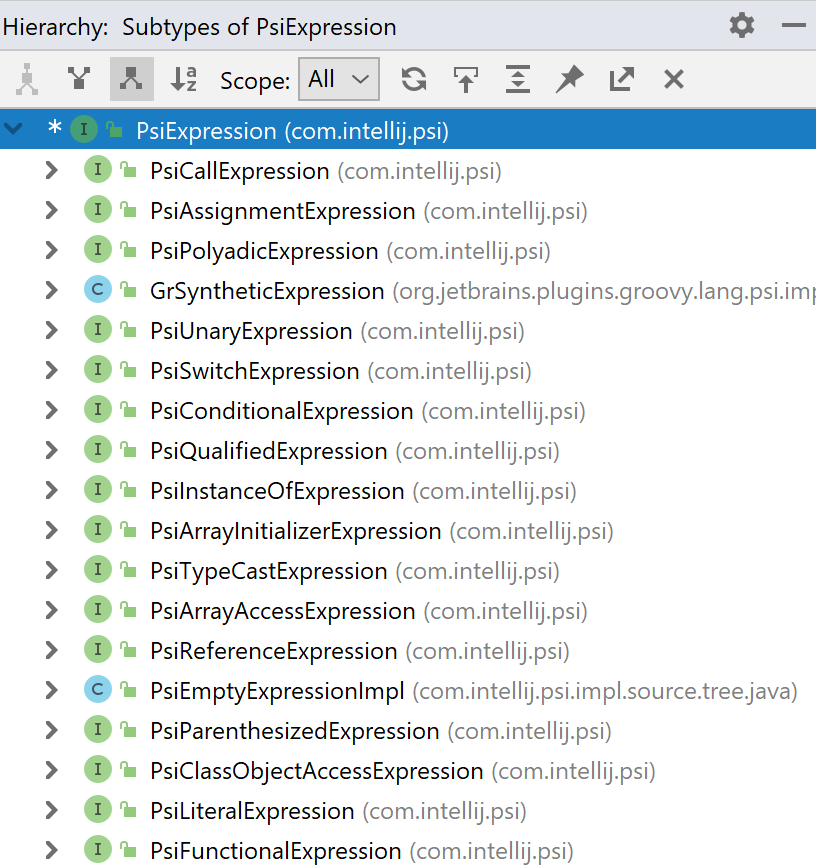
 A pesquisa e a navegação de código são recursos importantes de qualquer IDE. Em Java, uma das opções de pesquisa comumente usadas é procurar todas as implementações de uma interface. Esse recurso costuma ser chamado de hierarquia de tipos e se parece com a imagem à direita.
A pesquisa e a navegação de código são recursos importantes de qualquer IDE. Em Java, uma das opções de pesquisa comumente usadas é procurar todas as implementações de uma interface. Esse recurso costuma ser chamado de hierarquia de tipos e se parece com a imagem à direita.
É ineficiente iterar sobre todas as classes de projeto quando esse recurso é chamado. Uma opção é salvar a hierarquia completa de classes no índice durante a compilação, pois o compilador a constrói de qualquer maneira. Fazemos isso quando a compilação é executada pelo IDE e não delegada, por exemplo, a Gradle. Mas isso funciona apenas se nada tiver sido alterado no módulo após a compilação. Em geral, o código fonte é o provedor de informações mais atualizado e os índices são baseados no código fonte.
Encontrar filhos imediatos é uma tarefa simples se não estamos lidando com uma interface funcional. Ao procurar implementações da interface Foo , precisamos encontrar todas as classes que implements Foo e interfaces que extends Foo , bem como as new Foo(...) {...} classes anônimas do new Foo(...) {...} . Para fazer isso, basta criar uma árvore de sintaxe de cada arquivo de projeto com antecedência, encontrar as construções correspondentes e adicioná-las a um índice. No entanto, há uma complexidade aqui: você pode estar procurando a interface com.example.goodcompany.Foo , enquanto org.example.evilcompany.Foo é realmente usado. Podemos colocar o nome completo da interface pai no índice com antecedência? Pode ser complicado. Por exemplo, o arquivo em que a interface é usada pode ter esta aparência:
Olhando apenas o arquivo, é impossível dizer qual é o nome totalmente qualificado de Foo . Teremos que analisar o conteúdo de vários pacotes. E cada pacote pode ser definido em vários locais do projeto (por exemplo, em vários arquivos JAR). Se executarmos a resolução adequada do símbolo ao analisar esse arquivo, a indexação levará muito tempo. Mas o principal problema é que o índice criado no MyFoo.java também dependerá de outros arquivos. Podemos mover a declaração da interface Foo , por exemplo, do pacote org.example.foo para o pacote org.example.bar , sem alterar nada no arquivo MyFoo.java , mas o nome completo do Foo será alterado.
