Como na
maioria das postagens , houve um problema com um serviço distribuído, vamos chamar esse serviço de Alvin. Dessa vez eu não encontrei o problema, informaram os caras da parte do cliente.
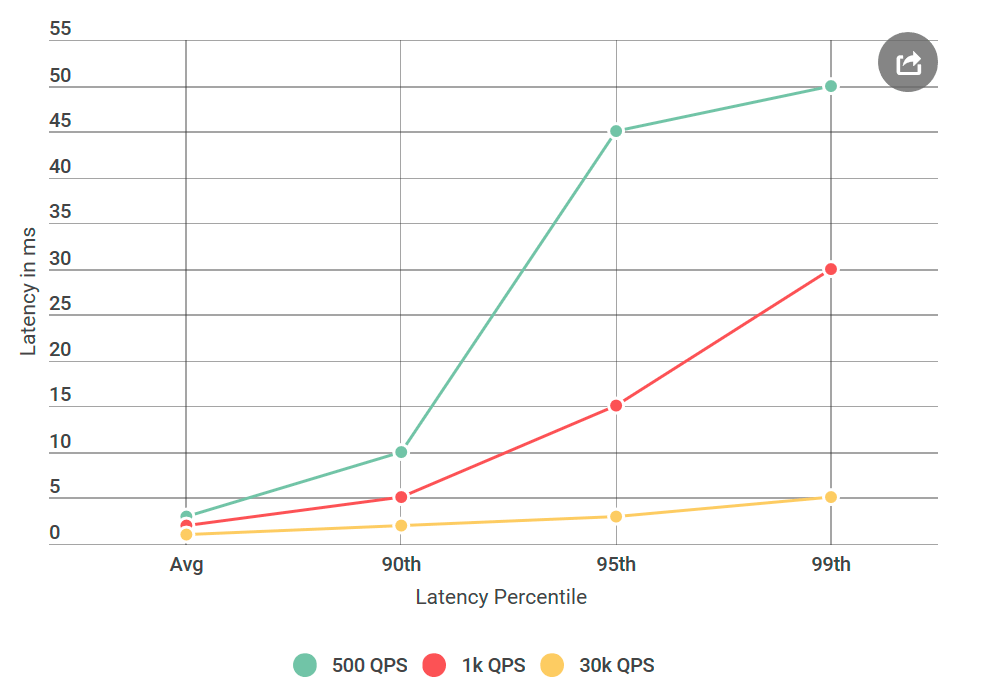
Certa vez, acordei de uma carta descontente devido aos grandes atrasos de Alvin, que planejávamos lançar em um futuro próximo. Em particular, o cliente encontrou um atraso do 99º percentil em torno de 50 ms, muito acima do nosso orçamento de atraso. Isso foi surpreendente, pois testei minuciosamente o serviço, principalmente por atrasos, porque esse é o assunto de queixas frequentes.
Antes de testar o Alvin, realizei muitas experiências com 40 mil solicitações por segundo (QPS), todas com atraso inferior a 10 ms. Eu estava pronto para declarar que não estava de acordo com os resultados deles. Mas, mais uma vez, olhando para a carta, chamei a atenção para algo novo: eu definitivamente não testei as condições que eles mencionaram, o QPS deles era muito menor que o meu. Eu testei em 40k QPS, e eles apenas em 1k. Fiz outro experimento, desta vez com QPS menor, apenas para agradá-los.
Desde que escrevi sobre isso no meu blog, você provavelmente já entendeu: os números deles estavam corretos. Testei meu cliente virtual repetidamente, tudo com o mesmo resultado: um número baixo de solicitações não apenas aumenta o atraso, mas também aumenta o número de solicitações com um atraso de mais de 10 ms. Em outras palavras, se no QPS de 40k, cerca de 50 solicitações por segundo excederam 50 ms, em 1k QPS a cada segundo, havia 100 solicitações acima de 50 ms. Paradoxo!
