
Olá Habr! A descrição da operação do interior de uma grande plataforma de pagamento continuará logicamente com uma descrição de como exatamente todos esses componentes funcionam no mundo real no hardware físico. Nesta postagem, eu estou falando sobre como e onde os aplicativos da plataforma estão localizados, como o tráfego do mundo exterior os alcança e também descreverei o esquema de um rack padrão para nós com equipamentos localizados em qualquer um dos nossos data centers.
Abordagens e limitações

Um dos primeiros requisitos que formulamos antes do desenvolvimento da plataforma parece "a capacidade de dimensionar recursos de computação linearmente para garantir o processamento de qualquer número de transações".
As abordagens clássicas dos sistemas pagos usadas pelos participantes do mercado implicam a presença de um teto, embora bastante alto, de acordo com as declarações. Normalmente, soa assim: "nosso processamento pode aceitar 1000 transações por segundo".
Essa abordagem não se encaixa em nossos objetivos e arquitetura de negócios. Nós não queremos ter nenhum limite. De fato, seria estranho ouvir do Yandex ou do Google a afirmação "podemos processar 1 milhão de pesquisas por segundo". A plataforma deve processar tantas solicitações quanto a empresa precisar no momento devido à arquitetura, o que permite, para simplificar, enviar um trabalhador de TI com um carrinho de servidores que ele instalará em racks, conectará ao switch e sairá. E o orquestrador da plataforma lançará cópias das instâncias de aplicativos de negócios para novas capacidades, como resultado do qual obteremos o aumento de RPS necessário.
O segundo requisito importante é garantir a alta disponibilidade dos serviços fornecidos. Seria engraçado, mas não muito útil, criar uma plataforma de pagamento que possa aceitar um número infinito de pagamentos em / dev / null.
Talvez a maneira mais eficaz de obter alta disponibilidade seja duplicar as entidades que atendem ao serviço várias vezes, para que a falha de qualquer número razoável de aplicativos, equipamentos ou data centers não afete a disponibilidade geral da plataforma.
A duplicação múltipla de aplicativos requer um grande número de servidores físicos e equipamentos de rede relacionados. Esse ferro custa dinheiro, cuja quantidade temos, é claro, que não podemos dar ao luxo de comprar muito ferro caro. Portanto, a plataforma foi projetada de maneira a acomodar e se sentir bem facilmente em uma grande quantidade de ferro barato e pouco potente, ou mesmo em uma nuvem pública.
O uso de servidores que não são os mais fortes em termos de poder de computação tem suas vantagens - sua falha não tem um efeito crítico nas condições gerais do sistema como um todo. Imagine o que é melhor - se um servidor de marca caro, grande e super confiável queimar, executando um DBMS de acordo com o esquema mestre-escravo (e de acordo com a lei de Murphy, ele certamente queimará e na noite de 31 de dezembro) ou alguns servidores em um cluster de 30 nós executando de acordo com os sem-mestre diagrama?
Com base nessa lógica, decidimos não criar outro ponto massivo de falha na forma de uma matriz de disco centralizada. Dispositivos de bloco comuns são fornecidos a nós pelo cluster Ceph, que é implantado hiperconvergente nos mesmos servidores, mas com uma infraestrutura de rede separada.
Assim, logicamente chegamos ao esquema geral de um rack universal com recursos de computação na forma de servidores baratos e pouco potentes no data center. Se precisarmos de mais recursos, finalizamos qualquer rack gratuito com servidores ou colocamos outro, de preferência mais perto.

Bem, no final, é simplesmente lindo. Quando uma quantidade clara do mesmo ferro é instalada nos racks, isso permite que você resolva problemas com a qualidade da instalação de arame, permite livrar-se dos ninhos da andorinha e o perigo de se enroscar nos fios, deixando cair o processamento. Do ponto de vista da engenharia, o sistema deve ser bonito em qualquer lugar - tanto do lado de dentro na forma de código quanto do lado de fora na forma de servidores e hardware de rede. Um sistema bonito funciona melhor e com mais confiabilidade. Eu tinha exemplos suficientes para verificar isso com a minha própria experiência.
