
1. Introdução
Fiz esse relatório em inglês na conferência GopherCon Russia 2019 em Moscou e em russo na reunião em Nizhny Novgorod. É sobre um índice de bitmap - menos comum que a árvore B, mas não menos interessante. Compartilho a
gravação do discurso na conferência em inglês e a transcrição do texto em russo.
Examinaremos como o índice de bitmap funciona, quando é melhor, quando é pior que outros índices e, em quais casos, é muito mais rápido que eles; Veremos quais DBMSs populares já possuem índices de bitmap. tente escrever o seu próprio no Go. E para a sobremesa, usaremos bibliotecas prontas para criar nosso próprio banco de dados especializado super-rápido.
Eu realmente espero que meu trabalho seja útil e interessante para você. Vamos lá!
1. Introdução
http://bit.ly/bitmapindexeshttps://github.com/mkevac/gopherconrussia2019Olá pessoal! São seis da noite, estamos todos super cansados. É um bom momento para falar sobre a teoria chata dos índices de banco de dados, certo? Não se preocupe, terei algumas linhas de código fonte aqui e ali. :-)
Se não houver piadas, o relatório está cheio de informações e não temos muito tempo. Então, vamos começar.

Hoje vou falar sobre o seguinte:
- o que são índices;
- o que é um índice de bitmap;
- onde é usado e onde não é usado e por que;
- implementação simples no Go e um pouco de luta com o compilador;
- implementação um pouco menos simples, mas muito mais produtiva no Go-assembler;
- "Problemas" de índices de bitmap;
- implementações existentes.
Então, o que são índices?
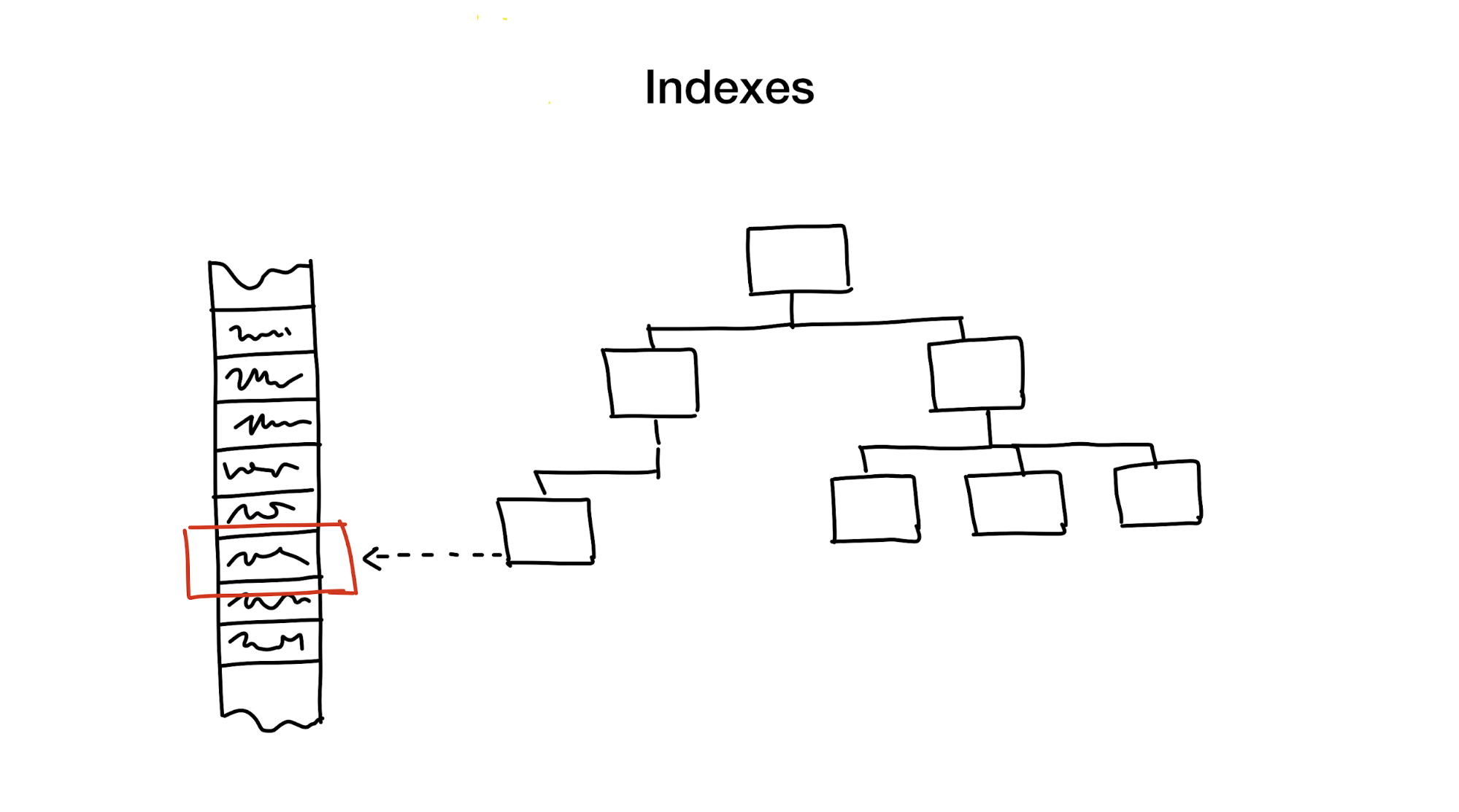
Um índice é uma estrutura de dados separada que mantemos e atualizamos, além dos dados principais. É usado para acelerar a pesquisa. Sem índices, uma pesquisa exigiria uma passagem completa dos dados (um processo chamado verificação completa), e esse processo tem complexidade algorítmica linear. Mas os bancos de dados geralmente contêm uma quantidade enorme de dados e a complexidade linear é muito lenta. Idealmente, teríamos uma logarítmica ou constante.
Esse é um tópico enorme e complexo, sobrecarregado de sutilezas e compromissos, mas, depois de analisar décadas de desenvolvimento e pesquisa de vários bancos de dados, estou pronto para argumentar que existem apenas algumas abordagens amplamente usadas para criar índices de banco de dados.

A primeira abordagem é reduzir hierarquicamente a área de pesquisa, dividindo-a em partes menores.
Geralmente fazemos isso usando todos os tipos de árvores. Um exemplo é uma caixa grande com materiais em seu armário, na qual existem caixas menores com materiais divididos por vários tópicos. Se você precisar de materiais, provavelmente os procurará em uma caixa com as palavras "Materiais", e não na que diz "Cookies", certo?
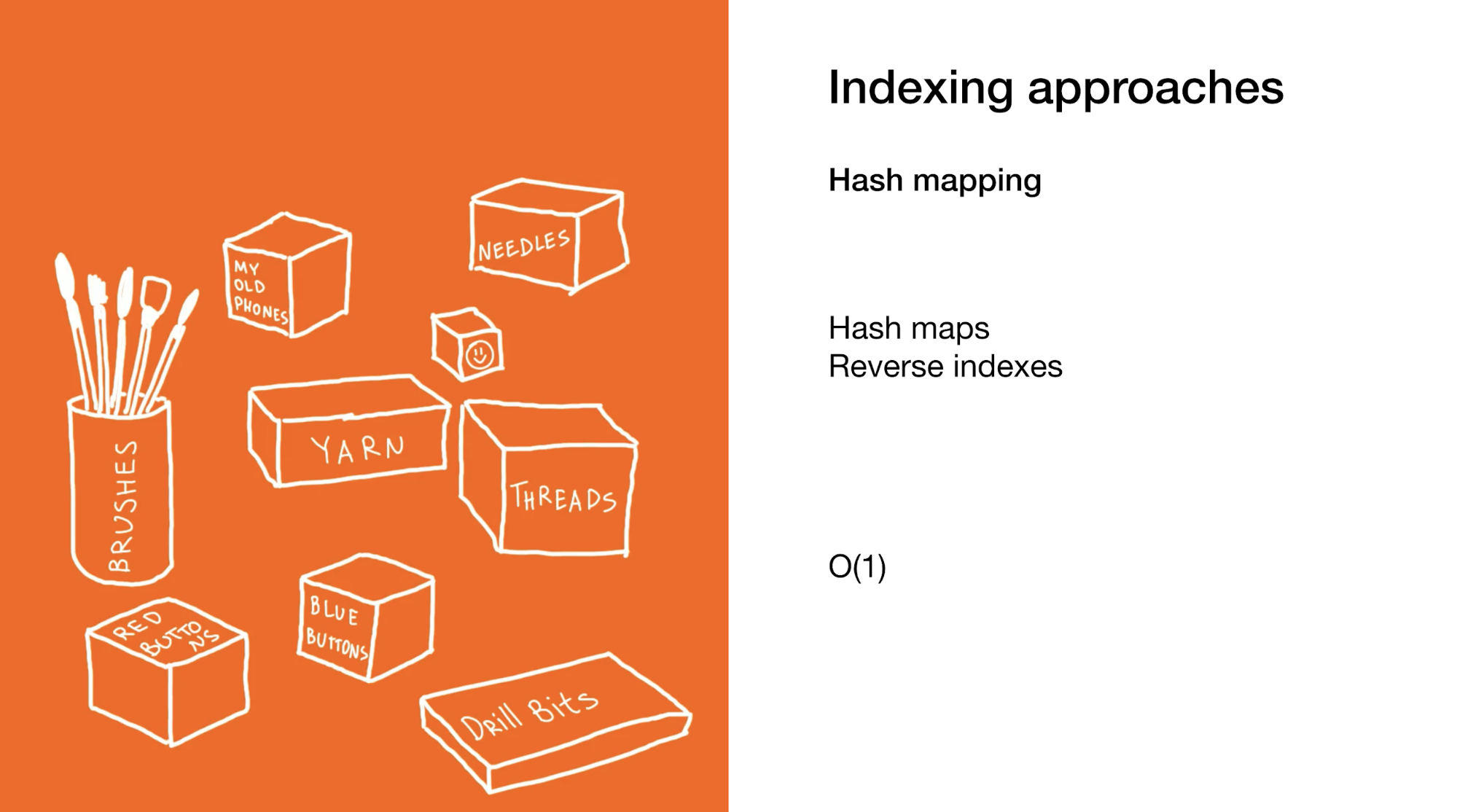
A segunda abordagem é selecionar imediatamente o elemento ou grupo de elementos desejado. Fazemos isso em mapas de hash ou em índices reversos. O uso de mapas de hash é muito semelhante ao exemplo anterior, mas em vez de uma caixa com caixas no seu armário, há muitas caixas pequenas com itens finais.

