A IA de hoje é tecnicamente "fraca" - no entanto, é complexa e pode afetar significativamente a sociedade
 Você não precisa ser Cyrus Dully para saber como uma inteligência inteligente pode se tornar assustadora [um ator americano que interpretou o astronauta Dave Bowman no filme "Space Odyssey 2001" / aprox. perev.]
Você não precisa ser Cyrus Dully para saber como uma inteligência inteligente pode se tornar assustadora [um ator americano que interpretou o astronauta Dave Bowman no filme "Space Odyssey 2001" / aprox. perev.]A IA, ou inteligência artificial, é agora uma das áreas mais importantes do conhecimento. Problemas "insolúveis" estão sendo resolvidos, bilhões de dólares estão sendo investidos e a Microsoft até
contrata Common para nos dizer com calma poética, que coisa maravilhosa é essa - a IA. Isso mesmo.
E, como em qualquer nova tecnologia, pode ser difícil passar por todo esse hype. Eu venho pesquisando no campo de drones e IA há anos, mas até pode ser difícil para mim acompanhar tudo isso. Nos últimos anos, passei muito tempo procurando respostas para as perguntas mais simples, como:
- O que as pessoas querem dizer com "IA"?
- Qual é a diferença entre IA, aprendizado de máquina e aprendizado profundo?
- O que há de tão bom no aprendizado profundo?
- Quais tarefas difíceis anteriores agora são fáceis de resolver e o que ainda é difícil?
Eu sei que ninguém está interessado em tais coisas. Portanto, se você estiver interessado no que todos esses entusiastas da IA estão conectados no nível mais simples, é hora de olhar nos bastidores. Se você é um especialista em IA e lê relatórios da Conferência sobre Processamento de Informações Neurológicas (NIPS) por diversão, o artigo não será novidade para você - no entanto, esperamos esclarecimentos e correções de você nos comentários.
O que é IA?
Existe uma piada tão antiga na ciência da computação: qual é a diferença entre IA e automação? A automação é algo que pode ser feito usando um computador, e a IA é algo que gostaríamos de poder fazer. Assim que aprendemos a fazer algo, ele passa do campo da IA para a categoria de automação.
Essa piada é válida hoje, já que a IA não está definida com clareza suficiente. Inteligência Artificial simplesmente não é um termo técnico. Se você entrar na Wikipedia, diz que a IA é "a inteligência demonstrada pelas máquinas, em contraste com a inteligência natural demonstrada pelas pessoas e outros animais". Você não pode dizer menos claramente.
Em geral, existem dois tipos de IA: forte e fraca. A maioria das pessoas imagina uma IA forte quando ouvem falar da IA - é algum tipo de intelecto onisciente de Deus como Skynet ou Hal 9000, capaz de raciocinar e comparável ao humano, enquanto excede suas capacidades.
As IAs fracas são algoritmos altamente especializados, projetados para responder a perguntas úteis específicas em áreas estritamente definidas. Por exemplo, um programa de xadrez muito bom se enquadra nessa categoria. O mesmo pode ser dito sobre o software que ajusta com muita precisão os pagamentos do seguro. Em seu campo, essas IAs alcançam resultados impressionantes, mas em geral são muito limitadas.
Com exceção dos opuses de Hollywood, hoje nem chegamos perto de uma IA forte. Até o momento, qualquer IA é fraca, e a maioria dos pesquisadores nesta área concorda que as técnicas que inventamos para criar grandes IAs fracas provavelmente não nos aproximam da criação de uma IA forte.
Portanto, a IA de hoje é mais um termo de marketing do que técnico. A razão pela qual as empresas anunciam sua IA em vez da automação é porque desejam introduzir a IA de Hollywood na mente do público. No entanto, isso não é tão ruim. Se isso não for tomado muito estritamente, as empresas só querem dizer que, embora ainda estamos muito longe de uma IA forte, a IA fraca de hoje é muito mais capaz do que existia há vários anos.
E se você se distrair do marketing, então é. Em certas áreas, as capacidades das máquinas aumentaram dramaticamente, e principalmente graças a mais duas frases que estão na moda: aprendizado de máquina e aprendizado profundo.
 Filmado em um pequeno vídeo de engenheiros do Facebook, mostrando como a IA em tempo real reconhece gatos (uma tarefa também conhecida como o Santo Graal da Internet)
Filmado em um pequeno vídeo de engenheiros do Facebook, mostrando como a IA em tempo real reconhece gatos (uma tarefa também conhecida como o Santo Graal da Internet)Aprendizado de máquina
MO é uma maneira especial de criar inteligência de máquina. Suponha que você queira lançar um foguete e preveja para onde ele irá. Em geral, não é tão difícil: a gravidade é muito bem estudada, você pode escrever as equações e calcular para onde irá, com base em várias variáveis - como velocidade e posição inicial.
No entanto, essa abordagem se torna embaraçosa se nos voltarmos para uma área cujas regras não são tão conhecidas e claras. Suponha que você queira que o computador diga se há gatos em algumas imagens. Como você escreverá as regras que descrevem a visão em todos os pontos de vista possíveis em todas as combinações possíveis de bigode e orelhas?
Hoje, a abordagem MO é bem conhecida: em vez de tentar anotar todas as regras, você cria um sistema que pode derivar independentemente um conjunto de regras internas depois de estudar um grande número de exemplos. Em vez de descrever gatos, você simplesmente mostra à sua IA várias fotos de gatos e permite que ele entenda por si mesmo o que é um gato e o que não é.
E hoje é a abordagem perfeita. Um sistema de autoaprendizagem baseado em dados pode ser aprimorado simplesmente adicionando dados. E se nossa espécie é capaz de fazer algo muito bem, é gerar, armazenar e gerenciar dados. Quer aprender a reconhecer melhor os gatos? A Internet está gerando milhões de exemplos neste exato momento.
O crescente fluxo de dados é uma das razões para o crescimento explosivo dos algoritmos MO nos últimos tempos. Outros motivos estão relacionados ao uso desses dados.
Além dos dados, há mais dois problemas relacionados a isso na região de Moscou:
- Como me lembro do que aprendi? Como armazenar e apresentar no computador as comunicações e regras que deduzi dos dados?
- Como eu aprendo? Como alterar a representação armazenada em resposta a novos exemplos e melhorar?
Em outras palavras, o que exatamente está sendo treinado com base em todos esses dados?
