
Com o advento de câmeras de alta qualidade em telefones celulares, estamos fotografando cada vez mais, gravando vídeos dos momentos brilhantes e importantes de nossas vidas. Muitos de nós têm arquivos de fotos que datam de dezenas de anos e milhares de fotografias, nos quais está se tornando cada vez mais difícil navegar. Lembre-se de quanto tempo levou para encontrar a foto certa há vários anos.
Um dos objetivos do Mail.ru Cloud é fornecer o acesso e a pesquisa mais convenientes no seu arquivo de fotos e vídeos. Para isso, nós, a equipe de visão de máquina do Mail.ru, criamos e implementamos sistemas inteligentes de processamento de fotos: pesquisa por objetos, cenas, rostos, etc. Outra tecnologia tão marcante é o reconhecimento de pontos turísticos. E hoje vou falar sobre como resolvemos esse problema com a ajuda do Deep Learning.
Imagine a situação: você saiu de férias e trouxe um monte de fotos. E em uma conversa com os amigos, eles pediram para mostrar como você visitou um palácio, castelo, pirâmide, templo, lago, cachoeira, montanha, etc. Você começa a rolar freneticamente pela pasta com fotos, tentando encontrar a correta. Provavelmente, você não o encontra entre centenas de imagens e diz que será exibido mais tarde.
Resolvemos esse problema agrupando fotos personalizadas em álbuns. Isso facilita encontrar as imagens corretas em apenas alguns cliques. Agora temos álbuns em rostos, objetos e cenas, além de atrações.
As fotos com pontos de referência são importantes porque geralmente exibem momentos significativos de nossas vidas (por exemplo, viagens). Podem ser fotografias no fundo de alguma estrutura arquitetônica ou um canto da natureza intocado pelo homem. Portanto, precisamos encontrar essas fotos e oferecer aos usuários acesso fácil e rápido a elas.
Reconhecimento de recursos
Mas há uma nuance: você não pode simplesmente pegar e treinar algum modelo para reconhecer os pontos turísticos, há muitas dificuldades.
- Em primeiro lugar, não podemos descrever claramente o que é um "marco". Não podemos dizer por que um prédio é um ponto de referência e, ao lado dele, não é. Este não é um conceito formalizado, o que complica a formulação do problema de reconhecimento.
- Em segundo lugar, os pontos turísticos são extremamente diversos. Pode ser edifícios históricos ou culturais - templos, palácios, castelos. Estes podem ser os monumentos mais diversos. Pode ser objetos naturais - lagos, desfiladeiros, cachoeiras. E um modelo deve ser capaz de encontrar todas essas atrações.
- Em terceiro lugar, existem muito poucas imagens com vistas, de acordo com nossos cálculos, elas são encontradas apenas em 1-3% das fotos dos usuários. Portanto, não podemos nos permitir erros de reconhecimento, porque se mostrarmos uma foto a uma pessoa sem um ponto de interesse, ela será imediatamente perceptível e causará perplexidade e reação negativa. Ou, pelo contrário, mostramos à pessoa uma foto com um ponto de referência em Nova York, e ele nunca esteve na América. Portanto, o modelo de reconhecimento deve ter um baixo FPR (taxa de falsos positivos).
- Quarto, cerca de 50% dos usuários, ou mais, desativam o armazenamento de informações geográficas ao fotografar. Precisamos levar isso em conta e determinar o local apenas a partir da imagem. A maioria dos serviços que hoje, de alguma forma, conseguem trabalhar com locais de interesse, fazem isso graças aos dados geográficos. Nossos requisitos iniciais eram mais rígidos.
Vou mostrar agora com exemplos.
Aqui estão objetos semelhantes, três catedrais góticas francesas. A esquerda é a Catedral de Amiens, no meio da Catedral de Reims, à direita é Notre Dame de Paris.

Até uma pessoa precisa de algum tempo para olhá-las e entender que essas são catedrais diferentes, e a máquina também deve ser capaz de lidar com ela e mais rapidamente do que uma pessoa.
E aqui está um exemplo de outra dificuldade: as três fotos no slide são Notre Dame de Paris, tiradas de diferentes ângulos. As fotos acabaram sendo muito diferentes, mas todas precisam ser reconhecidas e encontradas.

Objetos naturais são completamente diferentes dos arquitetônicos. À esquerda, Cesaréia, em Israel, à direita, o Parque Inglês, em Munique.

