Olá pessoal! Meu nome é Pavel Agaletsky. Eu trabalho como líder de uma equipe que desenvolve um sistema de entrega Lamoda. Em 2018, falei na conferência HighLoad ++ e hoje quero apresentar uma transcrição do meu relatório.
Meu tópico é dedicado à experiência de nossa empresa na implantação de sistemas e serviços em diferentes ambientes. A partir de nossos tempos pré-históricos, quando implantamos todos os sistemas em servidores virtuais regulares, terminando com uma transição gradual do Nomad para uma implantação no Kubernetes. Vou lhe dizer por que fizemos isso e quais problemas tivemos no processo.
Implantar aplicativos na VM
Para começar, há três anos, todos os sistemas e serviços da empresa foram implantados em servidores virtuais comuns. Tecnicamente, foi organizado de forma que todo o código de nossos sistemas permanecesse e montado usando ferramentas de construção automática usando jenkins. Com o Ansible, ele estava lançando nosso sistema de controle de versão para servidores virtuais. Além disso, cada sistema que estava em nossa empresa foi implantado pelo menos em 2 servidores: um deles estava na cabeça, o segundo na cauda. Esses dois sistemas eram absolutamente idênticos em todas as configurações, potência, configuração e muito mais. A única diferença entre eles era que a cabeça recebia o tráfego do usuário, enquanto a cauda nunca recebia o tráfego do usuário.
Por que isso foi feito?
Quando implantamos novos lançamentos de nosso aplicativo, queríamos oferecer a possibilidade de implantação contínua, ou seja, sem consequências visíveis para os usuários. Isso foi alcançado devido ao fato de que a próxima versão montada usando Ansible foi lançada na cauda. Lá, as pessoas envolvidas na implantação podiam verificar e garantir que tudo estava bem: todas as métricas, seções e aplicativos funcionavam; os scripts necessários são iniciados. Somente depois de convencidos de que está tudo bem, o tráfego foi alterado. Ele começou a ir para o servidor que era anterior antes. E a que era a cabeça antes, ficou sem tráfego de usuários, enquanto a versão anterior do nosso aplicativo estava nela.
Assim, para os usuários, foi perfeito. Porque a troca é simultânea, pois é apenas uma troca de balanceador. É muito fácil reverter para a versão anterior simplesmente retornando o balanceador. Também pudemos verificar a capacidade de produção do aplicativo mesmo antes do tráfego do usuário, o que era conveniente o suficiente.
Que vantagens vimos em tudo isso?
- Primeiro de tudo, funciona de maneira bastante simples. Todo mundo entende como esse esquema de implantação funciona, porque a maioria das pessoas já implantou em servidores virtuais comuns.
- Isso é bastante confiável , pois a tecnologia de implantação é simples, testada por milhares de empresas. Milhões de servidores são implantados dessa maneira. É difícil quebrar alguma coisa.
- E, finalmente, conseguimos implantações atômicas . Implantações que ocorrem aos usuários simultaneamente, sem um estágio perceptível de alternar entre a versão antiga e a nova.
Mas nisto também vimos várias deficiências:
- Além do ambiente de produção, ambiente de desenvolvimento, existem outros ambientes. Por exemplo, qa e pré-produção. Naquela época, tínhamos muitos servidores e cerca de 60 serviços. Por esse motivo, era necessário que cada serviço mantivesse a versão da máquina virtual que era relevante para ele . Além disso, se você deseja atualizar bibliotecas ou instalar novas dependências, é necessário fazer isso em todos os ambientes. Também foi necessário sincronizar o horário em que você implementaria a próxima nova versão do seu aplicativo com o horário em que os devops fizeram as configurações de ambiente necessárias. Nesse caso, é fácil entrar em uma situação em que nosso ambiente será ligeiramente diferente de uma só vez em todos os ambientes seguidos. Por exemplo, no ambiente de controle de qualidade, haverá algumas versões de bibliotecas e em produção - outras, o que levará a problemas.
- Dificuldade em atualizar as dependências do seu aplicativo. Não depende de você, mas da outra equipe. Ou seja, a partir do comando devops, que suporta o servidor. Você deve definir uma tarefa apropriada para eles e fornecer uma descrição do que deseja fazer.
- Naquela época, também queríamos dividir os grandes monólitos grandes que tínhamos em pequenos serviços separados, pois entendemos que haveria mais e mais deles. Naquela época, já tínhamos mais de 100. Era necessário que cada novo serviço criasse uma nova máquina virtual separada, que também precisa ser reparada e implantada. Além disso, você não precisa de um carro, mas de pelo menos dois. Para isso, o ambiente de controle de qualidade ainda está sendo adicionado. Isso causa problemas e torna a criação e o lançamento de novos sistemas mais difíceis, dispendiosos e demorados para você.
Portanto, decidimos que seria mais conveniente mudar da implantação de máquinas virtuais comuns para a implantação de nossos aplicativos no contêiner do docker. Se você possui janela de encaixe, precisa de um sistema que possa executar o aplicativo no cluster, pois não pode simplesmente levantar o contêiner. Geralmente, você deseja acompanhar quantos contêineres são levantados para que eles subam automaticamente. Por esse motivo, tivemos que escolher um sistema de controle.
Pensamos durante muito tempo sobre qual deles pode ser levado. O fato é que, naquela época, essa pilha de implantações em servidores virtuais comuns estava um pouco desatualizada, pois não havia as versões mais recentes dos sistemas operacionais. Em algum momento, até o FreeBSD ficou lá, o que não era muito conveniente de manter. Entendemos que você precisa migrar para o Docker o mais rápido possível. Nossos desenvolvedores analisaram sua experiência existente com diferentes soluções e escolheram um sistema como o Nomad.
Mudar para Nomad
Nomad é um produto HashiCorp. Eles também são conhecidos por suas outras decisões:
 O Consul
O Consul é uma ferramenta para descoberta de serviços.
O Terraform é um sistema de gerenciamento de servidor que permite configurá-los por meio de uma configuração chamada infraestrutura como código.
O Vagrant permite implantar máquinas virtuais localmente ou na nuvem por meio de arquivos de configuração específicos.
