Já discutimos o
mecanismo de indexação do PostgreSQL, a interface dos métodos de acesso e os principais métodos de acesso, como:
índices de hash ,
árvores B ,
GiST ,
SP-GiST e
GIN . Neste artigo, veremos como o gin se transforma em rum.
RUM
Embora os autores afirmem que o gin é um gênio poderoso, o tema das bebidas acabou vencendo: a próxima geração de GIN foi chamada de RUM.
Esse método de acesso expande o conceito subjacente ao GIN e nos permite executar a pesquisa de texto completo ainda mais rapidamente. Nesta série de artigos, este é o único método que não está incluído em uma entrega padrão do PostgreSQL e é uma extensão externa. Várias opções de instalação estão disponíveis para isso:
- Pegue o pacote "yum" ou "apt" do repositório PGDG . Por exemplo, se você instalou o PostgreSQL a partir do pacote "postgresql-10", também instale "postgresql-10-rum".
- Crie a partir do código-fonte no github e instale por conta própria (as instruções também estão lá).
- Use como parte do Postgres Pro Enterprise (ou pelo menos leia a documentação de lá).
Limitações do gin
Quais limitações do GIN o RUM nos permite transcender?
Primeiro, o tipo de dados "tsvector" contém não apenas lexemas, mas também informações sobre suas posições dentro do documento. Como observamos na
última vez , o índice GIN não armazena essas informações. Por esse motivo, as operações para procurar frases, que apareceram na versão 9.6, são suportadas pelo índice GIN ineficientemente e precisam acessar os dados originais para verificar novamente.
Segundo, os sistemas de pesquisa geralmente retornam os resultados classificados por relevância (o que isso significa). Podemos usar as funções de classificação "ts_rank" e "ts_rank_cd" para esse fim, mas elas precisam ser calculadas para cada linha do resultado, o que certamente é lento.
Para uma primeira aproximação, o método de acesso RUM pode ser considerado como GIN, que armazena adicionalmente informações de posição e pode retornar os resultados na ordem necessária (como o
GiST pode retornar vizinhos mais próximos). Vamos avançar passo a passo.
Procurando por Frases