A terceira abordagem é livrar-se da necessidade de uma pesquisa. Fazemos isso usando filtros Bloom ou filtros de cuco. O primeiro fornece uma resposta instantaneamente, eliminando a necessidade de pesquisar.
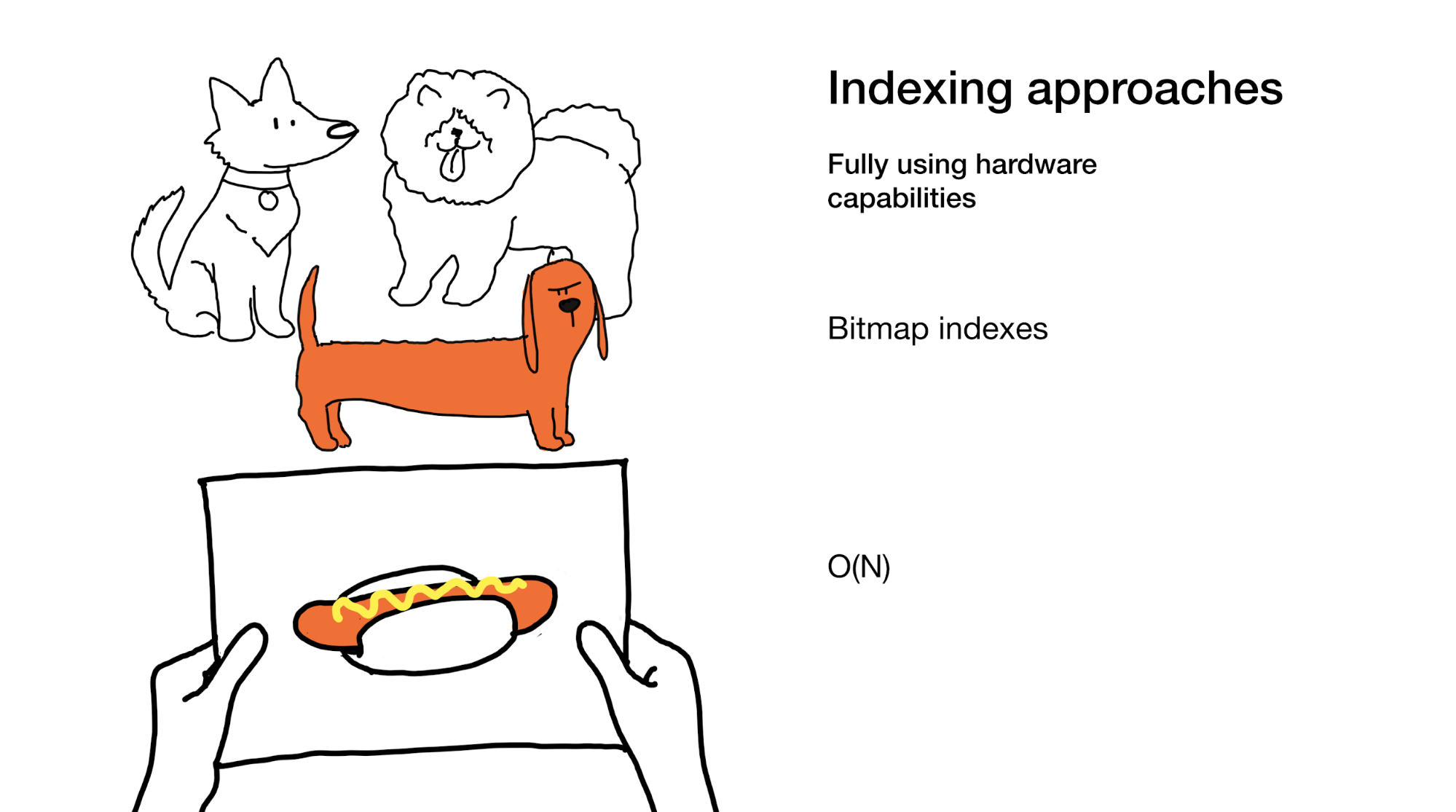
A última abordagem é utilizar totalmente todas as capacidades que o ferro moderno nos oferece. É exatamente isso que fazemos nos índices de bitmap. Sim, ao usá-los, às vezes precisamos percorrer todo o índice, mas fazemos isso de maneira super eficiente.
Como eu disse, o tópico de índices de banco de dados é vasto e transborda de compromissos. Isso significa que, às vezes, podemos usar várias abordagens ao mesmo tempo: se precisamos acelerar ainda mais a pesquisa ou se é necessário cobrir todos os tipos possíveis de pesquisa.
Hoje vou falar sobre a abordagem menos conhecida dentre elas - sobre índices de bitmap.
Quem sou eu para falar sobre isso?
Eu trabalho como líder de equipe no Badoo (talvez você conheça melhor nosso outro produto, o Bumble). Já temos mais de 400 milhões de usuários em todo o mundo e muitos recursos que estão envolvidos na seleção do melhor par para eles. Fazemos isso usando serviços personalizados que usam índices de bitmap também.
Então, o que é um índice de bitmap?
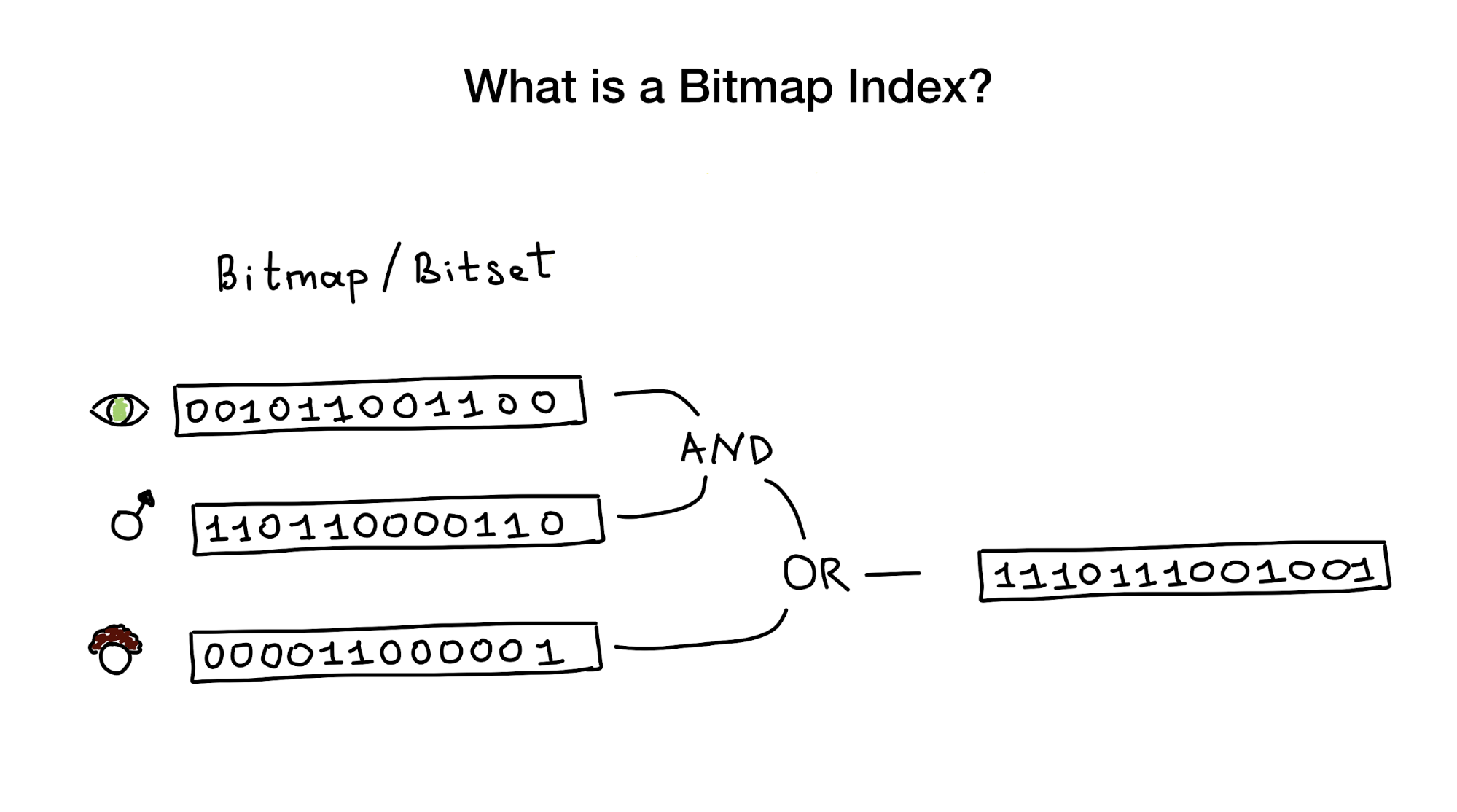
Os índices de bitmap, como o nome indica, usam bitmaps ou bitsets para implementar um índice de pesquisa. Do ponto de vista de um pássaro, esse índice consiste em um ou mais mapas de bits representando quaisquer entidades (como pessoas) e suas propriedades ou parâmetros (idade, cor dos olhos etc.) e em um algoritmo que usa operações de bits (AND, OU, NÃO) para responder a uma consulta de pesquisa.

Dizem-nos que os índices de bitmap são mais adequados e muito produtivos para casos em que há uma pesquisa que combina consultas em várias colunas com pouca cardinalidade (imagine "cor dos olhos" ou "estado civil" versus algo como "distância do centro da cidade" ) Mas depois mostrarei que elas funcionam perfeitamente no caso de colunas com alta cardinalidade.
Considere o exemplo mais simples de um índice de bitmap.

Imagine que temos uma lista de restaurantes em Moscou com propriedades binárias como estas:
- perto do metrô (perto do metrô);
- existe um estacionamento privado (tem estacionamento privado);
- há uma varanda (com terraço);
- Você pode reservar uma mesa (aceita reservas);
- adequado para vegetarianos (veganos);
- caro (caro).
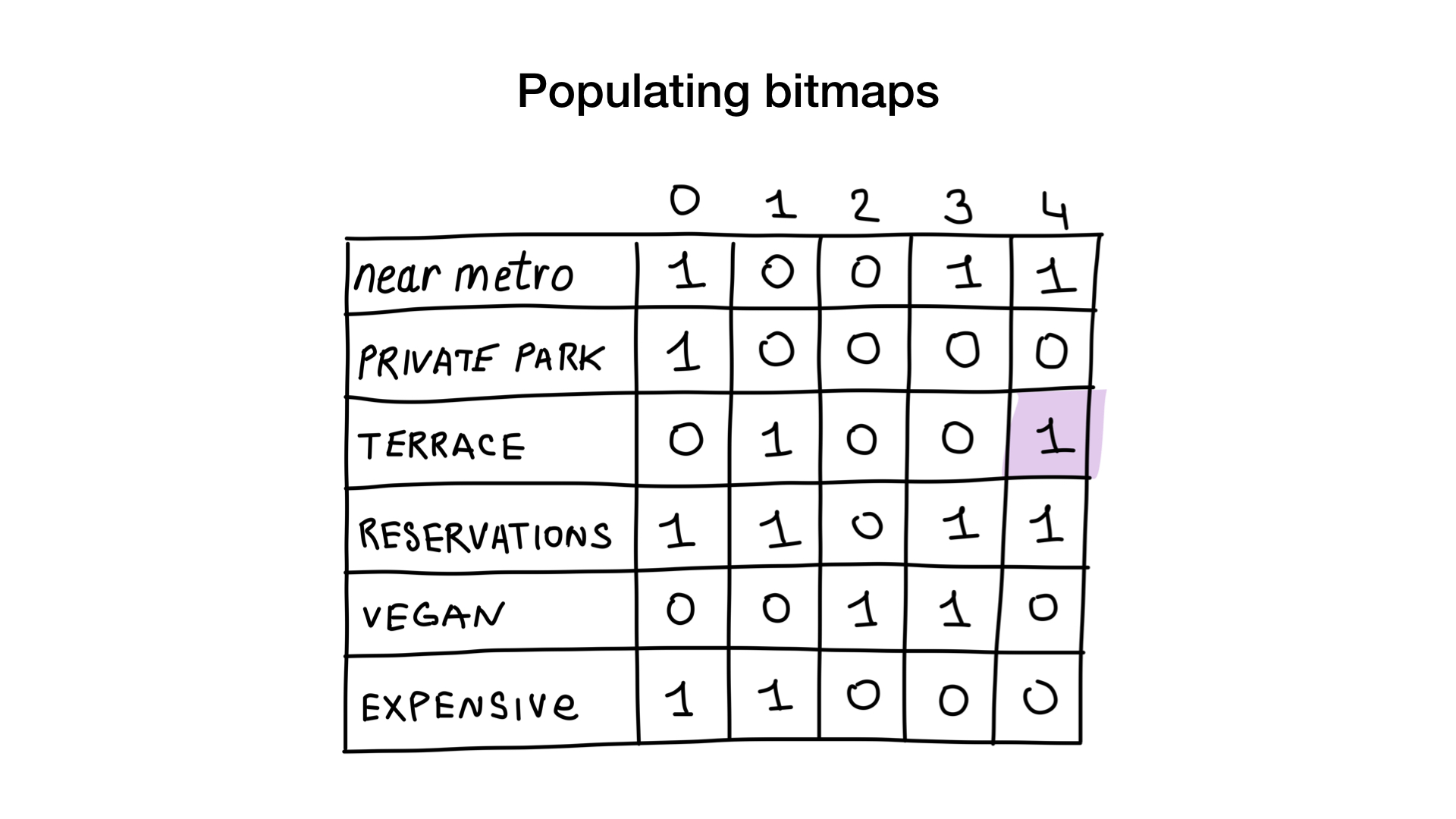
Vamos dar a cada restaurante um número de série começando em 0 e alocar memória para 6 bitmaps (um para cada característica). Em seguida, preenchemos esses bitmaps, dependendo se o restaurante tem essa propriedade ou não. Se o restaurante 4 tiver uma varanda, o bit No. 4 no bitmap “existe uma varanda” será definido como 1 (se não houver varanda, então como 0).