O Nomad na época parecia uma solução bastante simples para a qual você pode mudar rapidamente sem alterar toda a infraestrutura. Além disso, é facilmente dominado. Portanto, nós o escolhemos como nosso sistema de filtro para nosso contêiner.
O que é necessário para implantar completamente seu sistema no Nomad?
- Primeiro de tudo, você precisa da imagem do docker do seu aplicativo. Você precisa compilá-lo e colocá-lo no armazenamento de imagens da janela de encaixe. No nosso caso, isso é artefato - um sistema que permite inserir vários artefatos de vários tipos nele. Ele pode armazenar arquivos, imagens do docker, pacotes do compositor PHP, pacotes NPM e assim por diante.
- Você também precisa de um arquivo de configuração que informe ao Nomad o que, onde e quanto você deseja implantar.
Quando falamos sobre o Nomad, ele usa a linguagem HCL como um formato de arquivo de informações, que significa
HashiCorp Configuration Language . Este é um superconjunto do Yaml que permite descrever seu serviço em termos de Nomad.

Ele permite dizer quantos contêineres você deseja implantar, a partir de quais imagens os transferirão vários parâmetros durante a implantação. Assim, você alimenta esse arquivo Nomad e lança contêineres em produção de acordo com ele.
No nosso caso, percebemos que escrever exatamente os mesmos arquivos HLC idênticos para cada serviço não seria muito conveniente, porque existem muitos serviços e, às vezes, você deseja atualizá-los. Acontece que um serviço é implantado não em uma instância, mas nas mais diferentes. Por exemplo, um dos sistemas que temos em produção possui mais de 100 instâncias na produção. Eles são iniciados a partir das mesmas imagens, mas diferem nas configurações e nos arquivos de configuração.
Portanto, decidimos que seria conveniente armazenar todos os nossos arquivos de configuração para a implantação em um repositório comum. Assim, eles se tornaram observáveis: eram fáceis de manter e era possível ver quais sistemas tínhamos. Se necessário, também é fácil atualizar ou alterar alguma coisa. Adicionar um novo sistema também não é difícil - basta inserir o arquivo de configuração dentro do novo diretório. Dentro dele estão os arquivos: service.hcl, que contém uma descrição do nosso serviço, e alguns arquivos de ambiente que permitem a configuração desse serviço, sendo implantado na produção.

No entanto, alguns de nossos sistemas são implantados no produto não em uma cópia, mas em vários de uma vez. Portanto, decidimos que seria conveniente não armazenar configurações em sua forma pura, mas em sua forma de modelo. E, como linguagem de modelo, escolhemos o
jinja 2 . Nesse formato, armazenamos as configurações do próprio serviço e os arquivos env necessários para ele.
Além disso, colocamos no repositório uma implantação comum de script para todos os projetos, o que permite iniciar e implantar seu serviço em produção, no ambiente certo, no destino certo. No caso em que transformamos nossa HCL-config em um modelo, o arquivo HCL, que anteriormente era uma configuração regular do Nomad, nesse caso começou a parecer um pouco diferente.
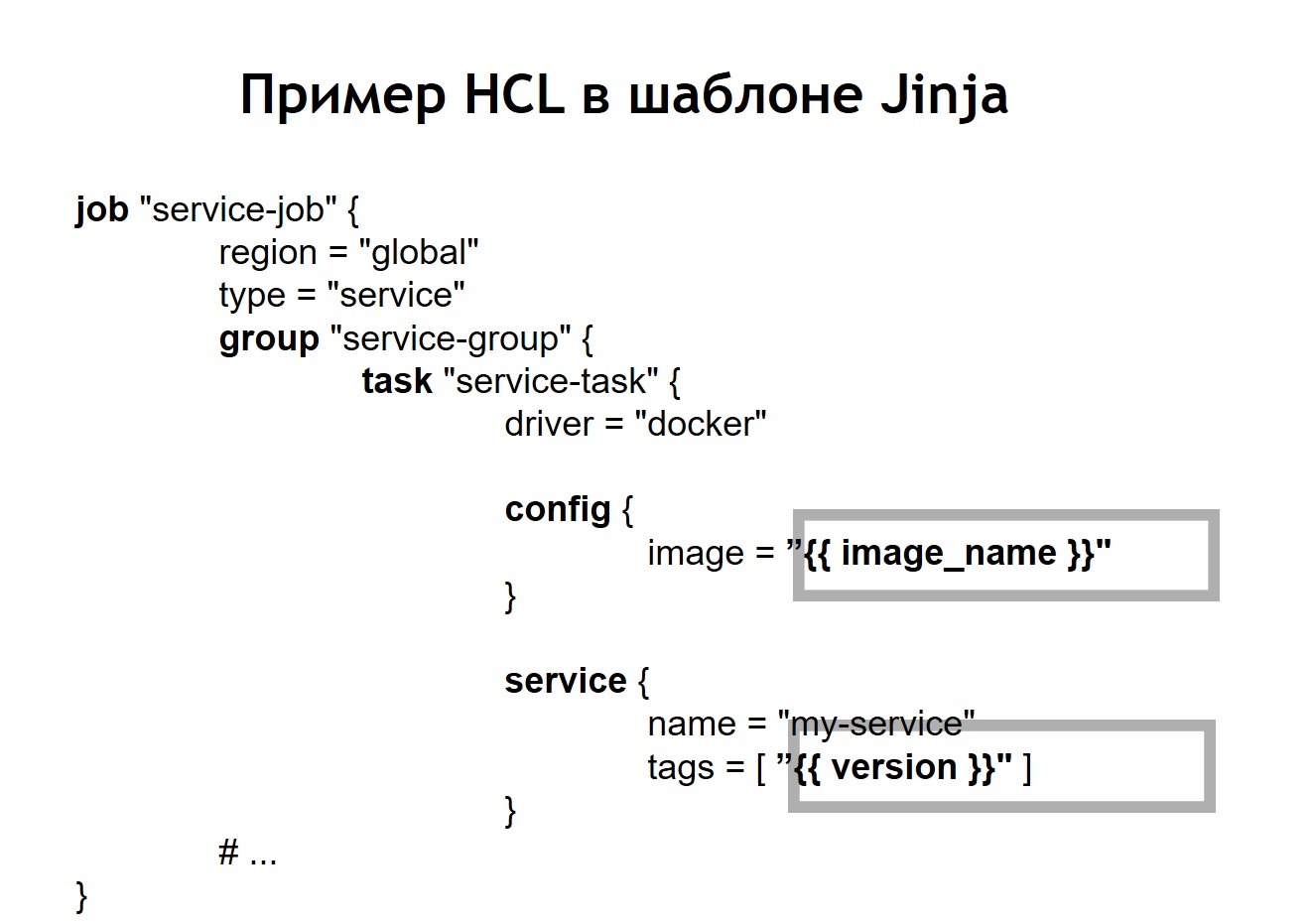
Ou seja, substituímos algumas variáveis no arquivo de configuração por inserções de variáveis, retiradas dos arquivos env ou de outras fontes. Além disso, conseguimos coletar arquivos HL dinamicamente, ou seja, podemos usar não apenas as inserções de variáveis usuais. Como o jinja suporta loops e condições, você também pode criar arquivos de configuração, que variam dependendo de onde exatamente você implanta seus aplicativos.
