Começamos uma série de artigos que descrevem várias situações nas quais o uso das ferramentas Intel para desenvolvedores aumentou significativamente a velocidade do software e melhorou sua qualidade.
Nossa primeira história aconteceu na Universidade de Novosibirsk, onde os pesquisadores desenvolveram uma ferramenta de software para simular numericamente problemas magneto-hidrodinâmicos durante a ionização do hidrogênio. Este trabalho foi realizado como parte do projeto global de modelagem de objetos astrofísicos
AstroPhi ;
Os processadores Intel Xeon Phi foram usados como plataforma de hardware. Como resultado do uso do
Intel Advisor e do
Intel Trace Analyzer and Collector , o desempenho da computação aumentou três vezes e a velocidade de solução de um problema diminuiu de uma semana para dois dias.
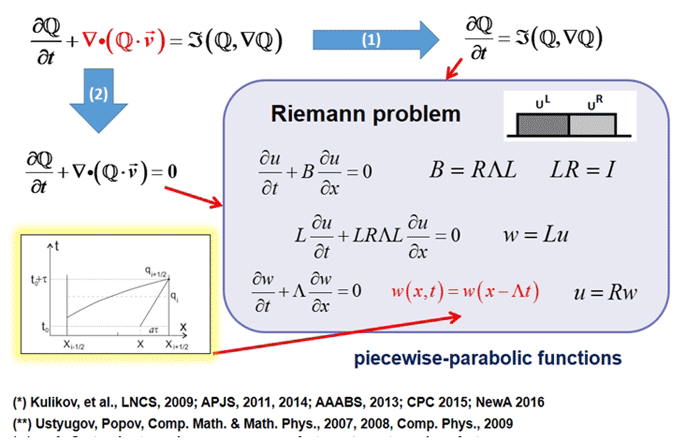
Descrição da tarefa
A modelagem matemática desempenha um papel importante na astrofísica moderna, como em qualquer ciência; Esta é uma ferramenta universal para estudar processos evolutivos não lineares no universo. A modelagem de alta resolução de processos astrofísicos complexos requer enormes recursos computacionais. Projeto AstroPhi A NSU está desenvolvendo código de software astrofísico para supercomputadores baseado nos processadores Intel Xeon Phi. Os alunos aprendem a escrever programas de simulação para um tempo de execução extremamente paralelo, adquirindo conhecimentos importantes que serão necessários ao trabalhar com outros supercomputadores.
O método de modelagem numérica usado no projeto teve várias vantagens importantes:
- falta de viscosidade artificial,
- Invariância galileana,
- garantia de não redução da entropia,
- paralelização simples
- extensibilidade potencialmente infinita.
Os três primeiros fatores são fundamentais para a modelagem realista de efeitos físicos significativos em problemas astrofísicos.
A equipe de pesquisa criou uma nova ferramenta de modelagem para arquiteturas multi-paralelas baseada no Intel Xeon Phi. Sua principal tarefa era evitar gargalos na troca de dados entre nós e simplificar ao máximo o refinamento do código. A solução de paralelização usa MPI e, para vetorização, as instruções Intel Advanced Vector Extensions 512 (Intel AVX-512) adicionam suporte ao SIMD de 512 bits e permitem que o programa agrupe 8 números de ponto flutuante de precisão dupla ou 16 números de precisão única (32 bits) ) para vetores com 512 bits. Portanto, duas vezes mais elementos de dados são processados por instrução do que quando se usa o AVX / AVX2 e quatro vezes mais que o SSE.
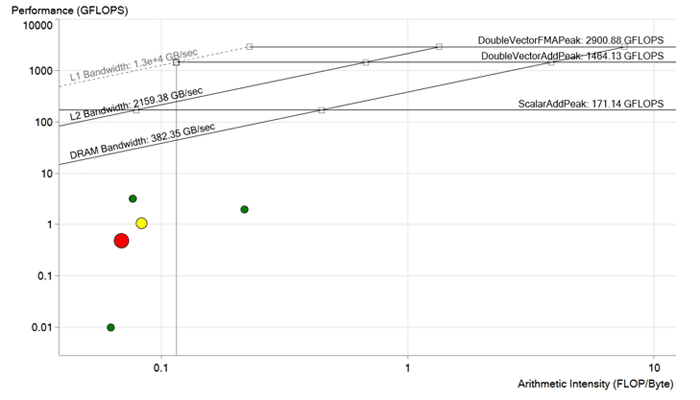 Imagem antes da otimização. Cada ponto é um ciclo de processamento. Quanto maior e mais vermelho o ponto, mais longo o ciclo continua e mais perceptível é o efeito de sua otimização. O ponto vermelho fica bem abaixo do limite da largura de banda da DRAM e é calculado com desempenho inferior a 1 GFLOP. Tem um grande potencial para melhorias.
Imagem antes da otimização. Cada ponto é um ciclo de processamento. Quanto maior e mais vermelho o ponto, mais longo o ciclo continua e mais perceptível é o efeito de sua otimização. O ponto vermelho fica bem abaixo do limite da largura de banda da DRAM e é calculado com desempenho inferior a 1 GFLOP. Tem um grande potencial para melhorias.Otimização de código
Antes da otimização, o código apresentava alguns problemas com dependências e tamanhos de vetor. O objetivo da otimização era remover as dependências de vetores e melhorar as operações de carregamento de dados na memória usando o tamanho ideal de vetores e matrizes para o Xeon Phi. Para otimização, usamos o
Intel Advisor e o
Intel Trace Analyzer and Collector , duas ferramentas do
Intel Parallel Studio XE .
O Intel Advisor é, como o nome indica, um consultor - uma ferramenta de software que avalia o grau de otimização - vetorização (usando as instruções AVX ou SIMD) e paralelização para obter o máximo desempenho. Usando essa ferramenta, a equipe conseguiu fazer uma análise geral dos ciclos, destacando aqueles com baixa produtividade, indicando o potencial de melhoria e determinando o que poderia ser melhorado e se o jogo valia a pena. O Intel Advisor classificou os ciclos por potencial, adicionou mensagens à fonte para melhor legibilidade do relatório do compilador. Ele também forneceu informações importantes, como tempos de ciclo, dependências de dados e padrões de acesso à memória para uma vetorização segura e eficiente.
O Intel Trace Analyzer and Collector é outra maneira de otimizar seu código. Inclui comunicação de perfil MPI e funcionalidade de análise para melhorar a escala fraca e forte. Essa ferramenta gráfica ajudou a equipe a entender o comportamento MPI do aplicativo, encontrar rapidamente gargalos e, o mais importante, aumentar o desempenho na arquitetura Intel.
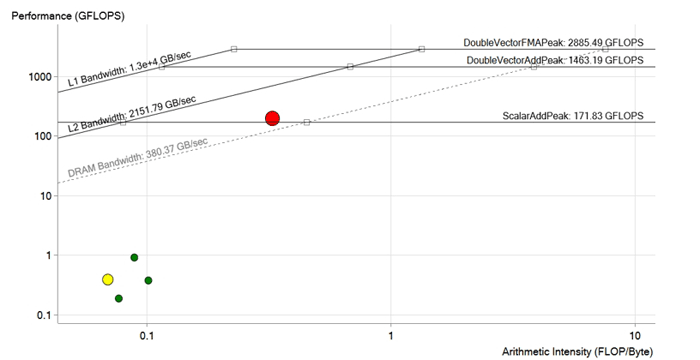 Imagem após otimização. Durante a otimização do ciclo vermelho, as dependências de vetorização foram removidas, as operações de carregamento na memória foram otimizadas, os tamanhos de vetores e matrizes foram adaptados para as instruções Intel Xeon Phi e AVX-512. O desempenho aumentou para 190 GFLOPS, ou seja, cerca de 200 vezes. Agora está acima do limite de DRAM e provavelmente limitado pelas características do cache L2
Imagem após otimização. Durante a otimização do ciclo vermelho, as dependências de vetorização foram removidas, as operações de carregamento na memória foram otimizadas, os tamanhos de vetores e matrizes foram adaptados para as instruções Intel Xeon Phi e AVX-512. O desempenho aumentou para 190 GFLOPS, ou seja, cerca de 200 vezes. Agora está acima do limite de DRAM e provavelmente limitado pelas características do cache L2Resultado
Portanto, depois de todas as melhorias e otimizações, a equipe alcançou o desempenho de 190 GFLOPS com uma intensidade aritmética de 0,3 FLOP / b, 100% de utilização e largura de banda de memória de 573 GB / s.
 Snippet de código otimizado
Snippet de código otimizado