Uma consulta de pesquisa em texto completo pode conter operadores especiais que levam em consideração a distância entre lexemes. Por exemplo, podemos encontrar documentos nos quais "mão" é separada de "coxa" com mais duas palavras:
postgres=# select to_tsvector('Clap your hands, slap your thigh') @@ to_tsquery('hand <3> thigh');
?column? ---------- t (1 row)
Ou podemos indicar que as palavras devem ser localizadas uma após a outra:
postgres=# select to_tsvector('Clap your hands, slap your thigh') @@ to_tsquery('hand <-> slap');
?column? ---------- t (1 row)
O índice GIN regular pode retornar os documentos que contêm os dois lexemas, mas podemos verificar a distância entre eles apenas olhando para tsvector:
postgres=# select to_tsvector('Clap your hands, slap your thigh');
to_tsvector -------------------------------------- 'clap':1 'hand':3 'slap':4 'thigh':6 (1 row)
No índice RUM, cada lexeme não faz apenas referência às linhas da tabela: cada TID é fornecida com a lista de posições em que o lexeme ocorre no documento. É assim que podemos visualizar o índice criado na tabela "slit-sheet", que já é bastante familiar para nós (a classe de operador "rum_tsvector_ops" é usada por tsvector por padrão):
postgres=# create extension rum; postgres=# create index on ts using rum(doc_tsv);
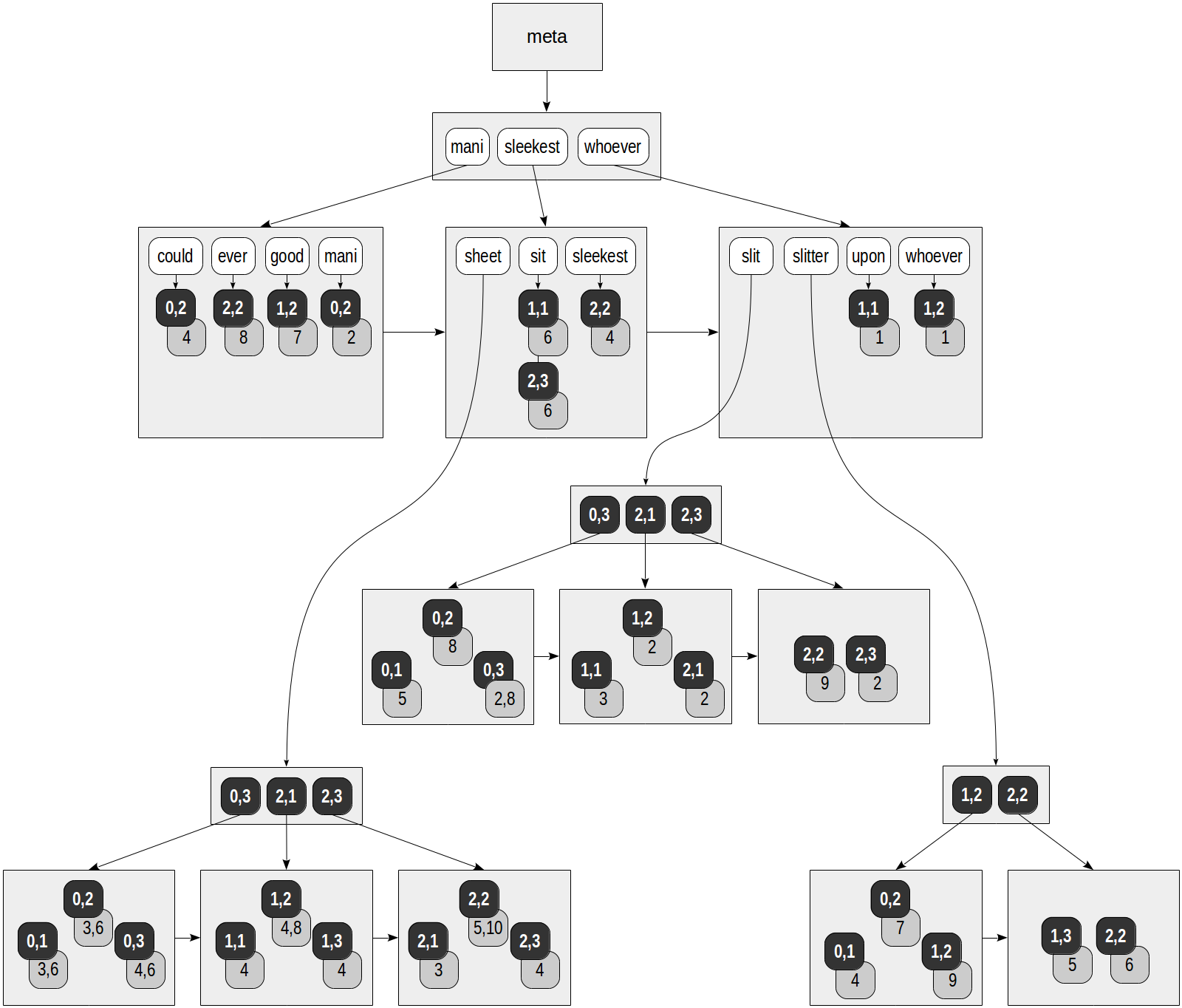
Quadrados cinza na figura contêm as informações de posição adicionadas:
postgres=# select ctid, left(doc,20), doc_tsv from ts;
ctid | left | doc_tsv -------+----------------------+--------------------------------------------------------- (0,1) | Can a sheet slitter | 'sheet':3,6 'slit':5 'slitter':4 (0,2) | How many sheets coul | 'could':4 'mani':2 'sheet':3,6 'slit':8 'slitter':7 (0,3) | I slit a sheet, a sh | 'sheet':4,6 'slit':2,8 (1,1) | Upon a slitted sheet | 'sheet':4 'sit':6 'slit':3 'upon':1 (1,2) | Whoever slit the she | 'good':7 'sheet':4,8 'slit':2 'slitter':9 'whoever':1 (1,3) | I am a sheet slitter | 'sheet':4 'slitter':5 (2,1) | I slit sheets. | 'sheet':3 'slit':2 (2,2) | I am the sleekest sh | 'ever':8 'sheet':5,10 'sleekest':4 'slit':9 'slitter':6 (2,3) | She slits the sheet | 'sheet':4 'sit':6 'slit':2 (9 rows)
O GIN também fornece uma inserção adiada quando o parâmetro "fastupdate" é especificado; essa funcionalidade é removida do RUM.