Por exemplo, você deseja implantar seu serviço na pré-produção e na produção. Suponha que, na pré-produção, você não queira executar scripts coroa, apenas queira ver o serviço em um domínio separado para garantir que esteja funcionando. Para qualquer pessoa que implanta um serviço, o processo parece muito simples e transparente. Basta executar o arquivo deploy.sh, especificar qual serviço você deseja implantar e em qual destino. Por exemplo, você deseja implantar um determinado sistema na Rússia, Bielorrússia ou Cazaquistão. Para fazer isso, basta alterar um dos parâmetros e você terá o arquivo de configuração correto.
Quando o serviço Nomad já está implantado no seu cluster, ele se parece com isso.
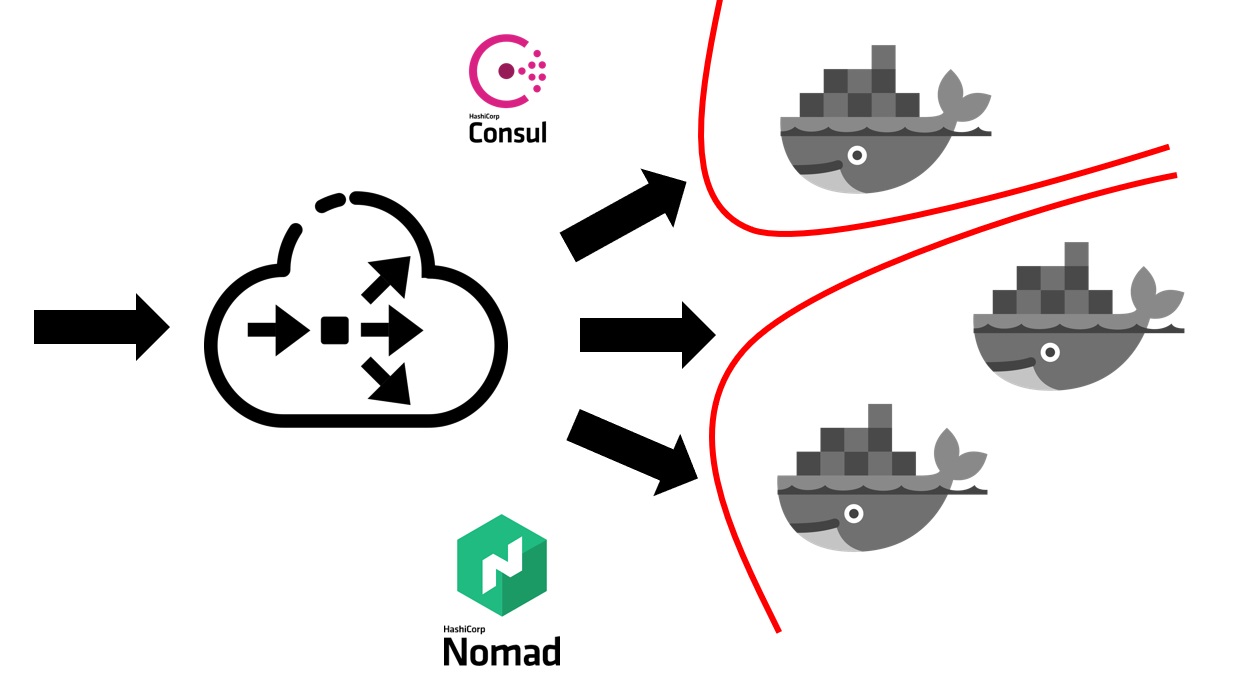
Primeiro, você precisa de um balanceador externo que absorve todo o tráfego do usuário. Ele trabalhará em conjunto com o Consul e descobrirá onde, em qual nó, em qual endereço IP há um serviço específico que corresponde a um nome de domínio específico. Os serviços no Consul são do próprio Nomad. Como são produtos da mesma empresa, eles estão bem conectados. Podemos dizer que o Nomad pronto para o registro pode registrar todos os serviços nele lançados no Consul.
Depois que seu balanceador externo descobre para qual serviço é necessário enviar tráfego, ele o redireciona para o contêiner apropriado ou para vários contêineres que correspondem ao seu aplicativo. Naturalmente, também é necessário pensar em segurança. Embora todos os serviços sejam executados nas mesmas máquinas virtuais em contêineres, isso geralmente exige a proibição de acesso gratuito de qualquer serviço a qualquer outro. Conseguimos isso por meio de segmentação. Cada serviço foi lançado em sua própria rede virtual, na qual foram prescritas regras de roteamento e regras para permitir / negar acesso a outros sistemas e serviços. Eles podem estar localizados dentro deste cluster e fora dele. Por exemplo, se você deseja impedir que um serviço se conecte a um banco de dados específico, isso pode ser feito por segmentação no nível da rede. Ou seja, mesmo por engano, você não pode se conectar acidentalmente de um ambiente de teste à sua base de produção.
Quanto custou a transição em termos de recursos humanos?
