O artigo em questão.
1. Introdução
Os sistemas modernos de reconhecimento limitam-se a classificar em um número relativamente pequeno de classes semanticamente não relacionadas. A atração de informações textuais, mesmo não relacionadas às figuras, permite enriquecer o modelo e, em certa medida, resolver os seguintes problemas:
- se o modelo de reconhecimento cometer um erro, geralmente esse erro não será semanticamente próximo da classe correta;
- não há como prever um objeto que pertence a uma nova classe que não foi representada no conjunto de dados de treinamento.
A abordagem proposta sugere a exibição de imagens em um rico espaço semântico no qual os rótulos de classes mais semelhantes estão mais próximos um do que os rótulos de classes menos semelhantes. Como resultado, o modelo apresenta uma distância menos semanticamente distante da verdadeira classe de previsões. Além disso, o modelo, levando em consideração a proximidade visual e semântica, pode classificar corretamente as imagens relacionadas a uma classe que não foi representada no conjunto de dados de treinamento.
Algoritmo Arquitetura
- Pré-treinamos o modelo de linguagem, o que fornece boas incorporações semanticamente significativas. A dimensão do espaço é n. Em seguida, n será considerado igual a 500 ou 1000.
- Pré-treinamos o modelo visual, que classifica bem os objetos em 1000 classes.
- Cortamos a última camada softmax do modelo visual pré-treinado e adicionamos uma camada totalmente conectada de 4096 para n neurônios. Nós treinamos o modelo resultante para cada imagem para prever a incorporação correspondente ao rótulo da imagem.
Vamos explicar com a ajuda de mapeamentos. Seja LM um modelo de linguagem, VM seja um modelo visual com softmax cortado e uma camada totalmente conectada adicionada, I - imagem, L - etiqueta da imagem, LM (L) - etiqueta incorporada no espaço semântico. Na terceira etapa, treinamos a VM para que:
Arquitetura:
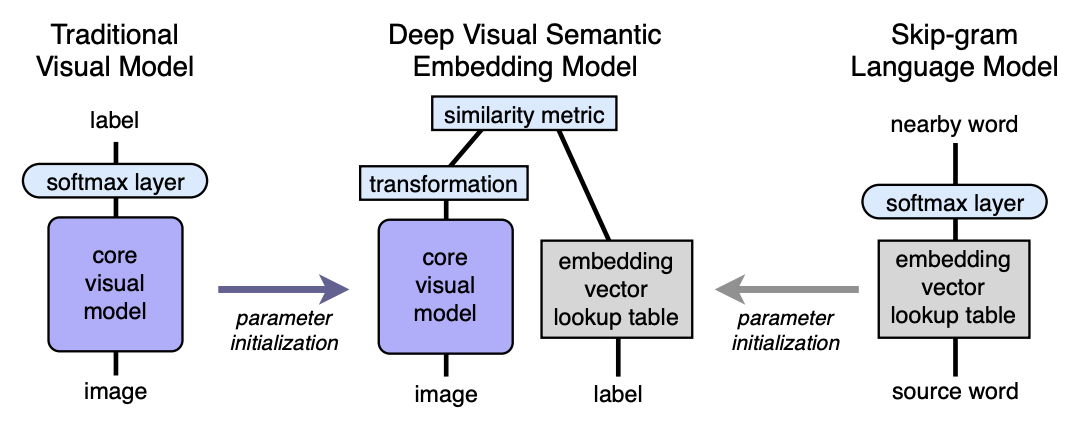
Modelo de linguagem
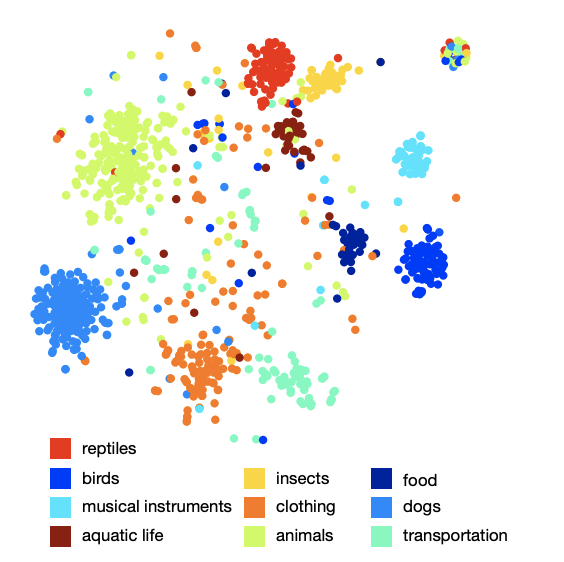
Para aprender o modelo da linguagem, foi utilizado o modelo de pular grama, um corpus de 5,4 bilhões de palavras retirado de wikipedia.org. O modelo usou uma camada hierárquica de softmax para prever conceitos relacionados, uma janela - 20 palavras, o número de passagens pelo corpo - 1. Foi estabelecido experimentalmente que o tamanho da incorporação é melhor para 500-1000.