Nestas fotografias, há muito poucos detalhes característicos para os quais o modelo possa “entender”.
Nosso método
Nosso método é completamente baseado em redes neurais convolucionais profundas. Como abordagem de aprendizado, eles escolheram o chamado aprendizado do currículo - o aprendizado em várias etapas. Para trabalhar com mais eficiência tanto na presença de dados geográficos quanto na ausência deles, fizemos uma inferência especial (conclusão). Vou falar sobre cada uma das etapas com mais detalhes.
Datacet
O combustível para o aprendizado de máquina são os dados. E antes de tudo, precisávamos coletar um conjunto de dados para o treinamento do modelo.
Dividimos o mundo em quatro regiões, cada uma das quais utilizada em diferentes estágios do treinamento. Em seguida, foram tirados países em cada região, para cada país uma lista de cidades foi compilada e um banco de dados de fotografias de suas atrações foi compilado. Exemplos de dados são apresentados abaixo.

Primeiro, tentamos treinar nosso modelo na base resultante. Os resultados foram ruins. Eles começaram a analisar e os dados estão muito "sujos". Cada atração tinha uma grande quantidade de lixo. O que fazer Analisar manualmente toda a enorme quantidade de dados é caro, sombrio e pouco inteligente. Portanto, fizemos uma limpeza automática da base, durante a qual o processamento manual é usado apenas em uma etapa: para cada atração, selecionamos manualmente 3-5 fotografias de referência que contêm com precisão a atração desejada em uma perspectiva mais ou menos correta. Acontece rapidamente, porque o volume desses dados de referência é pequeno em relação a todo o banco de dados. Em seguida, a limpeza automática baseada em redes neurais convolucionais profundas já é executada.
Além disso, usarei o termo "incorporação", pelo qual entenderei o seguinte. Temos uma rede neural convolucional, treinamos para classificação, cortamos a última camada de classificação, tiramos algumas imagens, dirigimos pela rede e obtivemos um vetor numérico na saída. Vou chamá-lo de incorporação.
Como eu disse, nosso treinamento foi realizado em várias etapas, correspondendo a partes de nosso banco de dados. Portanto, primeiro adotamos uma rede neural do estágio anterior ou uma rede de inicialização.
Iremos exibir as fotos dos pontos turísticos pela rede e realizar várias participações. Agora você pode limpar a base. Tiramos todas as fotos do conjunto de dados para esta atração e também conduzimos cada foto pela rede. Temos um monte de casamentos e, para cada um deles, consideramos as distâncias para a incorporação de padrões. Depois calculamos a distância média e, se for mais do que um certo limite, que é o parâmetro do algoritmo, consideramos que essa não é uma atração turística. Se a distância média for menor que o limite, deixamos esta foto.
Como resultado, obtivemos um banco de dados que contém mais de 11 mil atrações de mais de 500 cidades em 70 países do mundo - mais de 2,3 milhões de fotos. Agora é hora de lembrar que a maioria das fotos não contém atrações. Essas informações precisam ser compartilhadas de alguma forma com nossos modelos. Portanto, adicionamos 900 mil fotos sem vistas ao nosso banco de dados e treinamos nosso modelo no conjunto de dados resultante.
Para medir a qualidade do treinamento, introduzimos um teste offline. Com base no fato de que as vistas são encontradas apenas em cerca de 1-3% das fotografias, compilamos manualmente um conjunto de 290 fotografias que mostram as vistas. São fotografias diferentes e bastante complexas, com um grande número de objetos tirados de diferentes ângulos, de modo que o teste é o mais difícil possível para o modelo. Pelo mesmo princípio, selecionamos 11 mil fotografias sem pontos turísticos, que também são bastante complexos, e tentamos encontrar objetos muito semelhantes aos pontos turísticos disponíveis em nosso banco de dados.
Para avaliar a qualidade do treinamento, medimos a precisão do nosso modelo a partir de fotografias com e sem vistas. Essas são nossas duas principais métricas.
Abordagens existentes
Há relativamente pouca informação sobre o reconhecimento da visão na literatura científica. A maioria das soluções é baseada em recursos locais. A idéia é que tenhamos uma certa imagem de solicitação e uma imagem do banco de dados. Nestas figuras, encontramos sinais locais - pontos-chave e os comparamos. Se o número de correspondências for grande o suficiente, achamos que encontramos um ponto de interesse.
