O mercado de computação distribuída e big data, segundo as
estatísticas , cresce de 18 a 19% ao ano. Portanto, a questão de escolher um software para esses fins permanece relevante. Nesta postagem, começamos com o motivo pelo qual a computação distribuída é necessária, abordamos a escolha do software, falamos sobre o uso do Hadoop com o Cloudera e, finalmente, falamos sobre a escolha do hardware e como isso afeta o desempenho de maneiras diferentes.
Por que precisamos de computação distribuída em um negócio regular? Tudo é simples e complicado ao mesmo tempo. Simples - porque na maioria dos casos realizamos cálculos relativamente simples por unidade de informação. É difícil porque há muitas dessas informações. Muito. Como resultado, você deve
processar terabytes de dados em 1000 threads . Portanto, os cenários de uso são bastante universais: os cálculos podem ser aplicados sempre que for necessário levar em consideração um grande número de métricas em uma matriz ainda maior de dados.
Um exemplo recente: a cadeia de pizza Dodo Pizza
determinou, com base em uma análise da base de pedidos dos clientes, que, ao escolher uma pizza com recheio arbitrário, os usuários geralmente operam com apenas seis conjuntos básicos de ingredientes, além de alguns aleatórios. De acordo com isso, a pizzaria ajustou as compras. Além disso, ela pôde recomendar melhor aos usuários produtos adicionais oferecidos no estágio do pedido, o que ajudou a aumentar os lucros.
Outro exemplo: a
análise das posições
de commodities permitiu à loja H&M reduzir em 40% o alcance de lojas individuais, mantendo o nível de vendas. Isso foi conseguido com a eliminação de posições de venda deficiente e a sazonalidade foi levada em consideração nos cálculos.
Seleção de ferramenta
O padrão do setor para esse tipo de computação é o Hadoop. Porque Como o Hadoop é uma estrutura excelente e bem documentada (o mesmo Habr publica muitos artigos detalhados sobre esse tópico), acompanhado por todo um conjunto de utilitários e bibliotecas. Você pode inserir enormes conjuntos de dados estruturados e não estruturados, e o próprio sistema os distribuirá entre o poder da computação. Além disso, essas mesmas capacidades podem ser aumentadas ou desativadas a qualquer momento - a mesma escalabilidade horizontal em ação.
Em 2017, a influente empresa de consultoria Gartner
concluiu que o Hadoop seria em breve obsoleto. O motivo é bastante banal: os analistas acreditam que as empresas migrarão massivamente para a nuvem, porque lá podem pagar pelo fato de usar o poder da computação. O segundo fator importante, supostamente capaz de "enterrar" o Hadoop - é a velocidade do trabalho. Como opções como o Apache Spark ou o Google Cloud DataFlow são mais rápidas que o MapReduce subjacente ao Hadoop.
O Hadoop baseia-se em vários pilares, dos quais os mais notáveis são as tecnologias MapReduce (um sistema de distribuição de dados para computação entre servidores) e o sistema de arquivos HDFS. O último foi projetado especificamente para armazenar informações distribuídas entre os nós do cluster: cada bloco de tamanho fixo pode ser colocado em vários nós e, graças à replicação, o sistema é imune a falhas de nós individuais. Em vez de uma tabela de arquivos, um servidor especial chamado NameNode é usado.
A ilustração abaixo mostra o fluxo de trabalho do MapReduce. No primeiro estágio, os dados são divididos de acordo com uma determinada característica, no segundo - eles são distribuídos de acordo com o poder computacional, no terceiro - o cálculo é realizado.
O MapReduce foi originalmente criado pelo Google para as necessidades de sua pesquisa. Em seguida, o MapReduce entrou no código livre e o Apache assumiu o projeto. Bem, o Google migrou gradualmente para outras soluções. Uma nuance interessante: no momento, o Google tem um projeto chamado Google Cloud Dataflow, posicionado como o próximo passo após o Hadoop, como uma substituição rápida.
Uma análise mais detalhada revela que o Google Cloud Dataflow é baseado em uma variedade de Apache Beam, enquanto o Apache Beam inclui uma estrutura bem documentada do Apache Spark, que nos permite falar sobre quase a mesma velocidade de execução de decisões. Bem, o Apache Spark funciona bem no sistema de arquivos HDFS, que permite implantá-lo nos servidores Hadoop.
Adicione aqui o volume de soluções de documentação e chave na mão para Hadoop e Spark contra o Google Cloud Dataflow, e a escolha da ferramenta se torna óbvia. Além disso, os engenheiros podem decidir por si mesmos qual código - no Hadoop ou Spark - a ser executado, concentrando-se na tarefa, experiência e qualificações.