Limite a sua pesquisa
Diante do problema de atraso em um sistema distribuído com muitos componentes, a primeira coisa que você precisa fazer é fazer uma pequena lista de suspeitos. Nós nos aprofundamos um pouco mais na arquitetura de Alvin:
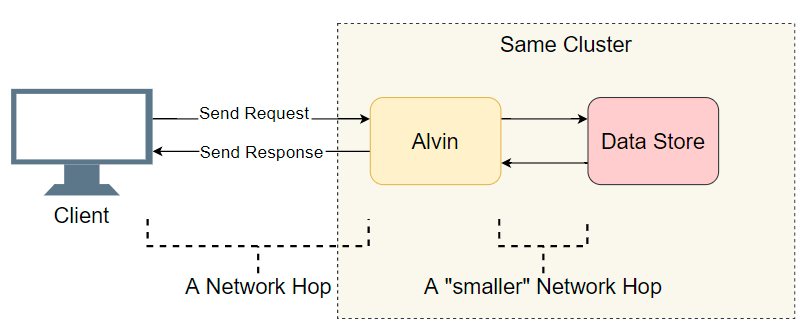
Um bom ponto de partida é uma lista de transições de E / S concluídas (chamadas de rede / pesquisas de disco, etc.). Vamos tentar descobrir onde está o atraso. Além da E / S óbvia com o cliente, Alvin dá um passo adicional: ele acessa o armazém de dados. No entanto, esse armazenamento funciona no mesmo cluster que o Alvin, portanto, deve haver menos atraso do que com o cliente. Então, a lista de suspeitos:
- Chamada de rede do cliente para Alvin.
- Chamada de rede da Alvin para o data warehouse.
- Pesquise no disco no armazém de dados.
- Chamada de rede do data warehouse para a Alvin.
- Chamada de rede da Alvin para o cliente.
Vamos tentar riscar alguns pontos.
Data Warehouse
A primeira coisa que fiz foi converter o Alvin em um servidor de ping que não lida com solicitações. Ao receber a solicitação, ele retorna uma resposta vazia. Se o atraso diminuir, um erro na implementação do Alvin ou no data warehouse não é algo inédito. No primeiro experimento, obtemos o seguinte gráfico:
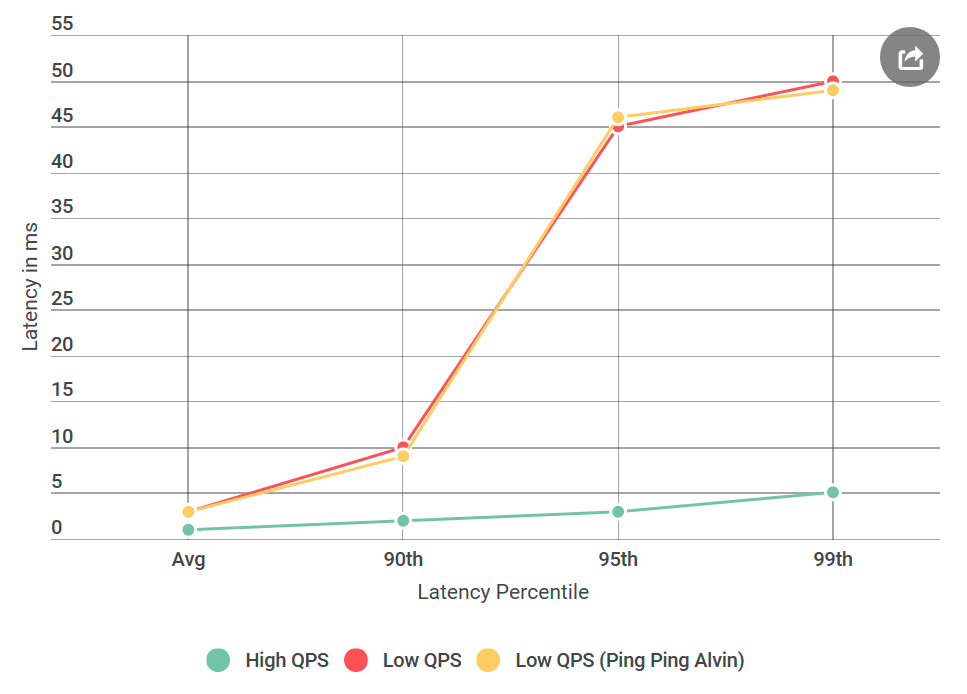
Como você pode ver, ao usar o servidor ping-ping, não há melhorias. Isso significa que o armazém de dados não aumenta o atraso e a lista de suspeitos é reduzida pela metade:
- Chamada de rede do cliente para Alvin.