Até o momento, o melhor método é o método proposto pelo Google, DELF (recursos locais profundos), no qual uma comparação dos recursos locais é combinada com o aprendizado profundo. Ao executar a imagem de entrada através da rede de convolução, obtemos alguns sinais DELF.

Como é o reconhecimento das atrações? Temos um banco de dados de fotos e uma imagem de entrada, e queremos entender se há ou não uma atração turística. Executamos todas as imagens através do DELF, obtemos os sinais correspondentes para a base e a imagem de entrada. Em seguida, realizamos uma pesquisa usando o método dos vizinhos mais próximos e, na saída, obtemos imagens candidatas com sinais. Comparamos esses sinais com a ajuda da verificação geométrica: se eles forem aprovados com êxito, acreditamos que há um ponto de interesse na imagem.
Rede Neural Convolucional
Para o Deep Learning, o pré-treinamento é crucial. Portanto, pegamos a base das cenas e pré-treinamos nela nossa rede neural. Porque assim? Uma cena é um objeto complexo que inclui um grande número de outros objetos. E a atração é um caso especial da cena. Como modelo de pré-treinamento, podemos dar ao modelo uma idéia de alguns recursos de baixo nível que podem ser generalizados para o reconhecimento bem-sucedido das atrações.
Como modelo, usamos uma rede neural da família de redes Residual. Sua principal característica é que eles usam um bloco residual, que inclui uma conexão de salto, que permite que o sinal passe livremente sem entrar em camadas com pesos. Com essa arquitetura, você pode treinar qualitativamente redes profundas e lidar com o efeito do gradiente de desfoque, o que é muito importante ao aprender.
Nosso modelo é o Wide ResNet 50-2, uma modificação do ResNet 50, na qual o número de convoluções no bloco interno de gargalos é dobrado.

A rede é muito eficiente. Realizamos testes em nosso banco de dados de cenas e foi isso que obtivemos:
O Wide ResNet foi quase o dobro da rede ResNet 200. E a velocidade da operação é muito importante para a operação. Com base na totalidade dessas circunstâncias, tomamos o Wide ResNet 50-2 como nossa principal rede neural.
Treinamento