No MO, a representação computacional do treinamento que armazenamos é um modelo. O tipo de modelo usado é muito importante: determina como a IA aprende, com quais dados pode aprender e quais perguntas você pode fazer.
Vejamos um exemplo muito simples. Suponha que compremos figos em uma mercearia e queremos fazer uma IA com o MO que nos diga se está madura. Isso deve ser fácil, pois no caso dos figos, mais suave é o doce.
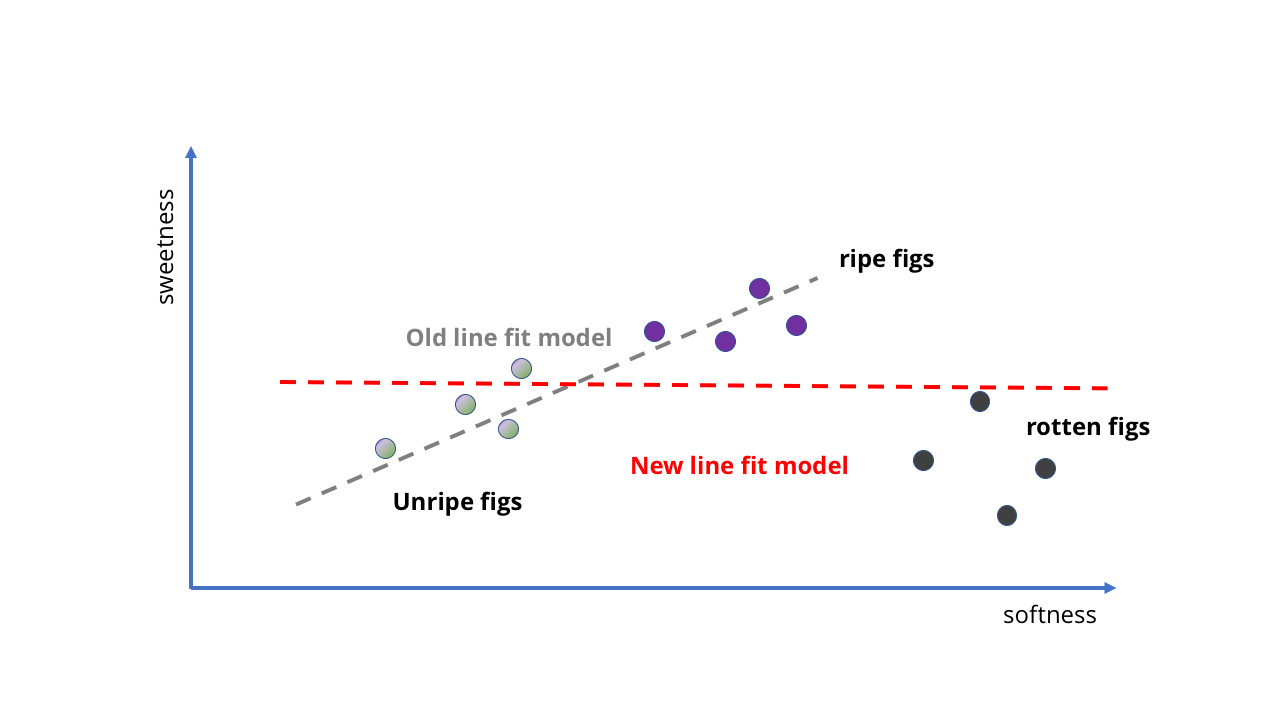
Podemos colher várias amostras de figos maduros e verdes, ver como são doces e depois colocá-las no gráfico e ajustar a linha reta para isso. Esta linha será o nosso modelo.
 IA de embriões na forma de "quanto mais suave, mais doce"
IA de embriões na forma de "quanto mais suave, mais doce" Com a adição de novos dados, a tarefa se torna mais complicada.
Com a adição de novos dados, a tarefa se torna mais complicada.Dê uma olhada! A linha reta segue implicitamente a idéia de que "quanto mais suaves elas são, mais doces", e nem precisávamos escrever nada. Nosso feto da IA não sabe nada sobre o teor de açúcar ou o amadurecimento das frutas, mas pode prever a doçura de uma fruta apertando-a.
Como treinar um modelo para torná-lo melhor? Podemos coletar ainda mais amostras e desenhar outra linha reta para obter previsões mais precisas (como na segunda figura acima). No entanto, os problemas imediatamente se tornam aparentes. Até agora, treinamos nossa IA de figo em bagas de qualidade - e se coletarmos dados do pomar? De repente, temos não apenas frutos maduros, mas também podres. Eles são muito macios, mas definitivamente não são adequados para comer.
O que fazemos? Bem, como esse é um modelo de MO, podemos apenas fornecer mais dados a ela, certo?
Como mostra a primeira imagem abaixo, neste caso, obteremos resultados completamente sem sentido. A linha simplesmente não é adequada para descrever o que acontece quando a fruta fica madura demais. Nosso modelo não se encaixa mais na estrutura de dados.
Em vez disso, temos que mudar isso e usar um modelo melhor e mais complexo - talvez uma parábola ou algo semelhante. Essa mudança complica o aprendizado porque desenhar curvas requer matemática mais sofisticada do que desenhar uma linha reta.
