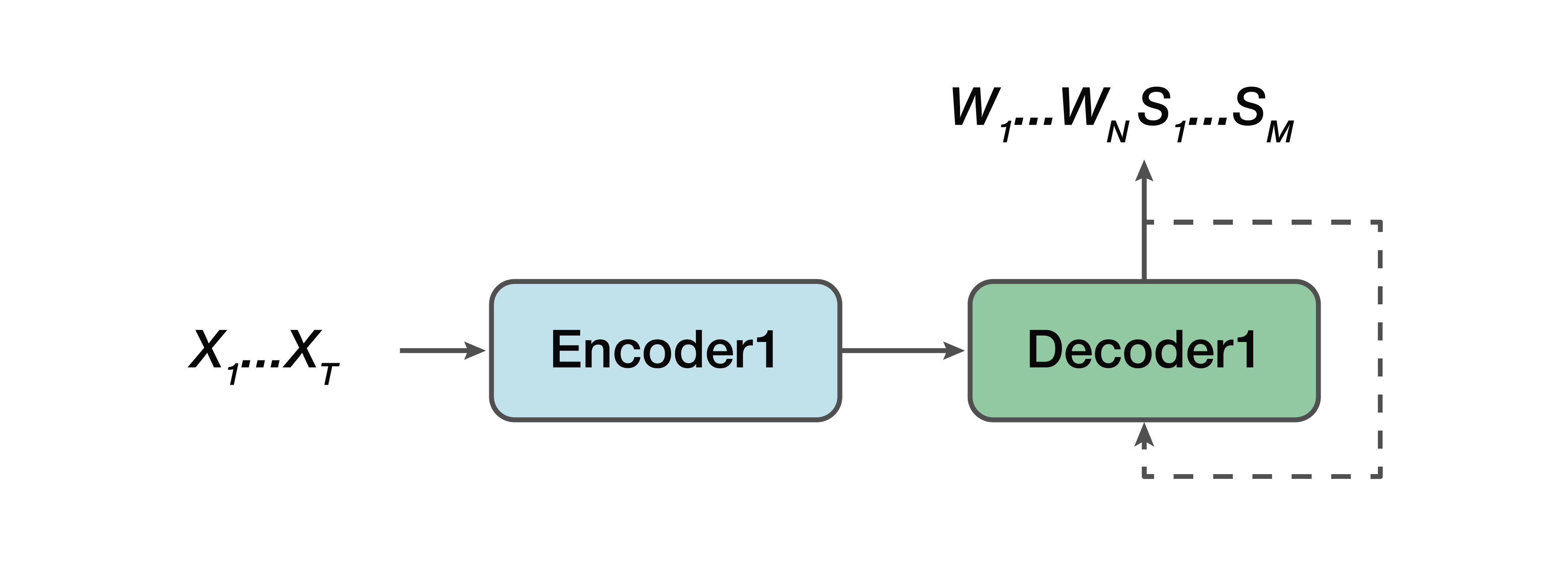
Dos profissionais: ainda temos um codificador simples, um decodificador simples. O aprendizado é facilitado porque o modelo não tenta resolver dois problemas ao mesmo tempo, como no caso do modelo direto. Mais uma vantagem é que essa dependência da estrutura semântica em atributos sonoros de baixo nível ainda está presente. Porque, novamente, um codificador, um decodificador. E, consequentemente, uma das vantagens pode-se notar que existe uma dependência em prever essa estrutura semântica e sua influência diretamente na própria transcrição - o que não nos convinha na abordagem clássica.
Novamente, precisamos encontrar a sequência mais provável de palavras W e as estruturas semânticas correspondentes S do sinal acústico X com os parâmetros θ.
Modelo multitarefa
A próxima abordagem é um modelo multitarefa. Novamente, a abordagem codificador-decodificador, mas com uma exceção.