Para treinar a rede, precisamos de perda (função de perda). Para selecioná-lo, decidimos usar a abordagem de aprendizado métrico: uma rede neural é treinada para que representantes da mesma classe sejam reunidos em um cluster. Ao mesmo tempo, clusters para diferentes classes devem estar o mais afastados possível. Para atrações, usamos a perda de centro, que reúne pontos da mesma classe para um determinado centro. Uma característica importante dessa abordagem é que ela não requer amostragem negativa, o que nas fases posteriores do treinamento é um procedimento bastante difícil.
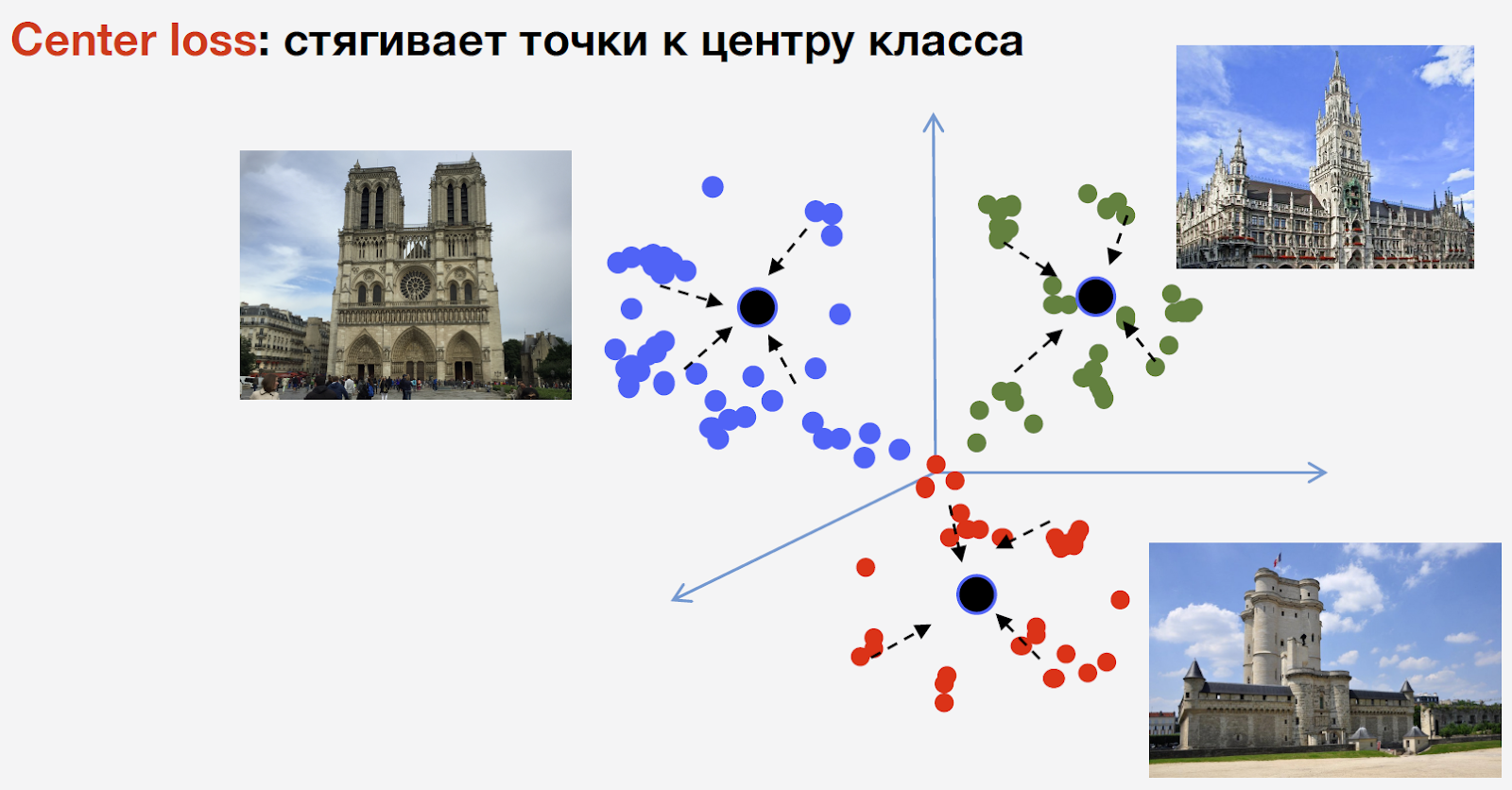
Deixe-me lembrá-lo de que temos n classes de atrações e outra classe de “não atrações”; a perda de centro não é usada para isso. Queremos dizer que um ponto de referência é o mesmo objeto, e há uma estrutura nele; portanto, é aconselhável considerar um centro para ele. Mas nem uma atração turística pode ser qualquer coisa, e considerar o centro para ele não é razoável.
Depois juntamos tudo e criamos um modelo para o treinamento. Consiste em três partes principais:
- Rede neural convolucional Wide ResNet 50-2, pré-treinada com base em cenas;
- Partes de incorporação consistindo em uma camada totalmente conectada e uma camada de norma de lote;
- Um classificador, que é uma camada totalmente conectada, seguido por um par de perda Softmax e perda Center.

Como você se lembra, nossa base é dividida em 4 partes por região do mundo. Usamos essas quatro partes como parte do paradigma de aprendizado do currículo. Em cada estágio, temos o conjunto de dados atual, adicionamos outra parte do mundo a ele e obtemos um novo conjunto de dados de treinamento.
O modelo consiste em três partes e, para cada uma delas, usamos nossa própria taxa de aprendizado no treinamento. Isso é necessário para que a rede possa aprender não apenas as vistas da nova parte do conjunto de dados que adicionamos, mas também não esquecer os dados já aprendidos. Depois de muitas experiências, essa abordagem acabou sendo a mais eficaz.
Então, treinamos o modelo. Você precisa entender como isso funciona. Vamos usar o mapa de ativação de classe para ver qual parte da imagem é mais responsiva à nossa rede neural. Na imagem abaixo, na primeira linha, as imagens de entrada e na segunda elas são sobrepostas ao mapa de ativação de classe da grade, que treinamos na etapa anterior.

O mapa de calor mostra em quais partes da imagem a rede presta mais atenção. A partir do mapa de ativação da classe, podemos ver que nossa rede neural aprendeu com sucesso o conceito de atração.