Por favor, não pense que somos trapaceiros ou que os negócios são prejudicados por financiamento. Desenvolver e manter uma plataforma distribuída é realmente um prazer muito caro. De fato, isso é ainda mais caro do que possuir um sistema clássico, construído, condicionalmente, em um hardware de marca poderosa com Oracle / MSSQL, servidores de aplicativos e outras ligações.
Nossa abordagem compensa com alta confiabilidade, recursos de dimensionamento horizontal muito flexíveis, falta de um limite no número de pagamentos por segundo e não importa o quão estranho isso pareça - muito divertido para a equipe de TI. Para mim, o nível de prazer dos desenvolvedores e devops do sistema que eles criam não é menos importante do que o tempo previsto de desenvolvimento, a quantidade e a qualidade dos recursos lançados.
Infraestrutura do servidor

Logicamente, nossas capacidades de servidor podem ser divididas em duas classes principais: servidores para hipervisores, para os quais a densidade de núcleos de CPU e RAM por unidade é importante, e servidores de armazenamento, onde a ênfase principal está na quantidade de espaço em disco por unidade, e CPU e RAM já estão selecionados para número de discos.
No momento, nosso servidor clássico para poder de computação fica assim:
- CPU 2xXeon E5-2630;
- 128G RAM;
- SSD 3xSATA (pool Ceph SSD);
- SSD 1xNVMe (cache dm).
Servidor para armazenar estados:
- CPU 1xXeon E5-2630;
- 12-16 HDD;
- 2 SSDs para block.db;
- 32G RAM.
Infraestrutura de rede
Na escolha do hardware de rede, nossa abordagem é um pouco diferente. Ainda usamos switches de marca para alternar e rotear entre vlan-s, agora é o Cisco SG500X-48 e o Cisco Nexus C5020 na SAN.
Fisicamente, cada servidor está conectado à rede por 4 portas físicas:
- 2x1GbE - rede de gerenciamento e RPC entre aplicativos;
- 2x10GbE - rede para armazenamento.
As interfaces dentro das máquinas são combinadas por ligação, e o tráfego marcado diverge de acordo com a vlan desejada.
Talvez este seja o único local em nossa infraestrutura onde você pode ver o rótulo de um fornecedor famoso. Porque para roteamento, filtragem de rede e inspeção de tráfego, usamos hosts Linux. Não compramos roteadores especializados. Tudo o que precisamos é configurado nos servidores executando o Gentoo (tabelas de ip para filtragem, BIRD para roteamento dinâmico, Suricata como IDS / IPS, Wallarm como WAF).
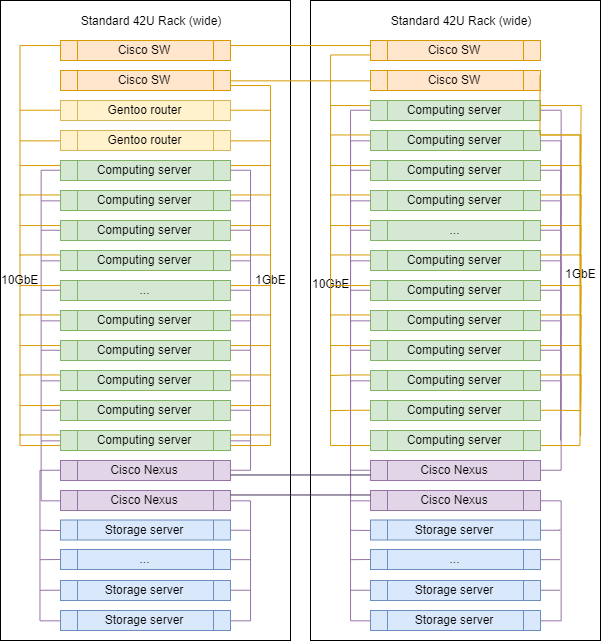
Rack típico em DC
Ao aumentar a escala, os racks nos controladores de domínio praticamente não diferem entre si, exceto nos roteadores de ligação ascendente, instalados em um deles.
As proporções exatas de servidores de diferentes classes podem variar, mas, em geral, a lógica é preservada - há mais servidores para computação do que servidores para armazenamento de dados.