 Ok, provavelmente a ideia de usar uma linha reta para uma IA complexa não teve muito sucesso
Ok, provavelmente a ideia de usar uma linha reta para uma IA complexa não teve muito sucesso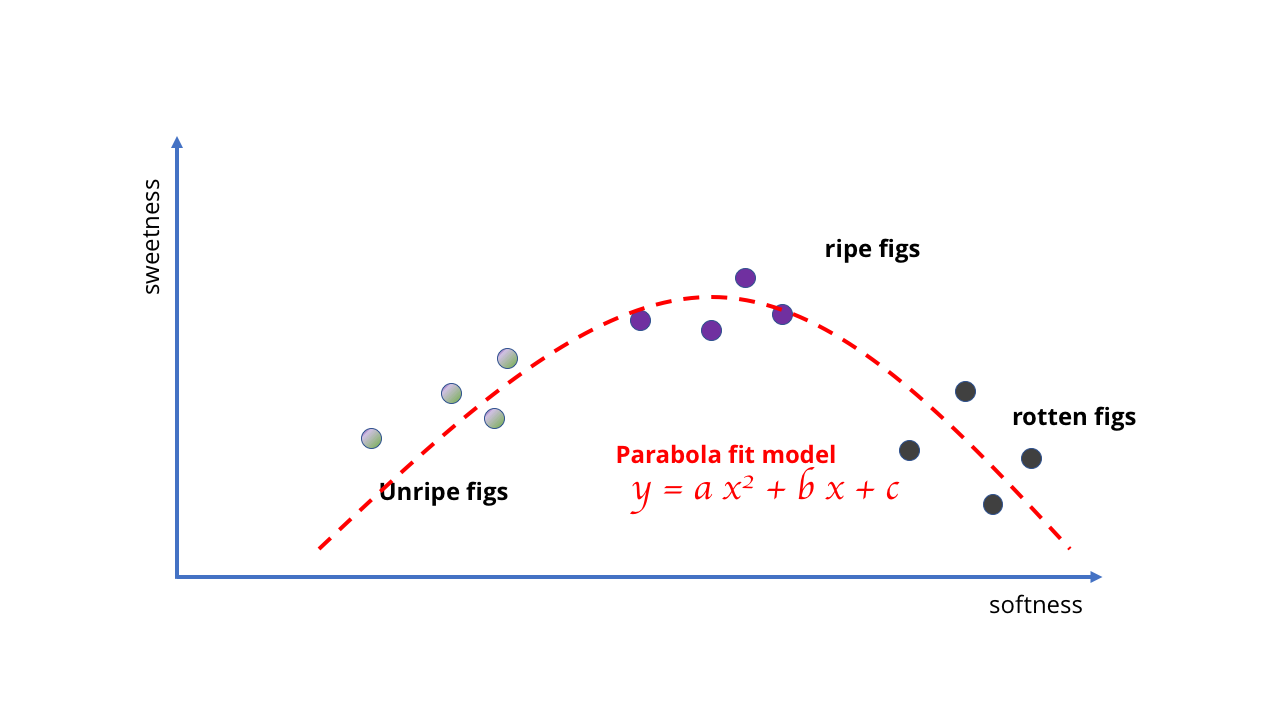 É necessária uma matemática mais complicada
É necessária uma matemática mais complicadaO exemplo é bastante estúpido, mas mostra que a escolha do modelo determina as possibilidades de aprendizado. No caso das figs, os dados são simples e os modelos podem ser simples. Mas se você está tentando aprender algo mais complexo, são necessários modelos mais complexos. Assim como nenhuma quantidade de dados faz um modelo linear refletir o comportamento de bagas podres, é impossível selecionar uma curva simples correspondente a um monte de fotos para criar um algoritmo de visão computacional.
Portanto, a dificuldade do MO é criar e selecionar os modelos certos para as tarefas correspondentes. Precisamos de um modelo complexo o suficiente para descrever as relações e estruturas realmente complexas, mas simples o suficiente para que você possa trabalhar com ele e treiná-lo. Portanto, embora a Internet, os smartphones etc. tenham criado montanhas de dados incríveis para aprender, ainda precisamos dos modelos certos para tirar proveito desses dados.
É aqui que o aprendizado profundo entra em cena.

Aprendizagem profunda
O aprendizado profundo é o aprendizado de máquina que usa um certo tipo de modelo: redes neurais profundas.
As redes neurais são um tipo de modelo MO que usa uma estrutura semelhante a neurônios no cérebro para cálculos e previsões. Os neurônios nas redes neurais são organizados em camadas: cada camada executa um conjunto de cálculos simples e passa a resposta para a próxima.
O modelo em camadas permite cálculos mais complexos. Uma rede simples com um pequeno número de camadas de neurônios é suficiente para reproduzir a linha reta ou a parábola que usamos acima. Redes neurais profundas são redes neurais com um grande número de camadas, com dezenas ou até centenas; daí o nome deles. Com tantas camadas, você pode criar modelos incrivelmente poderosos.
Essa oportunidade é uma das principais razões para a enorme popularidade das redes neurais profundas nos últimos tempos. Eles podem aprender várias coisas complexas sem forçar um pesquisador humano a definir regras, e isso nos permitiu criar algoritmos que podem resolver uma variedade de problemas que os computadores não podiam abordar antes.
No entanto, outro aspecto contribuiu para o sucesso das redes neurais: o treinamento.
A "memória" de um modelo é um conjunto de parâmetros numéricos que determina como ele fornece respostas às perguntas feitas. Treinar um modelo significa ajustar esses parâmetros para que o modelo dê as melhores respostas possíveis.
Em nosso modelo com figos, procuramos a equação da reta. Essa é uma tarefa simples de regressão e existem fórmulas que fornecerão a resposta em uma única etapa.
 Rede neural simples e rede neural profunda
Rede neural simples e rede neural profundaCom modelos mais complexos, as coisas não são tão simples. Uma linha reta e uma parábola podem ser facilmente representadas por vários números, mas uma rede neural profunda pode ter milhões de parâmetros, e o conjunto de dados para seu treinamento também pode consistir em milhões de exemplos. Uma solução analítica em uma etapa não existe.
Felizmente, há um truque estranho: você pode começar com uma rede neural ruim e melhorá-la com ajustes graduais.
Aprender o modelo MO dessa maneira é semelhante a testar um aluno usando testes. Cada vez que fazemos uma avaliação, comparamos quais respostas devem estar na opinião do modelo com as respostas "corretas" nos dados de treinamento. Então fazemos uma melhoria e executamos o teste novamente.
Como sabemos quais parâmetros ajustar e quanto? As redes neurais têm um recurso tão interessante quando, para muitos tipos de treinamento, você pode não apenas obter uma avaliação no teste, mas também calcular quanto será alterado em resposta a uma alteração em cada parâmetro. Em termos matemáticos, uma estimativa é uma função do valor e, para a maioria dessas funções, podemos calcular facilmente o gradiente dessa função em relação ao espaço do parâmetro.
Agora sabemos exatamente de que maneira precisamos ajustar os parâmetros para aumentar a pontuação e podemos ajustar a rede por etapas sucessivas em todas as melhores e melhores "direções", até chegar a um ponto em que nada pode ser melhorado. Isso geralmente é chamado de escalar uma colina, porque é realmente como subir uma colina: se você subir constantemente, acabará no topo.
 Você viu? Top!
Você viu? Top!Graças a isso, é fácil melhorar a rede neural. Se sua rede possui uma boa estrutura, após receber novos dados, você não precisa começar do zero. Você pode começar com os parâmetros disponíveis e aprender novamente com os novos dados. Sua rede irá melhorar gradualmente. A IA mais proeminente de hoje - do reconhecimento de gatos no Facebook às tecnologias que a Amazon (provavelmente) usa em lojas sem vendedores - se baseia nesse simples fato.