Inferência
Agora você precisa de alguma forma usar esse conhecimento para obter o resultado. Como usamos a perda do Center para treinamento, parece bastante lógico inferir também calcular o tserotóide para atrações.
Para isso, participamos das imagens do conjunto de treinamento para algum tipo de atração, por exemplo, para o Cavaleiro de Bronze. Nós os rodamos pela rede, obtemos casamentos, média e conseguimos um centróide.
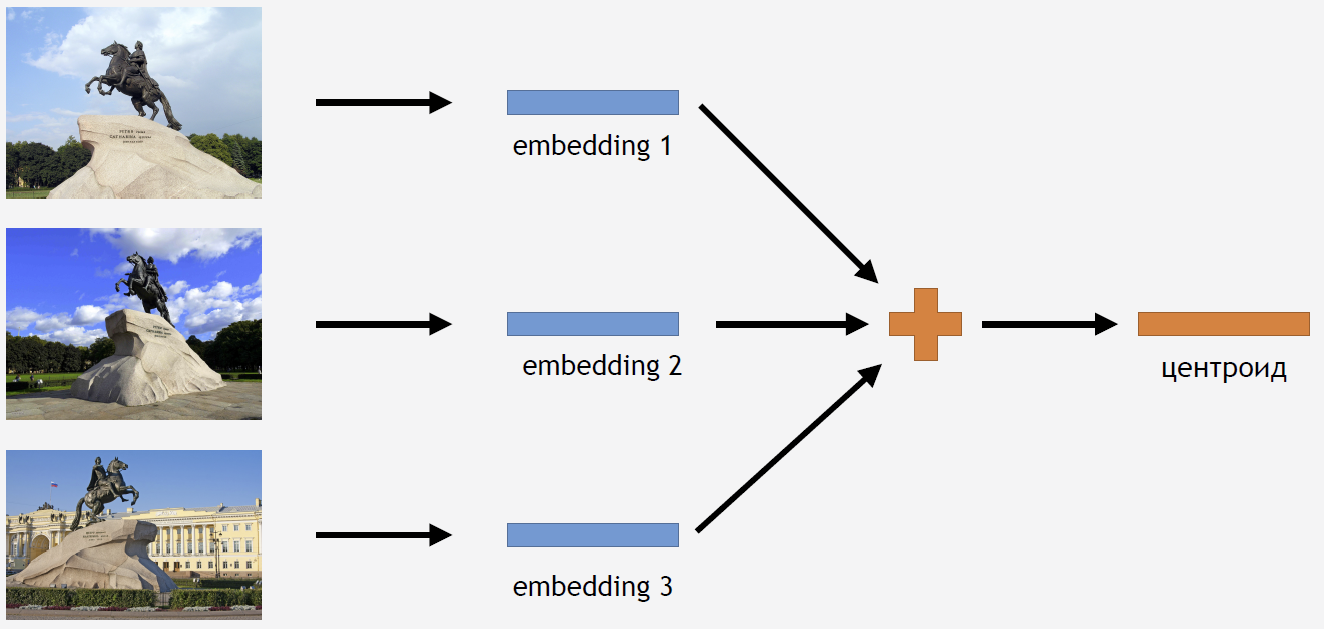
Mas surge a pergunta: quantos centróides para uma atração faz sentido calcular? A princípio, a resposta parece clara e lógica: um centróide. Mas isso acabou não sendo bem assim. No início, também decidimos fazer um centróide e obtivemos um resultado muito bom. Então, por que você precisa tomar alguns centróides?
Em primeiro lugar, nossos dados não são totalmente limpos. Embora tenhamos limpado o conjunto de dados, removemos apenas o lixo definitivo. E poderíamos ter imagens que não poderiam ser consideradas lixo, mas que pioram o resultado.
Por exemplo, eu tenho uma aula de referência do Palácio de Inverno. Eu quero contar um centróide para ele. Mas o conjunto incluía várias fotografias na Praça do Palácio e no arco do Edifício do Estado Maior. Se considerarmos o centróide em todas as imagens, ele não ficará muito estável. É necessário, de alguma forma, agrupar seus casamentos, obtidos a partir da grade usual, pegar apenas o centróide responsável pelo Palácio de Inverno e calcular a média de acordo com esses dados.

Em segundo lugar, as fotografias podem ser tiradas de diferentes ângulos.