Bloquear dispositivos e compartilhamento de recursos
Vamos tentar juntar tudo. Imagine que precisamos colocar vários de nossos microsserviços na infraestrutura, para maior clareza, serão microsserviços que precisam se comunicar via RPC e um deles é o Machinegun, que armazena o estado no cluster Riak, além de alguns serviços auxiliares, como como nós ES e Consul.
Um layout típico ficaria assim:
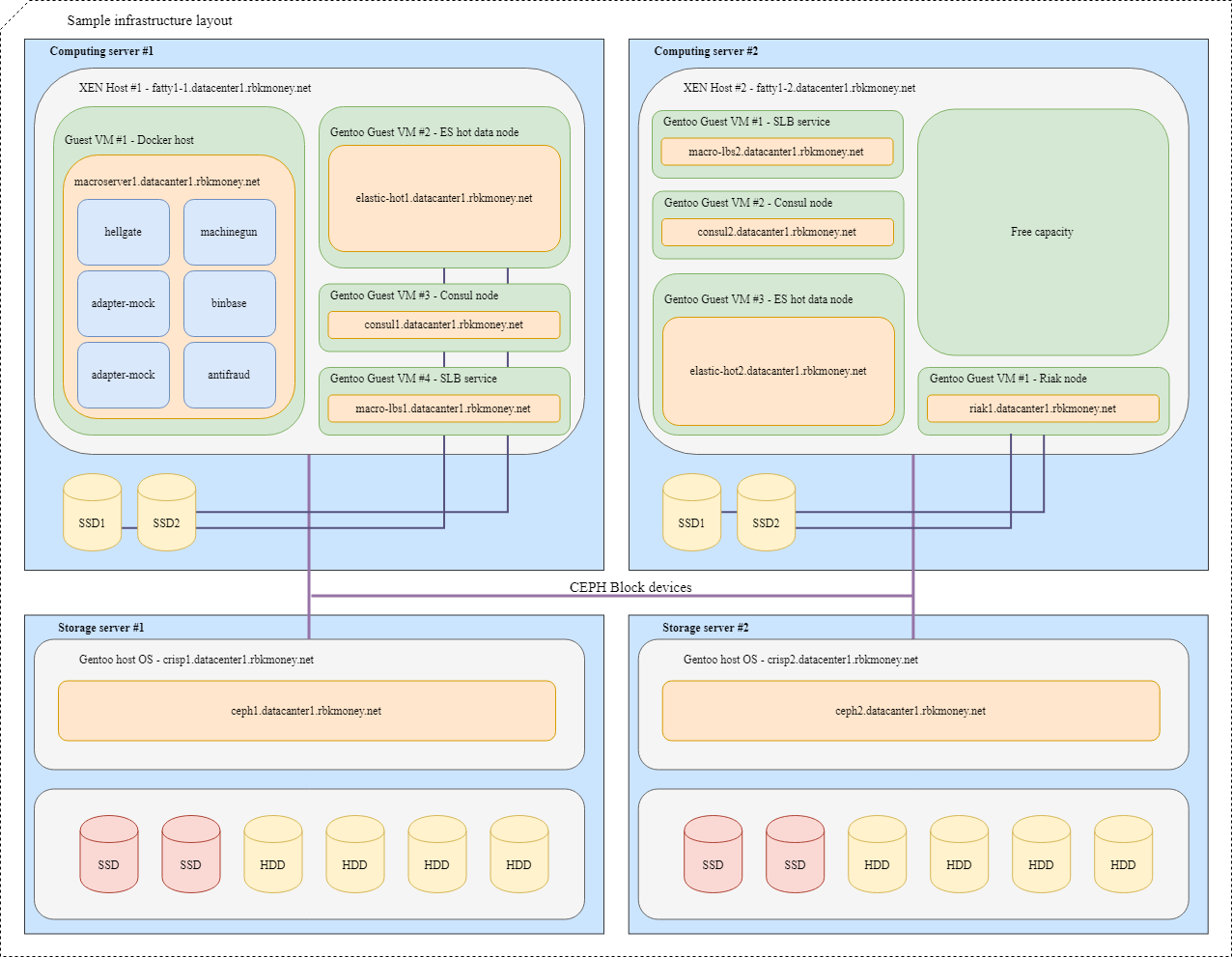
Para VMs com aplicativos que exigem velocidade máxima do dispositivo de bloco, como os nós quentes Riak e Elasticsearch, são usadas partições em discos NVMe locais. Essas VMs estão firmemente conectadas ao hypervisor e os próprios aplicativos são responsáveis pela disponibilidade e integridade de seus dados.