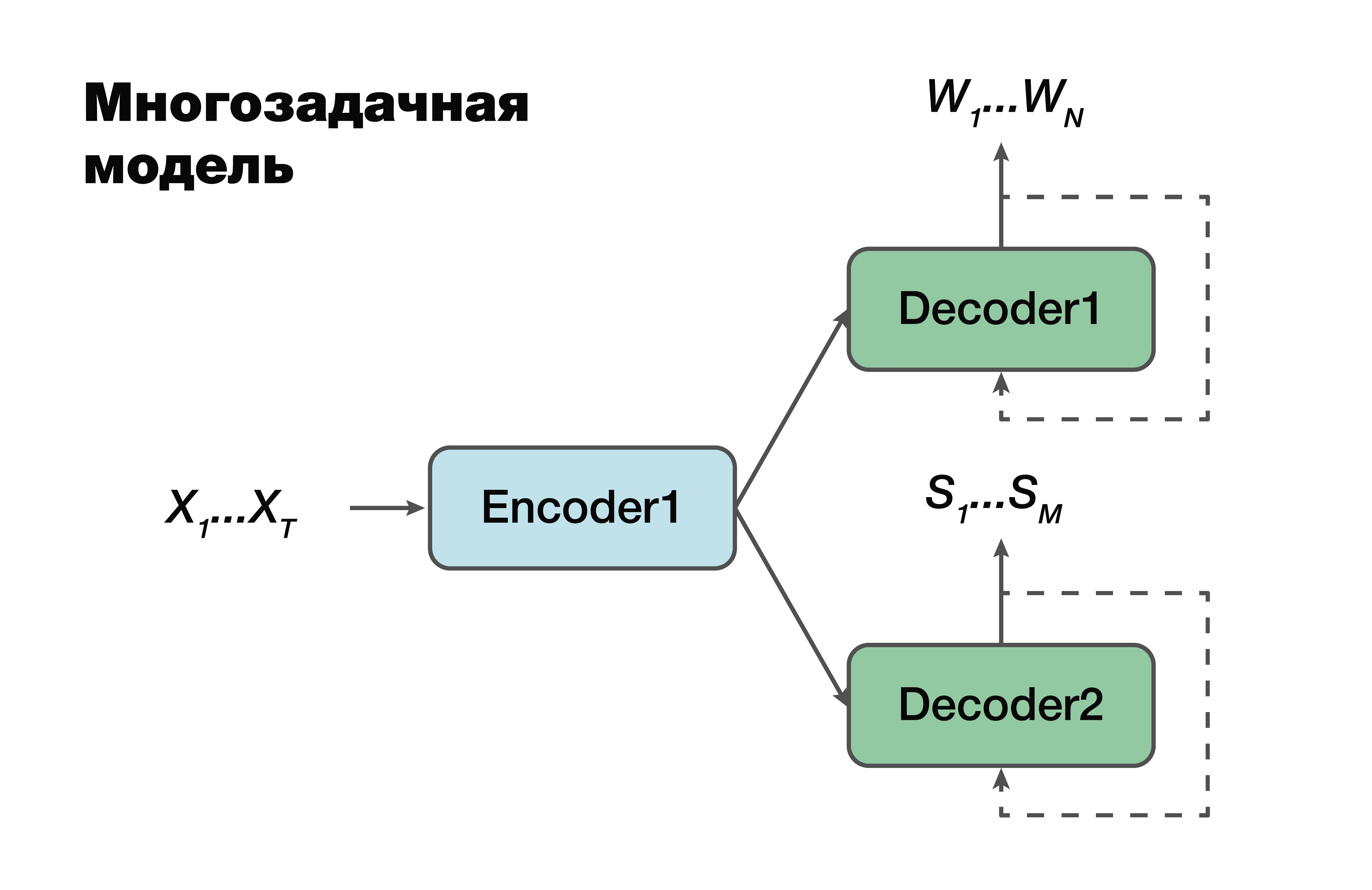
Para cada tarefa, ou seja, criar uma sequência verbal, criar uma estrutura semântica, temos nosso próprio decodificador que usa uma representação oculta comum que gera um único codificador. Um truque muito famoso no aprendizado de máquina, muito usado no trabalho. Resolver dois problemas diferentes ao mesmo tempo ajuda a procurar dependências nos dados de origem muito melhor. E como consequência disso - a melhor capacidade de generalização, pois o parâmetro ideal é selecionado para várias tarefas ao mesmo tempo. Essa abordagem é mais adequada para tarefas com menos dados. E os decodificadores usam um espaço vetorial oculto no qual seu codificador cria.