Agora, temos o índice de bitmap mais simples possível e podemos usá-lo para responder a perguntas como:
- “Mostre-me restaurantes adequados para vegetarianos”;
- "Mostre-me restaurantes baratos com uma varanda onde você pode reservar uma mesa."
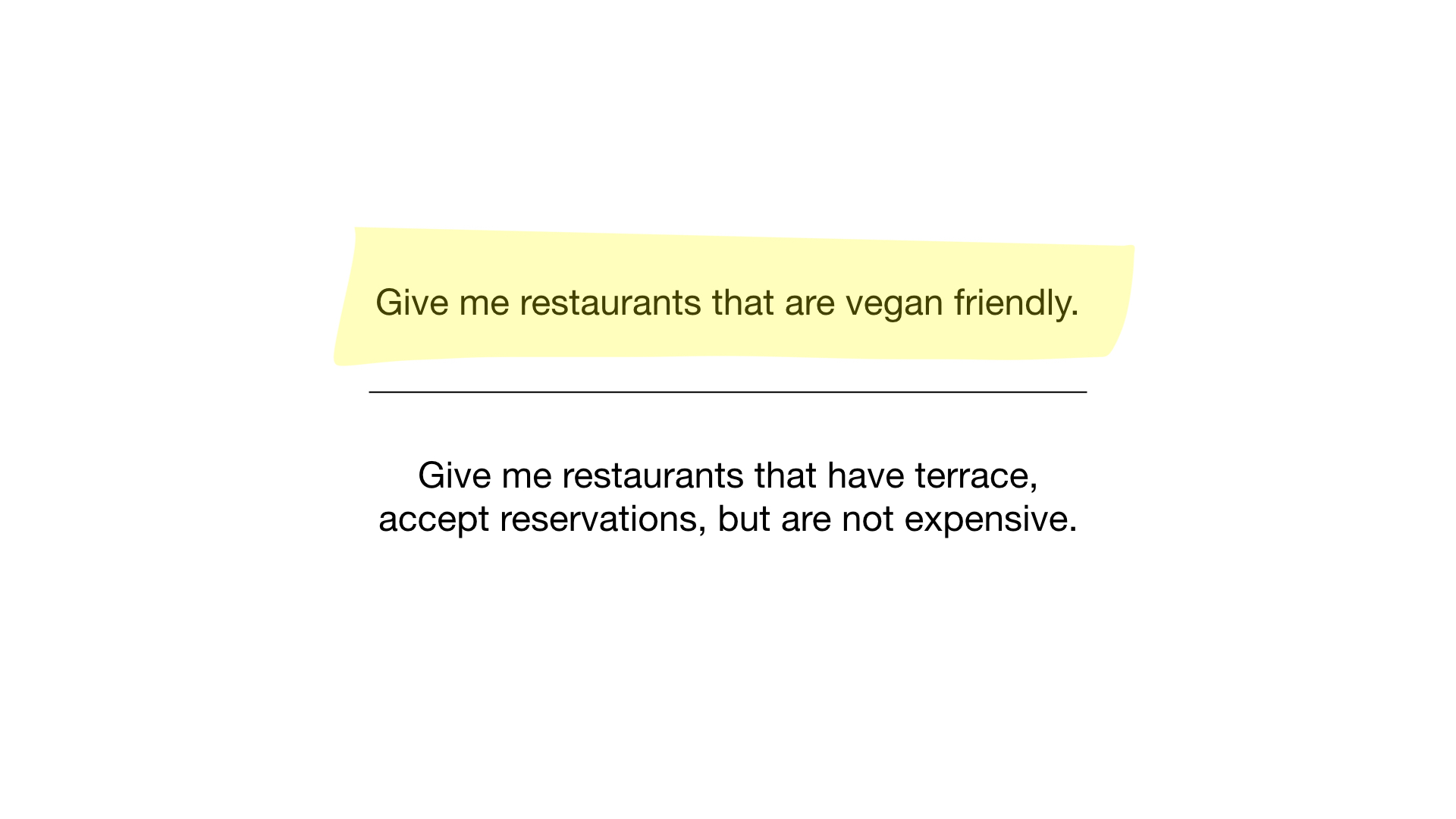
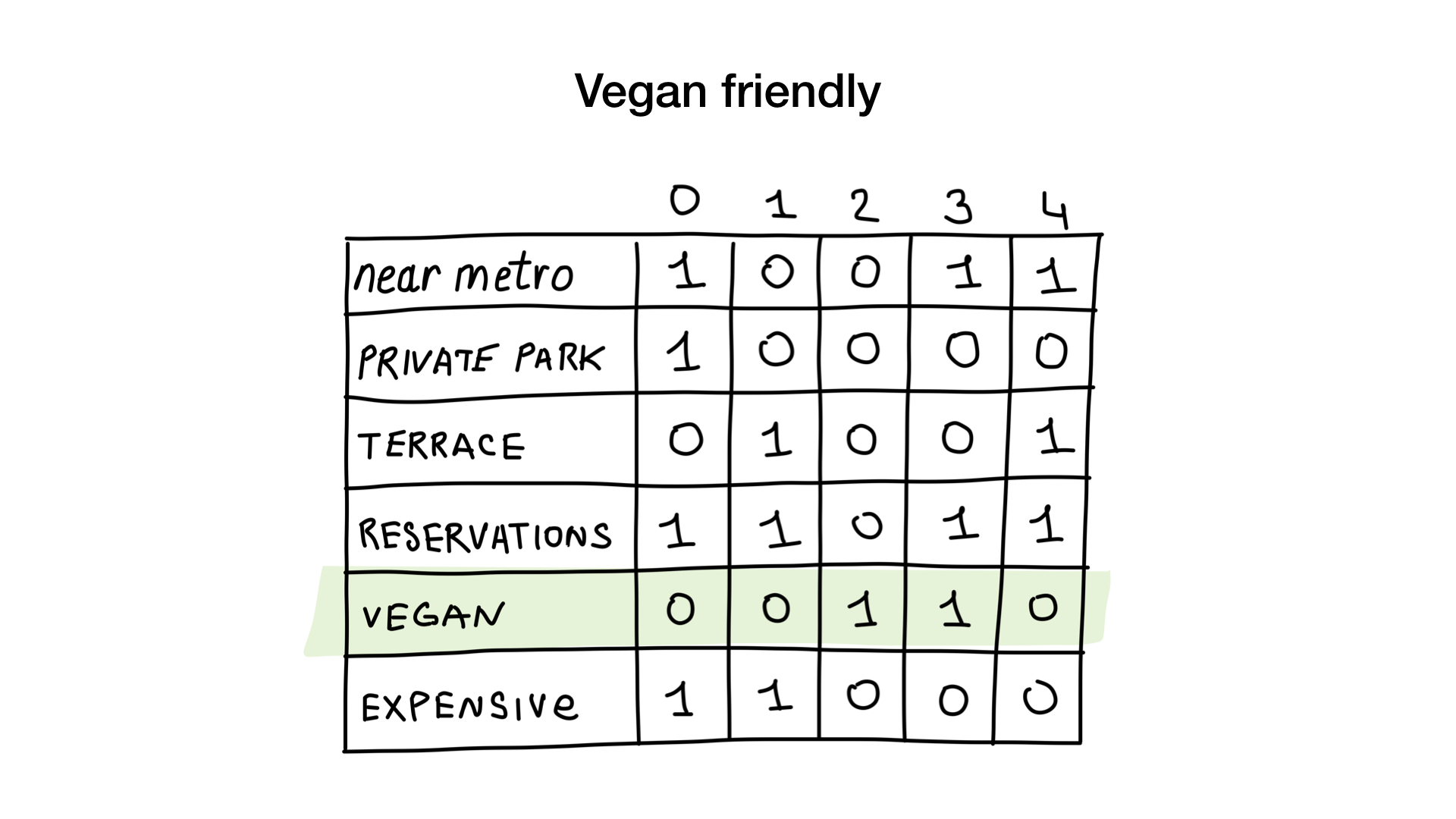
Como Vamos ver O primeiro pedido é muito simples. Tudo o que precisamos fazer é pegar o bitmap "adequado para vegetarianos" e transformá-lo em uma lista de restaurantes cujos bits estão em exibição.
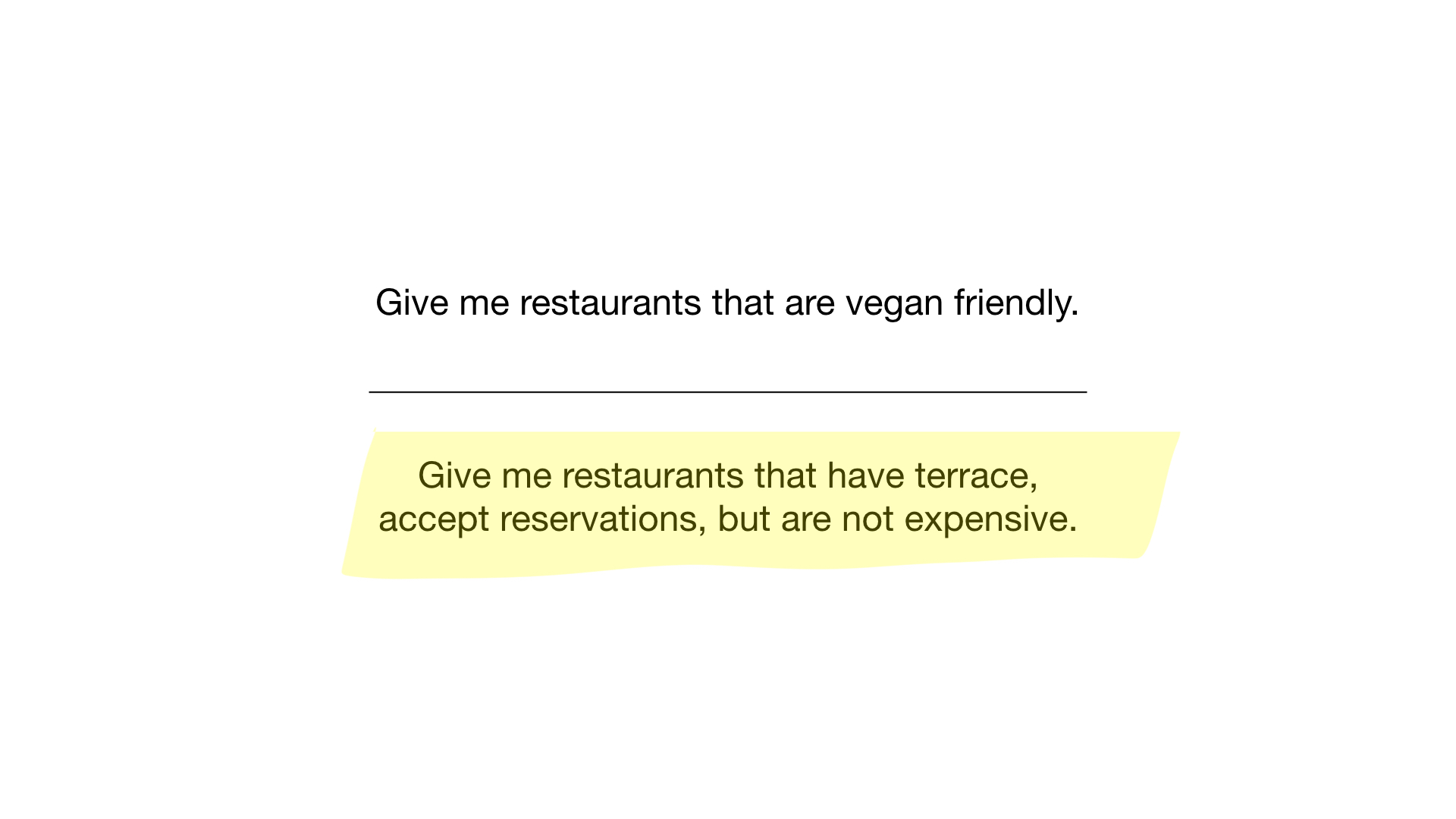

A segunda consulta é um pouco mais complicada. Precisamos usar a operação de bit NOT no bitmap "caro" para obter uma lista de restaurantes baratos, depois defini-la com o bitmap "você pode reservar uma tabela" e definir o resultado com o bitmap "há uma varanda". O bitmap resultante conterá uma lista de estabelecimentos que atendem a todos os nossos critérios. Neste exemplo, este é apenas o restaurante Yunost.
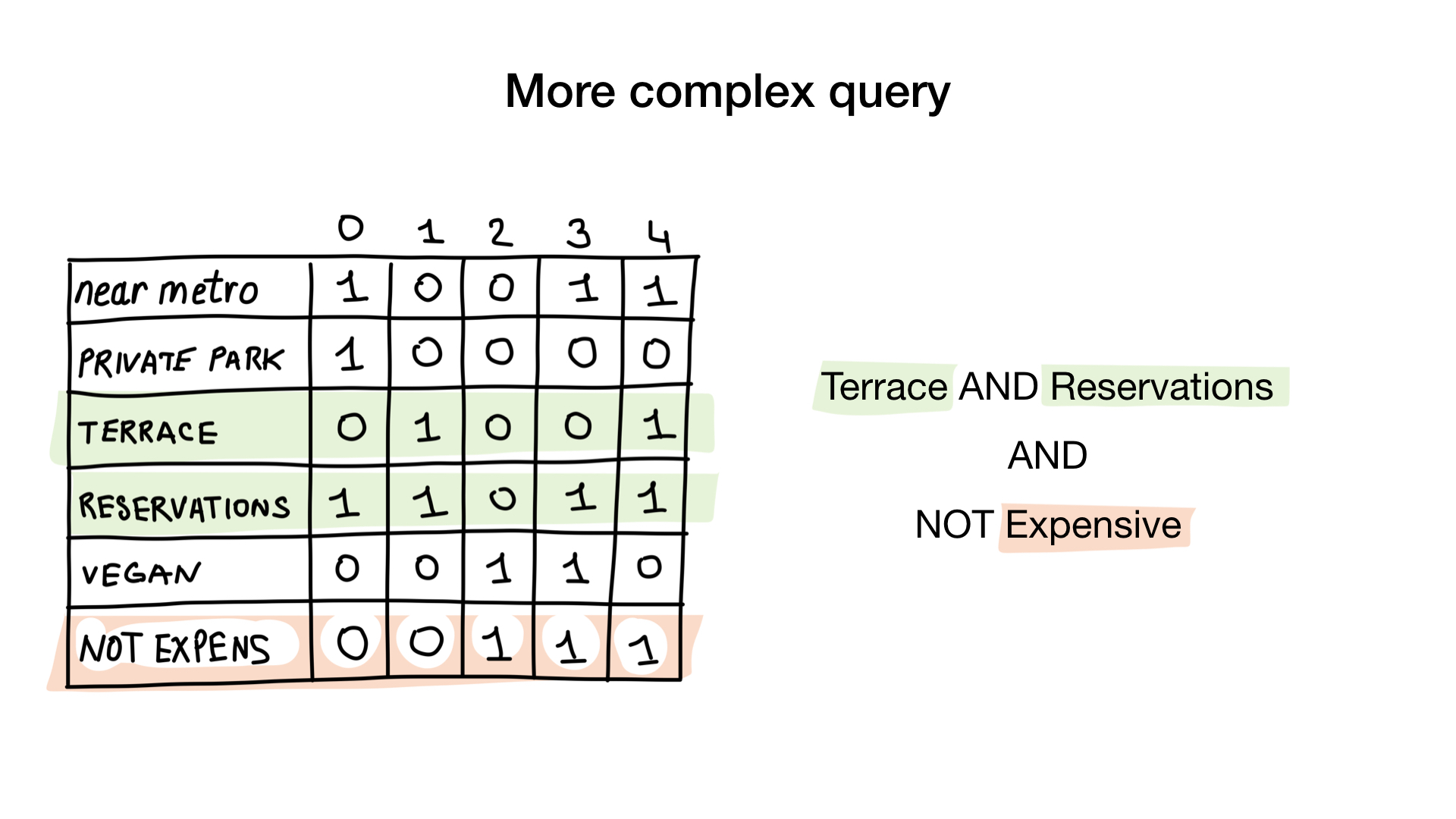
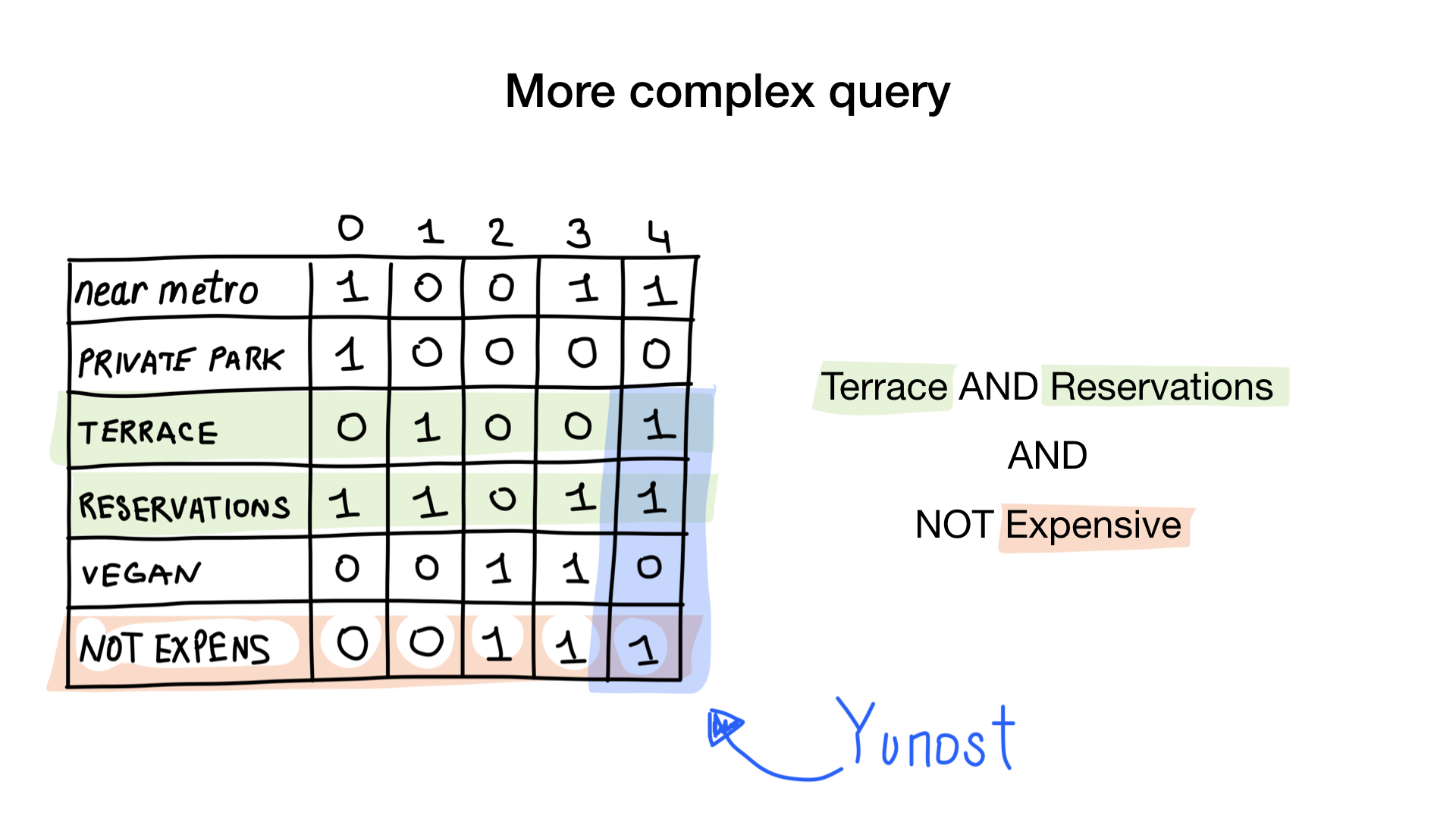
Há muita teoria, mas não se preocupe, veremos o código muito em breve.
Onde os índices de bitmap são usados?