Para dispositivos de bloco comuns, usamos Ceph RBD, geralmente com dm-cache de gravação no disco local do NVMe. O OSD do dispositivo pode ser flash completo ou HDD com log SSD, dependendo do tempo de resposta desejado.
Entrega de tráfego para aplicativos
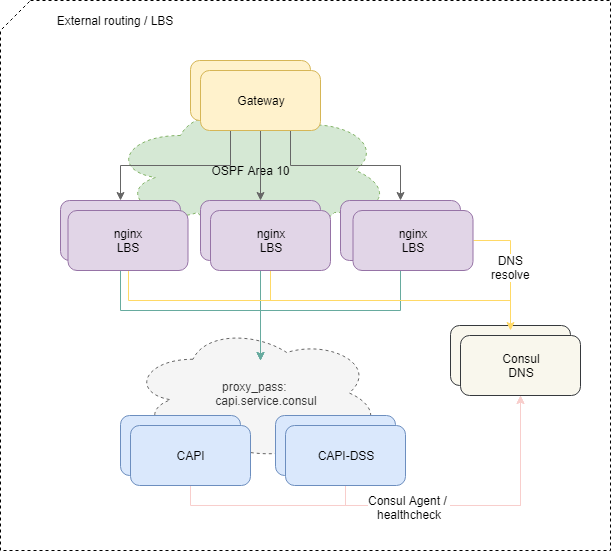
Para balancear solicitações vindas de fora, usamos o esquema OSPFv3 ECMP padrão. Pequenas máquinas virtuais com nginx, bird, consul anunciam na nuvem OSPF endereços anycast comuns a partir da interface lo. Nos roteadores, para esses endereços, o bird cria rotas multi-hop que fornecem balanceamento por fluxo, em que o fluxo é "src-ip src-porta dst-ip dst-porta". Para desativar rapidamente o balanceador ausente, o protocolo BFD é usado.
Quando qualquer um dos balanceadores é adicionado ou falha, os roteadores upstream obtêm a rota correspondente ou a excluem, e o tráfego de rede é entregue a eles de acordo com as abordagens de caminho múltiplo de custo igual. E se não intervirmos especificamente, todo o tráfego da rede será distribuído igualmente para todos os balanceadores disponíveis em cada fluxo IP.
A propósito, a abordagem com o balanceamento de ECMP tem armadilhas não óbvias, o que pode levar a perdas completamente não óbvias de algum tráfego, especialmente se outros roteadores ou firewalls estranhamente configurados estiverem na rota entre os sistemas.
Para resolver o problema, usamos o daemon PMTUD nesta parte da infraestrutura.
Além disso, o tráfego entra na plataforma para microsserviços específicos, de acordo com a configuração nginx nos balanceadores.
E se o equilíbrio do tráfego externo for mais ou menos simples e compreensível, seria difícil estender esse esquema ainda mais para dentro - precisamos mais do que apenas verificar a disponibilidade de um contêiner com um microsserviço no nível da rede.
Para que o microsserviço comece a receber e processar solicitações, ele deve se registrar no Service Discovery (usamos o Consul ), passar por verificações de integridade a cada segundo e ter um RTT razoável.
Se o microsserviço parecer e se comportar bem, a Consul começará a resolver o endereço do contêiner ao acessar o DNS pelo nome do serviço. Usamos a zona interna service.consul e, por exemplo, o microsserviço da API comum versão 2 será denominado capi-v2.service.consul .
A configuração do nginx referente ao balanceamento no final é assim:
location = /v2/ { set $service_hostname "${staging_pass}capi-v2.service.consul"; proxy_pass http://$service_hostname:8022; }
Portanto, se novamente não intervirmos de propósito, o tráfego dos balanceadores é distribuído igualmente entre todos os microsserviços registrados no Service Discovery, adicionando ou removendo novas instâncias dos microsserviços necessários é totalmente automatizado.