É importante notar que já em probabilidade existe uma dependência dos parâmetros dos modelos de codificador e decodificador. E esses parâmetros são importantes.
Modelo multiestágio
Na minha opinião, passamos à abordagem mais interessante: um modelo de vários estágios. Se você observar com muito cuidado, poderá ver que, de fato, esta é a mesma abordagem clássica de dois componentes, com uma exceção.
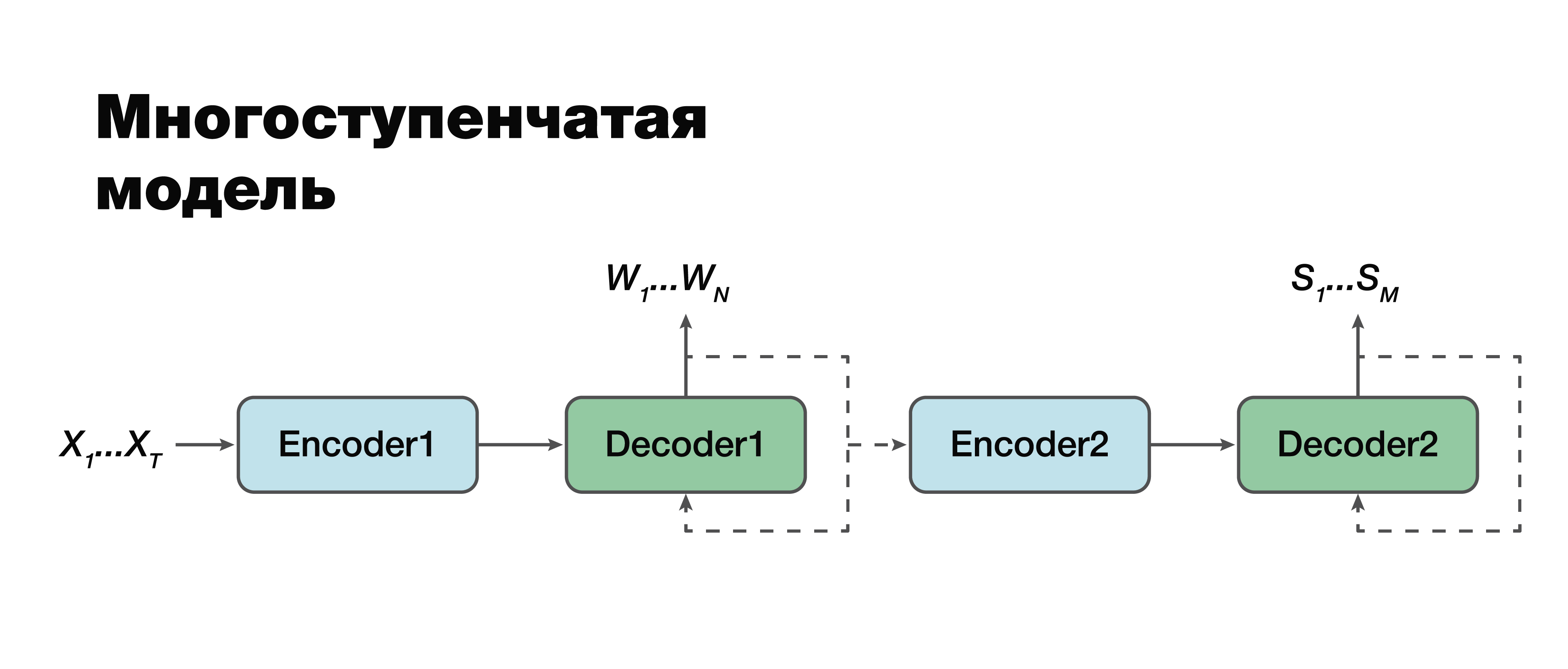
Aqui é possível estabelecer uma conexão entre os módulos e torná-los monomódulos. Portanto, a estrutura semântica é considerada condicionalmente dependente da transcrição. Existem duas opções para trabalhar com este modelo. Podemos treinar individualmente esses dois mini-blocos: o primeiro e o segundo codificador-decodificador. Ou combine-os e treine as duas tarefas ao mesmo tempo.