A transição de toda a empresa para a Nomad levou cerca de 5-6 meses. Mudamos sem serviço, mas em um ritmo bastante rápido. Cada equipe teve que criar seus próprios contêineres para serviços.
Adotamos uma abordagem que cada equipe é responsável pelas imagens do docker de seus sistemas por conta própria. Os Devops também fornecem a infraestrutura geral necessária para a implantação, ou seja, suporte para o próprio cluster, suporte para o sistema de IC e assim por diante. E naquela época, com mais de 60 sistemas transferidos para o Nomad, foram lançados cerca de 2 mil contêineres.
O Devops é responsável pela infraestrutura geral de tudo o que estiver conectado à implantação, com os servidores. E cada equipe de desenvolvimento, por sua vez, é responsável pela implementação de contêineres para seu sistema específico, pois é a equipe que sabe o que geralmente precisa em um contêiner específico.
Razões para abandonar o Nomad
Que vantagens tivemos ao mudar para implantar usando o Nomad e o docker também?
- Fornecemos as mesmas condições para todos os ambientes. Em uma empresa de desenvolvimento, ambiente de controle de qualidade, pré-produção, produção, as mesmas imagens de contêiner são usadas, com as mesmas dependências. Consequentemente, você praticamente não tem chance de que a produção seja diferente do que você testou anteriormente localmente ou em um ambiente de teste.
- Também descobrimos que é fácil adicionar um novo serviço . Do ponto de vista da implantação, quaisquer novos sistemas são lançados com muita simplicidade. Basta ir ao repositório que armazena as configurações, adicionar a próxima configuração ao seu sistema e você está pronto. Você pode implantar seu sistema em produção sem esforço adicional dos devops.
- Todos os arquivos de configuração em um repositório comum acabaram sendo monitorados . Nesse momento, quando implantamos nossos sistemas usando servidores virtuais, usamos o Ansible, no qual as configurações estão no mesmo repositório. No entanto, para a maioria dos desenvolvedores, foi um pouco mais difícil trabalhar. Aqui, o volume de configurações e código que você precisa adicionar para implantar o serviço ficou muito menor. Além disso, para os devops, é muito fácil corrigi-lo ou alterá-lo. No caso de transições, por exemplo, na nova versão do Nomad, elas podem pegar e atualizar maciçamente todos os arquivos operacionais no mesmo local.
Mas também enfrentamos várias deficiências:
Acabou que
não conseguimos implantações perfeitas no caso do Nomad. Ao rolar os contêineres para fora de condições diferentes, pode acontecer que ele esteja funcionando e o Nomad o percebe como um contêiner pronto para aceitar tráfego. Isso aconteceu antes mesmo do aplicativo iniciar. Por esse motivo, o sistema por um curto período começou a produzir 500 erros, porque o tráfego começou a ir para o contêiner, que ainda não estava pronto para recebê-lo.
Encontramos alguns
bugs . O erro mais significativo é que o Nomad não aceita muito bem um cluster grande se você tiver muitos sistemas e contêineres. Quando você deseja colocar em serviço um dos servidores incluídos no cluster Nomad, existe uma alta probabilidade de que o cluster não se sinta muito bem e desmorone. Parte dos contêineres pode, por exemplo, cair e não subir - subseqüentemente será muito caro para você se todos os seus sistemas de produção estiverem localizados em um cluster gerenciado pelo Nomad.
Portanto, decidimos pensar em onde ir a seguir. Naquela época, nos tornamos muito mais conscientes do que queremos alcançar. Ou seja: queremos confiabilidade, um pouco mais de funções do que o Nomad oferece e um sistema mais maduro e mais estável.
Nesse sentido, nossa escolha recaiu sobre o Kubernetes como a plataforma mais popular para o lançamento de clusters. Desde que o tamanho e a quantidade de nossos contêineres sejam bastante grandes. Para tais propósitos, Kubernetes parecia o sistema mais adequado daqueles que podíamos ver.
Indo para Kubernetes
Vou falar um pouco sobre os conceitos básicos do Kubernetes e como eles diferem do Nomad.
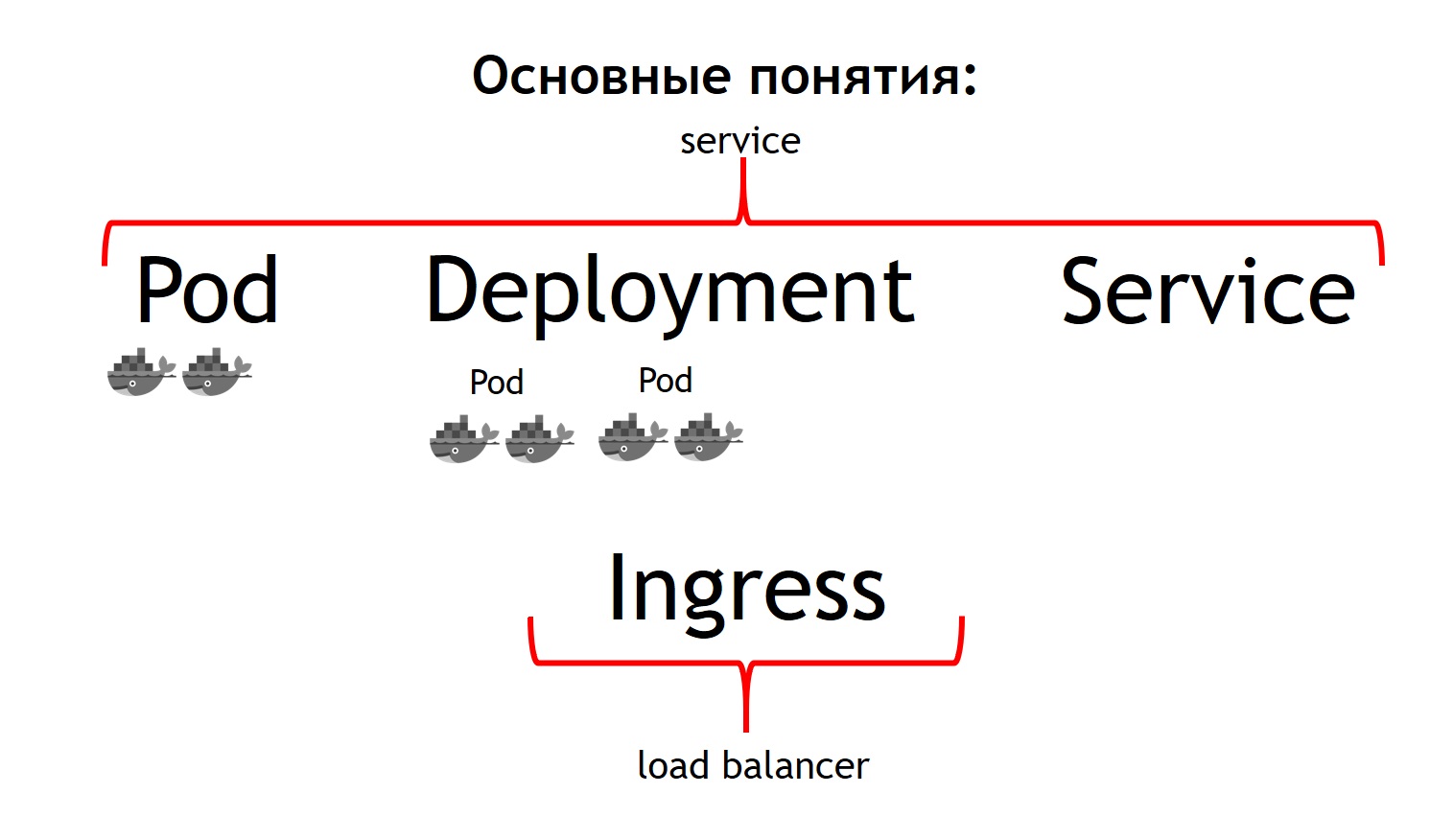
Primeiro de tudo, o conceito mais básico no Kubernetes é o conceito de vagem.