Para ver como o índice funciona com dados ativos, vamos usar o
arquivo familiar da lista de discussão pgsql-hackers.
fts=# alter table mail_messages add column tsv tsvector; fts=# set default_text_search_config = default; fts=# update mail_messages set tsv = to_tsvector(body_plain);
... UPDATE 356125
É assim que uma consulta que usa a pesquisa de frases é realizada com o índice GIN:
fts=# create index tsv_gin on mail_messages using gin(tsv); fts=# explain (costs off, analyze) select * from mail_messages where tsv @@ to_tsquery('hello <-> hackers');
QUERY PLAN --------------------------------------------------------------------------------- Bitmap Heap Scan on mail_messages (actual time=2.490..18.088 rows=259 loops=1) Recheck Cond: (tsv @@ to_tsquery('hello <-> hackers'::text)) Rows Removed by Index Recheck: 1517 Heap Blocks: exact=1503 -> Bitmap Index Scan on tsv_gin (actual time=2.204..2.204 rows=1776 loops=1) Index Cond: (tsv @@ to_tsquery('hello <-> hackers'::text)) Planning time: 0.266 ms Execution time: 18.151 ms (8 rows)
Como podemos ver no plano, o índice GIN é usado, mas retorna 1776 correspondências em potencial, das quais 259 são deixadas e 1517 são descartadas no estágio de verificação novamente.
Vamos excluir o índice GIN e criar o RUM.
fts=# drop index tsv_gin; fts=# create index tsv_rum on mail_messages using rum(tsv);
O índice agora contém todas as informações necessárias e a pesquisa é realizada com precisão:
fts=# explain (costs off, analyze) select * from mail_messages where tsv @@ to_tsquery('hello <-> hackers');
QUERY PLAN -------------------------------------------------------------------------------- Bitmap Heap Scan on mail_messages (actual time=2.798..3.015 rows=259 loops=1) Recheck Cond: (tsv @@ to_tsquery('hello <-> hackers'::text)) Heap Blocks: exact=250 -> Bitmap Index Scan on tsv_rum (actual time=2.768..2.768 rows=259 loops=1) Index Cond: (tsv @@ to_tsquery('hello <-> hackers'::text)) Planning time: 0.245 ms Execution time: 3.053 ms (7 rows)
Classificando por relevância
Para retornar documentos prontamente na ordem necessária, o índice RUM suporta operadores de pedidos, que discutimos no artigo relacionado ao
GiST . A extensão RUM define esse operador,
<=> , que retorna uma certa distância entre o documento ("tsvector") e a consulta ("tsquery"). Por exemplo:
fts=# select to_tsvector('Can a sheet slitter slit sheets?') <=>l to_tsquery('slit');
?column? ---------- 16.4493 (1 row)
fts=# select to_tsvector('Can a sheet slitter slit sheets?') <=> to_tsquery('sheet');
?column? ---------- 13.1595 (1 row)
O documento parecia ser mais relevante para a primeira consulta do que para a segunda: quanto mais a palavra ocorre, menos "valiosa" é.