Vou citar a torre sineira de Belfort, em Bruges, como ilustração desse comportamento. Dois centróides são contados para ela. Na linha superior da imagem estão as fotos mais próximas do primeiro centróide e na segunda linha - aquelas que estão mais próximas do segundo centróide:

O primeiro centróide é responsável pelas fotografias em close mais “inteligentes” tiradas da Praça do Mercado de Bruges. E o segundo centróide é responsável por fotografias tiradas de longe, de ruas adjacentes.
Acontece que, calculando vários centróides por classe de um ponto de interesse, podemos exibir ângulos diferentes desse ponto de interesse em inferência.
Então, como encontramos esses conjuntos para calcular centróides? Aplicamos o cluster hierárquico aos conjuntos de dados para cada ponto de interesse - link completo. Com sua ajuda, encontramos clusters válidos pelos quais calcularemos centróides. Por agrupamentos válidos, entendemos aqueles que, como resultado do agrupamento, contêm pelo menos 50 fotografias. Os clusters restantes são descartados. Como resultado, descobriu-se que cerca de 20% das vistas têm mais de um centróide.
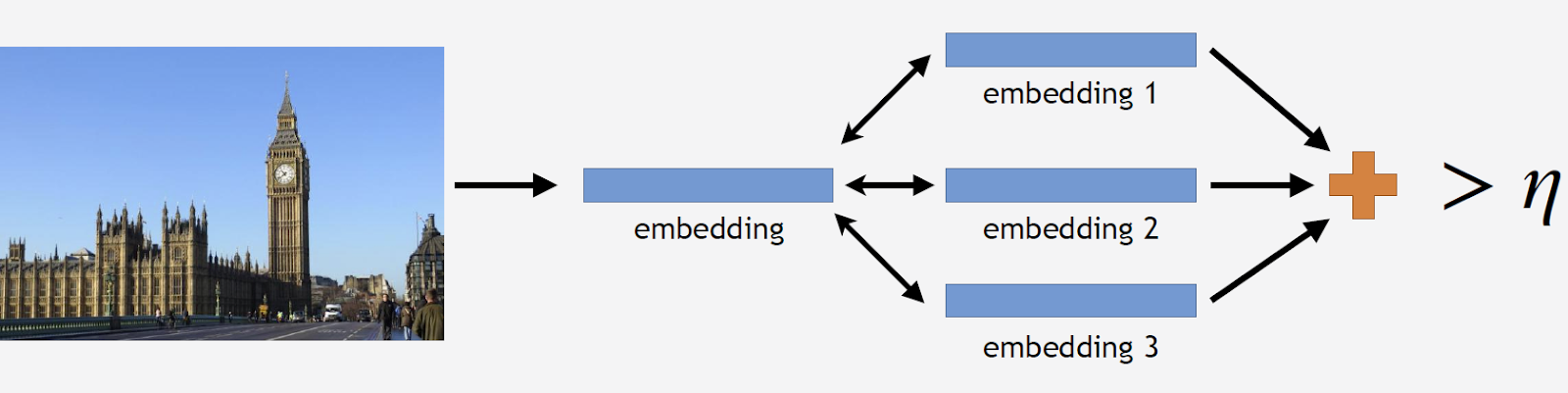
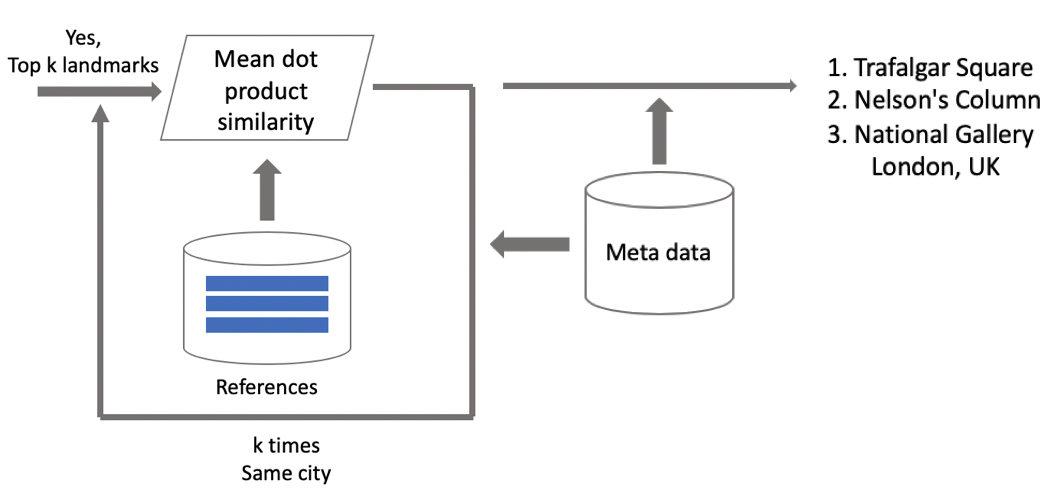
Agora inferência. Nós o calculamos em dois estágios: primeiro, executamos a imagem de entrada através de nossa rede neural convolucional e obtemos incorporação e, em seguida, usando o produto escalar, comparamos incorporação com centróides. Se as imagens contiverem dados geográficos, restringimos a pesquisa aos centróides, relacionados às atrações localizadas em um quadrado de 1 por 1 km a partir do local da gravação. Isso permite pesquisar com mais precisão, escolha um limite mais baixo para comparação subsequente. Se a distância obtida for maior que o limite, que é um parâmetro do algoritmo, dizemos que na foto existe um ponto de interesse com o valor máximo do produto escalar. Se menos, então isso não é uma atração turística.