Um pod é um grupo de um ou mais contêineres que sempre funcionam juntos. E eles parecem sempre funcionar estritamente na mesma máquina virtual. Eles estão disponíveis via IP 127.0.0.1 em portas diferentes.
Suponha que você tenha um aplicativo PHP que consiste em nginx e php-fpm - um circuito clássico. Provavelmente, você deseja que os contêineres nginx e php-fpm estejam sempre juntos. O Kubernetes faz isso descrevendo-os como um pod comum. É exatamente isso que não conseguimos com a ajuda do Nomad.
O segundo conceito é
implantação . O fato é que a cápsula em si é uma coisa efêmera, começa e desaparece. Se você deseja matar todos os seus contêineres anteriores primeiro e, em seguida, lançar novas versões de uma só vez, ou deseja lançá-las gradualmente - esse é o conceito pelo qual a implantação é responsável. Ele descreve como você implanta seus pods, em quantos e como atualizá-los.
O terceiro conceito é
serviço . Seu serviço é realmente o seu sistema, que recebe algum tráfego e o direciona para um ou mais pods que correspondem ao seu serviço. Ou seja, permite que você diga que todo o tráfego recebido para um serviço com esse nome deve ser enviado para esses pods específicos. E, ao mesmo tempo, fornece balanceamento de tráfego. Ou seja, você pode executar dois pods do seu aplicativo e todo o tráfego recebido será equilibrado igualmente entre os pods relacionados a este serviço.
E o quarto conceito básico é o
Ingress . Este é um serviço que é executado em um cluster Kubernetes. Ele atua como um balanceador de carga externo, que aceita todas as solicitações. Devido à API, o Kubernetes Ingress pode determinar para onde essas solicitações devem ser enviadas. E ele faz isso com muita flexibilidade. Você pode dizer que todas as solicitações para esse host e esse URL são enviadas para este serviço. E enviamos esses pedidos para este host e para outro URL para outro serviço.
O mais legal do ponto de vista de quem desenvolve o aplicativo é que você é capaz de gerenciar tudo sozinho. Depois de definir a configuração do Ingress, você pode enviar todo o tráfego que chega a essa API para separar os contêineres registrados, por exemplo, para Go. Mas esse tráfego que chega ao mesmo domínio, mas para uma URL diferente, deve ser enviado para contêineres escritos em PHP, onde há muita lógica, mas eles não são muito rápidos.
Se compararmos todos esses conceitos com o Nomad, podemos dizer que os três primeiros conceitos estão todos juntos em Serviço. E o último conceito no próprio Nomad está ausente. Utilizamos um balanceador externo: ele pode ser haproxy, nginx, nginx + e assim por diante. No caso de um cubo, você não precisa introduzir esse conceito adicional separadamente. No entanto, se você observar o Ingress por dentro, ele será nginx, haproxy ou traefik, mas como se estivesse embutido no Kubernetes.
Todos os conceitos que descrevi são essencialmente os recursos que existem no cluster Kubernetes. Para descrevê-los no cubo, é usado o formato yaml, que é mais legível e familiar que os arquivos HCl no caso do Nomad. Mas estruturalmente eles descrevem no caso de, por exemplo, pod a mesma coisa. Eles dizem - eu quero implantar esses e outros pods aqui e ali, com tais e tais imagens, em tal e em quantidade.

Além disso, percebemos que não queríamos criar cada recurso individual com nossas próprias mãos: implantação, serviços, Ingress e muito mais. Em vez disso, queríamos descrever cada sistema implantado em termos de Kubernetes durante a implantação, para que não precisássemos recriar manualmente todas as dependências de recursos necessárias na ordem certa. Helm foi escolhido como o sistema que nos permitiu fazer isso.
Principais conceitos no Helm
Helm é um
gerenciador de pacotes para o Kubernetes. É muito parecido com o modo como os gerenciadores de pacotes trabalham nas linguagens de programação. Eles permitem que você armazene um serviço que consiste em, por exemplo, nginx de implantação, php-fpm de implantação, uma configuração para o Ingress, configmaps (esta é uma entidade que permite definir env e outros parâmetros para o seu sistema) na forma de gráficos. Ao mesmo tempo, Helm
corre em cima de Kubernetes . Ou seja, esse não é um tipo de sistema que fica de lado, mas apenas outro serviço que é executado dentro do cubo. Você interage com ele através de sua API através de um comando do console. Sua conveniência e charme é que, mesmo que o helm seja interrompido ou você o remova do cluster, seus serviços não desaparecerão, pois o helm serve basicamente apenas para iniciar o sistema. O próprio Kubernetes é responsável pelo tempo de atividade e pelo estado dos serviços.