Vamos tentar novamente comparar GIN e RUM em um tamanho de dados relativamente grande: selecionaremos dez documentos mais relevantes que contêm "hello" e "hackers".
fts=# explain (costs off, analyze) select * from mail_messages where tsv @@ to_tsquery('hello & hackers') order by ts_rank(tsv,to_tsquery('hello & hackers')) limit 10;
QUERY PLAN --------------------------------------------------------------------------------------------- Limit (actual time=27.076..27.078 rows=10 loops=1) -> Sort (actual time=27.075..27.076 rows=10 loops=1) Sort Key: (ts_rank(tsv, to_tsquery('hello & hackers'::text))) Sort Method: top-N heapsort Memory: 29kB -> Bitmap Heap Scan on mail_messages (actual ... rows=1776 loops=1) Recheck Cond: (tsv @@ to_tsquery('hello & hackers'::text)) Heap Blocks: exact=1503 -> Bitmap Index Scan on tsv_gin (actual ... rows=1776 loops=1) Index Cond: (tsv @@ to_tsquery('hello & hackers'::text)) Planning time: 0.276 ms Execution time: 27.121 ms (11 rows)
O índice GIN retorna 1776 correspondências, que são classificadas como uma etapa separada para selecionar dez melhores ocorrências.
Com o índice RUM, a consulta é realizada usando uma simples verificação de índice: nenhum documento extra é examinado e nenhuma classificação separada é necessária:
fts=# explain (costs off, analyze) select * from mail_messages where tsv @@ to_tsquery('hello & hackers') order by tsv <=> to_tsquery('hello & hackers') limit 10;
QUERY PLAN -------------------------------------------------------------------------------------------- Limit (actual time=5.083..5.171 rows=10 loops=1) -> Index Scan using tsv_rum on mail_messages (actual ... rows=10 loops=1) Index Cond: (tsv @@ to_tsquery('hello & hackers'::text)) Order By: (tsv <=> to_tsquery('hello & hackers'::text)) Planning time: 0.244 ms Execution time: 5.207 ms (6 rows)
Informações adicionais
O índice RUM, bem como o GIN, podem ser criados em vários campos. Porém, enquanto o GIN armazena lexemes de cada coluna independentemente dos de outra coluna, o RUM permite "associar" o campo principal ("tsvector" neste caso) a outro. Para fazer isso, precisamos usar uma classe de operador especializada "rum_tsvector_addon_ops":
fts=# create index on mail_messages using rum(tsv RUM_TSVECTOR_ADDON_OPS, sent) WITH (ATTACH='sent', TO='tsv');
Podemos usar esse índice para retornar os resultados classificados no campo adicional:
fts=# select id, sent, sent <=> '2017-01-01 15:00:00' from mail_messages where tsv @@ to_tsquery('hello') order by sent <=> '2017-01-01 15:00:00' limit 10;
id | sent | ?column? ---------+---------------------+---------- 2298548 | 2017-01-01 15:03:22 | 202 2298547 | 2017-01-01 14:53:13 | 407 2298545 | 2017-01-01 13:28:12 | 5508 2298554 | 2017-01-01 18:30:45 | 12645 2298530 | 2016-12-31 20:28:48 | 66672 2298587 | 2017-01-02 12:39:26 | 77966 2298588 | 2017-01-02 12:43:22 | 78202 2298597 | 2017-01-02 13:48:02 | 82082 2298606 | 2017-01-02 15:50:50 | 89450 2298628 | 2017-01-02 18:55:49 | 100549 (10 rows)
Aqui, pesquisamos as linhas correspondentes o mais próximo possível da data especificada, não importa mais cedo ou mais tarde. Para obter resultados estritamente anteriores (ou seguintes) à data especificada, precisamos usar
<=| operador (ou
|=> ).
Como esperado, a consulta é realizada apenas por uma simples verificação de índice:
ts=# explain (costs off) select id, sent, sent <=> '2017-01-01 15:00:00' from mail_messages where tsv @@ to_tsquery('hello') order by sent <=> '2017-01-01 15:00:00' limit 10;
QUERY PLAN --------------------------------------------------------------------------------- Limit -> Index Scan using mail_messages_tsv_sent_idx on mail_messages Index Cond: (tsv @@ to_tsquery('hello'::text)) Order By: (sent <=> '2017-01-01 15:00:00'::timestamp without time zone) (4 rows)
Se criarmos o índice sem as informações adicionais sobre a associação de campos, para uma consulta semelhante, teremos que classificar todos os resultados da verificação do índice.