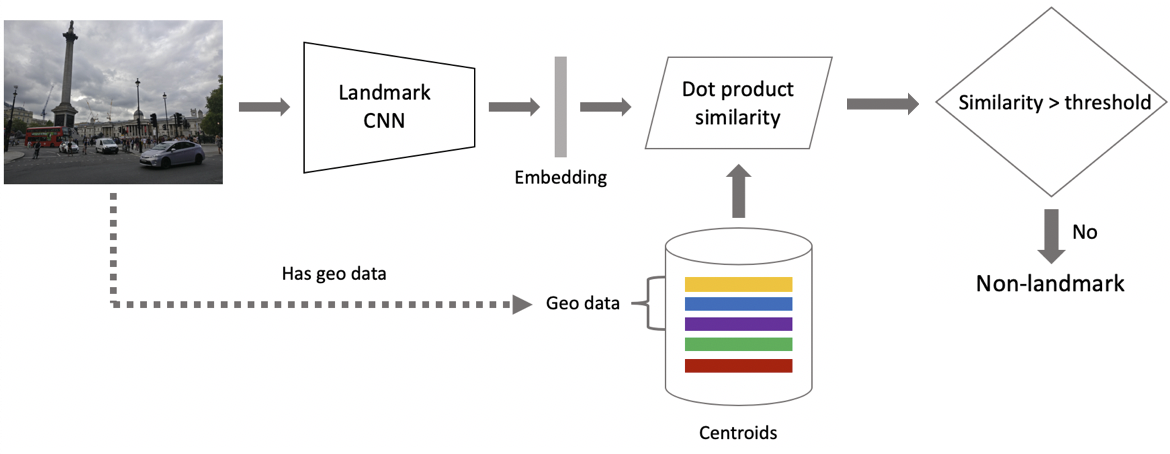
Suponha que a foto contenha um ponto de referência. Se tivermos dados geográficos, usamos-os e exibimos a resposta. Se não houver dados geográficos, faremos uma verificação adicional. Quando limpamos o conjunto de dados, fizemos um conjunto de imagens de referência para cada classe de atrações. Para eles, podemos contar as incorporações e, em seguida, calculamos a distância média entre elas e a incorporação da imagem solicitada. Se for mais do que algum limite, a verificação será aprovada, incluiremos metadados e exibiremos o resultado. É importante observar que podemos executar esse procedimento para várias atrações encontradas na imagem.
Resultados do teste
Comparamos nosso modelo com o DELF, para o qual adotamos os parâmetros nos quais ele apresentou os melhores resultados em nosso teste. Os resultados foram quase os mesmos.
: ( 100 ), 87 % , . : 85,3 %. 46 %, — .
/B- . 10 %, 3 %, 13 %.
DELF. GPU DELF 7 , 7 , 1 . CPU DELF . CPU 15 . , .
:
. .