Essa é a chave para mais uma razão pela qual a defesa civil se espalhou tão rápida e amplamente: subir uma colina permite que você pegue uma rede neural treinada para alguma tarefa e a treine novamente para executar outra, mas semelhante. Se você treinou a IA para reconhecer bem os gatos, essa rede pode ser usada para treinar a IA que reconhece cães ou girafas sem precisar começar do zero. Comece com a IA para gatos, avalie-a pela qualidade do reconhecimento de cães e depois suba a colina, melhorando a rede!
Portanto, nos últimos 5-6 anos, houve uma melhoria acentuada nas capacidades da IA. Várias peças do quebra-cabeça se uniram de maneira sinérgica: a Internet gerou uma enorme quantidade de dados para aprender. Os cálculos, especialmente os paralelos nas GPUs, tornaram possível processar esses conjuntos enormes. Finalmente, redes neurais profundas tornaram possível tirar proveito desses kits e criar modelos MO incrivelmente poderosos.
E tudo isso significa que algumas coisas que antes eram extremamente difíceis agora são muito fáceis de fazer.
E o que podemos fazer agora? Reconhecimento de padrões
Talvez o aprendizado profundo mais profundo (com pena do trocadilho) e o primeiro impacto tenham tido no campo da visão computacional - em particular, no reconhecimento de objetos nas fotografias. Alguns anos atrás, este quadrinho do xkcd descreveu perfeitamente a vanguarda da ciência da computação:

Hoje, o reconhecimento de pássaros e até mesmo certos tipos de pássaros é uma tarefa trivial que um aluno do ensino médio corretamente motivado pode resolver. O que mudou?
A idéia do reconhecimento visual de objetos é fácil de descrever, mas difícil de implementar: objetos complexos consistem em conjuntos de objetos mais simples, que por sua vez consistem em formas e linhas mais simples. Os rostos consistem em olhos, narizes e bocas, e esses consistem em círculos e linhas, e assim por diante.
Portanto, o reconhecimento facial torna-se uma questão de reconhecer padrões nos quais os olhos e bocas estão localizados, o que pode exigir o reconhecimento da forma dos olhos e da boca a partir de linhas e círculos.
Esses padrões são chamados de recursos e, antes do aprendizado profundo para reconhecimento, era necessário descrever todos os recursos manualmente e programar o computador para encontrá-los. Por exemplo, existe o famoso algoritmo de reconhecimento de rosto
Viola-Jones , baseado no fato de que as sobrancelhas e o nariz são geralmente mais claros que as órbitas oculares, de modo que eles formam uma forma T brilhante com dois pontos escuros. O algoritmo, de fato, está procurando formas em T semelhantes.
O método Viola-Jones funciona bem e é surpreendentemente rápido e serve como base para o reconhecimento facial em câmeras baratas, etc. Mas, obviamente, nem todo objeto que você precisa reconhecer se presta a essa simplificação, e as pessoas criaram padrões cada vez mais complexos e de baixo nível. Para que os algoritmos funcionassem corretamente, era necessária uma equipe de doutores em ciências, eles eram muito sensíveis e propensos a falhas.
A grande inovação ocorreu graças à defesa civil e, em particular, a um certo tipo de rede neural chamada rede neural convolucional. Redes neurais convolucionais, os SNS são redes profundas com uma certa estrutura, inspiradas na estrutura do córtex visual do cérebro dos mamíferos. Essa estrutura permite que o SNA aprenda independentemente a hierarquia de linhas e padrões para o reconhecimento de objetos, em vez de esperar que os doutores em ciências passem anos pesquisando quais recursos são mais adequados para isso. Por exemplo, o SNA, treinado em rostos, aprenderá sua própria representação interna de linhas e círculos que se formam nos olhos, ouvidos e narizes, e assim por diante.
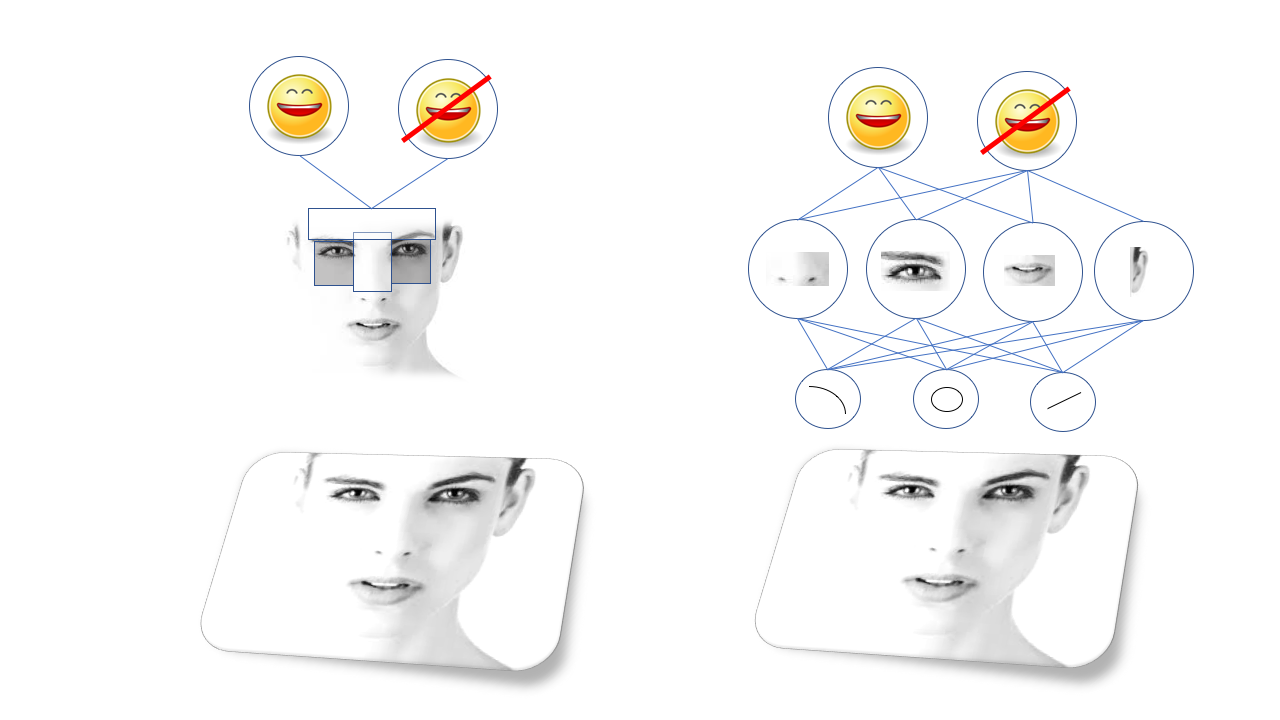 Algoritmos visuais antigos (método Viola-Jones, à esquerda) dependem de recursos selecionados manualmente e redes neurais profundas (à direita) em sua própria hierarquia de recursos mais complexos, compostos por outros mais simples
Algoritmos visuais antigos (método Viola-Jones, à esquerda) dependem de recursos selecionados manualmente e redes neurais profundas (à direita) em sua própria hierarquia de recursos mais complexos, compostos por outros mais simplesO SNA foi incrivelmente bom para a visão computacional, e logo os pesquisadores foram capazes de treiná-los para realizar todos os tipos de tarefas no reconhecimento visual, desde encontrar gatos na foto até identificar pedestres que entraram na câmera de um robomóvel.
