Infelizmente, agora o papel dos especialistas no ajuste de desempenho e na solução de problemas do banco de dados está sendo reduzido apenas até o último - solução de problemas: eles quase sempre se voltam para especialistas apenas quando os problemas já atingiram um ponto crítico e precisam ser resolvidos "ontem". E mesmo assim, é bom que eles mudem e não atrasem o problema comprando um hardware ainda mais caro e poderoso sem uma auditoria de desempenho detalhada e testes de estresse. De fato, muitas vezes as frustrações são suficientes: eles compraram equipamentos no valor de duas a cinco vezes mais caros e obtiveram apenas 30 a 40% em desempenho, cujo aumento total é consumido em poucos meses, seja pelo aumento no número de usuários ou por um aumento exponencial dos dados, juntamente com uma complicação da lógica.
E agora, no momento em que o número de arquitetos, testadores e engenheiros de DevOps está crescendo rapidamente, e os desenvolvedores do Java Core estão otimizando até mesmo o trabalho
com strings , lenta mas seguramente está chegando a hora dos otimizadores de banco de dados. Os DBMSs a cada versão tornam-se tão mais inteligentes e complexos que o estudo de nuances e otimizações documentadas e não documentadas requer uma quantidade enorme de tempo. Um grande número de artigos é publicado mensalmente e as principais conferências dedicadas à Oracle são realizadas. Desculpe a analogia banal, mas nessa situação, quando os administradores de banco de dados se tornam semelhantes aos pilotos de avião com inúmeros comutadores, botões, luzes e telas, é indecente carregá-los com as sutilezas da otimização de desempenho.
Obviamente, o DBA, como os pilotos, na maioria dos casos pode resolver facilmente problemas óbvios e simples quando é facilmente diagnosticado ou perceptível em vários "topos" (eventos principais, SQL principal, segmentos principais ...). E que são fáceis de encontrar no MOS ou no Google, mesmo que eles não conheçam a solução. É muito mais complicado quando até os sintomas estão ocultos por trás da complexidade do sistema e precisam ser pesquisados entre a enorme quantidade de informações de diagnóstico coletadas pelo próprio DBMS do Oracle.
Um dos exemplos mais simples e vívidos é a análise do filtro e do acesso previsto: em sistemas grandes e carregados, muitas vezes acontece que esse problema é facilmente esquecido, porque a carga é distribuída de maneira bastante uniforme por solicitações diferentes (com junções para várias tabelas, com pequenas diferenças de condições etc.) e os segmentos principais não mostram nada de especial, dizendo: "bem, sim, os dados dessas tabelas são mais frequentemente necessários e há mais" . Nesses casos, você pode iniciar a análise com estatísticas de SYS.COL_USAGE $:
col_usage.sqlcol owner format a30 col oname format a30 heading "Object name" col cname format a30 heading "Column name" accept owner_mask prompt "Enter owner mask: "; accept tab_name prompt "Enter tab_name mask: "; accept col_name prompt "Enter col_name mask: "; SELECT a.username as owner ,o.name as oname ,c.name as cname ,u.equality_preds as equality_preds ,u.equijoin_preds as equijoin_preds ,u.nonequijoin_preds as nonequijoin_preds ,u.range_preds as range_preds ,u.like_preds as like_preds ,u.null_preds as null_preds ,to_char(u.timestamp, 'yyyy-mm-dd hh24:mi:ss') when FROM sys.col_usage$ u , sys.obj$ o , sys.col$ c , all_users a WHERE a.user_id = o.owner
No entanto, para uma análise completa dessas informações não é suficiente, porque não mostra combinações de predicados. Nesse caso, a análise de v $ active_session_history ev $ sql_plan pode nos ajudar:
with ash as ( select sql_id ,plan_hash_value ,table_name ,alias ,ACCESS_PREDICATES ,FILTER_PREDICATES ,count(*) cnt from ( select h.sql_id ,h.SQL_PLAN_HASH_VALUE plan_hash_value ,decode(p.OPERATION ,'TABLE ACCESS',p.OBJECT_OWNER||'.'||p.OBJECT_NAME ,(select i.TABLE_OWNER||'.'||i.TABLE_NAME from dba_indexes i where i.OWNER=p.OBJECT_OWNER and i.index_name=p.OBJECT_NAME) ) table_name ,OBJECT_ALIAS ALIAS ,p.ACCESS_PREDICATES ,p.FILTER_PREDICATES
Como você pode ver na própria consulta, ela exibe as 50 principais colunas de pesquisa e os próprios predicados pelo número de vezes que o ASH é atingido nas últimas 3 horas. Apesar do fato de o ASH armazenar apenas instantâneos a cada segundo, a amostragem em bases carregadas é muito representativa. Pode esclarecer vários pontos:
- O campo cols - exibe as próprias colunas de pesquisa e total_by_cols - a soma das entradas no contexto dessas colunas.
- Eu acho que é bastante óbvio que essa informação em si não é um marcador suficiente do problema, porque por exemplo, várias varreduras completas únicas podem arruinar facilmente as estatísticas; portanto, você definitivamente precisará considerar as próprias consultas e a frequência delas (v $ sqlstats, dba_hist_sqlstat)
- Agrupando por OBJECT_ALIAS dentro de SQL_ID, plan_hash_value é importante para combinar predicados de índice e tabela por objeto, porque ao acessar a tabela por meio do índice, os predicados serão divididos em diferentes linhas do plano:
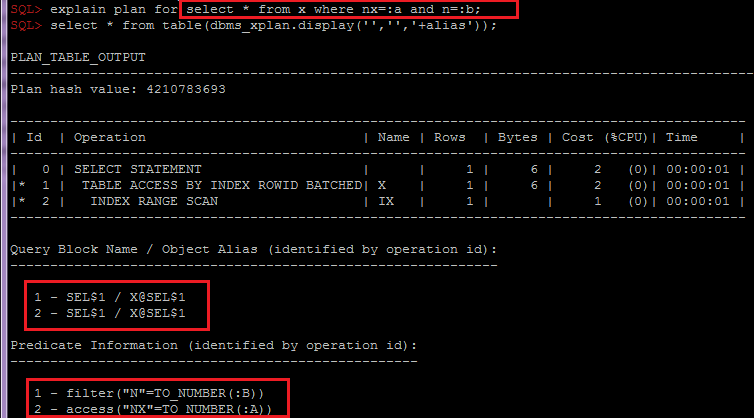
Dependendo da necessidade, esse script pode ser facilmente modificado para coletar informações adicionais em outras seções, por exemplo, levando em consideração o particionamento ou as expectativas. E já tendo analisado essas informações, juntamente com a análise das estatísticas da tabela e seus índices, o esquema geral de dados e a lógica de negócios, você pode passar recomendações aos desenvolvedores ou arquitetos para escolher uma solução, por exemplo: opções para desnormalização ou alteração do esquema ou índices de particionamento.
Também é frequentemente esquecido analisar o tráfego de rede SQL *, e também existem muitas sutilezas, por exemplo: tamanho de busca, SQLNET.COMPRESSION, tipos de dados estendidos, que permitem reduzir o número de roundtripes etc., mas este é um tópico para um artigo separado.
Concluindo, gostaria de dizer que agora que os usuários estão se tornando menos tolerantes a atrasos, otimizar o desempenho está se tornando uma vantagem competitiva.