Servidor local ou na nuvem
A tendência para uma transição universal para a nuvem gerou um termo tão interessante como Hadoop como serviço. Nesse cenário, a administração dos servidores conectados se tornou muito importante. Porque, apesar de sua popularidade, o Hadoop puro é uma ferramenta bastante difícil de configurar, pois muitas coisas precisam ser feitas com suas mãos. Por exemplo, configure individualmente os servidores, monitore seu desempenho, configure cuidadosamente muitos parâmetros. Em geral, trabalhar para um amador é uma ótima chance de estragar alguma coisa ou perder alguma coisa.
Portanto, várias distribuições, inicialmente equipadas com ferramentas convenientes de implantação e administração, ganharam grande popularidade. Uma das distribuições mais populares que suportam o Spark e facilitam as coisas é o Cloudera. Possui uma versão paga e uma gratuita - e, nesta última, toda a funcionalidade básica está disponível, e sem limitar o número de nós.

Durante a instalação, o Cloudera Manager se conectará via SSH aos seus servidores. Um ponto interessante: durante a instalação, é melhor indicar que isso deve ser feito pelos chamados
pacotes : pacotes especiais, cada um dos quais contém todos os componentes necessários configurados para trabalhar um com o outro. De fato, esta é uma versão melhorada do gerenciador de pacotes.
Após a instalação, obtemos o console de gerenciamento de cluster, onde você pode ver a telemetria por cluster, serviços instalados, além de adicionar / remover recursos e editar a configuração do cluster.
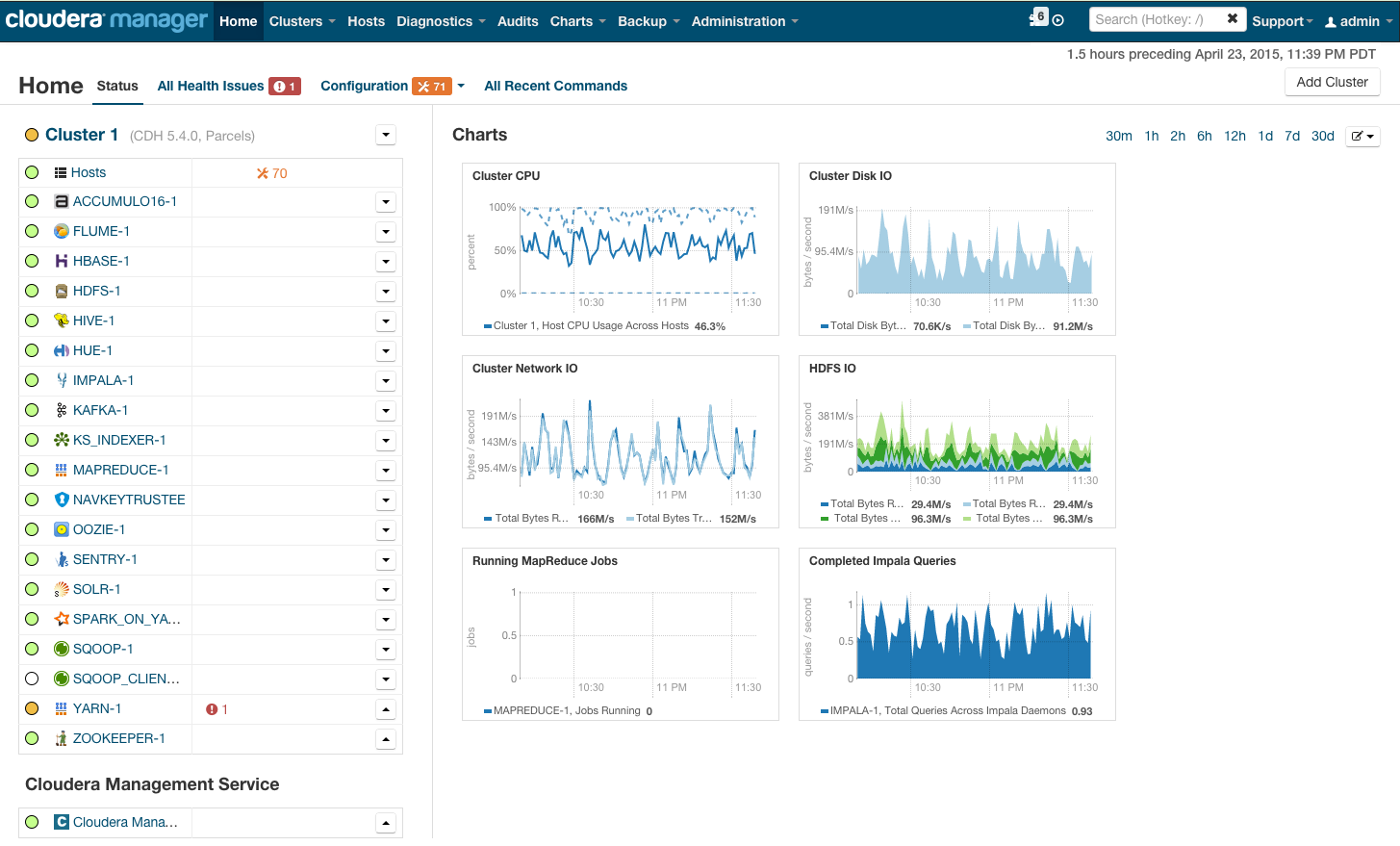
Como resultado, você vê a cabine do foguete que o levará ao futuro brilhante do BigData. Mas antes de você dizer "vamos lá", vamos nos esconder.