Tudo isso é maravilhoso, mas há outra razão para uma disseminação tão rápida e generalizada do SNA - é a facilidade com que eles se adaptam. Lembre-se de subir uma colina?
Se nosso aluno do ensino médio quiser reconhecer um determinado pássaro, ele pode pegar qualquer uma das muitas redes visuais com código-fonte aberto e treiná-lo em seu próprio conjunto de dados, sem nem mesmo entender como a matemática subjacente a ele funciona.Naturalmente, isso pode ser expandido ainda mais.Quem esta ai (reconhecimento facial)
Suponha que você queira treinar uma rede que reconheça não apenas as faces, mas uma face específica. Você pode treinar a rede para reconhecer uma pessoa específica, depois outra pessoa e assim por diante. No entanto, leva tempo para treinar redes, e isso significaria que, para cada nova pessoa, seria necessário treinar novamente a rede. Na verdadeEm vez disso, podemos começar com uma rede treinada para reconhecer rostos em geral. Seus neurônios estão configurados para reconhecer todas as estruturas faciais: olhos, ouvidos, bocas e assim por diante. Depois, basta alterar a saída: em vez de forçá-la a reconhecer certos rostos, ordene que ela forneça uma descrição de rosto na forma de centenas de números que descrevem a curvatura do nariz ou a forma dos olhos, e assim por diante. A rede pode fazer isso porque já “sabe” em quais componentes a face consiste.Obviamente, você não define tudo isso diretamente. Em vez disso, você treina a rede mostrando um conjunto de faces e comparando a saída. Você também a ensina para que ela faça descrições semelhantes entre si da mesma pessoa e muito diferentes umas das outras descrições de pessoas diferentes. Matematicamente falando, você treina uma rede para construir uma correspondência com as imagens das faces de um ponto em um espaço de recursos, onde a distância cartesiana entre pontos pode ser usada para determinar sua similaridade. Alterar a rede neural do reconhecimento de faces (à esquerda) para a descrição das faces (à direita) requer apenas a alteração do formato dos dados de saída, sem alterar sua
Alterar a rede neural do reconhecimento de faces (à esquerda) para a descrição das faces (à direita) requer apenas a alteração do formato dos dados de saída, sem alterar sua base.Agora você pode reconhecer faces comparando as descrições de cada uma das faces criadas pela rede neuralDepois de treinar a rede, você pode reconhecer facilmente rostos. Você pega a pessoa original e obtém sua descrição. Em seguida, dê uma nova cara e compare a descrição fornecida pela rede com o original. Se eles estiverem perto o suficiente, você diz que é a mesma pessoa. E agora você mudou de uma rede capaz de reconhecer uma face para o que pode ser usado para reconhecer qualquer face!Essa flexibilidade estrutural é outra razão para a utilidade de redes neurais profundas. Um grande número de vários modelos de MO para visão computacional já foi desenvolvido e, embora estejam se desenvolvendo em direções muito diferentes, a estrutura básica de muitos deles é baseada em SNAs iniciais, como Alexnet e Resnet.Eu até ouvi histórias sobre pessoas que usam redes neurais visuais para trabalhar com dados de séries temporais ou medições de sensores. Em vez de criar uma rede especial para analisar o fluxo de dados, eles treinaram uma rede neural de código aberto projetada para visão computacional para literalmente observar as formas dos gráficos de linhas.Essa flexibilidade é uma coisa boa, mas não infinita. Para resolver outros problemas, são necessários outros tipos de redes.