Se você "indexar" os índices de bitmap, 90% das respostas estarão relacionadas ao Oracle DB. Mas o resto do DBMS também provavelmente suporta uma coisa tão legal, certo? Na verdade não.
Vamos examinar a lista dos principais suspeitos.

O MySQL ainda não suporta índices de bitmap, mas existe Proposta com uma proposta para adicionar esta opção (
https://dev.mysql.com/worklog/task/?id=1524 ).
O PostgreSQL não suporta índices de bitmap, mas usa bitmaps simples e operações de bit para combinar resultados de pesquisa em vários outros índices.
O Tarantool possui índices de bits, suporta uma pesquisa simples sobre eles.
O Redis possui campos de bits simples
(https://redis.io/commands/bitfield ) sem a capacidade de pesquisar por eles.
O MongoDB ainda não suporta índices de bitmap, mas também existe uma proposta com uma proposta para adicionar esta opção
https://jira.mongodb.org/browse/SERVER-1723O Elasticsearch usa bitmaps dentro
(https://www.elastic.co/blog/frame-of-reference-and-roaring-bitmaps ).

- Mas um novo vizinho apareceu em nossa casa: Pilosa. Este é um novo banco de dados não relacional escrito em Go. Ele contém apenas índices de bitmap e baseia tudo neles. Falaremos sobre ela um pouco mais tarde.
Implementação Go
Mas por que os índices de bitmap são tão raramente usados? Antes de responder a essa pergunta, gostaria de demonstrar a você a implementação de um índice de bitmap muito simples no Go.

Os bitmaps são essencialmente apenas pedaços de dados. No Go, vamos usar fatias de bytes para isso.
Temos um bitmap por característica de restaurante e cada bit no bitmap indica se um restaurante específico tem essa propriedade ou não.

Vamos precisar de duas funções auxiliares. Um será usado para preencher nossos bitmaps com dados aleatórios. Aleatório, mas com uma certa probabilidade de que o restaurante tenha todas as propriedades. Por exemplo, acredito que existem muito poucos restaurantes em Moscou onde você não pode reservar uma mesa, e me parece que aproximadamente 20% dos estabelecimentos são adequados para vegetarianos.
A segunda função converterá o bitmap em uma lista de restaurantes.


Para responder à solicitação "Mostre-me restaurantes baratos, com varanda e onde você pode reservar uma mesa", precisamos de operações de dois bits: NOT e AND.
Podemos simplificar um pouco nosso código usando a operação AND NOT mais complexa.
Temos funções para cada uma dessas operações. Ambos passam pelas fatias, pegam os elementos correspondentes de cada uma, combinam-nos com uma operação de bit e colocam o resultado na fatia resultante.
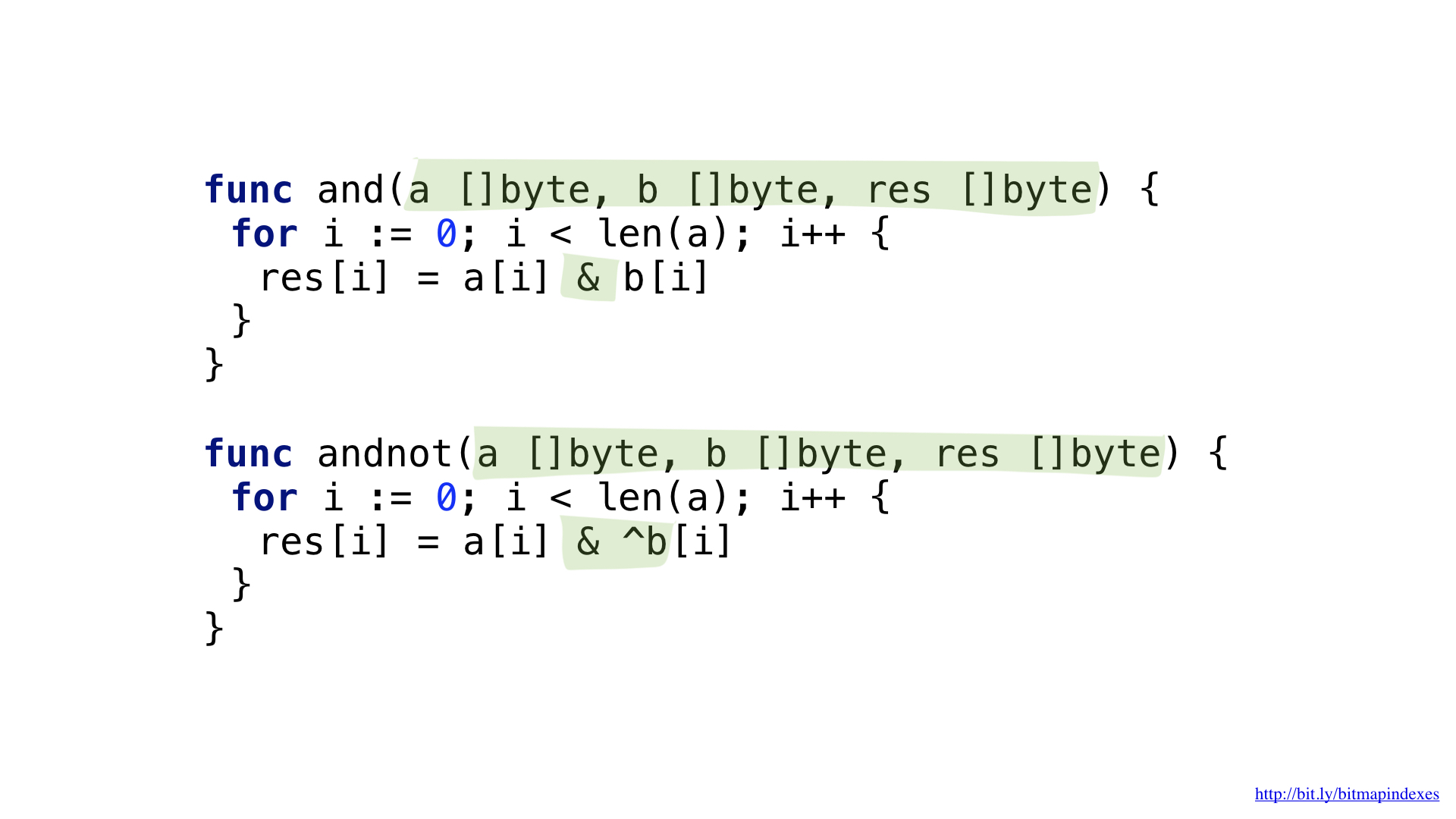
E agora podemos usar nossos bitmaps e funções para responder a uma consulta de pesquisa.

O desempenho não é tão alto, mesmo que as funções sejam muito simples e economizamos decentemente que não retornamos uma nova fatia resultante toda vez que a função foi chamada.
Tendo traçado um perfil um pouco com o pprof, notei que o compilador Go perdeu uma otimização muito simples, mas muito importante: a função embutida.
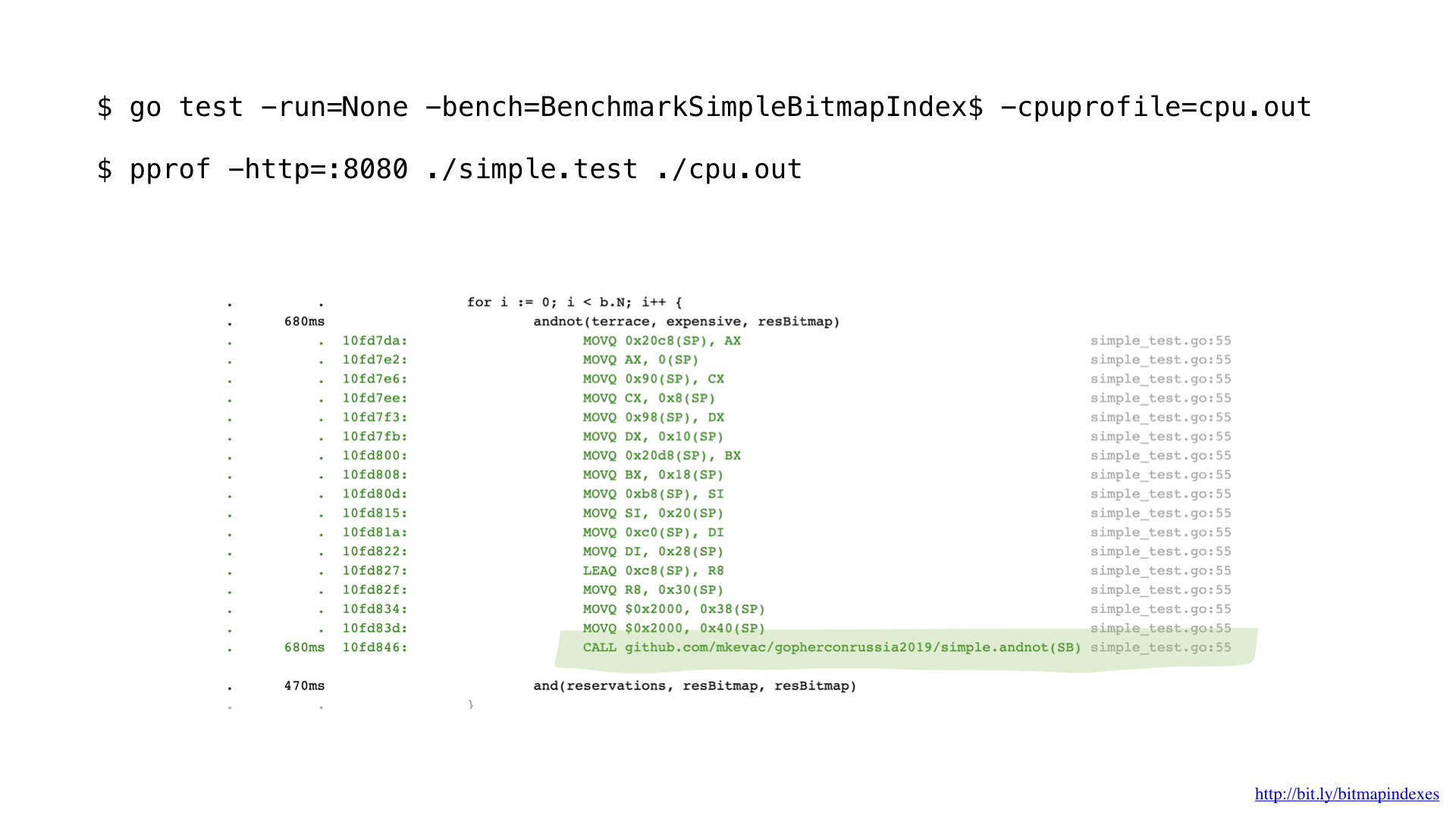
O fato é que o compilador Go tem muito medo de loops que passam por fatias e se recusa categoricamente a funções embutidas que contêm loops.
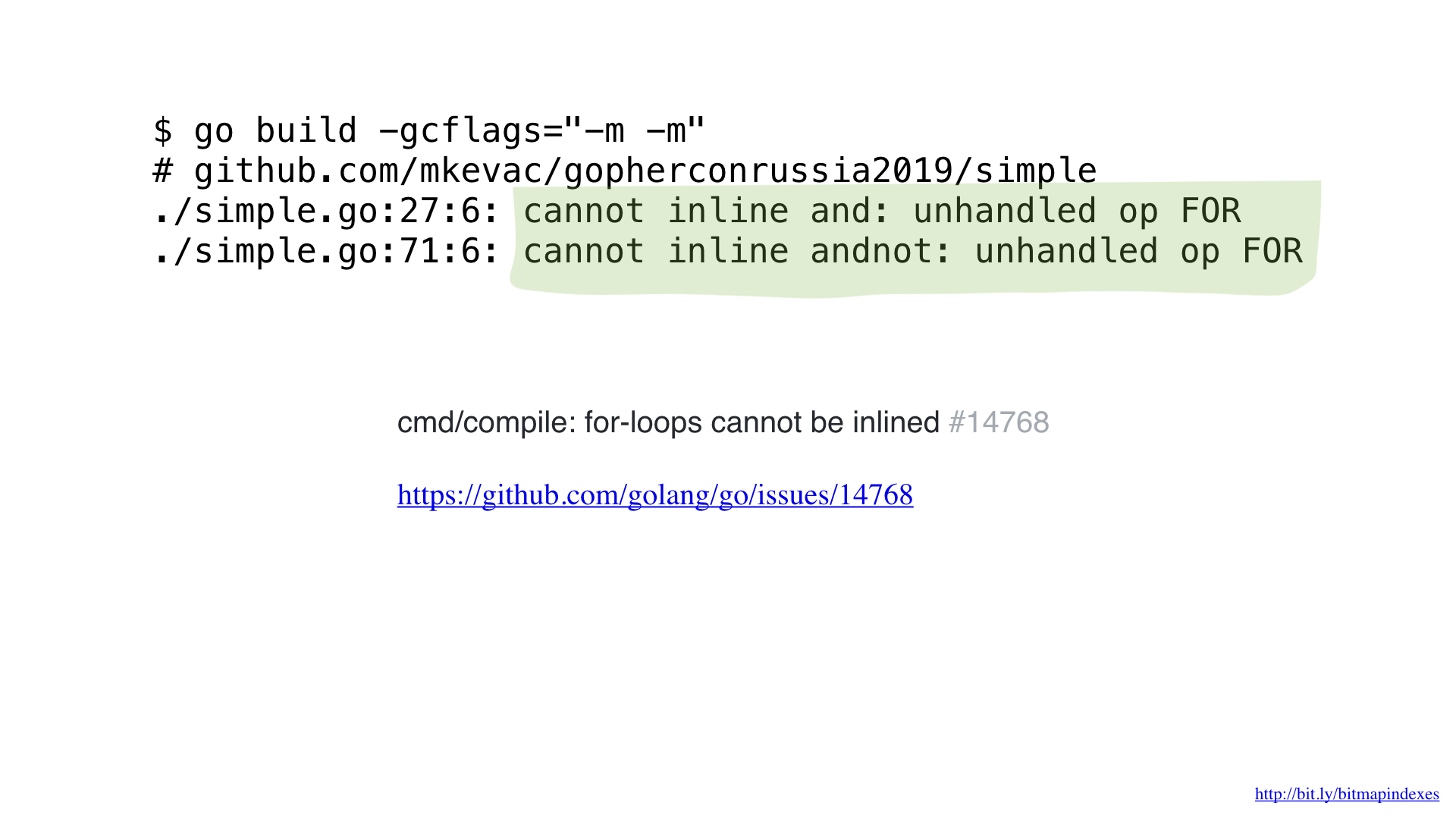
Mas não tenho medo e posso enganar o compilador usando goto em vez de um loop, como nos bons velhos tempos.


E, como você pode ver, agora o compilador descreve alegremente nossa função! Como resultado, conseguimos economizar cerca de 2 microssegundos. Nada mal!

O segundo gargalo é fácil de ver se você observa cuidadosamente a saída do montador. O compilador adicionou uma verificação de limite de fatias dentro do nosso loop mais quente. O fato é que Go é uma linguagem segura, o compilador tem medo de que meus três argumentos (três fatias) tenham tamanhos diferentes. Afinal, haverá uma possibilidade teórica do aparecimento do chamado estouro de buffer.
Vamos tranquilizar o compilador, mostrando a ele que todas as fatias são do mesmo tamanho. Podemos fazer isso adicionando uma verificação simples no início de nossa função.
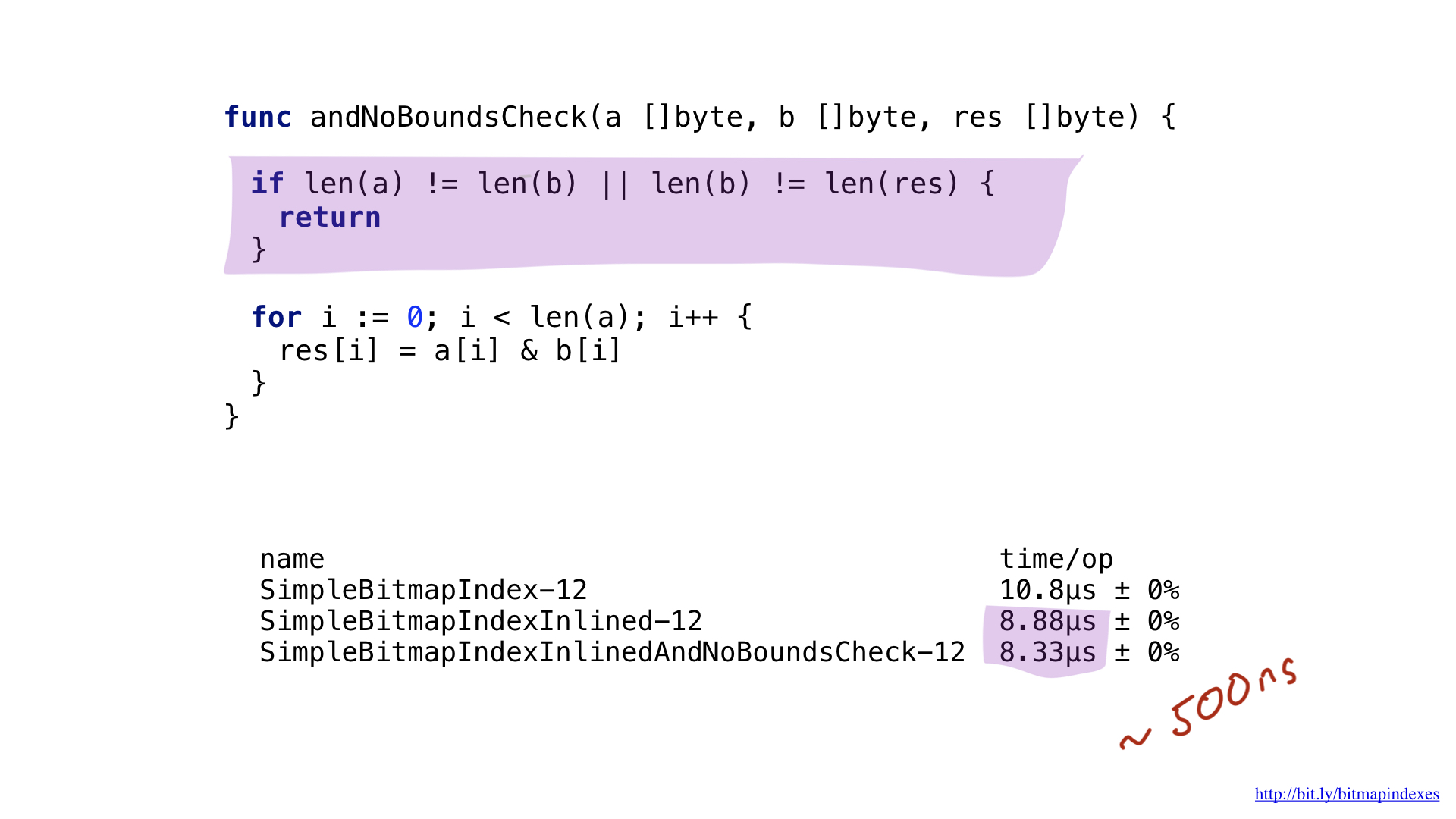
Vendo isso, o compilador pula felizmente o teste e acabamos economizando outros 500 nanossegundos.
Grandes lotes
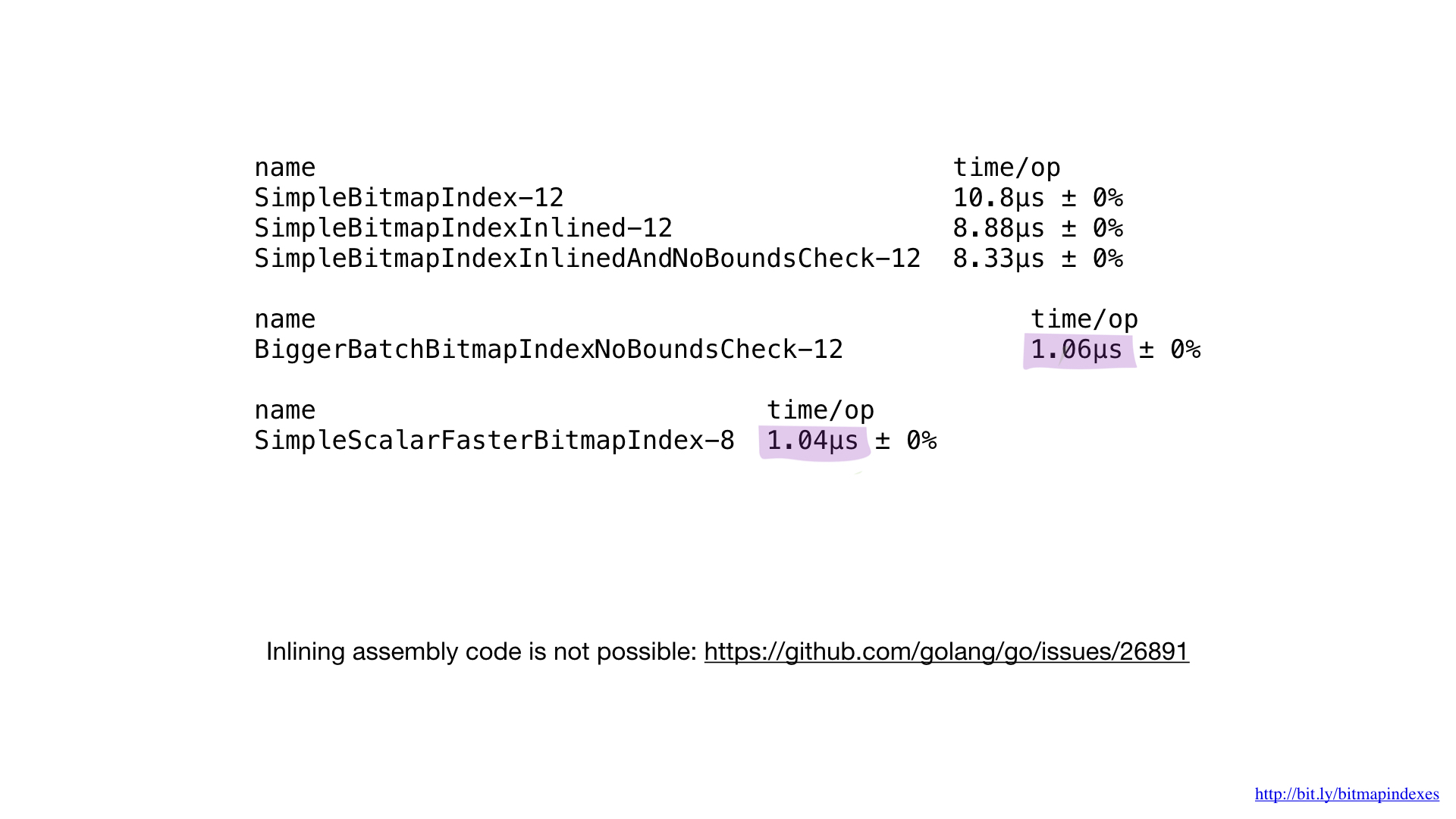
Ok, conseguimos extrair algum desempenho de nossa implementação simples, mas esse resultado, de fato, é muito pior do que é possível com o hardware atual.
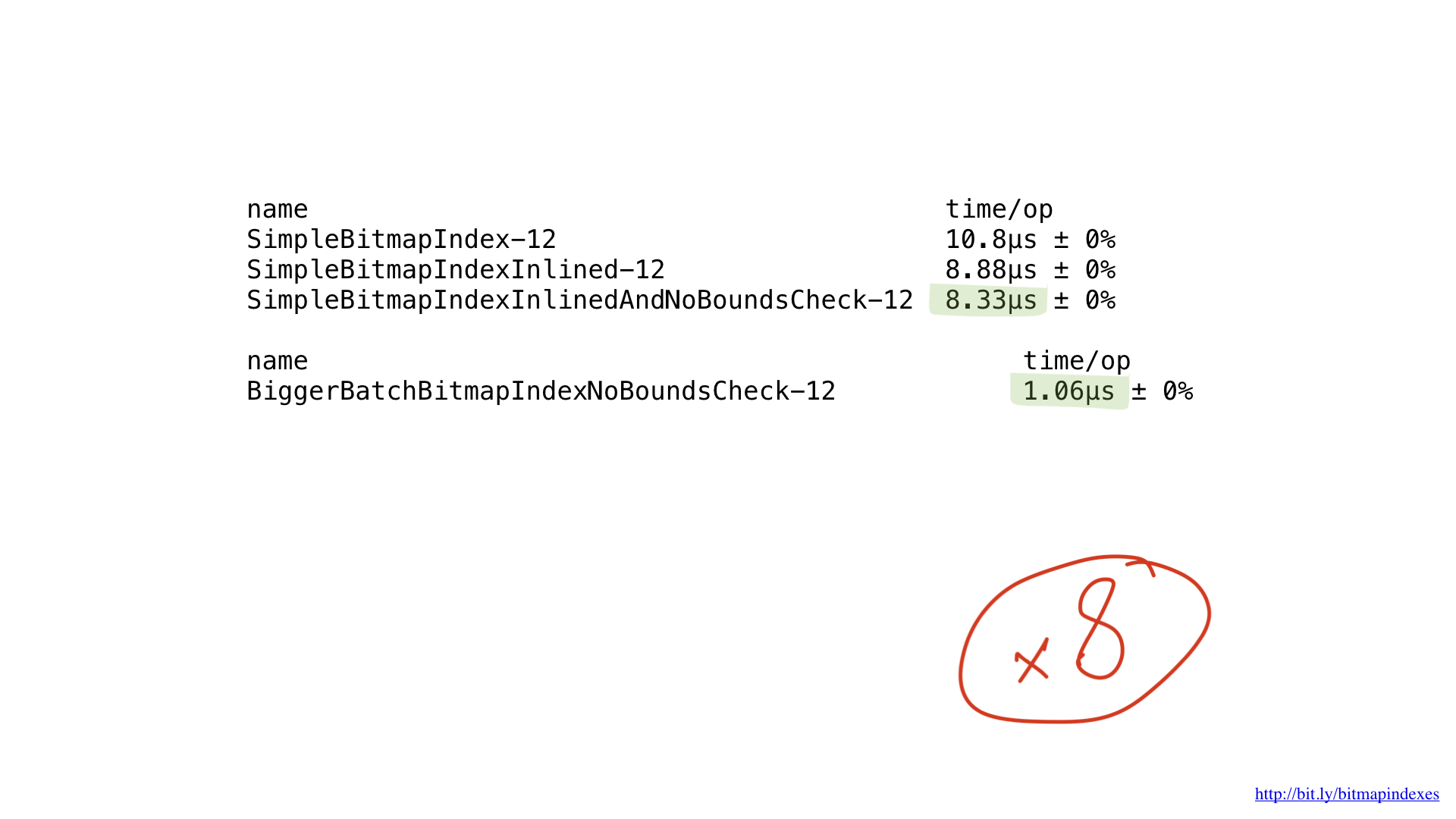
Tudo o que fazemos são operações básicas de bits, e nossos processadores as executam com muita eficiência. Infelizmente, porém, “alimentamos” nosso processador com peças muito pequenas. Nossas funções executam operações byte a byte. Podemos facilmente ajustar nosso código para que ele funcione com pedaços de 8 bytes usando fatias UInt64.

Como você pode ver, essa pequena alteração acelerou nosso programa oito vezes devido a um aumento no lote em oito vezes. Pode-se dizer que o ganho é linear.
Implementação de Assembler

Mas este não é o fim. Nossos processadores podem trabalhar com partes de 16, 32 e até 64 bytes. Tais operações "amplas" são chamadas de dados múltiplos de instrução única (SIMD; uma instrução, muitos dados), e o processo de transformação do código para que ele use essas operações é chamado de vetorização.
Infelizmente, o compilador Go está longe de ser um excelente aluno em vetorização. Atualmente, a única maneira de vetorizar o código no Go é executar e colocar essas operações manualmente usando o assembler do Go.

O Assembler Go é um animal estranho. Você provavelmente sabe que o assembler é algo fortemente vinculado à arquitetura do computador para o qual está escrevendo, mas esse não é o caso do Go. O assembler Go é mais como uma IRL (linguagem de representação intermediária) ou uma linguagem intermediária: é praticamente independente da plataforma. Rob Pike fez uma excelente
apresentação sobre esse assunto há alguns anos no GopherCon em Denver.
Além disso, o Go usa o formato incomum do Plano 9, que difere dos formatos geralmente reconhecidos da AT&T e Intel.

É seguro dizer que escrever o Go assembler manualmente não é a atividade mais divertida.
Felizmente, porém, já existem duas ferramentas de alto nível que nos ajudam a escrever o Go assembler: PeachPy e avo. Ambos os utilitários geram montadores Go a partir de códigos de nível superior escritos em Python e Go, respectivamente.