Além da data, certamente podemos adicionar campos de outros tipos de dados ao índice RUM. Praticamente todos os tipos de base são suportados. Por exemplo, uma loja online pode exibir rapidamente os produtos por novidade (data), preço (numérico) e popularidade ou valor do desconto (número inteiro ou ponto flutuante).
Outras classes de operadores
Para completar, devemos mencionar outras classes de operadores disponíveis.
Vamos começar com
"rum_tsvector_hash_ops" e
"rum_tsvector_hash_addon_ops" . Eles são semelhantes aos já discutidos "rum_tsvector_ops" e "rum_tsvector_addon_ops", mas o índice armazena o código de hash do lexeme em vez do próprio lexeme. Isso pode reduzir o tamanho do índice, mas é claro que a pesquisa se torna menos precisa e requer nova verificação. Além disso, o índice não suporta mais a pesquisa de uma correspondência parcial.
É interessante observar a classe de operador
"rum_tsquery_ops" . Ele nos permite resolver um problema "inverso": encontre consultas que correspondam ao documento. Por que isso pode ser necessário? Por exemplo, para inscrever um usuário em novos produtos de acordo com seu filtro ou para categorizar automaticamente novos documentos. Veja este exemplo simples:
fts=# create table categories(query tsquery, category text); fts=# insert into categories values (to_tsquery('vacuum | autovacuum | freeze'), 'vacuum'), (to_tsquery('xmin | xmax | snapshot | isolation'), 'mvcc'), (to_tsquery('wal | (write & ahead & log) | durability'), 'wal'); fts=# create index on categories using rum(query); fts=# select array_agg(category) from categories where to_tsvector( 'Hello hackers, the attached patch greatly improves performance of tuple freezing and also reduces size of generated write-ahead logs.' ) @@ query;
array_agg -------------- {vacuum,wal} (1 row)
As classes de operador restantes
"rum_anyarray_ops" e
"rum_anyarray_addon_ops" foram projetadas para manipular matrizes em vez de "tsvector". Isso já foi discutido pela
última vez no GIN e não precisa ser repetido.
Os tamanhos do índice e do log write-ahead (WAL)
É claro que, como o RUM armazena mais informações que o GIN, ele deve ter um tamanho maior. Estávamos comparando os tamanhos de diferentes índices da última vez; vamos adicionar RUM a esta tabela:
rum | gin | gist | btree --------+--------+--------+-------- 457 MB | 179 MB | 125 MB | 546 MB
Como podemos ver, o tamanho aumentou bastante, que é o custo da pesquisa rápida.
Vale a pena prestar atenção em mais um ponto não óbvio: o RUM é uma extensão, ou seja, pode ser instalado sem nenhuma modificação no núcleo do sistema. Isso foi ativado na versão 9.6 graças a um patch de
Alexander Korotkov . Um dos problemas que precisaram ser resolvidos para esse fim foi a geração de registros de log. Uma técnica para registro de operações deve ser absolutamente confiável, portanto, uma extensão não pode ser deixada nesta cozinha. Em vez de permitir que a extensão crie seus próprios tipos de registros de log, existe o seguinte: o código da extensão comunica sua intenção de modificar uma página, faz alterações nela, sinaliza a conclusão e é o núcleo do sistema, que compara as versões antiga e nova da página e gera registros de log unificados necessários.
O algoritmo atual de geração de log compara páginas byte a byte, detecta fragmentos atualizados e registra cada um desses fragmentos, juntamente com seu deslocamento desde o início da página. Isso funciona bem ao atualizar apenas vários bytes ou a página inteira. Mas se adicionarmos um fragmento dentro de uma página, movendo o restante do conteúdo para baixo (ou vice-versa, removendo um fragmento, movendo o conteúdo para cima), significativamente mais bytes serão alterados do que realmente foram adicionados ou removidos.
Devido a isso, a alteração intensa do índice RUM pode gerar registros de tamanho significativamente maior que o GIN (que, não sendo uma extensão, mas uma parte do núcleo, gerencia o log por conta própria). A extensão desse efeito irritante depende muito de uma carga de trabalho real, mas para obter uma idéia do problema, vamos tentar remover e adicionar várias linhas várias vezes, intercalando essas operações com "vácuo". Podemos avaliar o tamanho dos registros de log da seguinte maneira: no começo e no final, lembre-se da posição no log usando a função "pg_current_wal_location" ("pg_current_xlog_location" nas versões anteriores a dez) e depois observe a diferença.