- Chamada de rede da Alvin para o cliente.
Uau! A lista está diminuindo rapidamente. Eu pensei que quase descobri o motivo.
gRPC
Agora é a hora de apresentar um novo player:
gRPC . Esta é uma biblioteca de código aberto do Google para comunicações
RPC em processo. Embora o
gRPC bem otimizado e amplamente utilizado, a primeira vez que o usei em um sistema dessa escala, e esperava que minha implementação fosse abaixo do ideal - para dizer o mínimo.
A presença de
gRPC na pilha levantou uma nova pergunta: talvez essa seja minha implementação ou o próprio
gRPC cause um problema de atraso? Adicione à lista do novo suspeito:
- O cliente chama a biblioteca
gRPC
- A biblioteca
gRPC no cliente faz uma chamada de rede para a biblioteca gRPC no servidor
- Biblioteca
gRPC acessa Alvin (nenhuma operação no caso de servidor de ping-pong)
Para fazer você entender como é o código, minha implementação cliente / Alvin não é muito diferente dos
exemplos de cliente-servidor
assíncrono .
Nota: a lista acima é um pouco simplificada, pois o gRPC permite que você use seu próprio modelo de fluxo (modelo?), No qual a gRPC execução do gRPC e a implementação do usuário estão entrelaçadas. Por uma questão de simplicidade, mantemos esse modelo.
A criação de perfil corrigirá tudo
Atravessando os data warehouses, pensei que estava quase pronto: “Agora é fácil! Vamos aplicar o perfil e descobrir onde ocorre o atraso ". Sou um
grande fã de perfis precisos, porque as CPUs são muito rápidas e, na maioria das vezes, não representam um gargalo. A maioria dos atrasos ocorre quando o processador deve parar o processamento para fazer outra coisa. A criação de perfil preciso da CPU foi feita justamente para isso: registra com precisão todas as
alternâncias de contexto e deixa claro onde ocorrem atrasos.
Tomei quatro perfis: em QPS alto (baixa latência) e com um servidor de ping-pong em QPS baixo (alta latência), tanto no lado do cliente quanto no lado do servidor. E, por precaução, também peguei um perfil de processador de amostra. Ao comparar perfis, geralmente procuro uma pilha de chamadas anormal. Por exemplo, no lado ruim com um atraso alto, há muito mais opções de contexto (10 ou mais vezes). Mas no meu caso, o número de alternâncias de contexto quase coincidiu. Para meu horror, não havia nada significativo lá.
Depuração adicional
Eu estava desesperado. Eu não sabia que outras ferramentas poderiam ser usadas, e meu próximo plano era essencialmente repetir experimentos com diferentes variações, e não diagnosticar claramente o problema.
E se
Desde o início, fiquei preocupado com o tempo de atraso específico de 50 ms. Este é um momento muito grande. Decidi cortar as partes do código até descobrir exatamente qual parte estava causando esse erro. Em seguida, seguiu um experimento que funcionou.
Como sempre, pensando bem, tudo parece óbvio. Coloquei o cliente na mesma máquina com Alvin - e enviei a solicitação para o
localhost . E o aumento do atraso desapareceu!