No IntelliJ IDEA, os índices dependem apenas do conteúdo de um único arquivo. Por um lado, é muito conveniente: o índice associado a um arquivo específico se torna inválido quando o arquivo é alterado. Por outro lado, impõe grandes restrições ao que pode ser colocado no índice. Por exemplo, ele não permite que os nomes completos das classes pai sejam salvos de forma confiável no índice. Mas, em geral, não é tão ruim assim. Ao solicitar uma hierarquia de tipos, podemos encontrar tudo que corresponda à nossa solicitação por um nome abreviado e, em seguida, executar a resolução de símbolo adequada para esses arquivos e determinar se é isso que estamos procurando. Na maioria dos casos, não haverá muitos símbolos redundantes e a verificação não demorará muito.
 As coisas mudam, no entanto, quando a classe cujos filhos estamos procurando é uma interface funcional. Além das subclasses explícitas e anônimas, haverá expressões lambda e referências de método. O que colocamos no índice agora e o que deve ser avaliado durante a pesquisa?
As coisas mudam, no entanto, quando a classe cujos filhos estamos procurando é uma interface funcional. Além das subclasses explícitas e anônimas, haverá expressões lambda e referências de método. O que colocamos no índice agora e o que deve ser avaliado durante a pesquisa?
Vamos supor que temos uma interface funcional:
@FunctionalInterface public interface StringConsumer { void consume(String s); }
O código contém diferentes expressões lambda. Por exemplo:
() -> {}
Isso significa que podemos filtrar rapidamente lambdas que possuem um número inadequado de parâmetros ou um tipo de retorno claramente inadequado, por exemplo, nulo em vez de nulo. Geralmente, é impossível determinar o tipo de retorno com mais precisão. Por exemplo, em s -> list.add(s) você terá que resolver a list e add e, possivelmente, executar um procedimento regular de inferência de tipo. Leva tempo e depende do conteúdo de outros arquivos.
Temos sorte se a interface funcional receber cinco argumentos. Mas se for necessário apenas um, o filtro manterá um grande número de lambdas desnecessárias. É ainda pior quando se trata de referências de métodos. Pelo que parece, não se pode dizer se uma referência de método é adequada ou não.
Para esclarecer as coisas, pode valer a pena examinar o que rodeia a lambda. Às vezes funciona. Por exemplo:
Em todos esses casos, o nome abreviado da interface funcional correspondente pode ser determinado no arquivo atual e pode ser colocado no índice ao lado da expressão funcional, seja uma lambda ou uma referência de método. Infelizmente, em projetos da vida real, esses casos cobrem uma porcentagem muito pequena de todas as lambdas. Na maioria dos casos, as lambdas são usadas como argumentos do método:
list.stream() .filter(s -> StringUtil.isNonEmpty(s)) .map(s -> s.trim()) .forEach(s -> list.add(s));
Qual das três lambdas pode conter StringConsumer ? Obviamente, nenhum. Aqui, temos uma cadeia de API de fluxo que apresenta apenas interfaces funcionais da biblioteca padrão; ela não pode ter o tipo personalizado.
No entanto, o IDE deve ser capaz de entender o truque e fornecer uma resposta exata. E se list não for exatamente java.util.List e list.stream() retornar algo diferente de java.util.stream.Stream ? Em seguida, teremos que resolver a list , que, como sabemos, não pode ser feita de maneira confiável com base apenas no conteúdo do arquivo atual. E mesmo que o façamos, a pesquisa não deve depender da implementação da biblioteca padrão. E se neste projeto em particular substituímos java.util.List por uma classe própria? A pesquisa deve levar isso em conta. E, naturalmente, as lambdas são usadas não apenas em fluxos padrão: existem muitos outros métodos para os quais são transmitidos.
Como resultado, podemos consultar o índice para obter uma lista de todos os arquivos Java que usam lambdas com o número necessário de parâmetros e um tipo de retorno válido (na verdade, procuramos apenas quatro opções: void, non-void, boolean e qualquer). E o que vem depois? Precisamos construir uma árvore PSI completa (uma espécie de árvore de análise com resolução de símbolo, inferência de tipo e outros recursos inteligentes) para cada um desses arquivos e executar inferência de tipo adequada para lambdas? Para um grande projeto, levará muito tempo para obter a lista de todas as implementações de interface, mesmo se houver apenas duas delas.
Portanto, precisamos seguir os seguintes passos:
- Pergunte ao índice (não é caro)
- Criar PSI (caro)
- Inferir tipo lambda (muito caro)
Para Java 8 e posterior, a inferência de tipo é uma operação extremamente cara. Em uma cadeia de chamadas complexa, pode haver muitos parâmetros genéricos de substituição, cujos valores devem ser determinados usando o procedimento contencioso descrito no Capítulo 18 da especificação. Para o arquivo atual, isso pode ser feito em segundo plano, mas processar milhares de arquivos não abertos dessa maneira seria uma tarefa cara.