base.Agora você pode reconhecer faces comparando as descrições de cada uma das faces criadas pela rede neuralDepois de treinar a rede, você pode reconhecer facilmente rostos. Você pega a pessoa original e obtém sua descrição. Em seguida, dê uma nova cara e compare a descrição fornecida pela rede com o original. Se eles estiverem perto o suficiente, você diz que é a mesma pessoa. E agora você mudou de uma rede capaz de reconhecer uma face para o que pode ser usado para reconhecer qualquer face!Essa flexibilidade estrutural é outra razão para a utilidade de redes neurais profundas. Um grande número de vários modelos de MO para visão computacional já foi desenvolvido e, embora estejam se desenvolvendo em direções muito diferentes, a estrutura básica de muitos deles é baseada em SNAs iniciais, como Alexnet e Resnet.Eu até ouvi histórias sobre pessoas que usam redes neurais visuais para trabalhar com dados de séries temporais ou medições de sensores. Em vez de criar uma rede especial para analisar o fluxo de dados, eles treinaram uma rede neural de código aberto projetada para visão computacional para literalmente observar as formas dos gráficos de linhas.Essa flexibilidade é uma coisa boa, mas não infinita. Para resolver outros problemas, são necessários outros tipos de redes. E até este ponto, os assistentes virtuais demoraram muito tempo
E até este ponto, os assistentes virtuais demoraram muito tempoO que você disse? (Reconhecimento de Fala)
Catalogação de imagens e visão computacional não são as únicas áreas de ressurgimento da IA. Outra área na qual os computadores chegaram muito longe é o reconhecimento de fala, especialmente na tradução da fala para a escrita.A idéia básica no reconhecimento de fala é bastante semelhante ao princípio da visão computacional: reconhecer coisas complexas na forma de conjuntos de coisas mais simples. No caso da fala, o reconhecimento de sentenças e frases é baseado no reconhecimento de palavras, que é baseado no reconhecimento de sílabas ou, para ser mais preciso, em fonemas. Então, quando alguém diz "Bond, James Bond", ouvimos BON + DUH + JAY + MMS + BON + DUH.Na visão, os recursos são organizados espacialmente, e o SNA processa essa estrutura. Em boatos, esses recursos são organizados no tempo. As pessoas podem falar rápida ou devagar, sem um começo e um fim de fala claros. Precisamos de um modelo capaz de perceber os sons à medida que eles chegam, como pessoa, em vez de esperar e procurar frases completas neles. Não podemos, como na física, dizer que espaço e tempo são a mesma coisa.O reconhecimento de sílabas individuais é bastante fácil, mas elas são difíceis de isolar. Por exemplo, "Olá, lá" pode parecer "inferno, não, eles são" ... Portanto, para qualquer sequência de sons, geralmente existem várias combinações de sílabas realmente faladas.Para entender tudo isso, precisamos da oportunidade de estudar a sequência em um determinado contexto. Se eu ouvir um som, o mais provável é que a pessoa tenha dito "olá, querida" ou "diabos, não são veados?" Aqui, novamente, o aprendizado de máquina vem em socorro. Com um conjunto suficientemente grande de padrões de palavras faladas, você pode aprender as frases mais prováveis. E quanto mais exemplos você tiver, melhor será o resultado.Para isso, as pessoas usam redes neurais recorrentes, RNS. Na maioria dos tipos de redes neurais, como o SNA envolvido na visão computacional, as conexões entre os neurônios funcionam em uma direção, da entrada à saída (matematicamente falando, esses são gráficos acíclicos direcionados). No RNS, a saída de neurônios pode ser redirecionada de volta para neurônios do mesmo nível, para eles mesmos ou ainda mais. Isso permite que o RNS tenha sua própria memória (se você estiver familiarizado com a lógica binária, essa situação é semelhante à operação dos gatilhos).O SNA trabalha para uma abordagem: nós alimentamos uma imagem para ela e ela fornece algumas descrições. O RNS mantém a memória interna do que foi dado a ela anteriormente e fornece respostas com base no que ela já viu, além do que ela vê agora.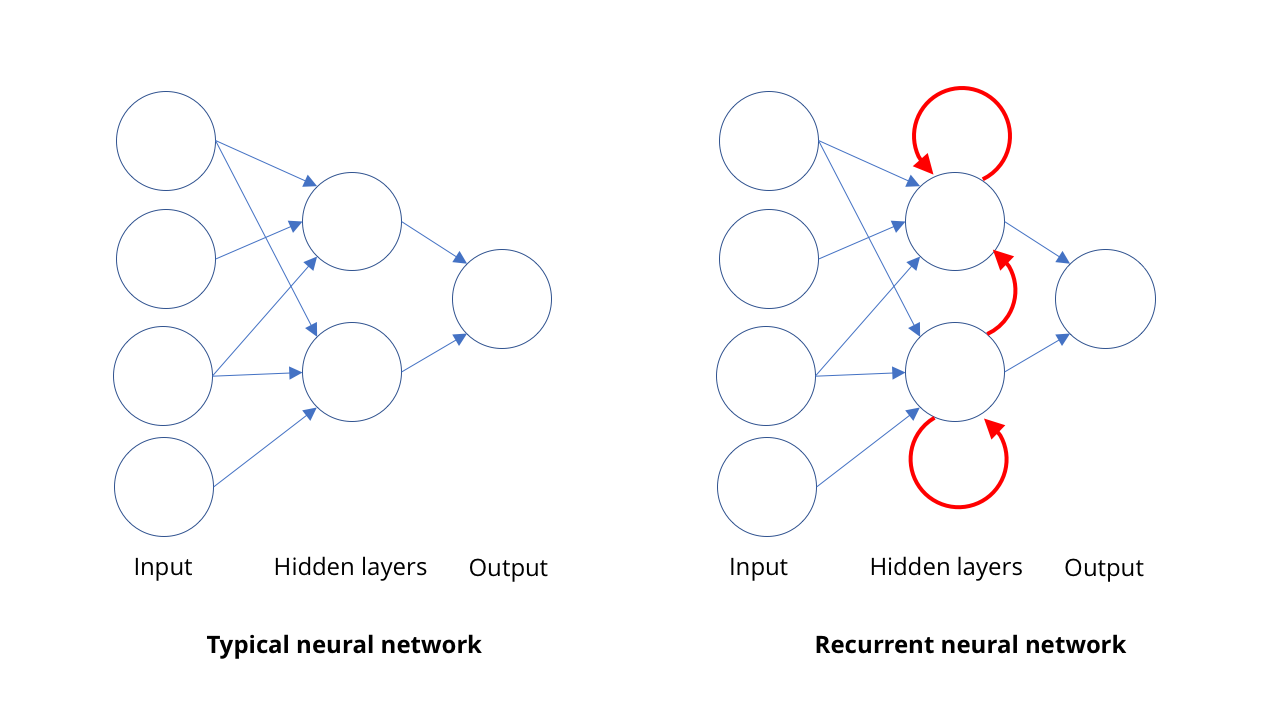 Essa propriedade de memória no RNS permite que eles não apenas “escutem” as sílabas que chegam a ela uma por uma. Isso permite que a rede aprenda quais sílabas se juntam para formar uma palavra e qual a probabilidade de certas seqüências.Usando o RNS, é possível obter uma transcrição muito boa da fala humana - a tal ponto que os computadores agora podem superar os humanos em algumas medições da precisão da transcrição. Obviamente, os sons não são a única área em que as seqüências aparecem. Hoje, o RNS também é usado para determinar sequências de movimentos para reconhecer ações em vídeo.