Esses utilitários simplificam coisas como alocação de registros, ciclos de gravação e geralmente simplificam o processo de entrada no mundo da programação de assembler no Go.
Como usaremos avo, nossos programas serão quase normais.

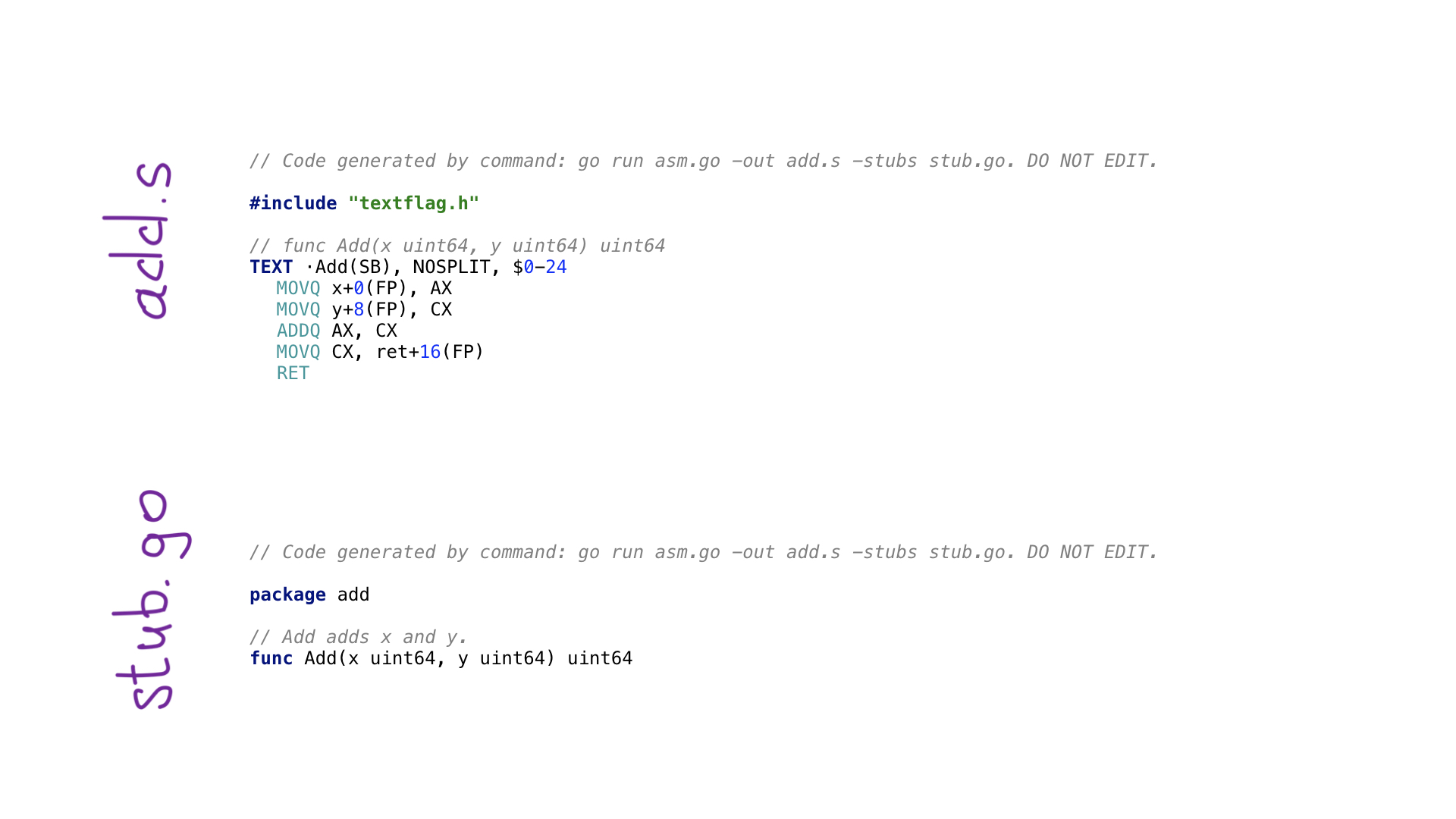
É assim que o exemplo mais simples de um programa avo se parece. Temos uma função main () que define a função Add () dentro de si mesma, cujo significado é adicionar dois números. Existem funções auxiliares para obter parâmetros pelo nome e obter um dos registros de processador gratuitos e adequados. Cada operação do processador tem uma função correspondente no avo, como visto no ADDQ. Finalmente, vemos uma função auxiliar para armazenar o valor resultante.

Ao chamar go generate, executaremos o programa no avo e no final serão gerados dois arquivos:
- add.s com o código Go assembler resultante;
- stub.go com cabeçalhos de função para conectar dois mundos: Go e assembler.
Agora que vimos o que e como o avo faz, vamos dar uma olhada em nossas funções. Eu implementei as versões escalar e vetorial (SIMD) de funções.
Primeiro, observe as versões escalares.

Como no exemplo anterior, solicitamos que você nos forneça um registro de uso geral gratuito e correto, não precisamos calcular as compensações e os tamanhos dos argumentos. Tudo isso avo faz por nós.

Anteriormente, usamos rótulos e goto (ou saltos) para melhorar o desempenho e enganar o compilador Go, mas agora fazemos isso desde o início. O fato é que os loops são um conceito de nível superior. Na montadora, só temos etiquetas e saltos.

O código restante já deve ser familiar e compreensível. Emulamos o loop com rótulos e saltos, pegamos uma pequena parte dos dados de nossas duas fatias, combinamos com uma operação de bit (AND NOT neste caso) e depois colocamos o resultado na fatia resultante. Só isso.

É assim que o código do assembler final se parece. Não precisamos calcular as compensações e tamanhos (destacados em verde) ou acompanhar os registros usados (destacados em vermelho).
Se compararmos o desempenho da implementação no assembler com o desempenho da melhor implementação no Go, veremos que é o mesmo. E isso é esperado. Afinal, não fizemos nada de especial - apenas reproduzimos o que o compilador Go faria.
Infelizmente, não podemos forçar o compilador a incorporar nossas funções escritas no assembler. O compilador Go não possui esse recurso hoje, embora a solicitação para adicioná-lo já exista há algum tempo.
É por isso que é impossível obter benefícios de pequenas funções no assembler. Precisamos escrever funções grandes, usar o novo pacote math / bits ou ignorar o lado do montador.
Vamos agora ver as versões vetoriais de nossas funções.

Neste exemplo, decidi usar o AVX2, portanto, usaremos operações que funcionam com blocos de 32 bytes. A estrutura do código é muito semelhante à opção escalar: carregar parâmetros, forneça um registro geral gratuito, etc.
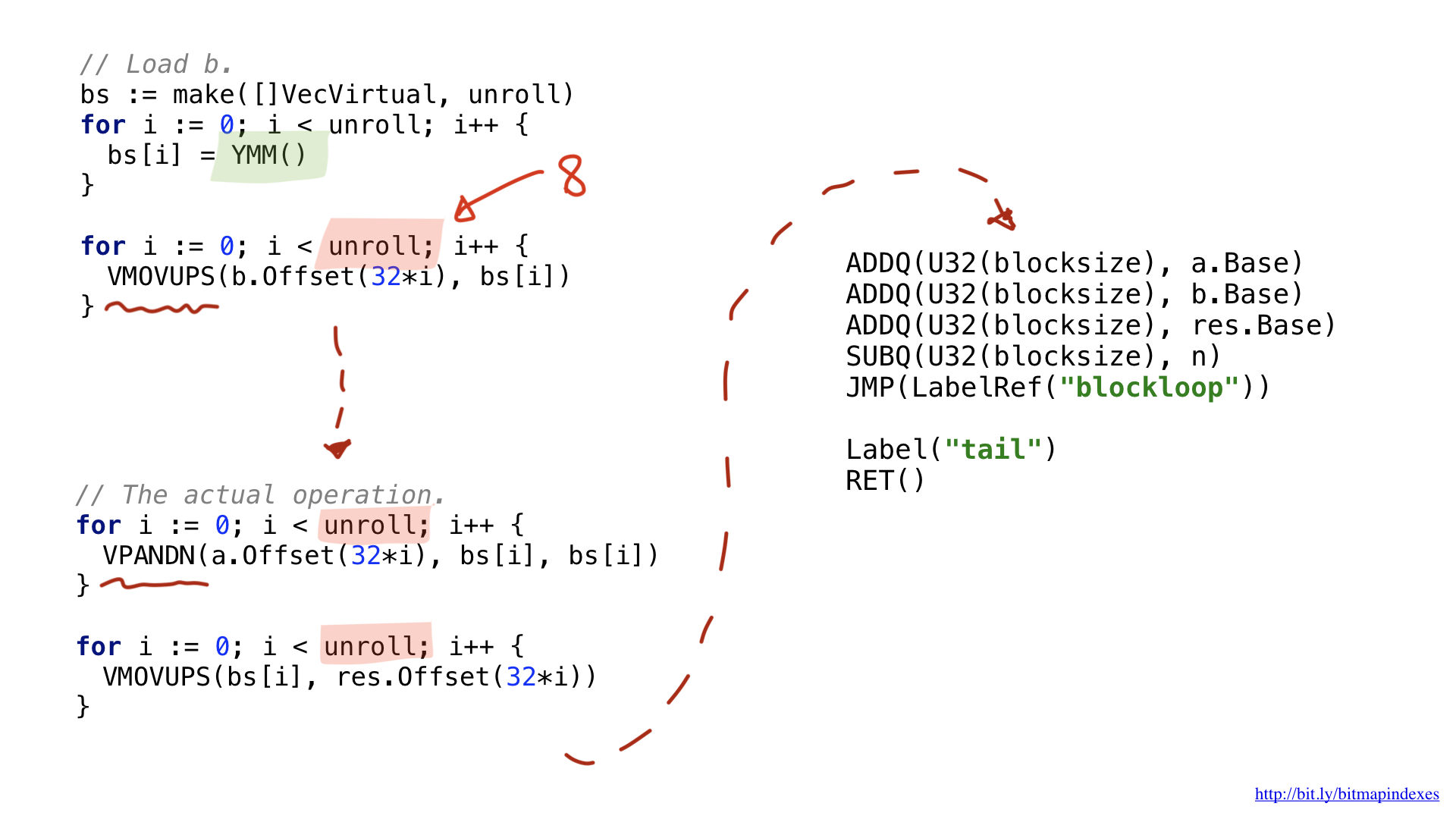
Uma das inovações é que operações vetoriais mais amplas usam registros amplos especiais. No caso de blocos de 32 bytes, esses são registros com o prefixo Y. É por isso que você vê a função YMM () no código. Se eu usasse o AVX-512 com pedaços de 64 bits, o prefixo seria Z.
A segunda inovação é que eu decidi usar uma otimização chamada desenrolamento de loop, ou seja, executar oito operações de loop manualmente antes de pular para o início do loop. Essa otimização reduz o número de brunches (ramificações) no código e é limitada pelo número de registros gratuitos disponíveis.
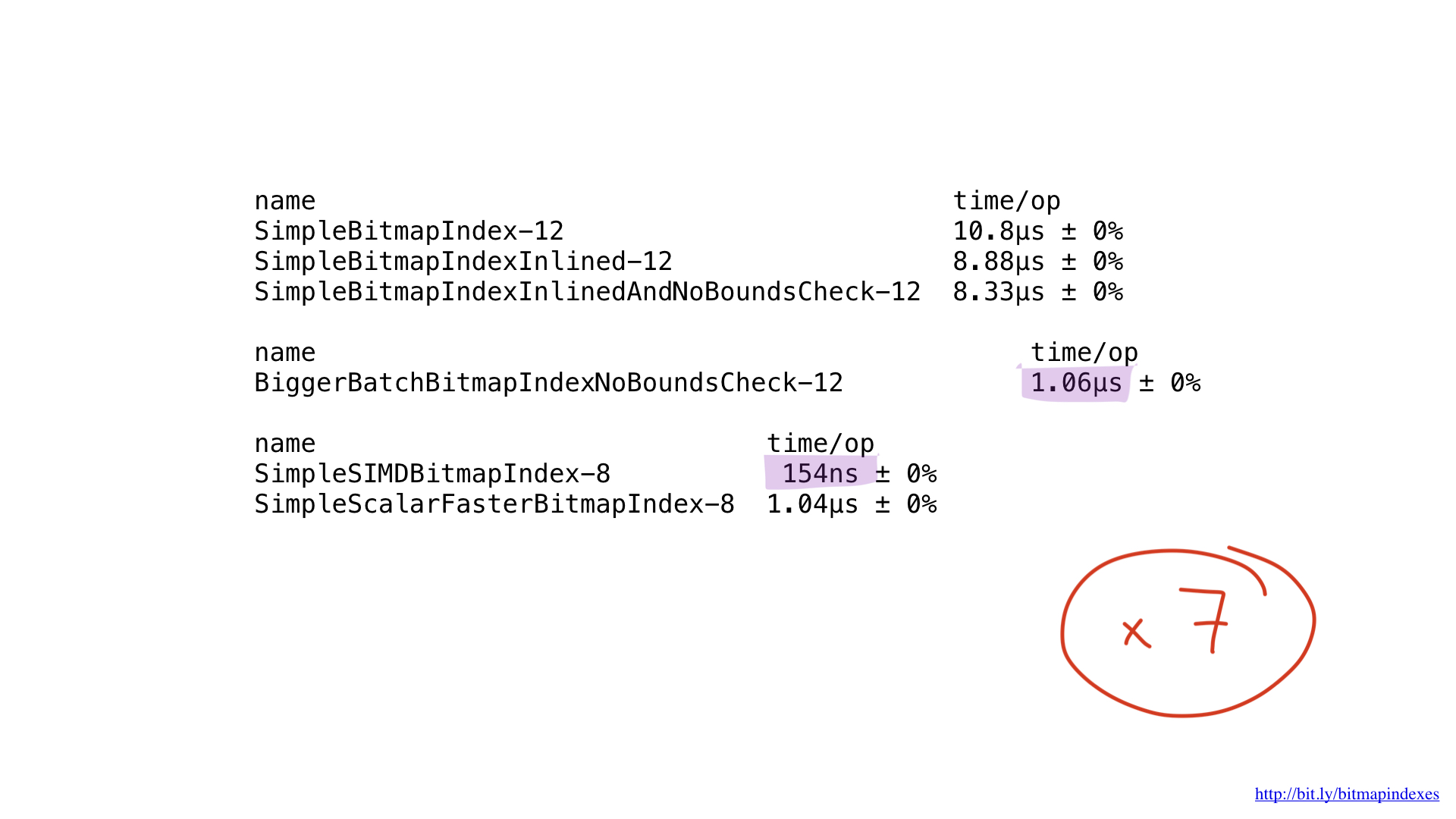
Bem, e o desempenho? Ela é linda! Aceleramos cerca de sete vezes em comparação com a melhor solução do Go. Impressionante, hein?
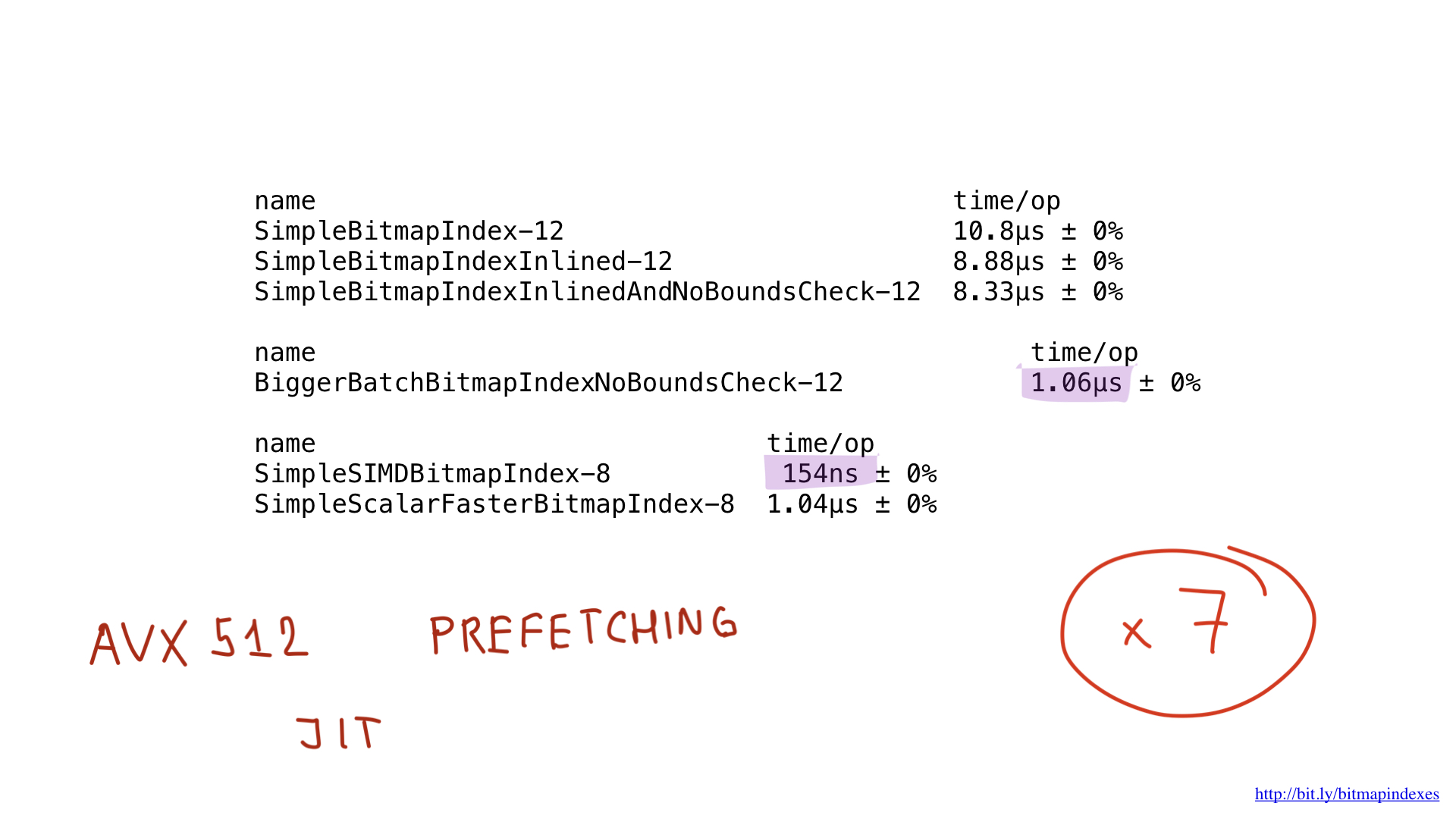
Mas mesmo essa implementação pode ser potencialmente acelerada usando o AVX-512, pré-busca ou JIT (compilador just-in-time) para o planejador de consultas. Mas este é certamente um tópico para um relatório separado.
Problemas de índice de bitmap
Agora que já analisamos uma implementação simples do índice de bitmap Go e uma linguagem assembly muito mais eficiente, vamos finalmente falar sobre por que os índices de bitmap são tão raramente usados.