Requisitos de hardware
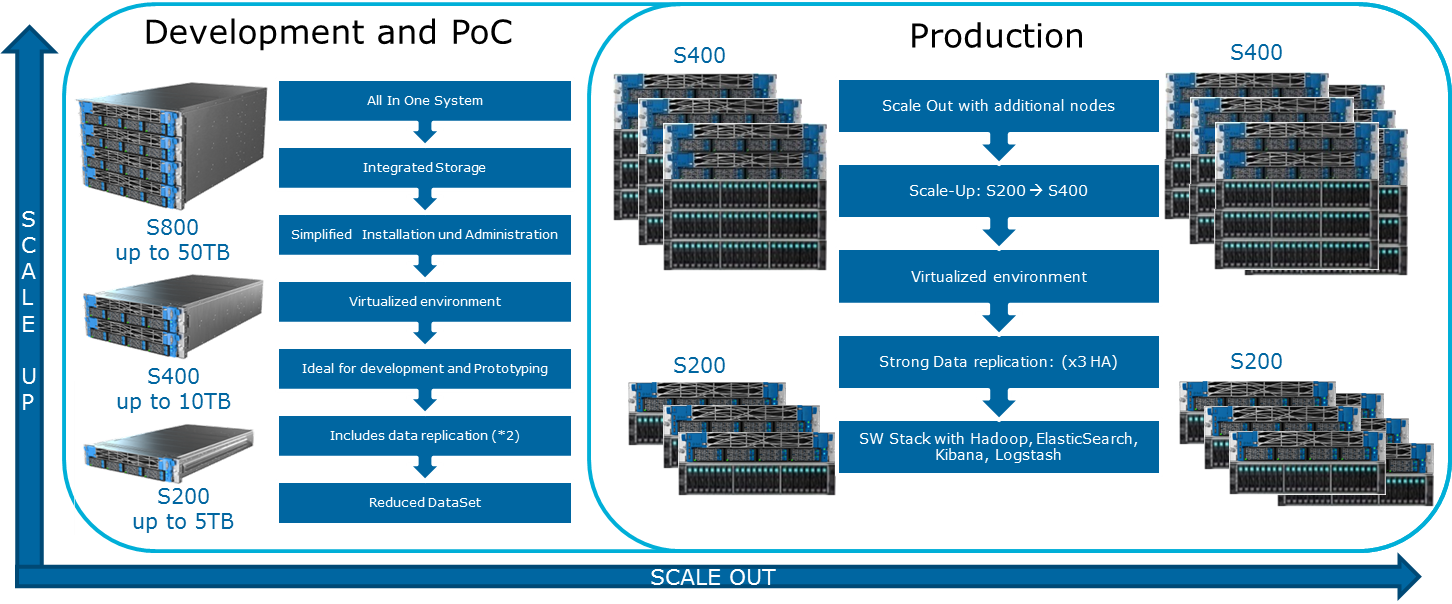
Cloudera menciona várias configurações possíveis em seu site. Os princípios gerais pelos quais eles são construídos são mostrados na ilustração:
Para lubrificar esta imagem otimista pode MapReduce. Se você olhar novamente para o diagrama da seção anterior, torna-se óbvio que, em quase todos os casos, a tarefa MapReduce pode ter um gargalo ao ler dados do disco ou da rede. Isso também é destaque no blog Cloudera. Como resultado, para quaisquer cálculos rápidos, inclusive através do Spark, que geralmente é usado para cálculos em tempo real, a velocidade de E / S é muito importante. Portanto, ao usar o Hadoop, é muito importante que máquinas rápidas e equilibradas entrem no cluster, o que, para dizer o mínimo, nem sempre é fornecido na infraestrutura de nuvem.