Também percebemos que a padronização , que antes disso deveria ser feita de forma independente através da introdução do jinja em nossas configurações, é uma das principais características do helm. Todas as configurações que você cria para seus sistemas são armazenadas no helm na forma de modelos semelhantes a um pouco de jinja, mas, de fato, usando o modelo de idioma Go no qual o helm está escrito, como o Kubernetes.Helm adiciona alguns conceitos adicionais a nós.Gráfico é uma descrição do seu serviço. Outros gerenciadores de pacotes o chamariam de pacote, pacote configurável ou algo assim. Isso é chamado de gráfico aqui.Valores são as variáveis que você deseja usar para criar suas configurações a partir de modelos.Lançamento. Cada vez que um serviço implantado usando o helm recebe uma versão incremental da liberação. Helm lembra qual era a configuração do serviço no ano anterior, no ano anterior ao último lançamento e assim por diante. Portanto, se você precisar reverter, basta executar o comando helm callback, indicando a versão anterior do release. Mesmo que, no momento da reversão, a configuração correspondente em seu repositório não esteja disponível, o helm ainda se lembrará do que era e reverte seu sistema para o estado em que estava no release anterior.No caso em que usamos helm, as configurações usuais do Kubernetes também se transformam em modelos, nos quais é possível usar variáveis, funções e aplicar operadores condicionais. Assim, você pode coletar a configuração do seu serviço, dependendo do ambiente.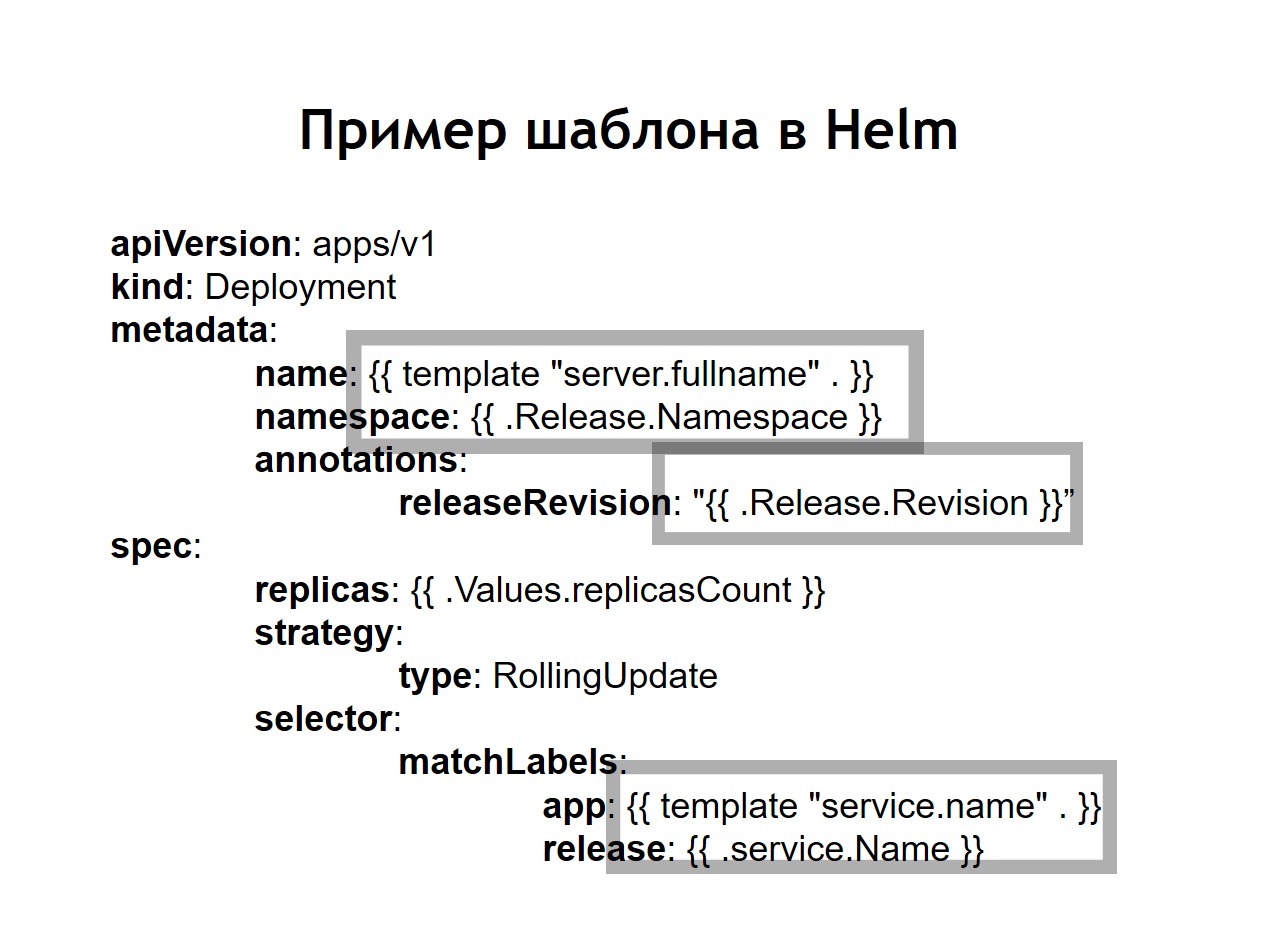 Na prática, decidimos fazer um pouco diferente do que fizemos no caso do Nomad. Se no Nomad no mesmo repositório foram armazenadas as duas configurações para a implantação e as n-variáveis necessárias para implantar nosso serviço, decidimos dividi-las em dois repositórios separados. Somente as n-variáveis necessárias para a implantação são armazenadas no repositório de implementação e as configurações ou gráficos são armazenados no repositório de helm.