Aqui, no entanto, é possível cortar ligeiramente os cantos: na maioria dos casos, não precisamos do tipo de concreto. A menos que um método aceite um parâmetro genérico em que o lambda é passado para ele, a etapa final de substituição de parâmetro pode ser evitada. Se inferimos o tipo java.util.function.Function<T, R> lambda, não precisamos avaliar os valores dos parâmetros substitucionais T e R : já está claro se deve incluir o lambda nos resultados da pesquisa ou não No entanto, não funcionará para um método como este:
static <T> void doSmth(Class<T> aClass, T value) {}
Este método pode ser chamado com doSmth(Runnable.class, () -> {}) . Em seguida, o tipo lambda será inferido como T , a substituição ainda é necessária. No entanto, este é um caso raro. Podemos poupar algum tempo de CPU aqui, mas apenas cerca de 10%, portanto isso não resolve o problema em sua essência.
Como alternativa, quando a inferência precisa de tipo é muito complicada, pode ser feita aproximada. Diferentemente da especificação sugerida, deixe-o funcionar apenas nos tipos de classe apagados e não reduza o conjunto de restrições, mas siga uma cadeia de chamadas. Desde que o tipo apagado não inclua parâmetros genéricos, tudo estará bem. Vamos considerar o fluxo do exemplo acima e determinar se o último lambda implementa StringConsumer :
- variável de
list -> tipo java.util.List List.stream() → Tipo java.util.stream.StreamStream.filter(...) -> tipo java.util.stream.Stream , não precisamos considerar argumentos de filter- da mesma forma,
Stream.map(...) → tipo java.util.stream.Stream Stream.forEach(...) → esse método existe, seu parâmetro tem o tipo Consumer , que obviamente não é StringConsumer .
E é assim que poderíamos fazer sem inferência de tipo regular. Com essa abordagem simples, no entanto, é fácil executar métodos sobrecarregados. Se não realizarmos inferência de tipo adequada, não podemos escolher o método sobrecarregado correto. Às vezes é possível, no entanto: se os métodos tiverem um número diferente de parâmetros. Por exemplo:
CompletableFuture.supplyAsync(Foo::bar, myExecutor).thenRunAsync(s -> list.add(s));
Aqui podemos ver que:
- Existem dois métodos
CompletableFuture.supplyAsync ; o primeiro pega um argumento e o segundo pega dois, então escolhemos o segundo. Retorna CompletableFuture . - Existem dois métodos
thenRunAsync também, e podemos escolher da mesma forma aquele que recebe um argumento. O parâmetro correspondente tem o tipo Runnable , o que significa que não é StringConsumer .
Se vários métodos tiverem o mesmo número de parâmetros ou tiverem um número variável de parâmetros, mas parecerem apropriados, teremos que pesquisar todas as opções. Muitas vezes, não é tão assustador:
new StringBuilder().append(foo).append(bar).chars().forEach(s -> list.add(s));
new StringBuilder() obviamente cria java.lang.StringBuilder . Para construtores, ainda resolvemos a referência, mas a inferência de tipo complexa não é necessária aqui. Mesmo se houvesse new Foo<>(x, y, z) , não inferiríamos os valores dos parâmetros de tipo, pois apenas Foo é de interesse para nós.- Existem muitos métodos
StringBuilder.append que usam um argumento, mas todos retornam o tipo java.lang.StringBuilder , portanto, não nos importamos com os tipos de foo e bar . - Há um método
StringBuilder.chars e retorna java.util.stream.IntStream . - Existe um único método
IntStream.forEach e é necessário o tipo IntConsumer .
Mesmo que várias opções permaneçam, você ainda pode acompanhar todas elas. Por exemplo, o tipo lambda passado para ForkJoinPool.getInstance().submit(...) pode ser Runnable ou Callable e, se estamos procurando outra opção, ainda podemos descartar esse lambda.
As coisas pioram quando o método retorna um parâmetro genérico. Em seguida, o procedimento falhará e você precisará executar uma inferência de tipo adequada. No entanto, apoiamos um caso. É bem exibido na minha biblioteca StreamEx, que possui uma classe abstrata AbstractStreamEx<T, S extends AbstractStreamEx<T, S>> classe abstrata AbstractStreamEx<T, S extends AbstractStreamEx<T, S>> que contém métodos como o S filter(Predicate<? super T> predicate) . Normalmente, as pessoas trabalham com um StreamEx<T> extends AbstractStreamEx<T, StreamEx<T>> concreto StreamEx<T> extends AbstractStreamEx<T, StreamEx<T>> classe StreamEx<T> extends AbstractStreamEx<T, StreamEx<T>> . Nesse caso, você pode substituir o parâmetro type e descobrir que S = StreamEx .