Mas, é claro, devemos considerar muitos aspectos aqui. Precisamos garantir que apenas um usuário esteja trabalhando com o sistema (caso contrário, registros "extras" serão levados em consideração). Mesmo se esse for o caso, levamos em conta não apenas o RUM, mas também as atualizações da própria tabela e do índice que suporta a chave primária. Os valores dos parâmetros de configuração também afetam o tamanho (o nível de log "réplica", sem compactação, foi usado aqui). Mas vamos tentar assim mesmo.
fts=# select pg_current_wal_location() as start_lsn \gset
fts=# insert into mail_messages(parent_id, sent, subject, author, body_plain, tsv) select parent_id, sent, subject, author, body_plain, tsv from mail_messages where id % 100 = 0;
INSERT 0 3576
fts=# delete from mail_messages where id % 100 = 99;
DELETE 3590
fts=# vacuum mail_messages;
fts=# insert into mail_messages(parent_id, sent, subject, author, body_plain, tsv) select parent_id, sent, subject, author, body_plain, tsv from mail_messages where id % 100 = 1;
INSERT 0 3605
fts=# delete from mail_messages where id % 100 = 98;
DELETE 3637
fts=# vacuum mail_messages;
fts=# insert into mail_messages(parent_id, sent, subject, author, body_plain, tsv) select parent_id, sent, subject, author, body_plain, tsv from mail_messages where id % 100 = 2;
INSERT 0 3625
fts=# delete from mail_messages where id % 100 = 97;
DELETE 3668
fts=# vacuum mail_messages;
fts=# select pg_current_wal_location() as end_lsn \gset fts=# select pg_size_pretty(:'end_lsn'::pg_lsn - :'start_lsn'::pg_lsn);
pg_size_pretty ---------------- 3114 MB (1 row)
Então, temos cerca de 3 GB. Mas se repetirmos o mesmo experimento com o índice GIN, isso renderá apenas cerca de 700 MB.
Portanto, é desejável ter um algoritmo diferente, que encontre o número mínimo de operações de inserção e exclusão que podem transformar um estado da página em outro. O utilitário "Diff" funciona de maneira semelhante.
Oleg Ivanov já implementou esse algoritmo e seu
patch está sendo discutido. No exemplo acima, esse patch permite reduzir o tamanho dos registros de log em 1,5 vezes, para 1900 MB, ao custo de uma pequena desaceleração.
Infelizmente, o patch travou e não há atividade em torno dele.
Propriedades
Como de costume, vamos examinar as propriedades do método de acesso RUM, prestando atenção às diferenças do GIN (consultas
já foram fornecidas ).
A seguir estão as propriedades do método de acesso:
amname | name | pg_indexam_has_property --------+---------------+------------------------- rum | can_order | f rum | can_unique | f rum | can_multi_col | t rum | can_exclude | t -- f for gin
As seguintes propriedades da camada de índice estão disponíveis:
name | pg_index_has_property ---------------+----------------------- clusterable | f index_scan | t -- f for gin bitmap_scan | t backward_scan | f
Observe que, diferentemente do GIN, o RUM suporta a verificação de índice - caso contrário, não seria possível retornar exatamente o número necessário de resultados em consultas com a cláusula "limit". Não há necessidade da contrapartida do parâmetro "gin_fuzzy_search_limit" de acordo. E, como consequência, o índice pode ser usado para suportar restrições de exclusão.
A seguir estão as propriedades da camada de coluna:
name | pg_index_column_has_property --------------------+------------------------------ asc | f desc | f nulls_first | f nulls_last | f orderable | f distance_orderable | t -- f for gin returnable | f search_array | f search_nulls | f
A diferença aqui é que o RUM suporta operadores de pedidos. No entanto, isso não é verdade para todas as classes de operadores: por exemplo, isso é falso para "tsquery_ops".
Continue lendo .