No primeiro caso, os parâmetros para as duas tarefas não estão relacionados (podemos treinar usando dados diferentes). Suponha que tenhamos um grande corpo sonoro e as sequências e transcrições verbais correspondentes. Nós os "dirigimos", treinamos apenas a primeira parte. Temos uma boa simulação de transcrição. Então pegamos a segunda parte, treinamos em outro caso. Conectamos e obtemos uma solução que nessa abordagem é 100% consistente com a abordagem clássica, porque escolhemos e treinamos separadamente a primeira parte e separadamente a segunda. E então treinamos o modelo conectado no caso, que já contém tríades de dados: um sinal de áudio, a transcrição correspondente e a estrutura semântica correspondente. Se tivermos um edifício assim, podemos treinar novamente o modelo, treinado individualmente em grandes edifícios, para nossa pequena tarefa específica e obter o máximo ganho de precisão de uma maneira tão complicada. Essa abordagem nos permite levar em consideração a importância de diferentes partes da transcrição e sua influência na previsão da estrutura semântica,
levando em consideração os erros do segundo estágio no primeiro.
É importante notar que a tarefa final é muito semelhante à abordagem clássica, com apenas uma grande diferença: o segundo termo de nossa função - o logaritmo da probabilidade da estrutura semântica - desde que o sinal acústico de entrada X também dependa dos parâmetros do
modelo do primeiro estágio .

Também é importante observar aqui que o segundo componente depende dos parâmetros do primeiro e do segundo modelos.
Metodologia para avaliar a precisão das abordagens
Agora vale a pena decidir sobre a metodologia para avaliar a precisão. Como, de fato, medir essa precisão, a fim de levar em consideração características que não nos convêm na abordagem clássica? Existem rótulos clássicos para essas tarefas separadas. Para avaliar os componentes de reconhecimento de fala, podemos usar a métrica clássica do WER. Esta é uma taxa de erro do Word. Consideramos, de acordo com uma fórmula não muito complicada, o número de inserções, substituições, permutações da palavra e as dividimos pelo número de todas as palavras. E temos uma certa característica estimada da qualidade do nosso reconhecimento. Para uma estrutura semântica, componente a componente, podemos simplesmente considerar a pontuação F1. Essa também é uma métrica clássica para o problema de classificação. Aqui tudo é mais ou menos claro. Há plenitude, há precisão. E isso é apenas um meio harmônico entre eles.
Mas surge a questão de como medir a precisão quando a transcrição de entrada e o argumento de saída não coincidem ou quando a saída é de dados de áudio. O Google propôs uma métrica que levará em conta a importância de prever o primeiro componente do reconhecimento de fala, avaliando o efeito desse reconhecimento no próprio segundo componente. Eles o chamavam de Arg WER, ou seja, pesa WER sobre as entidades da estrutura semântica.
Aceite o pedido: "Defina o alarme por 5 horas". Essa estrutura semântica contém um argumento como "cinco horas", um argumento do tipo "data e hora". É importante entender que, se o componente de reconhecimento de fala produzir esse argumento, a métrica de erro desse argumento, ou seja, WER, será 0%. Se esse valor não corresponder a cinco horas, a métrica terá 100% de WER. Portanto, simplesmente consideramos o valor médio ponderado de todos os argumentos e, em geral, obtemos uma certa métrica agregada que estima a importância dos erros de transcrição que criam o componente de reconhecimento de fala.
Deixe-me dar um exemplo das experiências do Google que ele conduziu em um de seus estudos sobre este tópico. Eles usaram dados de cinco domínios, cinco assuntos: Mídia, Media_Control, Produtividade, Prazer, Nenhum - com a distribuição correspondente de dados nos conjuntos de dados de teste de treinamento. É importante observar que todos os modelos foram treinados do zero. Cross_entropy foi usado, o parâmetro de busca do feixe foi 8, o otimizador que eles usaram, é claro, Adam. Considerado, é claro, em uma grande nuvem de seu TPU. Qual é o resultado? Estes são números interessantes:
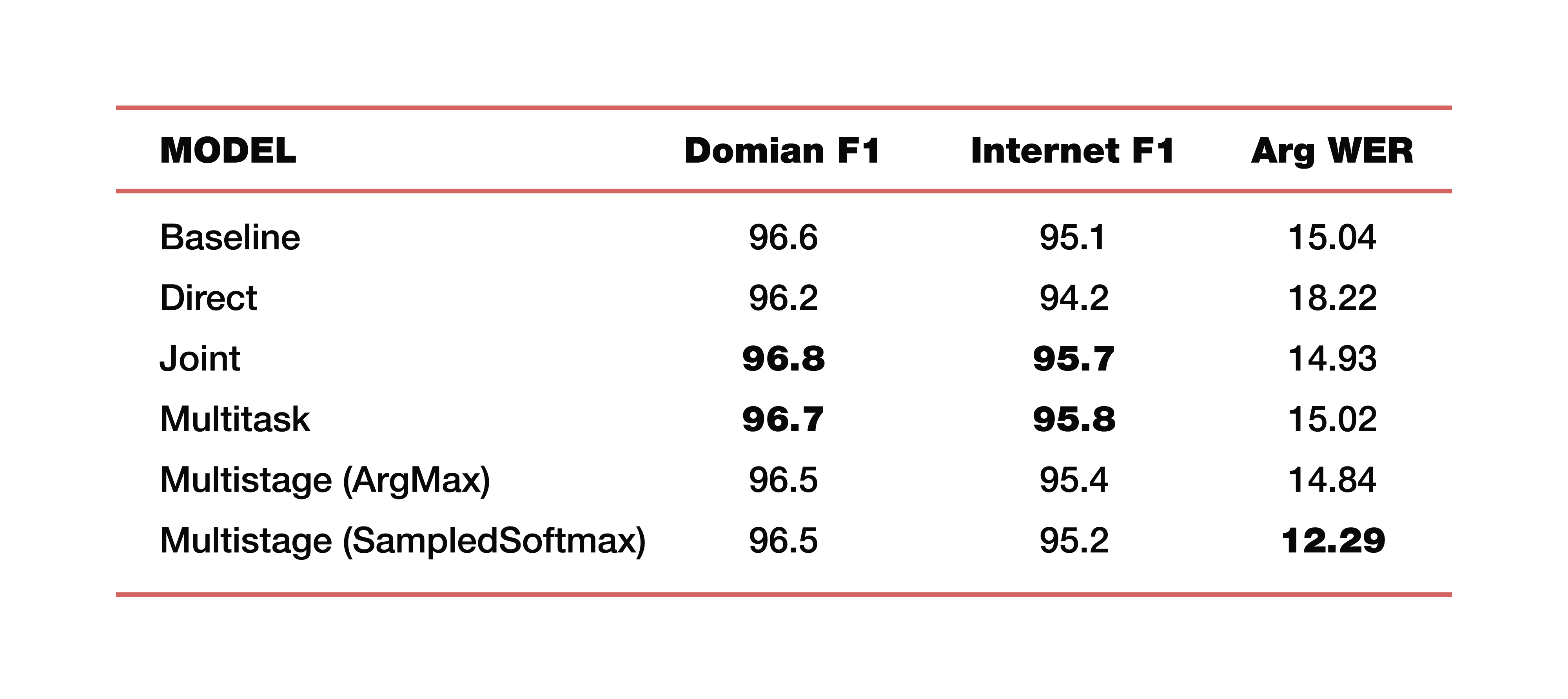
Para entender, a linha de base é uma abordagem clássica que consiste em dois componentes, como dissemos no início. A seguir, são apresentados exemplos de modelos diretos, conectados, multitarefa e de vários estágios.