Essa propriedade de memória no RNS permite que eles não apenas “escutem” as sílabas que chegam a ela uma por uma. Isso permite que a rede aprenda quais sílabas se juntam para formar uma palavra e qual a probabilidade de certas seqüências.Usando o RNS, é possível obter uma transcrição muito boa da fala humana - a tal ponto que os computadores agora podem superar os humanos em algumas medições da precisão da transcrição. Obviamente, os sons não são a única área em que as seqüências aparecem. Hoje, o RNS também é usado para determinar sequências de movimentos para reconhecer ações em vídeo.Mostre-me como você pode se mover (falsificações profundas e redes generativas)
Até agora, conversamos sobre modelos MO projetados para reconhecimento: diga-me o que é mostrado na figura, diga-me o que a pessoa disse. Mas esses modelos são capazes de mais - os modelos GO atuais também podem ser usados para criar conteúdo.É quando as pessoas falam sobre deepfake - vídeos e imagens falsos incrivelmente realistas, criados usando o GO. Há algum tempo, um funcionário da televisão alemã provocou uma extensa discussão política criando um vídeo falsoem que o ministro das Finanças grego mostrou à Alemanha o dedo médio. Para criar este vídeo, precisávamos de uma equipe de editores que trabalhassem na criação de um programa de TV, mas no mundo moderno, isso pode ser feito em poucos minutos por qualquer pessoa com acesso a um computador de jogo de tamanho médio.Tudo isso é bastante triste, mas não tão sombrio nessa área - meu vídeo favorito sobre o tema desta tecnologia é mostrado no topo.Essa equipe criou um modelo capaz de processar um vídeo com os movimentos de dança de uma pessoa e criar um vídeo com outra pessoa repetindo esses movimentos, realizando-os magicamente no nível de especialista. Também é interessante ler o trabalho científico que o acompanha .Pode-se imaginar que, usando todas as técnicas discutidas por nós, é possível treinar uma rede que receba a imagem de um dançarino e diga onde estão seus braços e pernas. E, nesse caso, obviamente, em algum nível, a rede aprendeu a conectar os pixels da imagem à localização dos membros humanos. Dado que uma rede neural é apenas dados armazenados em um computador, não um cérebro biológico, deve ser possível pegar esses dados e seguir na direção oposta - para obter pixels que correspondam à localização dos membros.Comece com uma rede que extrai poses de imagens de pessoas.
Os modelos MO que podem fazer isso são chamados de modelos generativos. gerar - gerar, produzir, criar / aprox. transl.]. Todos os modelos anteriores que consideramos são chamados discriminatórios [eng. discriminar - distinguir / aprox. transl.]. A diferença entre eles pode ser imaginada da seguinte forma: um modelo discriminatório para gatos examina fotos e distingue entre fotos contendo gatos e fotos onde não estão. O modelo generativo cria imagens de gatos com base em, digamos, uma descrição de como deve ser um gato. Modelos generativos que “desenham” imagens de objetos são criados usando as mesmas estruturas de SNA dos modelos usados para reconhecer esses objetos. E esses modelos podem ser treinados da mesma maneira que outros modelos MO.No entanto, o truque é apresentar uma "avaliação" para o treinamento. Ao treinar um modelo discriminatório, existe uma maneira simples de avaliar a exatidão e a incorreta da resposta - como se a rede distinguisse corretamente o cão do gato. No entanto, como avaliar a qualidade da imagem do gato resultante ou sua precisão?E aqui para uma pessoa que adora teorias da conspiração e acredita que todos estamos condenados, a situação se torna um pouco assustadora. Veja bem, a melhor maneira que inventamos para aprender redes generativas não é fazer você mesmo. Para isso, simplesmente usamos uma rede neural diferente.Essa tecnologia é chamada de rede adversária generativa, ou GSS. Você força duas redes neurais a competir entre si: uma rede está tentando criar falsificações, por exemplo, desenhando um novo dançarino com base nas posturas antigas. Outra rede é treinada para encontrar a diferença entre exemplos reais e falsos usando vários exemplos reais de dançarinos.E essas duas redes jogam um jogo competitivo. Daí a palavra "contraditório" no título. A rede generativa tenta fazer falsificações convincentes, e a rede discriminatória tenta entender onde está a falsificação e onde está a coisa real.No caso de um vídeo com uma dançarina, uma rede discriminatória separada foi criada durante o processo de treinamento, fornecendo respostas sim / não simples. Ela olhou para a imagem da pessoa e a descrição da posição de seus membros, e decidiu se a imagem era uma fotografia real ou uma imagem desenhada por um modelo generativo.