Nos artigos científicos antigos, três problemas de índices de bitmap são mencionados, mas artigos científicos mais recentes e eu argumentamos que eles não são mais relevantes.
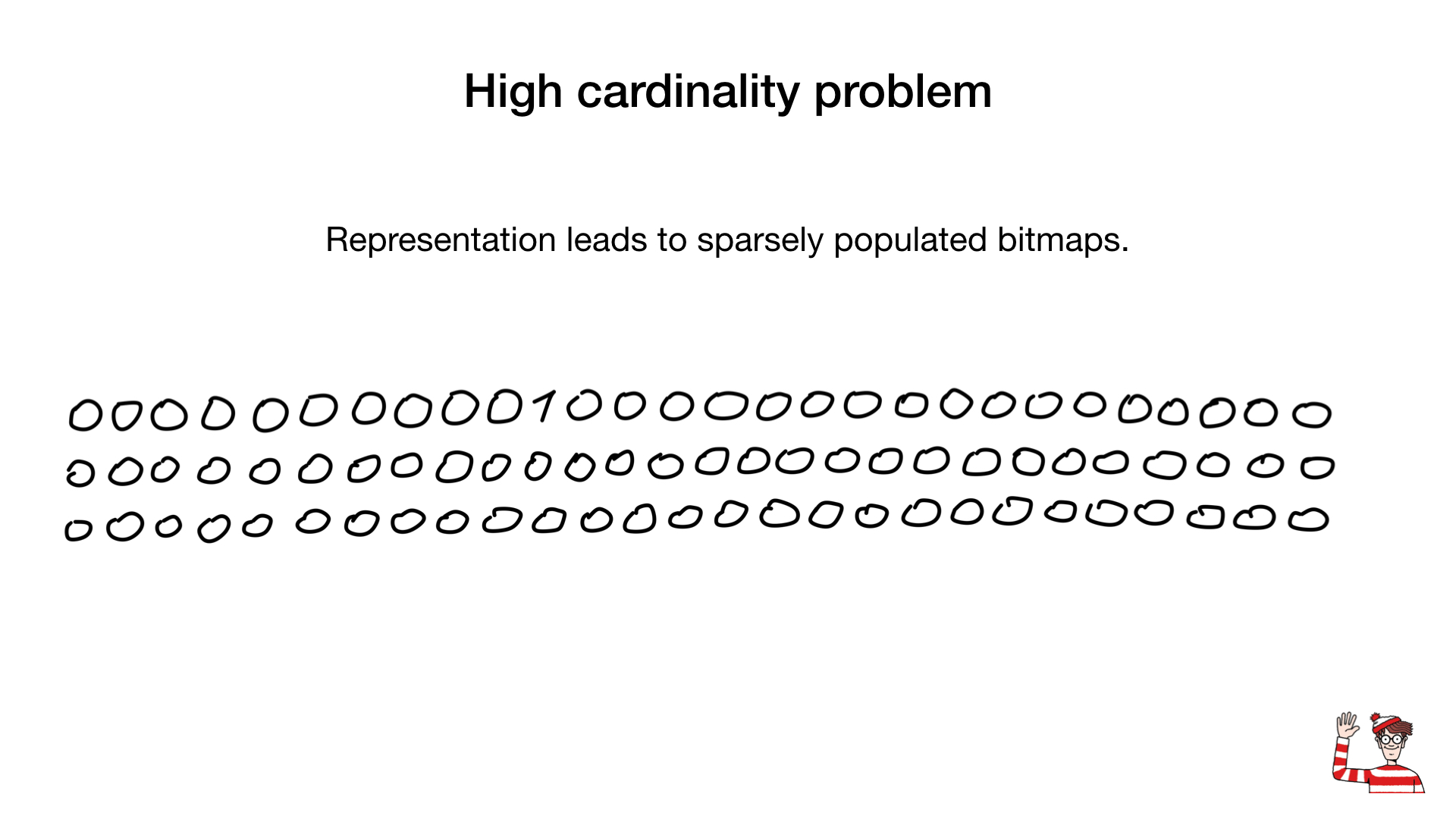
Não nos aprofundaremos em cada um desses problemas, mas os consideraremos superficialmente.O problema da grande cardinalidade
, , bitmap- , , (, ), , ( ) , , bitmap- () .
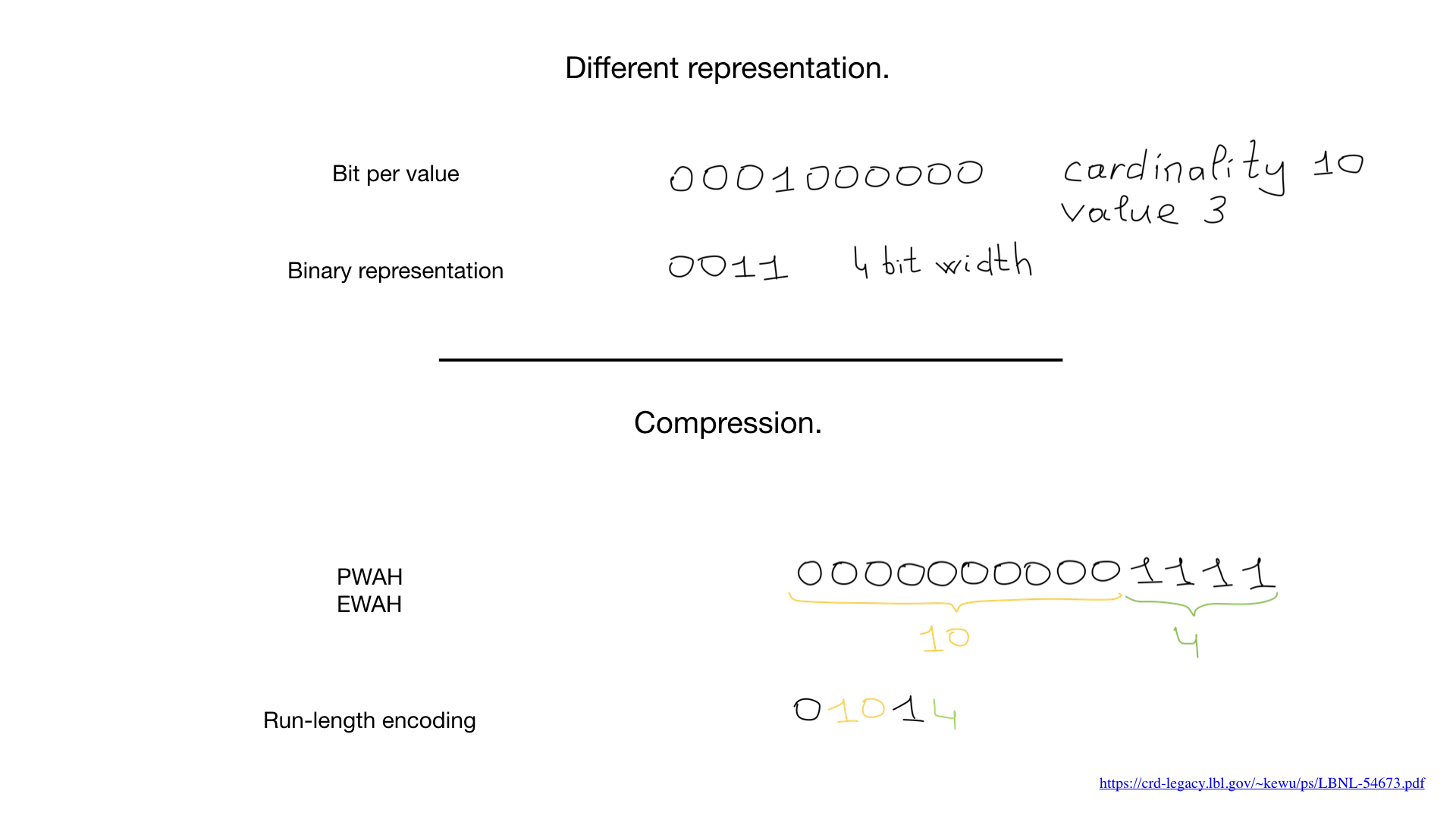
, , . . . , — .