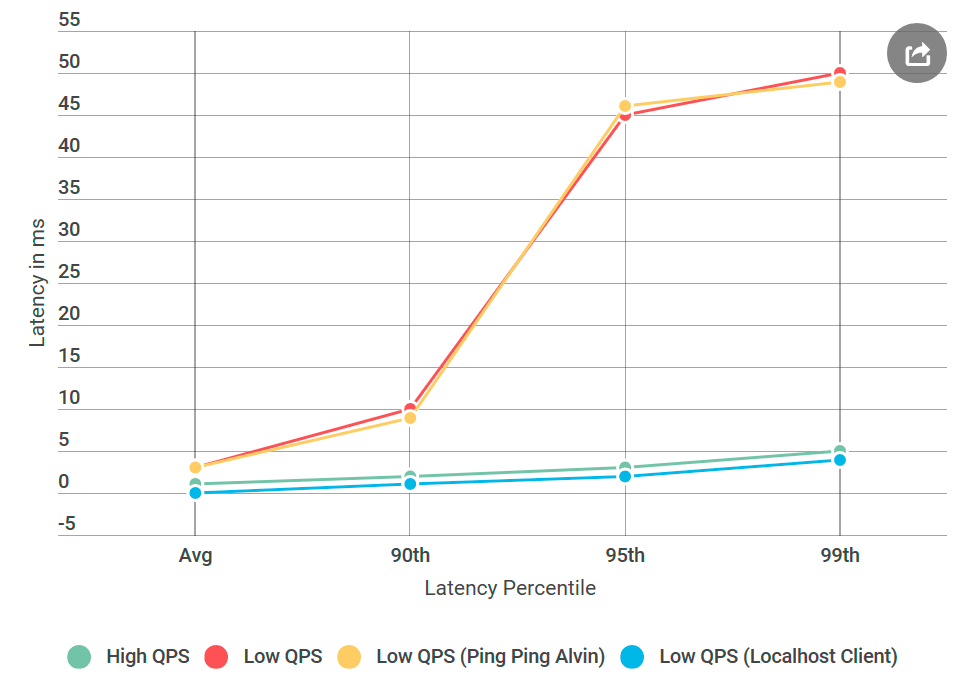
Algo estava errado com a rede.
Aprendendo as habilidades de um engenheiro de rede
Devo admitir: meu conhecimento de tecnologias de rede é terrível, principalmente considerando o fato de trabalhar diariamente com elas. Mas a rede era o principal suspeito e eu precisava aprender como depurá-la.
Felizmente, a Internet ama quem quer aprender. A combinação de ping e tracert parecia um começo suficientemente bom para depurar problemas de transporte de rede.
Primeiro, eu executei o
PsPing na porta TCP de
Alvin . Eu usei as opções padrão - nada de especial. Dos mais de mil pings, nenhum excedeu 10 ms, com exceção do primeiro para aquecimento. Isso contradiz o aumento observado no atraso de 50 ms no percentil 99: lá, para cada 100 solicitações, devemos ver cerca de uma solicitação com um atraso de 50 ms.
Então tentei
rastrear : talvez o problema esteja em um dos nós ao longo do caminho entre Alvin e o cliente. Mas o rastreador voltou de mãos vazias.
Portanto, o motivo do atraso não foi o meu código, nem a implementação do gRPC, nem a rede. Eu já comecei a me preocupar que nunca vou entender isso.
Agora em que SO estamos
gRPC amplamente usado no Linux, mas é exótico para Windows. Decidi realizar um experimento que funcionou: criei uma máquina virtual Linux, compilei o Alvin para Linux e implantei.