A imagem da organização das aulas no espaço mostra que o modelo aprendeu uma estrutura semântica qualitativa e rica. Por exemplo, para uma determinada espécie de tubarão no espaço semântico resultante, 9 vizinhos mais próximos são os outros 9 tipos de tubarões.
Modelo visual
A arquitetura que venceu a competição ILSVRC de 2012 foi tomada como modelo visual. O Softmax foi removido e uma camada totalmente conectada foi adicionada para obter o tamanho de incorporação desejado na saída.
Função de perda
Descobriu-se que a escolha da função de perda é importante. Foi usada uma combinação de similaridade de cosseno e perda de classificação de dobradiça. A função de perda incentivou um produto escalar maior entre o vetor do resultado da rede visual e a rotulagem do rótulo correspondente e multado por um produto escalar grande entre o resultado da rede visual e as rotulações dos possíveis rótulos aleatórios da imagem. O número de rótulos aleatórios arbitrários não foi fixo, mas foi limitado pela condição sob a qual a soma de produtos escalares com rótulos falsos se tornou mais do que um produto escalar com um rótulo válido menos uma margem fixa (constante igual a 0,1). Obviamente, todos os vetores foram pré-normalizados.
Processo de treinamento
No começo, apenas a última camada totalmente conectada adicionada foi treinada, o restante da rede não atualizou o peso. Nesse caso, foi utilizado o método de otimização SGD. Em seguida, toda a rede visual foi descongelada e treinada usando o otimizador Adagrad para que, durante a propagação de retorno em diferentes camadas da rede, os gradientes sejam dimensionados corretamente.
Previsão
Durante a previsão, a partir da imagem usando a rede visual, obtemos algum vetor em nosso espaço semântico. Em seguida, encontramos os vizinhos mais próximos, ou seja, alguns rótulos possíveis e, de uma maneira especial, os exibem novamente nos sinsets do ImageNet para pontuação. O procedimento para a última exibição não é tão simples, pois os rótulos no ImageNet são um conjunto de sinônimos, não apenas um rótulo. Se o leitor estiver interessado em conhecer os detalhes, recomendo o artigo original (apêndice 2).
Resultados
O resultado do modelo DEVISE foi comparado com dois modelos:
- Modelo de linha de base Softmax - um modelo de visão de ponta (SOTA - no momento da publicação)
- O modelo de incorporação aleatória é uma versão do modelo DEVISE descrito, em que as incorporação não são aprendidas pelo modelo de linguagem, mas são inicializadas arbitrariamente.
Para avaliar a qualidade, foram utilizadas as métricas hit @ flat e métrica de precisão hierárquica @ k. A métrica "plana" hit @ k é a porcentagem de imagens de teste para as quais o rótulo correto está presente entre as primeiras k opções previstas. A métrica hierárquica de precisão @ k foi usada para avaliar a qualidade da correspondência semântica. Essa métrica foi baseada na hierarquia de rótulos no ImageNet. Para cada rótulo verdadeiro e k fixo, o conjunto
rótulos semanticamente corretos - lista de fundamentos da verdade. Obter a previsão (vizinhos mais próximos) foi a porcentagem de interseção com a lista de verdade do solo.

Os autores esperavam que o modelo softmax apresentasse os melhores resultados em métricas planas, devido ao fato de minimizar a perda de entropia cruzada, o que é muito adequado para métricas “planas” de hit @ k. Os autores ficaram surpresos com a proximidade do modelo DEVISE com o modelo softmax, atingindo a paridade em geral k e ultrapassando k = 20.
Na métrica hierárquica, o modelo DEVISE mostra-se em toda a sua glória e supera o beisebol softmax em 3% para k = 5 e 7% para k = 20.
Aprendizagem zero-shot
Uma vantagem particular do modelo DEVISE é a capacidade de fornecer previsão adequada para imagens cujas etiquetas a rede nunca viu durante o treinamento. Por exemplo, durante o treinamento, a rede viu imagens etiquetadas de tubarão-tigre, tubarão-boi e tubarão-azul e nunca atingiu a marca de tubarão. Como o modelo de linguagem possui uma representação para o tubarão no espaço semântico e está próximo de incorporação de diferentes tipos de tubarão, é muito provável que o modelo dê uma previsão adequada. Isso é chamado de capacidade de generalizar - generalização.
Vamos demonstrar alguns exemplos de previsões de tiro zero:

Observe que o modelo DEVISE, mesmo em suas suposições errôneas, está mais próximo da resposta correta do que as suposições errôneas do modelo softmax.
Portanto, o modelo apresentado perde um pouco para softmax na linha de base em métricas planas, mas vence significativamente na precisão hierárquica @ k métrica. O modelo tem a capacidade de generalizar, produzindo previsões adequadas para imagens cujas etiquetas a rede não atendeu (aprendizado de tiro zero).
A abordagem descrita pode ser facilmente implementada, pois é baseada em dois modelos pré-treinados - linguagem e visual.