, , , roaring . — , bit runs — , .
roaring . , Go.
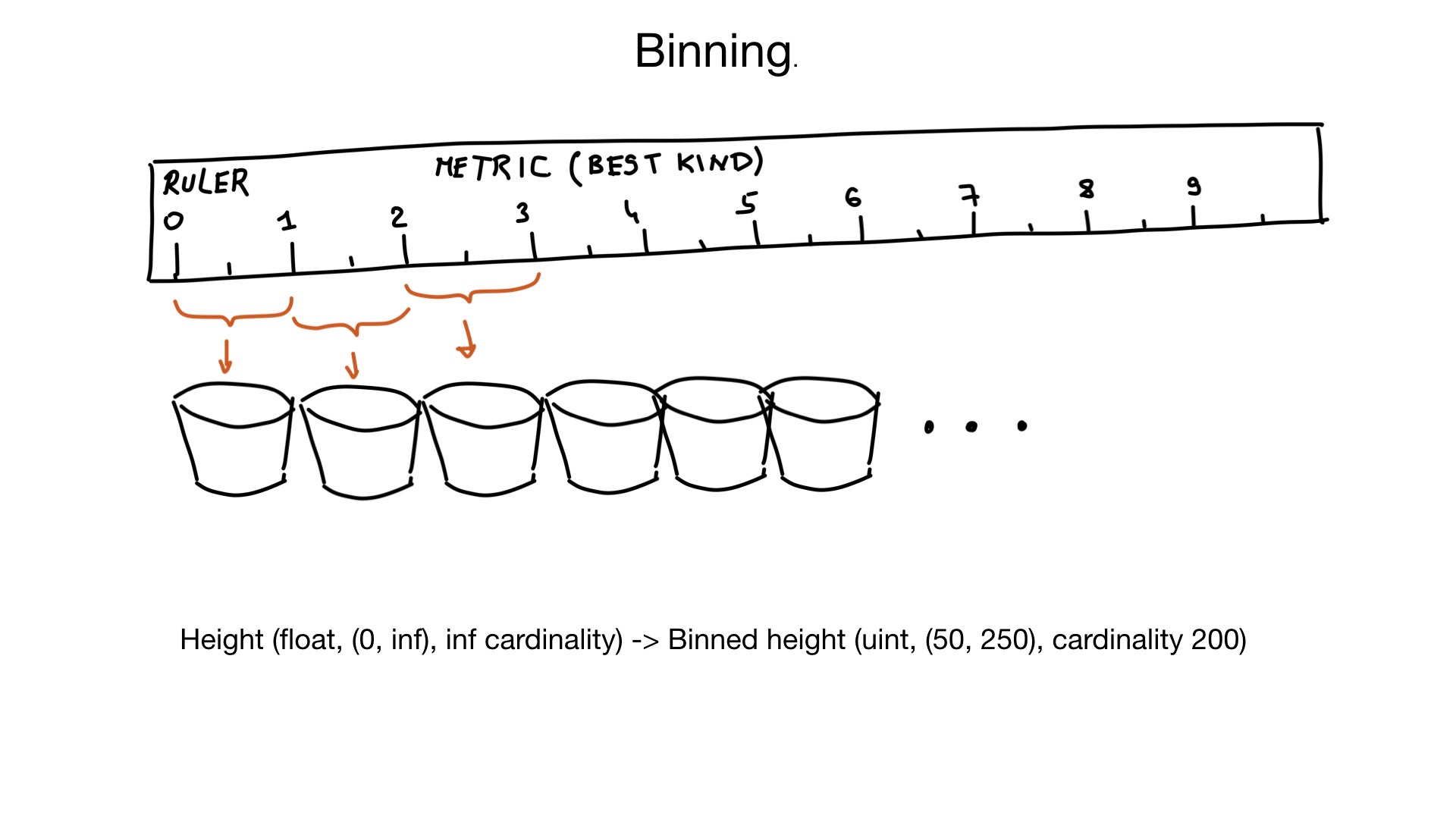
, , (binning). , , . — , , , . 185,2 185,3 .
, 1 .
, 50 250 , , , 200 .
, .
bitmap- , .
, . , . , , — lock contention, .
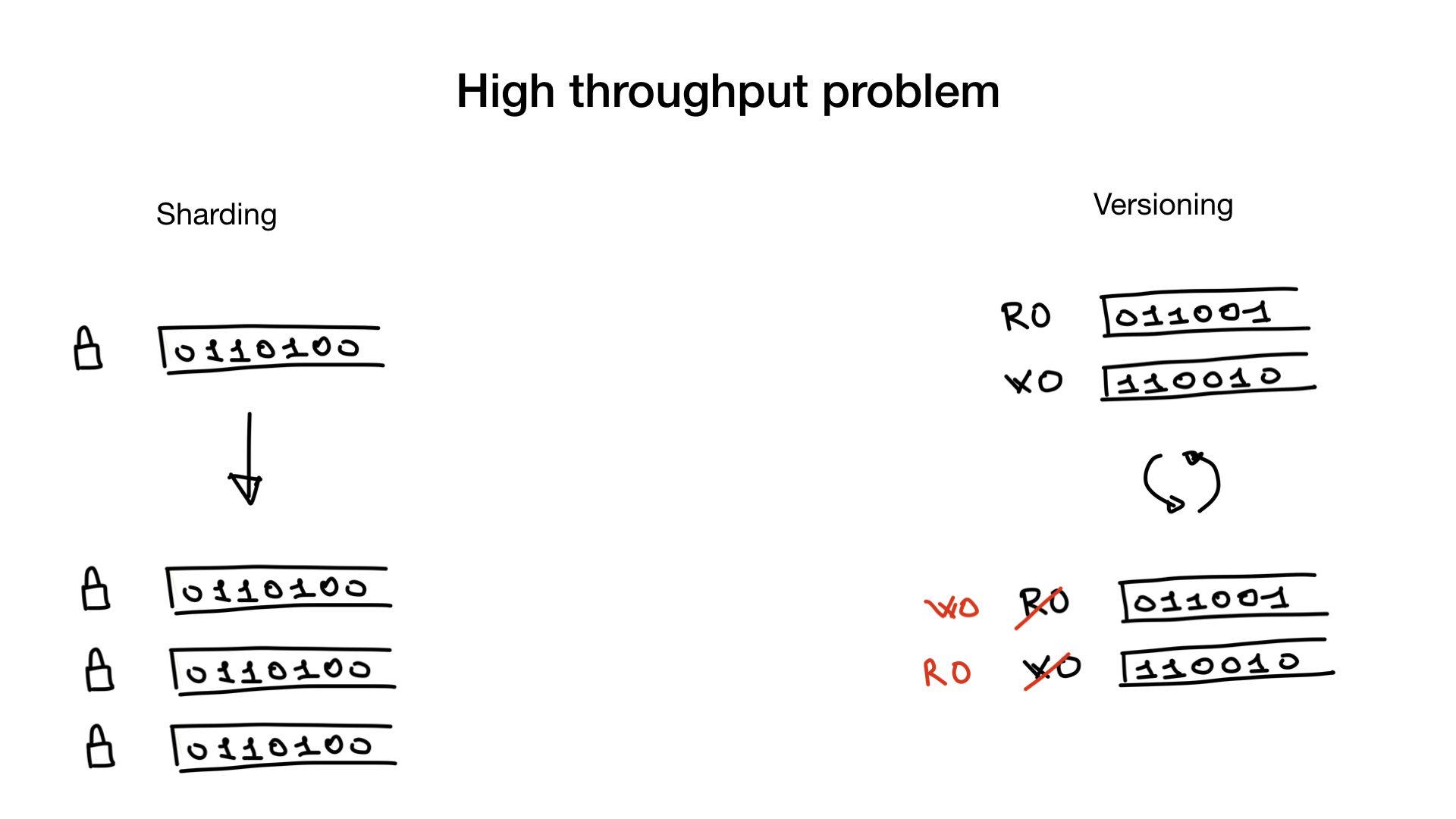
.
— . bitmap- , . lock contention.
— . , , — . - (, 100 500 ) . , , .
: .
bitmap- , , , , « ».
, , AND, OR . . - « 200 300 ».

OR.

. , 50 . 50 .
, . range-encoded bitmaps.

- (, 200), , . 200 . 300: 300 . E assim por diante
, , . , 300 , , 199 . Feito.

, bitmap-. , , . , S2 Google. , . « » ( ).
Soluções prontas
. - - , , .
, , bitmap- . , SIMD, .
, , .

Roaring
-, roaring bitmaps-, . , , bitmap-.
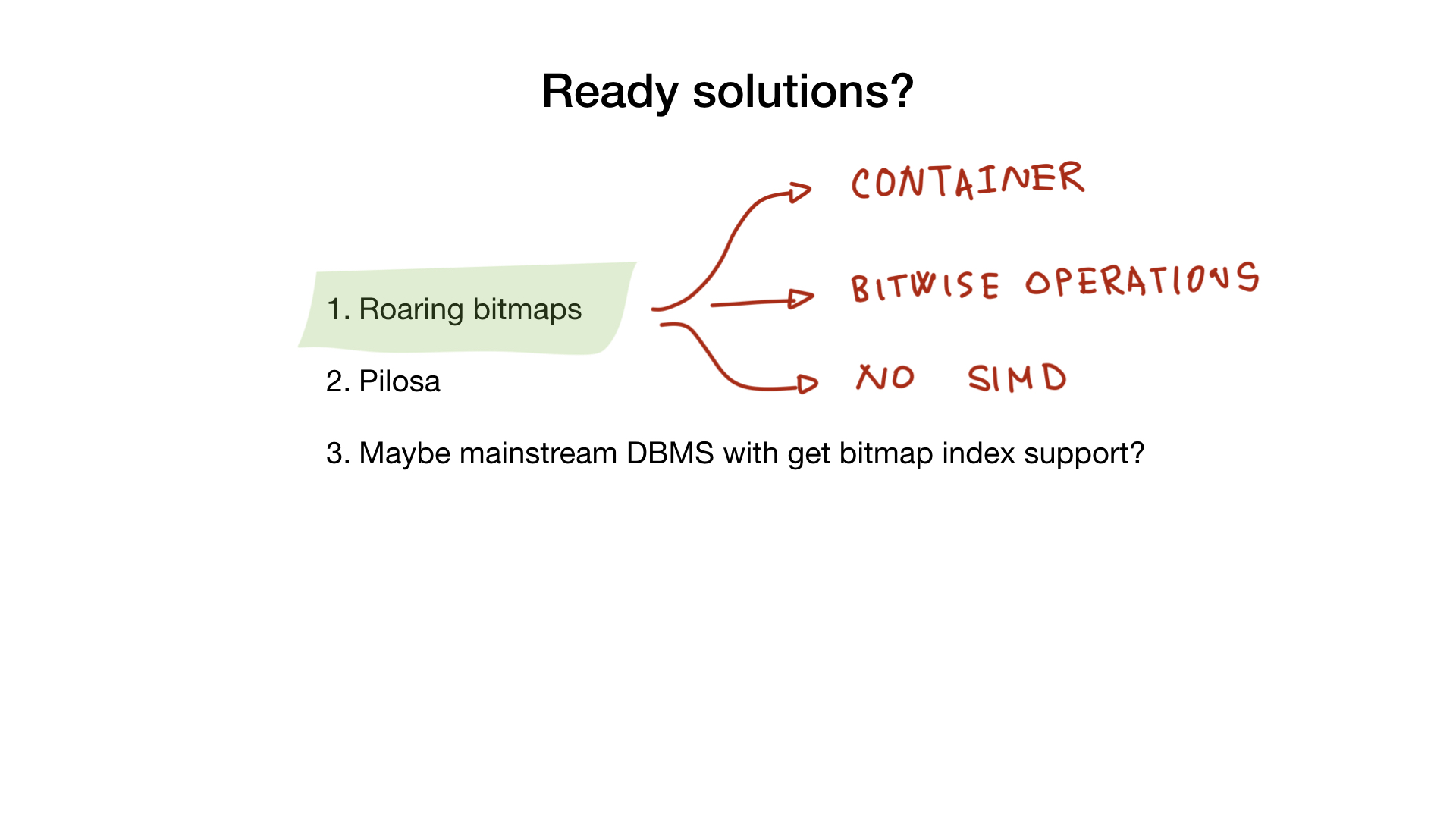
, Go- SIMD, , Go- , C, .
Pilosa
, , — Pilosa, , , bitmap- . , .
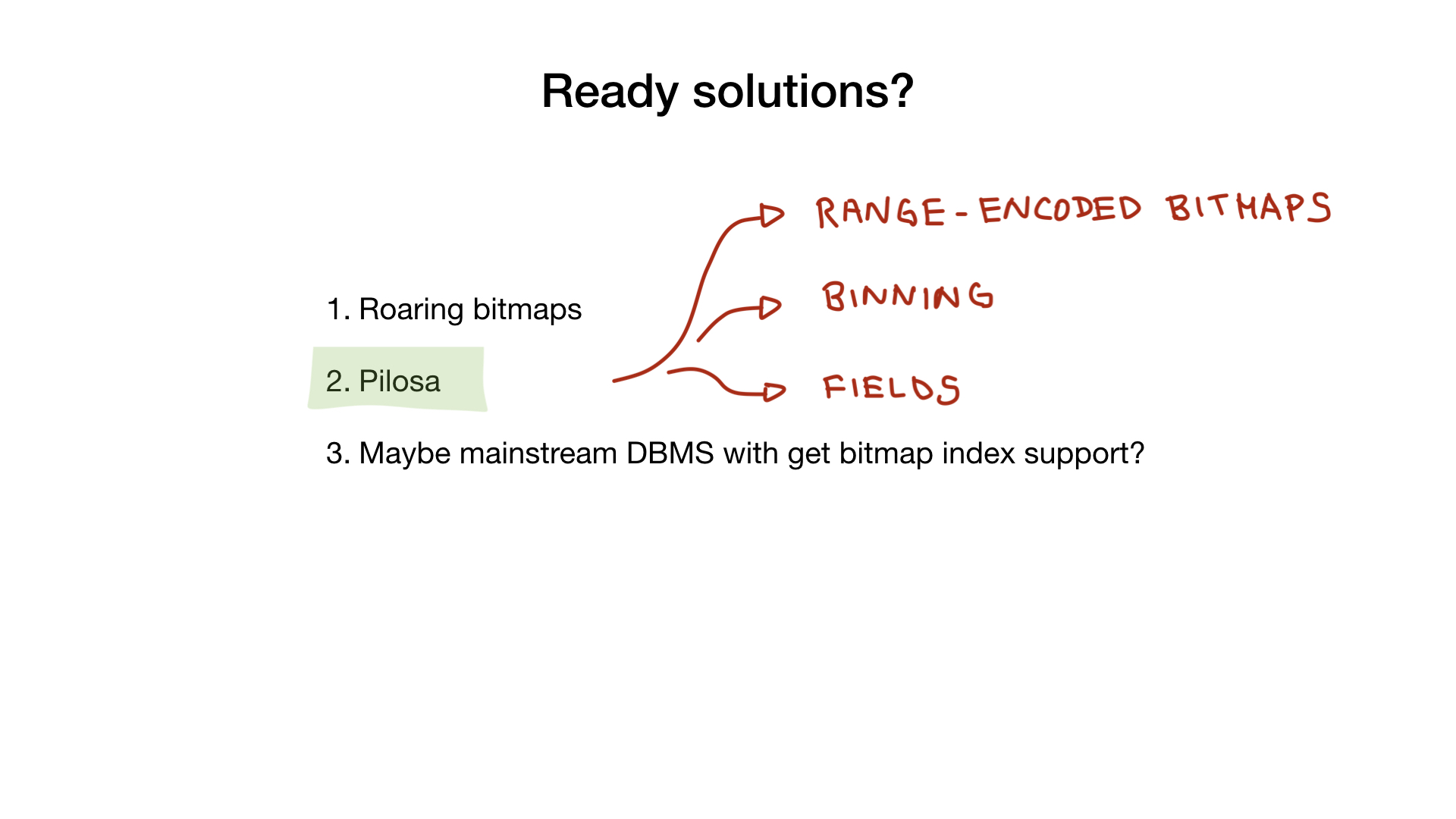
Pilosa roaring , , : , range-encoded bitmaps, . .
Pilosa .

, . Pilosa, , , , .
NOT «expensive», ( AND-) «terrace» «reservations». , .

, MySQL PostgreSQL — bitmap-.

Conclusão

Se você ainda não dormiu, obrigado. Tive que abordar muitos tópicos de passagem por causa do tempo limitado, mas espero que o relatório tenha sido útil e, talvez, até motivador.
É bom saber sobre índices de bitmap, mesmo que você não precise deles agora. Deixe que eles sejam outra ferramenta na sua gaveta.
Você e eu examinamos vários truques de desempenho do Go e as coisas que o compilador Go não faz muito bem até agora. Mas é absolutamente útil para todo programador Go saber.
Isso é tudo que eu queria contar. Obrigada