Na prática, decidimos fazer um pouco diferente do que fizemos no caso do Nomad. Se no Nomad no mesmo repositório foram armazenadas as duas configurações para a implantação e as n-variáveis necessárias para implantar nosso serviço, decidimos dividi-las em dois repositórios separados. Somente as n-variáveis necessárias para a implantação são armazenadas no repositório de implementação e as configurações ou gráficos são armazenados no repositório de helm. O que isso nos deu?Apesar de não armazenarmos dados realmente confidenciais nos próprios arquivos de configuração. Por exemplo, senhas de banco de dados. Eles são armazenados como segredos no Kubernetes, mas, no entanto, ainda existem algumas coisas que não queremos dar acesso a todos seguidos. Portanto, o acesso ao repositório de implementação é mais limitado, e o repositório helm simplesmente contém uma descrição do serviço. Por esse motivo, é possível conceder acesso a um círculo maior de pessoas com segurança.Como não temos apenas produção, mas também outros ambientes, graças a essa separação, podemos reutilizar nossos gráficos de comando para implantar serviços não apenas na produção, mas também, por exemplo, no ambiente de controle de qualidade. Mesmo implantá-los localmente usando o Minikube é algo capaz de executar o Kubernetes localmente.Dentro de cada repositório, deixamos uma separação em diretórios separados para cada serviço. Ou seja, dentro de cada diretório, existem modelos relacionados ao gráfico correspondente e descrevem os recursos que precisam ser implantados para iniciar nosso sistema. No repositório de implantação, deixamos apenas invejas. Nesse caso, não usamos modelos com jinja, porque o próprio leme fornece modelos fora da caixa - essa é uma de suas principais funções.Deixamos o script de implantação deploy.sh, que simplifica e padroniza o lançamento para implantação usando o helm. Portanto, para quem deseja implantar, a interface de implantação é exatamente a mesma que era no caso da implantação via Nomad. O mesmo deploy.sh, o nome do seu serviço e onde você deseja implantá-lo. Isso faz com que o leme comece por dentro. Por sua vez, ele coleta configurações de modelos, substitui os arquivos de valores necessários neles e depois os implanta, colocando-os no Kubernetes.
O que isso nos deu?Apesar de não armazenarmos dados realmente confidenciais nos próprios arquivos de configuração. Por exemplo, senhas de banco de dados. Eles são armazenados como segredos no Kubernetes, mas, no entanto, ainda existem algumas coisas que não queremos dar acesso a todos seguidos. Portanto, o acesso ao repositório de implementação é mais limitado, e o repositório helm simplesmente contém uma descrição do serviço. Por esse motivo, é possível conceder acesso a um círculo maior de pessoas com segurança.Como não temos apenas produção, mas também outros ambientes, graças a essa separação, podemos reutilizar nossos gráficos de comando para implantar serviços não apenas na produção, mas também, por exemplo, no ambiente de controle de qualidade. Mesmo implantá-los localmente usando o Minikube é algo capaz de executar o Kubernetes localmente.Dentro de cada repositório, deixamos uma separação em diretórios separados para cada serviço. Ou seja, dentro de cada diretório, existem modelos relacionados ao gráfico correspondente e descrevem os recursos que precisam ser implantados para iniciar nosso sistema. No repositório de implantação, deixamos apenas invejas. Nesse caso, não usamos modelos com jinja, porque o próprio leme fornece modelos fora da caixa - essa é uma de suas principais funções.Deixamos o script de implantação deploy.sh, que simplifica e padroniza o lançamento para implantação usando o helm. Portanto, para quem deseja implantar, a interface de implantação é exatamente a mesma que era no caso da implantação via Nomad. O mesmo deploy.sh, o nome do seu serviço e onde você deseja implantá-lo. Isso faz com que o leme comece por dentro. Por sua vez, ele coleta configurações de modelos, substitui os arquivos de valores necessários neles e depois os implanta, colocando-os no Kubernetes.Conclusões