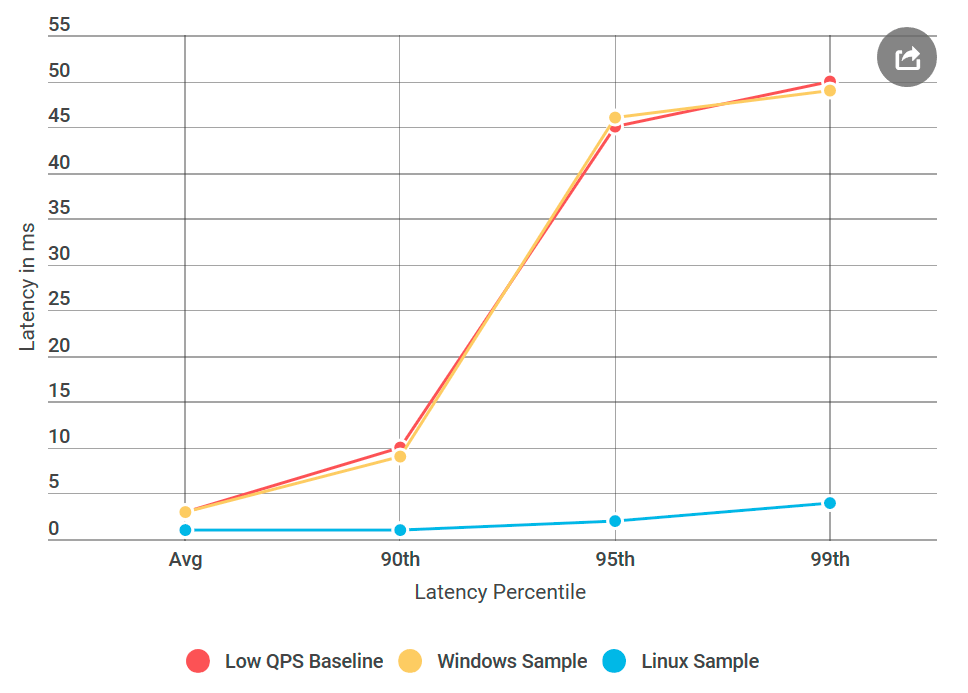
E aqui está o que aconteceu: o servidor Linux de pingue-pongue não teve atrasos como um nó semelhante do Windows, embora a fonte de dados não tenha diferido. Acontece que o problema está na implementação do gRPC para Windows.
Algoritmo Nagle
Todo esse tempo, pensei que estava faltando a flag
gRPC . Agora eu percebi que isso
gRPC não tem a bandeira do Windows no
gRPC . Encontrei a biblioteca RPC interna, na qual eu tinha certeza de que ela funciona bem para todos os sinalizadores
Winsock instalados. Em seguida, ele adicionou todos esses sinalizadores ao gRPC e implantou o Alvin no Windows, no servidor de ping-pong fixo do Windows!
 Quase
Quase pronto: comecei a excluir os sinalizadores adicionados um de cada vez até a regressão retornar, para que eu pudesse identificar sua causa. Era o infame
TCP_NODELAY , um comutador do algoritmo Nagle.
O algoritmo Neigl tenta reduzir o número de pacotes enviados pela rede atrasando a transmissão de mensagens até que o tamanho do pacote exceda um determinado número de bytes. Embora isso possa ser agradável para o usuário médio, é destrutivo para servidores em tempo real, pois o sistema operacional atrasará algumas mensagens, causando atrasos no QPS baixo.
gRPC tinha esse sinalizador definido na implementação do Linux para soquetes TCP, mas não para o Windows. Eu
consertei .
Conclusão
Um grande atraso no baixo QPS foi causado pela otimização do sistema operacional. Olhando para trás, a criação de perfil não detectou um atraso porque foi executada no modo kernel e não no
modo usuário . Não sei se é possível observar o algoritmo Nagle por meio de capturas ETW, mas isso seria interessante.
Quanto ao experimento localhost, provavelmente ele não tocou no código de rede real e o algoritmo Neigl não foi iniciado; portanto, os problemas de atraso desapareceram quando o cliente entrou em contato com a Alvin através do localhost.
Na próxima vez que você observar um aumento na latência enquanto diminui o número de solicitações por segundo, o algoritmo Neigl deve estar na sua lista de suspeitos!