O balanceamento de carga balanceado é alcançado através do uso da virtualização Openstack em servidores com poderosas CPUs multi-core. Os nós de dados recebem seus recursos do processador e discos específicos. Em nossa solução
Atos Codex Data Lake Engine , é alcançada uma ampla virtualização, e é por isso que vencemos tanto no desempenho (a influência da infraestrutura de rede é minimizada) quanto no TCO (servidores físicos desnecessários são eliminados).
No caso de usar servidores BullSequana S200, obtemos uma carga muito uniforme, sem alguns gargalos. A configuração mínima inclui 3 servidores BullSequana S200, cada um com dois JBODs, além de S200s adicionais opcionais, contendo quatro nós de dados, opcionalmente conectados. Aqui está um exemplo de carregamento no teste do TeraGen:
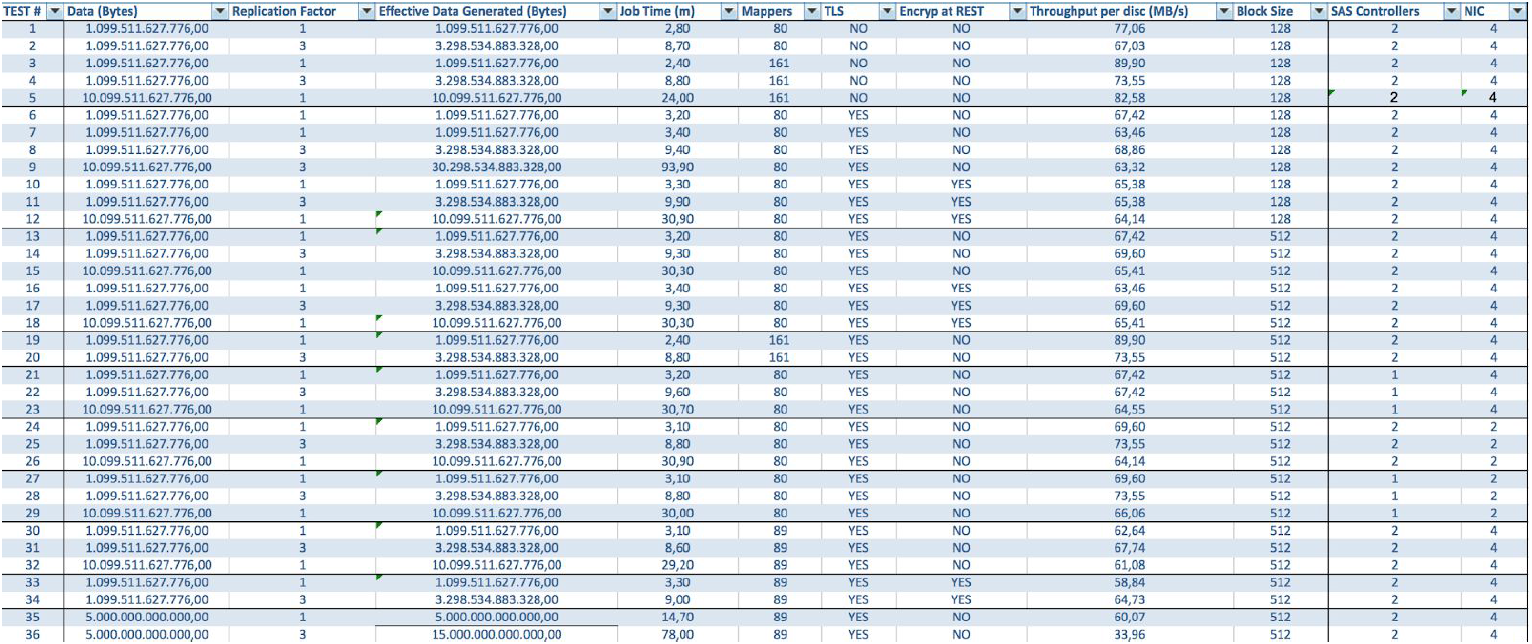
Testes com diferentes volumes de dados e valores de replicação mostram os mesmos resultados em termos de balanceamento de carga entre nós do cluster. Abaixo está um gráfico da distribuição do acesso ao disco por testes de desempenho.