Quanto custam dois modelos de vários estágios? Apenas na junção da primeira e segunda partes, diferentes camadas foram usadas. No primeiro caso, é ArgMax, no segundo caso, SampedSoftmax.
No que vale a pena prestar atenção? A abordagem clássica perde nas três métricas, que são uma estimativa da colaboração direta desses dois componentes. Sim, não estamos interessados em quão bem a transcrição é feita lá, apenas em como o elemento que prediz a estrutura semântica funciona. Ele é avaliado por três métricas: F1 - por tópico, F1 - por intenção e métrica ArgWer, que é considerada pelos argumentos das entidades. F1 é considerada uma média ponderada entre precisão e integridade. Ou seja, o padrão é 100. ArgWer, pelo contrário, não é um sucesso, é um erro, ou seja, aqui o padrão é 0.
Vale ressaltar que nossos modelos acoplados e multitarefas superam completamente todos os modelos de classificação para tópicos e intenções. E o modelo, que é de vários estágios, tem um aumento muito grande no ArgWer total. Por que isso é importante? Como nas tarefas associadas à compreensão do discurso coloquial, a ação final que será executada no componente responsável pela lógica de negócios é importante. Não depende diretamente das transcrições criadas pelo ASR, mas da qualidade dos componentes ASR e NLU trabalhando juntos. Portanto, uma diferença de quase três pontos na métrica argWER é um indicador muito interessante, que indica o sucesso dessa abordagem. Também é importante notar que todas as abordagens têm valores comparáveis por definição de tópicos e intenções.
Vou dar alguns exemplos do uso de tais algoritmos para entender o discurso conversacional. O Google, ao falar sobre as tarefas de entender a fala conversacional, observa principalmente as interfaces homem-computador, ou seja, todos os tipos de assistentes virtuais, como o Google Assistant, o Apple Siri, o Amazon Alexa e assim por diante. Como segundo exemplo, vale mencionar um pool de tarefas como o Interactive Voice Response. Ou seja, esta é uma história que está envolvida na automação de call centers.
Portanto, examinamos as abordagens com a possibilidade de usar a otimização conjunta, o que ajuda o modelo a se concentrar nos erros mais importantes para as SLUs. Essa abordagem da tarefa de entender o idioma falado simplifica bastante a complexidade geral.
Temos a oportunidade de fazer uma conclusão lógica, ou seja, obter algum tipo de resultado, sem a necessidade de recursos adicionais como o léxico, modelos de linguagem, analisadores e assim por diante (ou seja, todos esses são fatores inerentes à abordagem clássica). A tarefa é resolvida "diretamente".
Na verdade, você não pode parar por aí. E se agora combinamos as duas abordagens, os dois componentes de uma estrutura comum, podemos procurar mais. Combine os três componentes e os quatro - apenas continue a combinar essa cadeia lógica e "repasse" a importância dos erros para um nível mais baixo, dada a criticidade já existente. Isso nos permitirá aumentar a precisão da solução do problema.