Modelos generativos que “desenham” imagens de objetos são criados usando as mesmas estruturas de SNA dos modelos usados para reconhecer esses objetos. E esses modelos podem ser treinados da mesma maneira que outros modelos MO.No entanto, o truque é apresentar uma "avaliação" para o treinamento. Ao treinar um modelo discriminatório, existe uma maneira simples de avaliar a exatidão e a incorreta da resposta - como se a rede distinguisse corretamente o cão do gato. No entanto, como avaliar a qualidade da imagem do gato resultante ou sua precisão?E aqui para uma pessoa que adora teorias da conspiração e acredita que todos estamos condenados, a situação se torna um pouco assustadora. Veja bem, a melhor maneira que inventamos para aprender redes generativas não é fazer você mesmo. Para isso, simplesmente usamos uma rede neural diferente.Essa tecnologia é chamada de rede adversária generativa, ou GSS. Você força duas redes neurais a competir entre si: uma rede está tentando criar falsificações, por exemplo, desenhando um novo dançarino com base nas posturas antigas. Outra rede é treinada para encontrar a diferença entre exemplos reais e falsos usando vários exemplos reais de dançarinos.E essas duas redes jogam um jogo competitivo. Daí a palavra "contraditório" no título. A rede generativa tenta fazer falsificações convincentes, e a rede discriminatória tenta entender onde está a falsificação e onde está a coisa real.No caso de um vídeo com uma dançarina, uma rede discriminatória separada foi criada durante o processo de treinamento, fornecendo respostas sim / não simples. Ela olhou para a imagem da pessoa e a descrição da posição de seus membros, e decidiu se a imagem era uma fotografia real ou uma imagem desenhada por um modelo generativo. O GSS força duas redes a competir entre si: uma produz falsificações e a outra tenta distinguir falsas do original.No
O GSS força duas redes a competir entre si: uma produz falsificações e a outra tenta distinguir falsas do original.No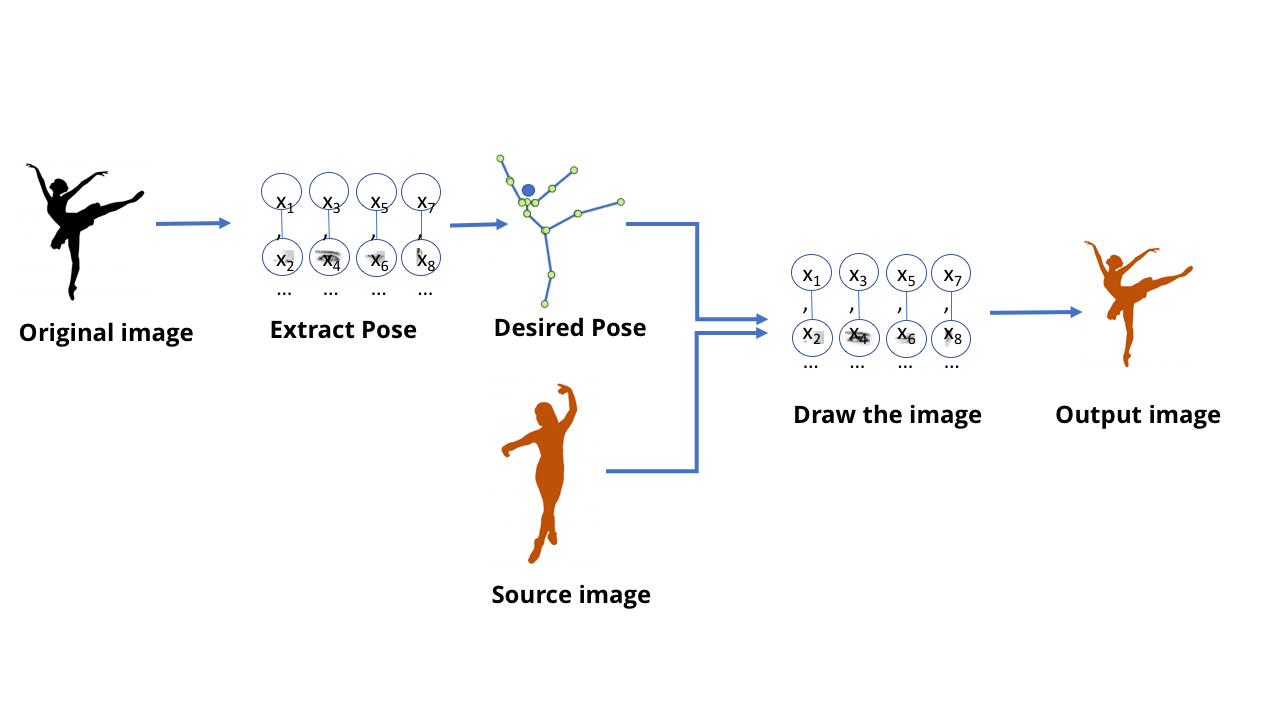 fluxo de trabalho final, apenas um modelo generativo é usado para criar as imagens necessáriasDurante as repetidas rodadas de treinamento, os modelos foram ficando cada vez melhores. Isso é semelhante a uma competição entre um especialista em joias e um especialista em avaliação - competindo com um oponente forte, cada um deles se torna mais forte e inteligente. Finalmente, quando os modelos funcionam bem o suficiente, você pode pegar um modelo generativo e usá-lo separadamente.Modelos generativos pós-treinamento podem ser muito úteis para criar conteúdo. Por exemplo, eles podem gerar imagens de rostos (que podem ser usados para treinar programas de reconhecimento de rosto) ou fundos para videogames.Para que tudo isso funcione corretamente, é necessário muito trabalho em ajustes e correções, mas, em essência, a pessoa aqui atua como árbitro. É a IA que trabalha uma contra a outra, fazendo grandes melhorias.
fluxo de trabalho final, apenas um modelo generativo é usado para criar as imagens necessáriasDurante as repetidas rodadas de treinamento, os modelos foram ficando cada vez melhores. Isso é semelhante a uma competição entre um especialista em joias e um especialista em avaliação - competindo com um oponente forte, cada um deles se torna mais forte e inteligente. Finalmente, quando os modelos funcionam bem o suficiente, você pode pegar um modelo generativo e usá-lo separadamente.Modelos generativos pós-treinamento podem ser muito úteis para criar conteúdo. Por exemplo, eles podem gerar imagens de rostos (que podem ser usados para treinar programas de reconhecimento de rosto) ou fundos para videogames.Para que tudo isso funcione corretamente, é necessário muito trabalho em ajustes e correções, mas, em essência, a pessoa aqui atua como árbitro. É a IA que trabalha uma contra a outra, fazendo grandes melhorias.Então, devemos esperar o surgimento do Skynet e do Hal 9000 em um futuro próximo?
Em todo documentário sobre a natureza, no final, há um episódio em que os autores falam sobre como toda essa grandiosa beleza desaparecerá em breve devido ao quão terríveis as pessoas são. Penso que, no mesmo espírito, cada discussão responsável sobre a IA deve incluir uma seção sobre suas limitações e conseqüências sociais.
Primeiro, vamos enfatizar mais uma vez as limitações atuais da IA: a principal idéia que espero que você tenha aprendido ao ler este artigo é que o sucesso do MO ou da IA depende extremamente dos modelos de treinamento que escolhemos. Se as pessoas não organizam bem a rede ou usam materiais inadequados para treinamento, essas distorções podem ser muito óbvias para todos.
As redes neurais profundas são incrivelmente flexíveis e poderosas, mas não possuem propriedades mágicas. Apesar de você usar redes neurais profundas para RNS e SNA, sua estrutura é muito diferente e, portanto, as pessoas devem determiná-lo de qualquer maneira. Portanto, mesmo se você puder pegar o SNA para carros e treiná-lo novamente para reconhecimento de pássaros, não poderá pegar esse modelo e treiná-lo novamente para reconhecimento de fala.
Se o descrevemos em termos humanos, tudo parece ter entendido como o córtex visual e o córtex auditivo funcionam, mas não temos idéia de como o córtex cerebral funciona e onde podemos começar a abordá-lo.
Isso significa que, em um futuro próximo, provavelmente não veremos a IA divina de Hollywood. Mas isso não significa que, na sua forma atual, a IA não possa ter um sério impacto na sociedade.
Muitas vezes imaginamos como a IA nos substitui, ou seja, como os robôs literalmente fazem nosso trabalho, mas, na realidade, isso não vai acontecer. Dê uma olhada na radiologia, por exemplo: às vezes as pessoas, olhando para o sucesso da visão computacional, dizem que a IA substituirá os radiologistas. Talvez não cheguemos ao ponto em que não teremos um único radiologista humano. Mas é possível um futuro em que, para uma centena de radiologistas de hoje, a IA permita que cinco a dez deles façam o trabalho de todos os outros. Se esse cenário for realizado, para onde irão os 90 médicos restantes?
Mesmo que a geração moderna de IA não corresponda às esperanças de seus apoiadores mais otimistas, ela ainda levará a consequências muito extensas. E teremos que resolver esses problemas, portanto, um bom começo provavelmente será dominar o básico dessa área.