
Eu moro em uma boa cidade. Mas, como em muitos outros, a busca por um estacionamento sempre se transforma em um teste. Os espaços livres ocupam rapidamente e, mesmo se você tiver o seu, será difícil para os amigos ligar para você, porque eles não terão onde estacionar.
Por isso, decidi apontar a câmera para fora da janela e usar o aprendizado profundo para que meu computador me diga quando o espaço está disponível:

Pode parecer complicado, mas escrever um protótipo funcional com aprendizado profundo é rápido e fácil. Todos os componentes necessários já estão lá - você só precisa saber onde encontrá-los e como montá-los.
Então, vamos nos divertir e escrever um sistema preciso de notificação de estacionamento gratuito usando Python e aprendizado profundo
Decompondo a tarefa
Quando temos uma tarefa difícil que queremos resolver usando o aprendizado de máquina, o primeiro passo é dividi-la em uma sequência de tarefas simples. Então, podemos usar várias ferramentas para resolver cada uma delas. Ao combinar várias soluções simples, obtemos um sistema capaz de algo complexo.
Aqui está como eu quebrei minha tarefa:

O fluxo de vídeo da webcam direcionado para a janela entra na entrada do transportador:

Através do pipeline, transmitiremos cada quadro do vídeo, um de cada vez.
O primeiro passo é reconhecer todos os lugares de estacionamento possíveis no quadro. Obviamente, antes que possamos procurar lugares desocupados, precisamos entender em quais partes da imagem há estacionamento.
Em cada quadro, você precisa encontrar todos os carros. Isso nos permitirá rastrear o movimento de cada máquina de quadro a quadro.
O terceiro passo é determinar quais locais são ocupados por máquinas e quais não são. Para fazer isso, combine os resultados das duas primeiras etapas.
Por fim, o programa deve enviar um alerta quando o estacionamento ficar livre. Isso será determinado pelas alterações na localização das máquinas entre os quadros do vídeo.
Cada uma dessas etapas pode ser concluída de diferentes maneiras, usando diferentes tecnologias. Não existe uma maneira certa ou errada de compor esse transportador; abordagens diferentes terão suas vantagens e desvantagens. Vamos lidar com cada etapa com mais detalhes.
Reconhecemos vagas de estacionamento
Aqui está o que nossa câmera vê:

De alguma forma, precisamos digitalizar esta imagem e obter uma lista de lugares para estacionar:

A solução “na testa” seria simplesmente codificar manualmente os locais de todos os lugares de estacionamento em vez de reconhecê-los automaticamente. Mas, neste caso, se movermos a câmera ou quisermos procurar vagas em outra rua, teremos que executar todo o procedimento novamente. Parece tão, então vamos procurar uma maneira automática de reconhecer vagas de estacionamento.
Como alternativa, você pode procurar parquímetros na imagem e supor que haja um espaço de estacionamento próximo a cada um deles:

No entanto, com essa abordagem, nem tudo é tão tranquilo. Em primeiro lugar, nem todos os lugares de estacionamento possuem um medidor de estacionamento e, de fato, estamos mais interessados em encontrar vagas de estacionamento pelas quais você não precisa pagar. Em segundo lugar, a localização do medidor de estacionamento não nos diz nada sobre onde fica o espaço de estacionamento, mas apenas nos permite fazer uma suposição.
Outra idéia é criar um modelo de reconhecimento de objeto que procure por marcas de vagas de estacionamento desenhadas na estrada:

Mas essa abordagem é mais ou menos. Em primeiro lugar, na minha cidade todas essas marcas são muito pequenas e difíceis de ver à distância, por isso será difícil detectá-las usando um computador. Em segundo lugar, a rua está cheia de todos os tipos de outras linhas e marcas. Será difícil separar as marcas de estacionamento dos divisores de faixa e travessias de pedestres.
Quando você encontrar um problema que, à primeira vista, parece difícil, dedique alguns minutos para encontrar outra abordagem para resolvê-lo, o que ajudará a contornar alguns problemas técnicos. O que há um espaço de estacionamento? Este é apenas um lugar onde um carro fica estacionado por um longo tempo. Talvez não precisemos reconhecer vagas de estacionamento. Por que simplesmente não reconhecemos os carros que ficam parados por um longo tempo e não assumimos que eles estão no estacionamento?
Em outras palavras, os espaços de estacionamento estão localizados onde os carros ficam por muito tempo:

Assim, se pudermos reconhecer os carros e descobrir quais deles não se movem entre os quadros, podemos adivinhar onde estão os lugares de estacionamento. Simples assim - vá para o reconhecimento da máquina!
Reconhecer carros
O reconhecimento de carros em um quadro de vídeo é uma tarefa clássica de reconhecimento de objetos. Existem muitas abordagens de aprendizado de máquina que poderíamos usar para reconhecimento. Aqui estão alguns deles, desde a "velha escola" até a "nova escola":
- Você pode treinar o detector com base no HOG (Histograma de gradientes orientados, histogramas de gradientes direcionais) e percorrer toda a imagem para encontrar todos os carros. Essa abordagem antiga, que não usa aprendizado profundo, funciona relativamente rápido, mas não lida muito bem com máquinas localizadas de maneiras diferentes.
- Você pode treinar o detector baseado na CNN (Rede Neural Convolucional, uma rede neural convolucional) e percorrer toda a imagem até encontrar todos os carros. Essa abordagem funciona exatamente, mas não com tanta eficiência, pois precisamos digitalizar a imagem várias vezes usando a CNN para encontrar todas as máquinas. E embora possamos encontrar máquinas localizadas de maneiras diferentes, precisamos de muito mais dados de treinamento do que para um detector HOG.
- Você pode usar uma nova abordagem com aprendizado profundo, como Mask R-CNN, Faster R-CNN ou YOLO, que combina a precisão da CNN e um conjunto de truques técnicos que aumentam bastante a velocidade do reconhecimento. Esses modelos funcionarão relativamente rapidamente (na GPU) se tivermos muitos dados para treinar o modelo.
No caso geral, precisamos da solução mais simples, que funcionará como deveria e exigirá a menor quantidade de dados de treinamento. Não é necessário que seja o algoritmo mais recente e mais rápido. No entanto, especificamente no nosso caso, o Mask R-CNN é uma escolha razoável, apesar de ser bastante novo e rápido.
A arquitetura Mask R-CNN foi projetada de forma a reconhecer objetos em toda a imagem, gastando efetivamente recursos e não usar a abordagem de janela deslizante. Em outras palavras, funciona muito rápido. Com uma GPU moderna, poderemos reconhecer objetos em vídeo em alta resolução a uma velocidade de vários quadros por segundo. Para o nosso projeto, isso deve ser suficiente.
Além disso, o Mask R-CNN fornece muitas informações sobre cada objeto reconhecido. A maioria dos algoritmos de reconhecimento retorna apenas uma caixa delimitadora para cada objeto. No entanto, o Mask R-CNN não apenas nos fornecerá a localização de cada objeto, mas também seu contorno (máscara):

Para treinar o Mask R-CNN, precisamos de muitas imagens de objetos que queremos reconhecer. Poderíamos sair, tirar fotos de carros e marcá-los em fotografias, o que exigiria vários dias de trabalho. Felizmente, os carros são um daqueles objetos que as pessoas geralmente querem reconhecer, por isso já existem vários conjuntos de dados públicos com imagens de carros.
Um deles é o popular
conjunto de dados SOCO (abreviação de Common Objects In Context), que possui imagens anotadas com máscaras de objetos. Este conjunto de dados contém mais de 12.000 imagens com máquinas já rotuladas. Aqui está um exemplo de imagem do conjunto de dados:

Esses dados são excelentes para o treinamento de um modelo baseado no Mask R-CNN.
Mas segure os cavalos, há notícias ainda melhores! Não somos os primeiros a querer treinar seu modelo usando o conjunto de dados COCO - muitas pessoas já fizeram isso antes de nós e compartilharam seus resultados. Portanto, em vez de treinar nosso modelo, podemos usar um modelo pronto que já pode reconhecer carros. Para o nosso projeto, usaremos o
modelo de código aberto da Matterport.Se dermos uma imagem da câmera para a entrada deste modelo, é isso que já obtemos "fora da caixa":