O serviço Kubernetes parece mais complexo que o Nomad.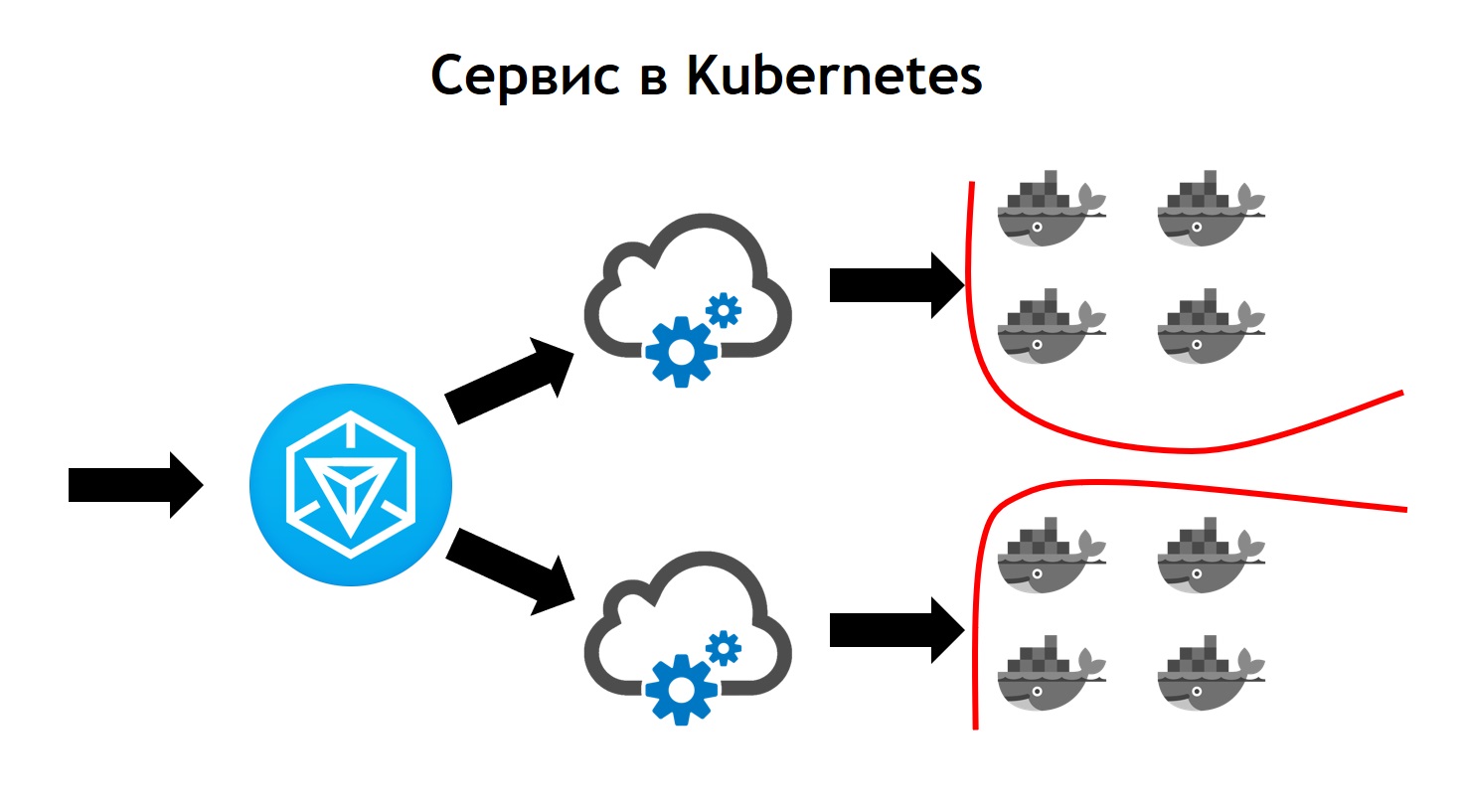 É aqui que o tráfego de saída chega ao Ingress. Este é apenas o controlador frontal, que recebe todos os pedidos e os envia posteriormente aos serviços correspondentes aos dados do pedido. Ele os define com base nas configurações, que fazem parte da descrição do seu aplicativo no leme e que os desenvolvedores definem independentemente. O serviço envia solicitações para seus pods, ou seja, contêineres específicos, equilibrando o tráfego de entrada entre todos os contêineres pertencentes a esse serviço. Bem, é claro, não esqueça que não devemos ir a lugar nenhum da segurança no nível da rede. Portanto, o cluster Kubernetes opera a segmentação, que é baseada na marcação. Todos os serviços possuem determinadas tags, às quais os direitos de acesso dos serviços a determinados recursos externos / internos estão anexados dentro ou fora do cluster.Ao concluir a transição, vimos que o Kubernetes tem todos os recursos do Nomad, que usamos anteriormente, e também adiciona muitas coisas novas. Ele pode ser expandido através de plug-ins e, de fato, através de tipos de recursos personalizados. Ou seja, você tem a oportunidade não apenas de usar algo que entra no Kubernetes imediatamente, mas também de criar seu próprio recurso e serviço que lerá seu recurso. Isso fornece opções adicionais para expandir seu sistema sem a necessidade de reinstalar o Kubernetes e sem a necessidade de alterações.Um exemplo disso é o Prometheus, que é executado dentro do nosso cluster Kubernetes. Para que ele comece a coletar métricas de um serviço específico, precisamos adicionar um tipo de recurso adicional, o chamado monitor de serviço, à descrição do serviço. O Prometheus, devido ao fato de poder ler, sendo lançado no Kubernetes, um tipo personalizado de recursos, começa automaticamente a coletar métricas do novo sistema. É bastante conveniente.A primeira implantação que fizemos no Kubernetes foi em março de 2018. E durante esse tempo, nunca tivemos problemas com ele. Funciona de forma estável o suficiente, sem erros significativos. Além disso, podemos expandi-lo ainda mais. Hoje, temos oportunidades suficientes e gostamos muito do ritmo de desenvolvimento do Kubernetes. Atualmente, mais de 3.000 contêineres estão localizados em Kubernetes. O cluster leva vários nós. Ao mesmo tempo, é atendido, estável e muito controlado.
É aqui que o tráfego de saída chega ao Ingress. Este é apenas o controlador frontal, que recebe todos os pedidos e os envia posteriormente aos serviços correspondentes aos dados do pedido. Ele os define com base nas configurações, que fazem parte da descrição do seu aplicativo no leme e que os desenvolvedores definem independentemente. O serviço envia solicitações para seus pods, ou seja, contêineres específicos, equilibrando o tráfego de entrada entre todos os contêineres pertencentes a esse serviço. Bem, é claro, não esqueça que não devemos ir a lugar nenhum da segurança no nível da rede. Portanto, o cluster Kubernetes opera a segmentação, que é baseada na marcação. Todos os serviços possuem determinadas tags, às quais os direitos de acesso dos serviços a determinados recursos externos / internos estão anexados dentro ou fora do cluster.Ao concluir a transição, vimos que o Kubernetes tem todos os recursos do Nomad, que usamos anteriormente, e também adiciona muitas coisas novas. Ele pode ser expandido através de plug-ins e, de fato, através de tipos de recursos personalizados. Ou seja, você tem a oportunidade não apenas de usar algo que entra no Kubernetes imediatamente, mas também de criar seu próprio recurso e serviço que lerá seu recurso. Isso fornece opções adicionais para expandir seu sistema sem a necessidade de reinstalar o Kubernetes e sem a necessidade de alterações.Um exemplo disso é o Prometheus, que é executado dentro do nosso cluster Kubernetes. Para que ele comece a coletar métricas de um serviço específico, precisamos adicionar um tipo de recurso adicional, o chamado monitor de serviço, à descrição do serviço. O Prometheus, devido ao fato de poder ler, sendo lançado no Kubernetes, um tipo personalizado de recursos, começa automaticamente a coletar métricas do novo sistema. É bastante conveniente.A primeira implantação que fizemos no Kubernetes foi em março de 2018. E durante esse tempo, nunca tivemos problemas com ele. Funciona de forma estável o suficiente, sem erros significativos. Além disso, podemos expandi-lo ainda mais. Hoje, temos oportunidades suficientes e gostamos muito do ritmo de desenvolvimento do Kubernetes. Atualmente, mais de 3.000 contêineres estão localizados em Kubernetes. O cluster leva vários nós. Ao mesmo tempo, é atendido, estável e muito controlado.