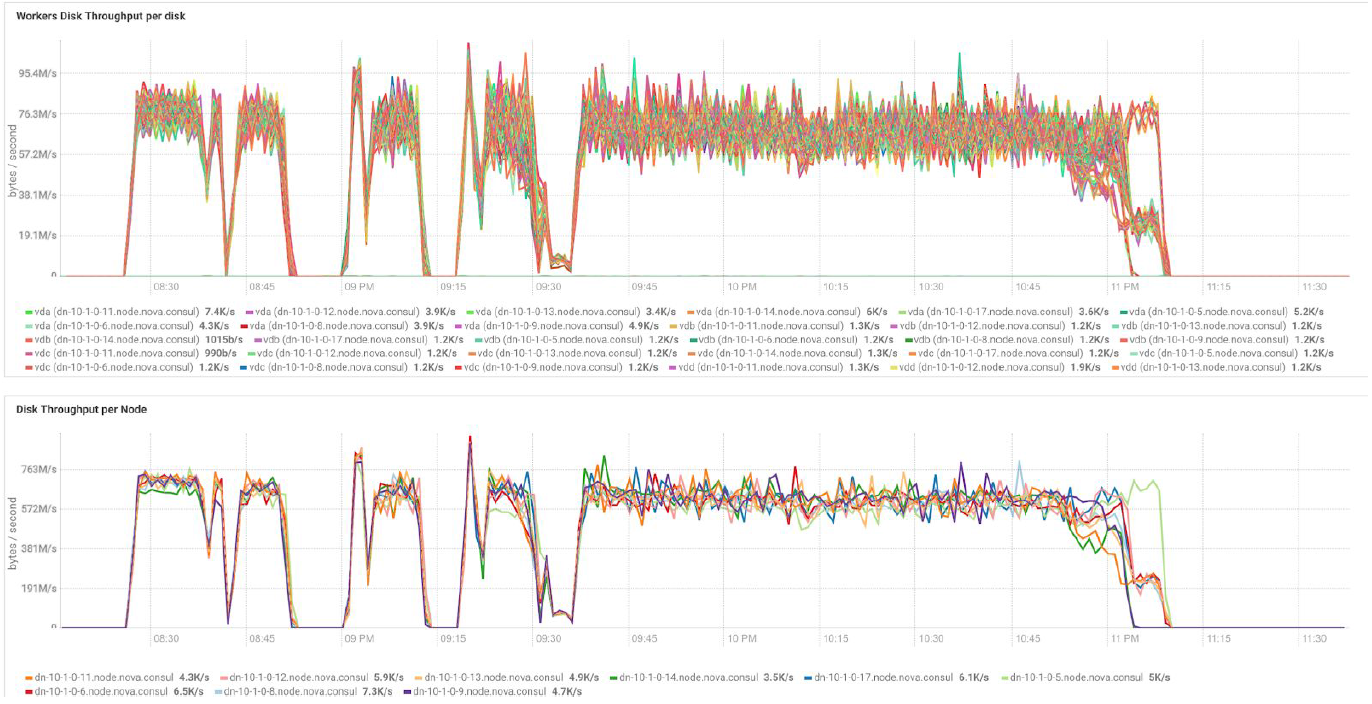
Os cálculos são baseados na configuração mínima de 3 servidores BullSequana S200. Inclui 9 nós de dados e 3 nós principais, além de máquinas virtuais reservadas em caso de implantação de proteção baseada na OpenStack Virtualization. Resultado do teste TeraSort: o tamanho do bloco de 512 MB do coeficiente de replicação de três com a criptografia é de 23,1 minutos.
Como posso expandir o sistema? Vários tipos de extensões estão disponíveis para o Data Lake Engine:
- Nós de dados: para cada 40 TB de espaço útil
- Nós analíticos com a capacidade de instalar uma GPU
- Outras opções, dependendo das necessidades da empresa (por exemplo, se você precisar de Kafka e similares)
O Atos Codex Data Lake Engine inclui os próprios servidores e o software pré-instalado, incluindo um conjunto licenciado Cloudera; O próprio Hadoop, o OpenStack com máquinas virtuais baseadas no kernel RedHat Enterprise Linux, um sistema de replicação de dados e backup (incluindo o uso do nó de backup e do Cloudera BDR - Backup and Disaster Recovery). O Atos Codex Data Lake Engine foi a primeira solução de virtualização certificada pela
Cloudera .
Se você estiver interessado nos detalhes, teremos o maior prazer em responder às nossas perguntas nos comentários.