O modelo reconheceu não apenas carros, mas também objetos como semáforos e pessoas. É engraçado que ela reconheceu a árvore como planta de casa.
Para cada objeto reconhecido, o modelo Mask R-CNN retorna 4 itens:
- Tipo de objeto detectado (inteiro). O modelo COCO pré-treinado pode reconhecer 80 objetos comuns diferentes, como carros e caminhões. Uma lista completa deles pode ser encontrada aqui.
- O grau de confiança nos resultados do reconhecimento. Quanto maior o número, mais forte o modelo confia no reconhecimento do objeto.
- Uma caixa delimitadora para um objeto na forma de coordenadas XY de pixels na imagem.
- Uma "máscara" que mostra quais pixels dentro da caixa delimitadora fazem parte do objeto. Usando os dados da máscara, você pode encontrar o contorno do objeto.
Abaixo está o código Python para detectar a caixa delimitadora de máquinas usando os modelos Mask R-CNN e OpenCV pré-treinados:
import numpy as np import cv2 import mrcnn.config import mrcnn.utils from mrcnn.model import MaskRCNN from pathlib import Path
Depois de executar este script, uma imagem com um quadro ao redor de cada máquina detectada aparecerá na tela:

Além disso, as coordenadas de cada máquina serão exibidas no console:
Cars found in frame of video: Car: [492 871 551 961] Car: [450 819 509 913] Car: [411 774 470 856]
Então aprendemos a reconhecer carros na imagem.
Reconhecemos vagas vazias
Conhecemos as coordenadas de pixel de cada máquina. Observando vários quadros consecutivos, podemos determinar facilmente qual dos carros não se moveu e assumir que há vagas de estacionamento. Mas como entender que o carro saiu do estacionamento?
O problema é que os quadros das máquinas se sobrepõem parcialmente:

Portanto, se você imaginar que cada quadro representa um espaço de estacionamento, pode ser que ele esteja parcialmente ocupado pela máquina, quando na verdade está vazio. Precisamos encontrar uma maneira de medir o grau de interseção de dois objetos para procurar apenas os quadros "mais vazios".
Usaremos uma medida chamada Intersecção sobre união (proporção da área de interseção com a área total) ou IoU. A IoU pode ser encontrada calculando o número de pixels em que dois objetos se cruzam e divida pelo número de pixels ocupados por esses objetos:
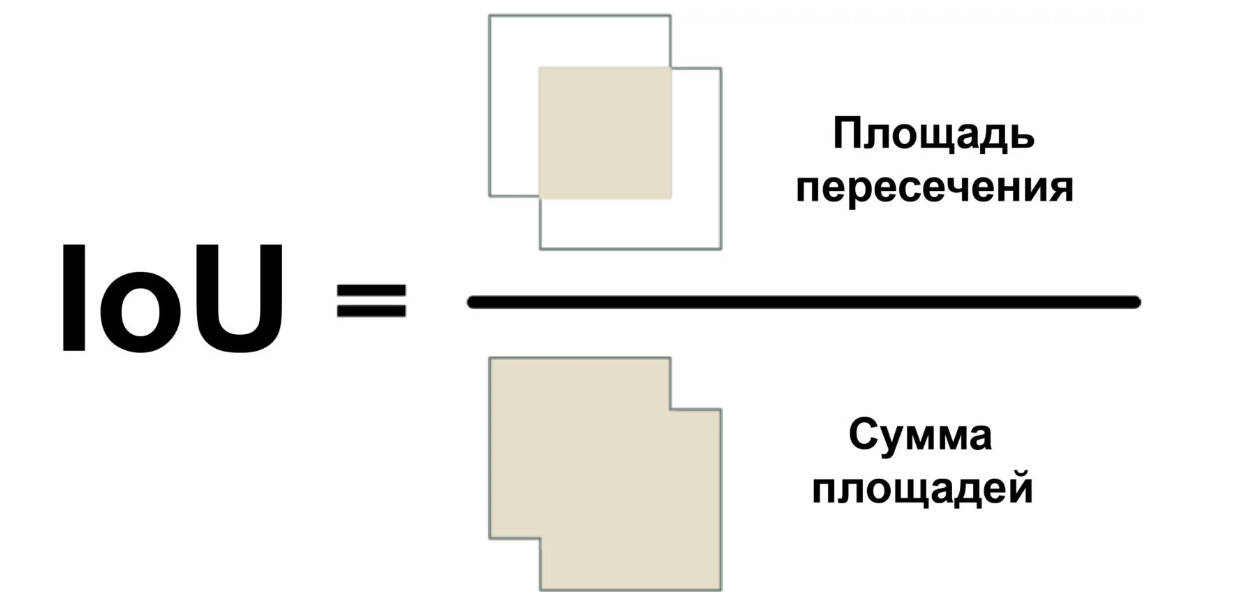
Assim, podemos entender como a estrutura delimitadora do carro se cruza com a estrutura do estacionamento. Isso facilitará determinar se o estacionamento é gratuito. Se o valor de IoU for baixo, como 0,15, o carro ocupará uma pequena parte do espaço de estacionamento. E se for alto, como 0,6, isso significa que o carro ocupa a maior parte do espaço e você não pode estacionar lá.
Como a IoU é usada com bastante frequência na visão computacional, é muito provável que as bibliotecas correspondentes implementem essa medida. Na nossa biblioteca Mask R-CNN, é implementada como uma função mrcnn.utils.compute_overlaps ().
Se tivermos uma lista de caixas delimitadoras para vagas de estacionamento, você poderá adicionar uma verificação da presença de carros nessa estrutura adicionando uma linha inteira ou duas de código:
O resultado deve ser algo como isto:
[ [1. 0.07040032 0. 0.] [0.07040032 1. 0.07673165 0.] [0. 0. 0.02332112 0.] ]
Nesta matriz bidimensional, cada linha reflete um quadro do espaço de estacionamento. E cada coluna indica com que intensidade cada um dos lugares se cruza com uma das máquinas detectadas. Um resultado de 1.0 significa que todo o local está completamente ocupado pelo carro, e um valor baixo como 0,02 indica que o carro subiu um pouco no lugar, mas você ainda pode estacionar nele.
Para encontrar lugares desocupados, basta verificar cada linha dessa matriz. Se todos os números estiverem próximos de zero, provavelmente o local é gratuito!
No entanto, lembre-se de que o reconhecimento de objetos nem sempre funciona perfeitamente com vídeos em tempo real. Embora o modelo baseado no Mask R-CNN seja bastante preciso, de tempos em tempos ele pode perder um carro ou dois em um quadro do vídeo. Portanto, antes de afirmar que o local é gratuito, é necessário garantir que ele permaneça assim pelos próximos 5 a 10 próximos quadros do vídeo. Dessa forma, podemos evitar situações em que o sistema marca erroneamente um local vazio devido a uma falha em um quadro do vídeo. Assim que garantirmos que o local permaneça livre por vários quadros, você poderá enviar uma mensagem!
Enviar SMS
A última parte do nosso transportador está enviando notificações por SMS quando aparece um espaço de estacionamento gratuito.
Enviar uma mensagem do Python é muito fácil se você usar o Twilio. O Twilio é uma API popular que permite enviar SMS de quase qualquer linguagem de programação com apenas algumas linhas de código. Obviamente, se você preferir um serviço diferente, poderá usá-lo. Não tenho nada a ver com o Twilio, é apenas a primeira coisa que vem à mente.
Para usar o Twilio, inscreva-se em uma
conta de avaliação , crie um número de telefone Twilio e obtenha as informações de autenticação da sua conta. Em seguida, instale a biblioteca do cliente:
$ pip3 install twilio
Depois disso, use o seguinte código para enviar a mensagem:
from twilio.rest import Client
Para adicionar a capacidade de enviar mensagens para o nosso script, basta copiar esse código lá. No entanto, você precisa garantir que a mensagem não seja enviada em todos os quadros, onde poderá ver o espaço livre. Portanto, teremos um sinalizador que no estado instalado não permitirá o envio de mensagens por algum tempo ou até que outro local seja desocupado.
Juntando tudo
import numpy as np import cv2 import mrcnn.config import mrcnn.utils from mrcnn.model import MaskRCNN from pathlib import Path from twilio.rest import Client
Para executar esse código, primeiro você precisa instalar o Python 3.6+, o
Matterport Mask R-CNN e o
OpenCV .
Escrevi especificamente o código o mais simples possível. Por exemplo, se ele vê um carro no primeiro quadro, ele conclui que todos eles estão estacionados. Tente experimentá-lo e veja se você pode melhorar sua confiabilidade.
Apenas alterando os identificadores dos objetos que o modelo está procurando, você pode transformar o código em algo completamente diferente. Por exemplo, imagine que você está trabalhando em uma estação de esqui. Depois de fazer algumas alterações, você pode transformar esse script em um sistema que reconheça automaticamente os praticantes de snowboard pulando da rampa e grave vídeos com saltos frios. Ou, se você trabalha em uma reserva natural, pode criar um sistema que conta zebras. Você é limitado apenas pela sua imaginação.
Mais artigos desse tipo podem ser lidos no canal de telegrama
Neuron (@neurondata)
Link de tradução alternativo:
tproger.ru/translations/parking-searching/Todo conhecimento. Experimente!