Uma lição introdutória gratuita é o recurso da Escola Skyeng. Um aluno em potencial pode se familiarizar com a plataforma, verificar seu nível de inglês e, finalmente, se divertir. Para a escola, a lição introdutória faz parte do funil de vendas, seguida pelo primeiro pagamento. É conduzido por um metodologista de aula introdutório - uma pessoa especial que combina um professor e um vendedor, seu tempo é pago, independentemente de o cliente ter comprado o primeiro pacote ou não, e se ele compareceu à aula. O absenteísmo é uma ocorrência muito comum, devido à qual o preço de uma lição se torna muito alto.
Neste artigo, descreveremos como, com a ajuda do modelo analítico e da experiência das companhias aéreas, conseguimos reduzir os custos da lição introdutória em quase metade.
O funil de vendas Skyeng consiste em cinco etapas: registrar-se no site, ligar para a primeira linha de vendas com uma entrada para a lição introdutória, lição introdutória, tocar a segunda linha de vendas, pagar o primeiro pacote. Anteriormente, após a primeira chamada, estabelecemos um horário para um metodologista de aula introdutório em particular, que estava esperando o aluno naquele momento. Se uma pessoa se inscreveu e não compareceu, o metodologista desperdiçou seu tempo e a escola - dinheiro para pagar por esse tempo. O absenteísmo ocorre em média em metade dos casos; um terço dos clientes compra o primeiro pacote após uma lição introdutória. Assim, a conversão da gravação para uma lição introdutória em pagamento é de apenas 0,15. Uma lição introdutória bem-sucedida (convertida em pagamento) no antigo esquema nos custou 4.000 rublos e tivemos que fazer algo a respeito.
Você pode simplesmente recusá-lo, mas, nesse caso, a conversão final do lead em pagamento cairá significativamente, o que não nos convém. Teremos que procurar outra solução, criar modelos, contar e experimentar.
Primeira panqueca
Nos voltamos para a experiência das companhias aéreas, especificamente para a prática de overbooking. As transportadoras sabem que 100% dos passageiros que compraram uma passagem raramente estão em um voo e se beneficiam disso vendendo mais passagens do que assentos no avião. Se de repente todos os passageiros chegarem ao pouso, você poderá encontrar voluntários entre eles, prontos para voar para o próximo coque no próximo vôo. Assim, as companhias aéreas aumentam seus lucros e podemos reduzir custos por um método semelhante.
Então: recusamos o registro a uma pessoa específica, criamos um conjunto de metodologistas da lição introdutória, dispersamos aplicativos entre eles na expectativa de que metade não apareça. E, se houver mais, sugerimos que você se inscreva para outro dia. Lançamos esse MVP no teste e imediatamente percebemos que tínhamos feito tudo errado.
Metade das pessoas que entram na lição introdutória são estatísticas, na realidade, a proporção varia muito, dependendo da hora, dia, canal de onde a pessoa veio. Além disso, mais de 80% dos alunos em potencial, em resposta a uma proposta de adiar a lição, caem imediatamente ou não aparecem no segundo registro. Tudo isso poderia levar ao fato de que, em dias ruins, perderíamos até um terço dos clientes. O teste foi desligado e passou a fazer tudo de maneira inteligente.
Modelo, previsões, polinômios
Antes de tudo, era necessário descobrir de que depende a proporção daqueles que frequentam a lição introdutória. A primeira observação é que depende do canal de marketing de onde a pessoa veio. Dividimos esses canais do ponto de vista da conversão em pagamento em "quente", onde a conversão é maior, "quente" e "frio", onde é menor; descobriu-se que a "temperatura do canal" afeta a conversão para a saída da lição introdutória da mesma maneira.
Continuando a analogia da aviação, fizemos diferentes "balcões de check-in" para leads de diferentes canais, colocando-os com coeficientes correspondentes à probabilidade histórica de saída desse canal: 0.8, 0.4 e 0.2. Para canais "quentes", alocamos mais metodologistas, "frios" - menos. Isso funcionou melhor, mas ainda em dias ruins houve mais de 20% de “partidas” (situações em que mais clientes assistiram à aula introdutória do que metodologistas livres). Eles tentaram aumentar os coeficientes adicionando uma margem de 0,1: por um lado, quanto mais divulgamos os metodólogos, menos perdemos clientes, por outro - os custos de realização de lições introdutórias estão aumentando.
A partir dessas observações, o segundo MVP cresceu. Para cada inscrito, fazemos uma previsão da probabilidade de ele ir para uma aula introdutória. Fazemos uma distribuição conjunta de probabilidade e intervalo de confiança com um nível de confiança de 95%. Para casos raros em que mais clientes estão saindo do que o planejado, possuímos uma reserva de metodologistas - professores que atualmente estão envolvidos em trabalhos não urgentes, como a verificação de ensaios.
Para calcular a previsão para um aluno em particular, construímos um modelo estatístico com base em nossos dados históricos e levando em consideração vários fatores: canal, região, criança / adulto, cliente particular / corporativo, tempo desde a gravação até a lição introdutória.
O modelo opera com os seguintes conceitos:
- slot : data e hora da aula introdutória;
- fator de correção : a probabilidade de uma saída anormal neste dia e hora;
- peso do aplicativo : probabilidade admissível de saída de um determinado cliente;
- Partida : aplicativo não atendido (cliente encerrado, todos os metodologistas estão ocupados);
- metodologista simples : resultou menos do que o previsto, as pessoas estão paradas;
- restrição :% no intervalo de confiança, após o qual o modelo proíbe adicionar pedidos ao slot.
Cada slot contém N metodologistas e o slot em si possui um fator de correção k (com uma base de 100). O número de metodologistas disponíveis para o modelo é definido como redondo (N * k / 100). Quando um aplicativo aparece, o modelo determina seu peso , analisa a soma desses pesos já no slot e determina o slot como disponível se, como resultado da adição desse aplicativo, a soma dos pesos do aplicativo no slot não exceder o número de metodologistas. As métricas para avaliar o modelo são: a proporção de partidas (necessárias para minimizar), carregamento de slots (maximizado), o tempo de espera para a lição introdutória do cliente (minimizada). Os parâmetros variáveis do modelo incluem peso e restrição do aplicativo .
Para prever quantos clientes serão liberados, foi utilizada a fórmula do produto de probabilidades:

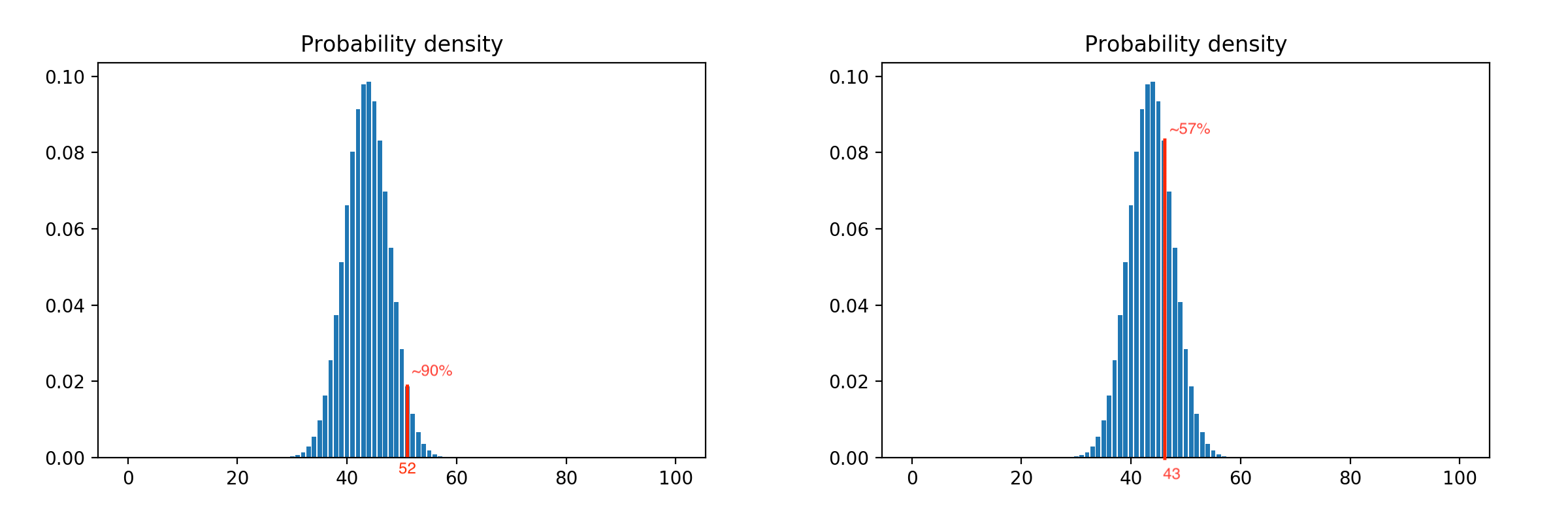
Considerando todas as combinações possíveis de resultados, obtemos uma distribuição de probabilidade muito próxima da natural. A distribuição para cem clientes é assim:

Aplicando o intervalo de confiança, podemos ajustar a agressividade do modelo. Por exemplo, deslocar a restrição para a esquerda aumenta, ou seja, liberamos mais clientes com o mesmo número de metodologistas e uma mudança para a direita o reduz, porque restrição é acionada anteriormente. Exemplo com restrições de 90% e 57%:
Além disso, a agressividade do modelo pode ser ajustada por um fator de correção: uma diminuição o reduz, um aumento aumenta. Isso é útil quando sabemos que em um dia / hora específico, certos fatores externos podem causar a anormalidade.
A fórmula com multiplicação de probabilidades mostrou-se bem nos testes, mas era difícil do ponto de vista computacional, por isso a reescrevemos com polinômios:

As desvantagens do modelo incluem:
- devido ao fato de ser baseado em dados históricos, não responde bem a mudanças repentinas na saída;
- se o metodologista tiver um evento de força maior e ele sair do slot, essa é uma partida quase garantida, os gerentes precisam reatribuir urgentemente a lição;
- se a marcação dinâmica do “calor” dos canais cai, o modelo calcula incorretamente a probabilidade de saída do cliente.
Como resultado do uso desse modelo, recebemos até 45% de economia de custos na lição introdutória com perda mínima para os clientes.
Por que não o aprendizado de máquina?
Como o modelo estatístico funciona muito bem e, em vez de melhorar a precisão de uma previsão existente usando o ML, é mais lucrativo direcionar os esforços dos desenvolvedores do ML para outras tarefas.
Por exemplo, estamos desenvolvendo um sistema de pontuação para um cliente em potencial, remotamente semelhante a um sistema bancário. Usando a pontuação, os bancos determinam a probabilidade de reembolso de um empréstimo e podemos determinar a probabilidade de um primeiro pagamento. Se for muito baixo, não há necessidade de gastar recursos na organização de uma lição introdutória; se, pelo contrário, for muito alto, você poderá enviar imediatamente o cliente para a página de pagamento.
Mas essa história é para outra época.