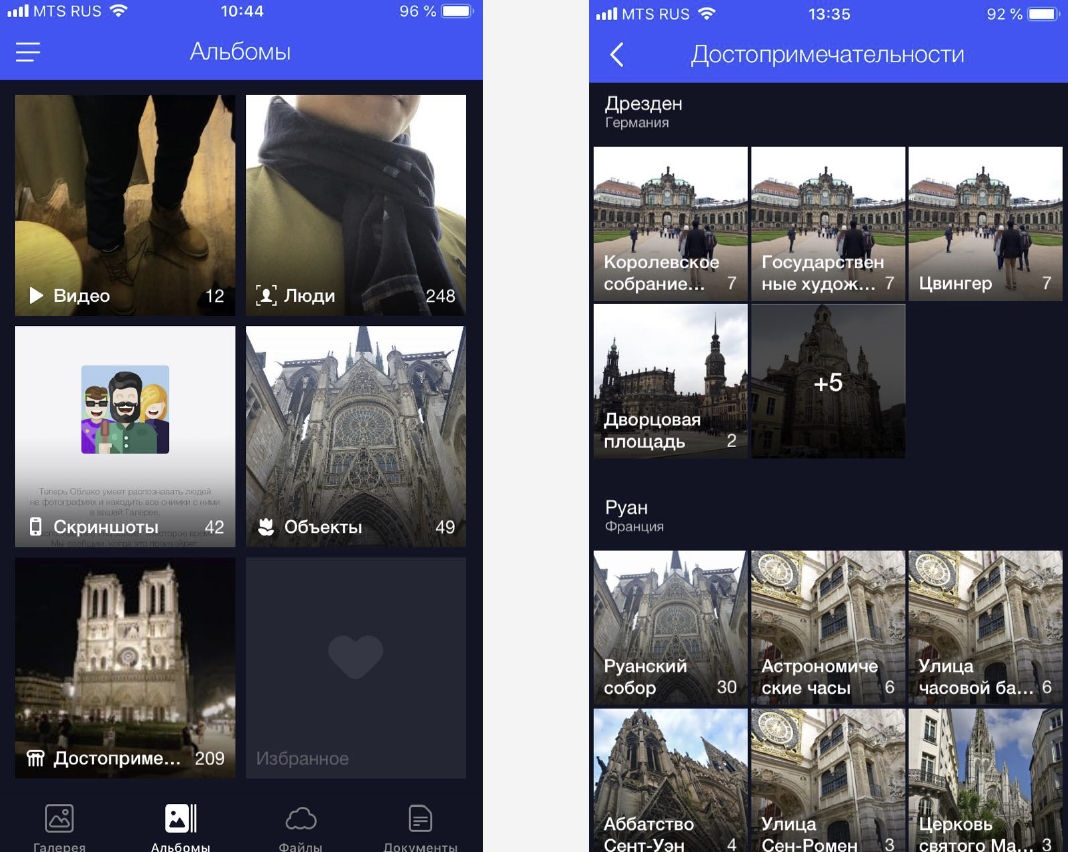
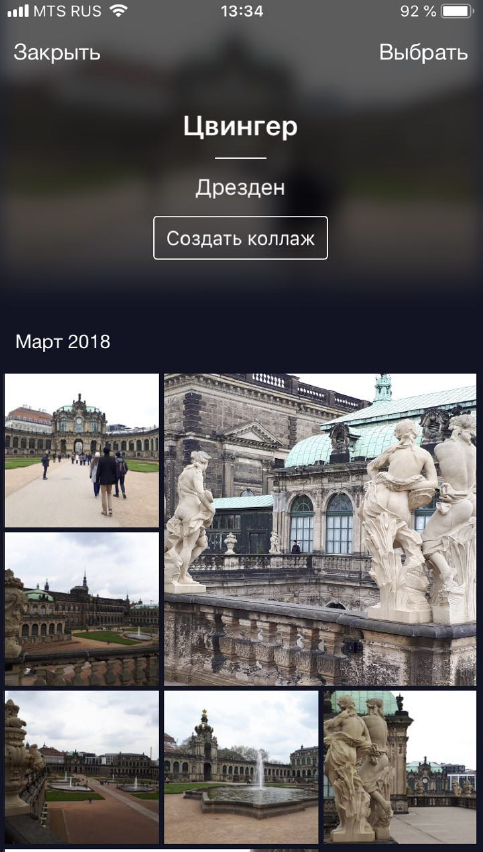
, . «», «», «». , . , .
: , , . Instagram , , — .
.
- . , . .
- deep metric learning, .
- curriculum learning — . . inference , .
, — . , , . - . !