É assim que nos livramos da inferência de tipo dispendiosa em muitos casos. Mas não fizemos nada com a construção do PSI. É decepcionante ter analisado um arquivo com 500 linhas de código apenas para descobrir que o lambda na linha 480 não corresponde à nossa consulta. Vamos voltar ao nosso fluxo:
list.stream() .filter(s -> StringUtil.isNonEmpty(s)) .map(s -> s.trim()) .forEach(s -> list.add(s));
Se list é uma variável local, um parâmetro de método ou um campo na classe atual, já no estágio de indexação, podemos encontrar sua declaração e estabelecer que o nome do tipo abreviado é List . Dessa forma, podemos colocar as seguintes informações no índice do último lambda:
Esse tipo lambda é um tipo de parâmetro de um método forEach que usa um argumento, chamado no resultado de um método de map que usa um argumento, chamado no resultado de um método de filter que usa um argumento, chamado no resultado de um método de stream que recebe zero argumentos, chamados em um objeto de List .
Toda essa informação está disponível no arquivo atual e, portanto, pode ser colocada no índice. Durante a pesquisa, solicitamos essas informações sobre todas as lambdas do índice e tentamos restaurar o tipo lambda sem criar um PSI. Primeiro, teremos que fazer uma pesquisa global por classes com o nome abreviado da List . Obviamente, encontraremos não apenas java.util.List mas também java.awt.List ou algo do código do projeto. Em seguida, todas essas classes passarão pelo mesmo procedimento aproximado de inferência de tipo que usamos anteriormente. Classes redundantes geralmente são filtradas rapidamente. Por exemplo, java.awt.List não tem método de stream , portanto, ele será excluído. Porém, mesmo se algo redundante permanecer e encontrarmos vários candidatos para o tipo lambda, é provável que nenhum deles corresponda à consulta de pesquisa e ainda assim evitaremos criar um PSI completo.
A pesquisa global pode se tornar muito cara (quando um projeto contém muitas classes de List ) ou o início da cadeia não pode ser resolvido no contexto de um arquivo (por exemplo, é um campo de uma classe pai) ou o A cadeia pode se quebrar conforme o método retorna um parâmetro genérico. Não desistiremos e tentaremos recomeçar com a pesquisa global no próximo método da cadeia. Por exemplo, para a cadeia map.get(key).updateAndGet(a -> a * 2) , a seguinte instrução vai para o índice:
Esse tipo lambda é o tipo do parâmetro único de um método updateAndGet , chamado no resultado de um método get com um parâmetro, chamado em um objeto Map .
Imagine que temos sorte e o projeto tenha apenas um tipo de Map java.util.Map . Ele possui um método get(Object) , mas, infelizmente, retorna um parâmetro genérico V Em seguida, descartamos a cadeia e procuramos o método updateAndGet com um parâmetro globalmente (usando o índice, é claro). E estamos felizes em descobrir que existem apenas três métodos no projeto: nas AtomicInteger , AtomicLong e AtomicReference com os tipos de parâmetro IntUnaryOperator , LongUnaryOperator e UnaryOperator , respectivamente. Se estamos procurando outro tipo, já descobrimos que esse lambda não corresponde à solicitação e não precisamos criar o PSI.
Surpreendentemente, este é um bom exemplo de um recurso que funciona mais devagar com o tempo. Por exemplo, quando você está procurando implementações de uma interface funcional e possui apenas três delas em seu projeto, o IntelliJ IDEA leva dez segundos para encontrá-las. Você se lembra que há três anos o número era o mesmo, mas o IDE forneceu os resultados da pesquisa em apenas dois segundos na mesma máquina. E, embora seu projeto seja grande, ele cresceu apenas cinco por cento nesses anos. É razoável começar a reclamar sobre o que os desenvolvedores do IDE fizeram de errado para torná-lo terrivelmente lento.
Embora possamos ter mudado nada. A pesquisa funciona como costumava fazer há três anos. O fato é que, três anos atrás, você acabou de mudar para o Java 8 e tinha apenas cem lambdas em seu projeto. Até agora, seus colegas transformaram classes anônimas em lambdas, começaram a usar fluxos ou alguma biblioteca reativa. Como resultado, em vez de cem lambdas, existem dez mil. E agora, para encontrar os três necessários, o IDE precisa pesquisar centenas de vezes mais opções.
Eu disse "poderíamos" porque, naturalmente, voltamos a essa pesquisa de tempos em tempos e tentamos acelerá-la. Mas é como remar o riacho, ou melhor, subir a cachoeira. Nós nos esforçamos bastante, mas o número de lambdas em projetos continua crescendo muito rapidamente.