Se a solicitação do balanceador subiu a montante e ele morreu no caminho, retornamos 502 - o balanceador em seu nível não pode determinar se a solicitação foi idempotente ou não, portanto, atribuímos o processamento desses erros a um nível mais alto de lógica.
Idempotência e prazos
Em geral, não temos medo e não hesitamos em fornecer erros 5xx com a API. Essa é uma parte normal do sistema se você fizer o processamento correto desses erros no nível da lógica de negócios da RPC. Os princípios desse processamento são descritos em nosso formulário como um pequeno manual chamado Política de Nova Tentativa de Erros, os distribuímos aos nossos clientes comerciantes e os implementamos em nossos serviços.
Para simplificar esse processamento, implementamos várias abordagens.
Em primeiro lugar, para qualquer solicitação de alteração de estado para nossa API, você pode especificar uma chave de idempotência exclusiva na conta, que dura uma eternidade e permite que você tenha certeza de que uma chamada repetida com o mesmo conjunto de dados retornará a mesma resposta.
Em segundo lugar, implementamos um mecanismo adicional na forma de um identificador exclusivo para a sessão de pagamento, que garante a idempotência dos pedidos de fundos de débito, fornecendo proteção contra débitos repetidos incorretos, mesmo se você não gerar e transmitir uma chave de idempotência separada.
Em terceiro lugar, decidimos permitir um tempo de resposta previsível e controlado externamente a qualquer chamada externa para nossa API na forma de um parâmetro de corte de tempo que determina o tempo máximo de espera para que uma operação seja concluída mediante solicitação. É suficiente transferir, por exemplo, o cabeçalho HTTP X-Request-Deadline: 10s para garantir que sua solicitação seja executada em 10 segundos ou será eliminada pela plataforma em algum lugar interno, após o qual podemos ser contatados novamente, guiados por solicitar política de encaminhamento.
Usamos o SaltStack como uma ferramenta de gerenciamento para as configurações e a infraestrutura como um todo. Ferramentas separadas para o controle automatizado do poder de computação da plataforma ainda não decolaram, embora já entendamos que iremos nessa direção. Com o nosso amor pelos produtos Hashicorp, é provável que seja Nomad.
As principais ferramentas de monitoramento de infraestrutura são verificações em Nagios, mas para entidades comerciais, configuramos principalmente alertas no Grafana. Possui uma ferramenta muito conveniente para definir condições, e um modelo de plataforma baseado em eventos permite gravar tudo no Elasticsearch e configurar as condições de seleção.
Os data centers estão localizados em Moscou, onde alugamos espaços em rack, instalamos e gerenciamos independentemente todos os equipamentos. Não usamos óptica escura em nenhum lugar, apenas temos a Internet fora de fornecedores locais.
Caso contrário, nossas abordagens de monitoramento, gerenciamento e serviços relacionados são bastante padrão para o setor, não tenho certeza de que a próxima descrição da integração desses serviços seja mencionada em um post.
Neste artigo, provavelmente terminarei a série de postagens de revisão sobre como nossa plataforma de pagamento está organizada.
Penso que o ciclo acabou por ser bastante franco, encontrei poucos artigos que revelariam com tanto detalhe a cozinha interior de grandes sistemas de pagamento.
Em geral, na minha opinião, um alto nível de abertura e franqueza é uma coisa muito importante para o sistema de pagamentos. Essa abordagem não apenas aumenta o nível de confiança de parceiros e pagadores, mas também disciplina a equipe, os criadores e os operadores do serviço.
Portanto, guiados por esse princípio, disponibilizamos recentemente o status da plataforma e o histórico de tempo de atividade de nossos serviços. Todo o histórico subseqüente de nosso tempo de atividade, atualizações e falhas agora está público e disponível em https://status.rbk.money/ .
Espero que você tenha se interessado, e talvez alguém ache nossas abordagens e os erros descritos úteis. Se você estiver interessado em alguma das áreas descritas nas postagens e gostaria que eu as divulgasse com mais detalhes, não hesite em escrever nos comentários ou no PM.
Obrigado por estar conosco!

PS Para sua conveniência, um ponteiro para os artigos anteriores da série: