Olá pessoal! Meu nome é Pasha e sou engenheiro de controle de qualidade da equipe de processamento de pedidos da Lamoda. Eu falei recentemente no PHP Badoo Meetup. Hoje eu quero fornecer uma transcrição do meu relatório.
Falaremos sobre a codecepção, sobre como a usamos no Lamoda e como escrever testes nela.
Lamoda tem muitos serviços. Existem serviços de clientes que interagem diretamente com nossos usuários, com usuários do site, aplicativo móvel. Nós não vamos falar sobre eles. E existe o que nossa empresa chama de back-end profundo - esses são nossos sistemas de back-office que automatizam nossos processos de negócios. Isso inclui entrega, armazenamento, automação de estúdios de fotografia e um call center. A maioria desses serviços é desenvolvida em PHP.
Falando brevemente sobre nossa pilha, este é o PHP + Symfony. Aqui e há projetos antigos no Zend'e. PostgreSQL e MySQL são usados como bancos de dados, e Rabbit ou Kafka são usados como sistemas de mensagens.
Por que o back-end do PHP?Como eles geralmente têm uma API ramificada - é REST, em alguns lugares há um pouco de SOAP. Se eles tiverem uma interface do usuário, essa interface será mais auxiliar, usada por nossos usuários internos.
Por que precisamos de autotestes em Lamoda?Em geral, quando cheguei ao trabalho na Lamoda, havia um slogan: "Vamos nos livrar da regressão manual". Não testaremos manualmente nada de regressão. E nós trabalhamos nessa tarefa. Na verdade, essa é uma das principais razões pelas quais precisamos de autotestes - para não conduzir a regressão manualmente. Por que precisamos disso? Direito de liberar rapidamente. Para que possamos lançar nossos lançamentos sem problemas, com muita rapidez e, ao mesmo tempo, ter algum tipo de grade de autoteste que eles nos dirão, bom ou ruim. Estes são provavelmente os objetivos mais importantes. Mas há alguns auxiliares sobre os quais também quero dizer.
Por que precisamos de autoteste?
- Não teste a regressão com as mãos
- Liberação rápida
- Use como documentação
- Acelere a integração de novos funcionários
- Os autotestes são convenientemente usados (em alguns casos) como documentação. Às vezes, é mais fácil entrar nos testes, ver quais casos são cobertos, como eles funcionam e entender como essa ou aquela funcionalidade funciona e acelerar a entrada de novos funcionários - desenvolvedores e testadores - em um novo projeto. Quando você se senta para escrever autotestes, fica imediatamente claro como o sistema funciona.
Ok, conversamos sobre por que precisamos de autotestes. Agora vamos falar sobre os testes que escrevemos em Lamoda.
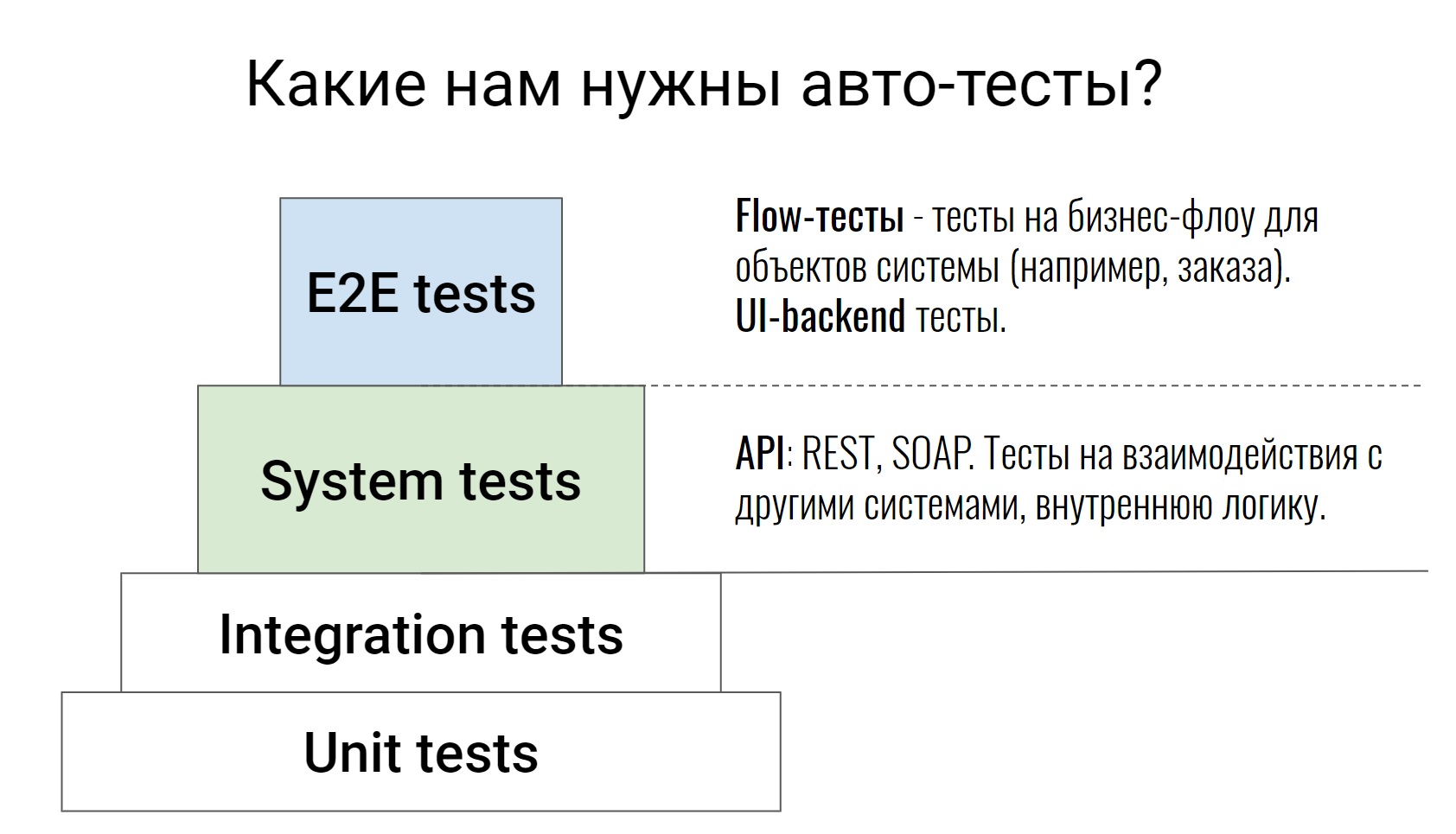
Essa é uma pirâmide de teste bastante padrão, desde testes de unidade até testes E2E, onde algumas cadeias de negócios já foram testadas. Não falarei sobre os dois níveis inferiores; não é à toa que eles são pintados com a cor branca. Estes são testes no próprio código, eles são escritos por nossos desenvolvedores. Em casos extremos, o testador pode acessar a solicitação de solicitação, examinar o código e dizer: "Bem, algo não é suficiente aqui, vamos cobrir outra coisa". Isso conclui o trabalho do testador para esses testes.
Falaremos sobre os níveis acima, escritos por desenvolvedores e testadores. Vamos começar com os testes do sistema. Estes são testes que testam a API (REST ou SOAP), testam alguma lógica interna do sistema, vários comandos, analisam filas no Rabbit ou trocam com sistemas externos. Como regra, esses testes são bastante atômicos. Eles não verificam nenhuma cadeia, mas verificam uma ação. Por exemplo, um método de API ou um comando. E eles verificam o maior número possível de casos, positivos e negativos.
Vá em frente, testes E2E. Dividi-os em 2 partes. Temos testes que testam várias UI e back-end. E existem testes que chamamos de testes de fluxo. Eles testam a cadeia - a vida de um objeto do começo ao fim.
Por exemplo, temos um sistema para gerenciar o processamento de nossos pedidos. Dentro desse sistema, pode haver um teste - um pedido da criação à entrega, ou seja, passando por todos os status. É nesses testes que é muito fácil e simples observar como o sistema funciona. Você vê imediatamente todo o fluxo de certos objetos, com quais sistemas externos tudo isso interage, quais comandos são usados para isso.
Como temos essa interface do usuário usada por usuários internos, o acesso entre navegadores não é importante para nós. Não realizamos esses testes em nenhum farms, basta fazer o check-in em um navegador e, às vezes, nem precisamos usar um navegador.
"Por que escolhemos o Codeception para automação de testes?" - você provavelmente pergunta.
Para ser sincero, não tenho resposta para essa pergunta. Quando cheguei a Lamoda, o Codeception já estava selecionado como padrão para escrever autotestes, e me deparei com isso de fato. Mas depois de trabalhar com essa estrutura por algum tempo, eu ainda entendia o porquê da codecepção. É isso que quero compartilhar com você.
Por que co-concepção?- Você pode escrever e executar os mesmos testes de qualquer tipo (unidade, funcional, aceitação).
- Muitos ancinhos já foram resolvidos, muitos módulos já foram escritos.
- Em todos os projetos, apesar das necessidades um pouco diferentes, os testes terão a mesma aparência.
- O conceito de codecepção sugere que você escreva quaisquer testes nesta estrutura: unidade, integração, funcional, aceitação. E você, pelo menos, eles serão lançados igualmente.
- A co-recepção é um processador poderoso o suficiente no qual muitos problemas, muitas perguntas e muitas tarefas para testes já foram resolvidos. Se algo não for decidido, provavelmente você encontrará algo de fora - algum complemento para algum trabalho específico. Você não precisa escrever nenhum wrapper de teste para bancos de dados, para outra coisa. Basta pegar e conectar os módulos ao Codeception e trabalhar com eles.
- Bem, essa vantagem (provavelmente é mais adequada para grandes empresas quando você tem muitos projetos e serviços) - em todos os projetos, os testes terão a aparência mais ou menos a mesma. Isso é muito legal.
Vou dizer brevemente como é a codecepção, já que muitos trabalharam com ela.

A co-concepção funciona em um modelo de ator. Depois de arrastá-lo para o projeto e inicializar, essa estrutura é gerada.
Temos os arquivos yml, aqui abaixo -
functional.suite.yml ,
integration.suit.yml ,
unit.suite.yml . Eles criam a configuração dos seus testes. Existem pais para cada tipo de teste, onde estão esses testes, existem 3 pais auxiliares:
_
dados - para dados de teste;
_
output - onde os relatórios são colocados (xml, html);
_
suporte - onde alguns auxiliares auxiliares, funções e tudo o que você escreve são utilizados em seus testes.
Para começar, vou lhe dizer o que tiramos da codecepção e usá-lo imediatamente, sem modificar nada, sem resolver tarefas ou problemas adicionais.
Módulos padrão- Phpbrowser
- REST
- Db
- Cli
- AMQP
O primeiro desses módulos é o PhpBrowser. Este módulo é um invólucro do Guzzle que permite interagir com seu aplicativo: abrir páginas, preencher formulários, enviar formulários. E se você não se importa com os testes entre navegadores e navegadores, se estiver repentinamente testando a interface do usuário, poderá usar o PhpBrowser. Como regra, usamos em nossos testes de interface do usuário, porque não precisamos de nenhuma lógica de interação complicada, precisamos apenas abrir a página e fazer algo pequeno lá.
O segundo módulo que usamos é REST. Eu acho que o nome deixa claro o que ele está fazendo. Para qualquer interação http, você pode usar este módulo. Parece-me que quase todas as interações são resolvidas: cabeçalhos, cookies, autorização. Tudo o que você precisa está nele.
O terceiro módulo que usamos imediatamente é o módulo Db. Nas versões recentes do Codeception, suporte para não um, mas vários bancos de dados foram adicionados lá. Portanto, se você repentinamente tiver vários bancos de dados em seu projeto, agora ele funciona imediatamente.
O módulo Cli, que permite executar
comandos shell e
bash a partir de testes, e nós o usamos também.
Existe um módulo AMQP que funciona com qualquer agente de mensagens baseado neste protocolo. Quero observar que é oficialmente testado no RabbitMQ. Desde que usamos RabbitMQ, está tudo bem com ele.
De fato, a codecepção, pelo menos no nosso caso, cobre 80 a 85% de todas as tarefas de que precisamos. Mas eu ainda tinha que trabalhar em alguma coisa.
Vamos começar com SOAP.

Em nossos serviços, em alguns lugares existem pontos de extremidade SOAP. Eles precisam ser testados, puxados, algo a ver com eles. Mas você dirá que no Codeception existe um módulo que permite enviar solicitações e fazer alguma coisa com as respostas. De alguma forma para analisar, adicionar cheques e está tudo bem. Mas o módulo SOAP não funciona imediatamente com vários pontos de extremidade SOAP.

Por exemplo, temos monólitos que possuem vários WSDLs, vários pontos de extremidade SOAP. Isso significa que é impossível no módulo Codeception configurar isso em um arquivo yml para que ele possa trabalhar com vários.

A codecepção possui uma reconfiguração de módulo dinâmico e você pode gravar algum tipo de adaptador para receber, por exemplo, um módulo SOAP e reconfigurá-lo dinamicamente. Nesse caso, é necessário substituir o terminal e o esquema usado. Em seguida, no teste, se você precisar alterar o terminal para o qual deseja enviar uma solicitação, obtemos nosso adaptador e o alteramos para um novo terminal, para um novo circuito e enviamos uma solicitação para ele.

Em Codeception, não há trabalho com Kafka e não há complementos mais ou menos oficiais de terceiros para trabalhar com Kafka. Não há com o que se preocupar, escrevemos nosso módulo.

Portanto, ele está configurado em um arquivo yml. Algumas configurações são definidas para corretores, consumidores e tópicos. Essas configurações, quando você escreve seu módulo, pode puxá-lo para os módulos com a função de inicialização e inicializar este módulo com as mesmas configurações. E, de fato, o módulo possui todos os outros métodos para implementar - coloque a mensagem no tópico e leia-a. É tudo o que você precisa deste módulo.
 Conclusão
Conclusão : os módulos para codecepção são fáceis de escrever.
Vá em frente. Como eu disse, o Codeception possui um módulo Cli - um invólucro para comandos do
shell e trabalhando com sua saída.

Mas, às vezes, o comando
shell precisa ser executado não nos testes, mas no aplicativo. Em geral, testes e aplicativos são entidades ligeiramente diferentes, podem estar em lugares diferentes. Os testes podem ser executados em um local e o aplicativo em outro.
Então, por que precisamos executar o
shell nos testes?
Temos comandos em aplicativos que, por exemplo, analisam filas no RabbitMQ e movem objetos por status. Esses comandos no modo pro são iniciados no supervisor. O supervisor monitora sua implementação. Se eles caírem, ele os inicia novamente e assim por diante.
Quando testamos, o supervisor não está sendo executado. Caso contrário, os testes se tornam instáveis, imprevisíveis. Nós mesmos queremos controlar o lançamento desses comandos dentro do aplicativo. Portanto, precisamos executar esses comandos a partir dos testes no aplicativo. Nós usamos duas opções. Aquele, aquele outro - em princípio, tudo é o mesmo e tudo funciona.
Como executar um
shell em um aplicativo?
Primeiro: execute os testes no mesmo local em que o aplicativo está localizado. Como todos os aplicativos que temos no Docker, os testes podem ser executados no mesmo contêiner em que o serviço está localizado.
A segunda opção: faça um contêiner separado para testes, algum
executor de testes , mas faça o mesmo que o aplicativo. Ou seja, da mesma imagem do Docker e tudo funcionará da mesma maneira.

Outro problema que encontramos nos testes está trabalhando com vários sistemas de arquivos. Abaixo está um exemplo do que você pode e deve trabalhar. Os três primeiros são relevantes para nós. Estes são Webdav, SFTP e o sistema de arquivos da Amazon.
Com o que você precisa trabalhar?
- Webdav
- FTP / SFTP
- AWS S3
- Local
- Azure, Dropbox, Google Drive
Se você vasculhar o Codeception, poderá encontrar alguns módulos para quase qualquer sistema de arquivos mais ou menos popular.
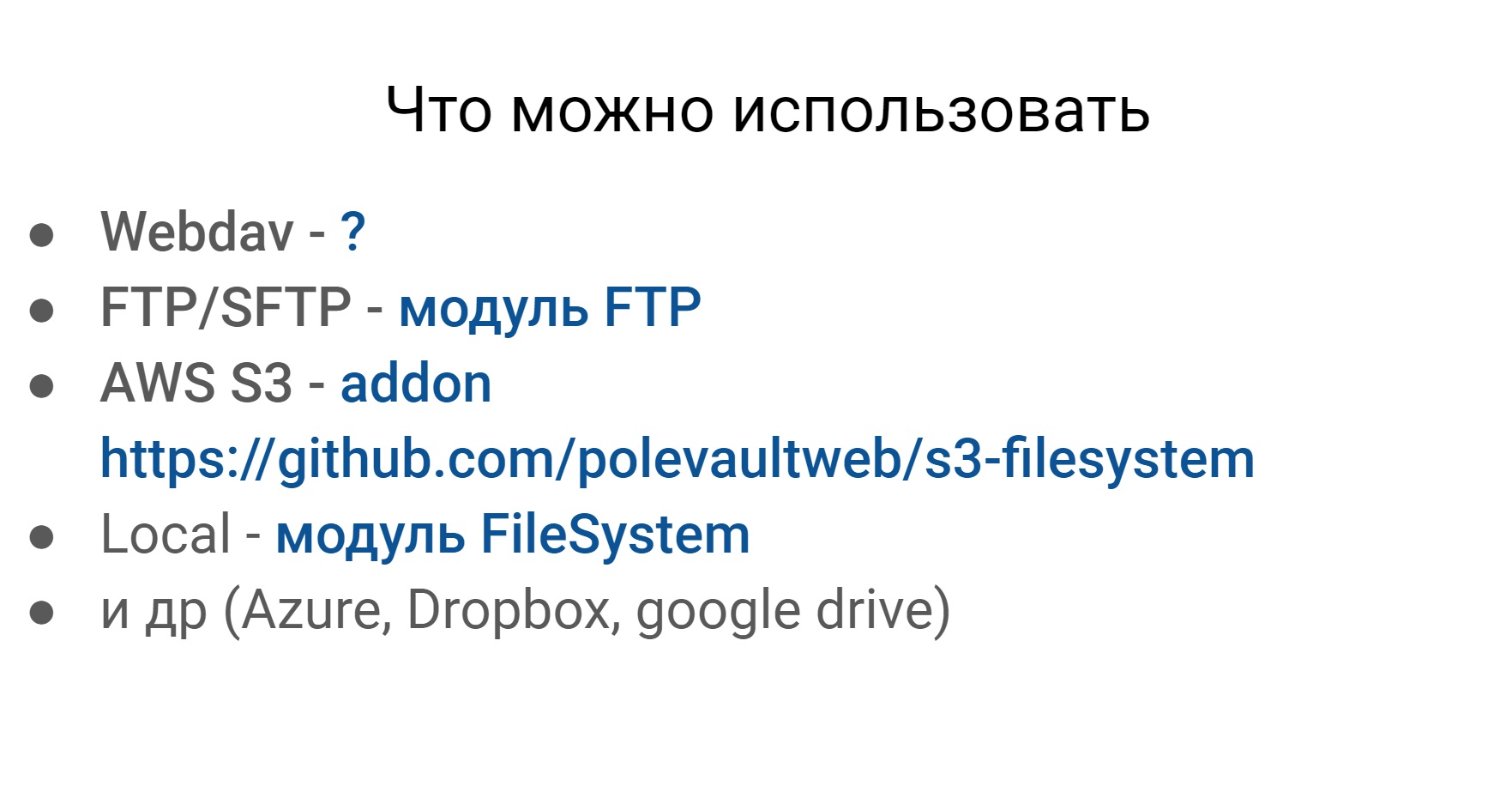
A única coisa que não encontrei é para o Webdav. Mas esses sistemas de arquivos, mais ou menos, são os mesmos em termos de trabalho externo com eles, e queremos trabalhar com eles da mesma maneira.
Nós escrevemos nosso módulo chamado Flysystem. Encontra-se no
Github em domínio público e suporta 2 sistemas de arquivos - SFTP e Webdav - e permite trabalhar com os dois usando a mesma API.

Obtenha uma lista de arquivos, limpe o diretório, escreva um arquivo e assim por diante. Se você também adicionar o sistema de arquivos da Amazon, nossas necessidades serão definitivamente atendidas.
O próximo ponto, eu acho, é muito importante para autotestes, especialmente no nível do sistema, para trabalhar com bancos de dados. Em geral, eu quero que seja, como na figura, - VZHUH e tudo inicia, funciona, e esses bancos de dados devem ter menos suporte nos testes.

Quais são as principais tarefas que eu vejo aqui:
- Como implantar o banco de dados da estrutura desejada - Db
- Como preencher o banco de dados com dados de teste
- Como fazer seleções e verificações - Db
Para todas as 3 tarefas em Codeception, existem 2 módulos - Db, sobre o qual eu já falei, outro é chamado Fixtures.
Desses 2 módulos e 3 tarefas, usamos apenas DB para a terceira tarefa.
Para a primeira tarefa, você pode usar o DB. Lá você pode configurar o dump SQL a partir do qual o banco de dados será implantado, bem, o módulo com dispositivos elétricos, acho que está claro por que é necessário.
Haverá acessórios na forma de matrizes que podem ser mantidas no banco de dados.
Como eu disse, nas 2 primeiras tarefas resolvemos um pouco diferente, agora vou lhe dizer como fazemos.
Implantação de banco de dados- Criando um contêiner com PostgreSQL ou MySQL
- Rolamos todas as migrações com migrações de doutrina
O primeiro é sobre a implantação de um banco de dados. Como isso acontece nos testes. Nós aumentamos o contêiner com o banco de dados desejado - PostgreSQL ou MySQL, depois rolamos todas as migrações necessárias usando as migrações de
doutrina . Tudo, o banco de dados da estrutura desejada está pronto, pode ser usado em testes.
Por que não usamos amortecedores - porque não precisa ser suportado. Esse é algum tipo de despejo que reside nos testes, que precisa ser constantemente atualizado se algo mudar no banco de dados. Existem migrações - não há necessidade de manter um despejo.
O segundo ponto é a criação de dados de teste. Não usamos o módulo Fixtures da Codeception, usamos o pacote
Symfony para fixtures.

Há um
link para ele e um exemplo de como você pode criar acessórios no banco de dados.
Seu equipamento será criado como um objeto do domínio, poderá ser armazenado no banco de dados e os dados de teste estarão prontos.
Por que DoctrineFixtureBundle?
- Mais fácil criar cadeias de objetos relacionados.
- Menos duplicação de dados se acessórios para testes diferentes forem semelhantes.
- Menos edições ao alterar a estrutura do banco de dados.
- As aulas de fixação são muito mais visuais que as matrizes.
Por que usamos? Sim, pelo mesmo motivo - esses equipamentos são muito mais fáceis de manter do que os da Codeception. É mais fácil criar cadeias de objetos relacionados, porque está tudo no pacote symfony. Menos dados precisam ser duplicados, porque os equipamentos podem ser herdados, são classes. Se a estrutura do banco de dados mudar, essas matrizes sempre precisam ser editadas e as classes nem sempre. As luminárias na forma de objetos de domínio são sempre mais visíveis que matrizes.
Nós conversamos sobre bancos de dados, vamos falar um pouco sobre moki.
Como esses são testes de nível suficientemente alto que testam todo o sistema e como nossos sistemas são altamente interconectados, fica claro que existem algumas trocas e interações. Agora vamos falar sobre mokeys na interação entre sistemas.
Regras para mok- Chorar todas as interações externas de serviço http
- Verificando não apenas cenários positivos, mas também negativos
Interações são algumas interações http REST ou SOAP. Todas essas interações dentro da estrutura dos testes que estamos molhando. Ou seja, em nossos testes não há apelo real para sistemas externos em nenhum lugar. Isso torna os testes estáveis. Porque um serviço externo pode funcionar, pode não funcionar, pode responder lentamente, pode rapidamente, em geral, não saber qual é o seu comportamento. Portanto, cobrimos tudo com moks.
Nós também temos essa regra. Estamos molhando não apenas interações positivas, mas também tentando verificar alguns casos negativos. Por exemplo, quando um serviço de terceiros responde com um erro 500 ou produz um erro mais significativo, tentamos verificar tudo.
Usamos o Wiremock para zombarias, o próprio Codeception suporta ..., ele tem um complemento oficial Httpmock, mas gostamos mais do Wiremock. Como isso funciona?
O Wiremock surge como um contêiner do Docker separado durante os testes e todas as solicitações que devem ser enviadas ao sistema externo vão para o Wiremock.
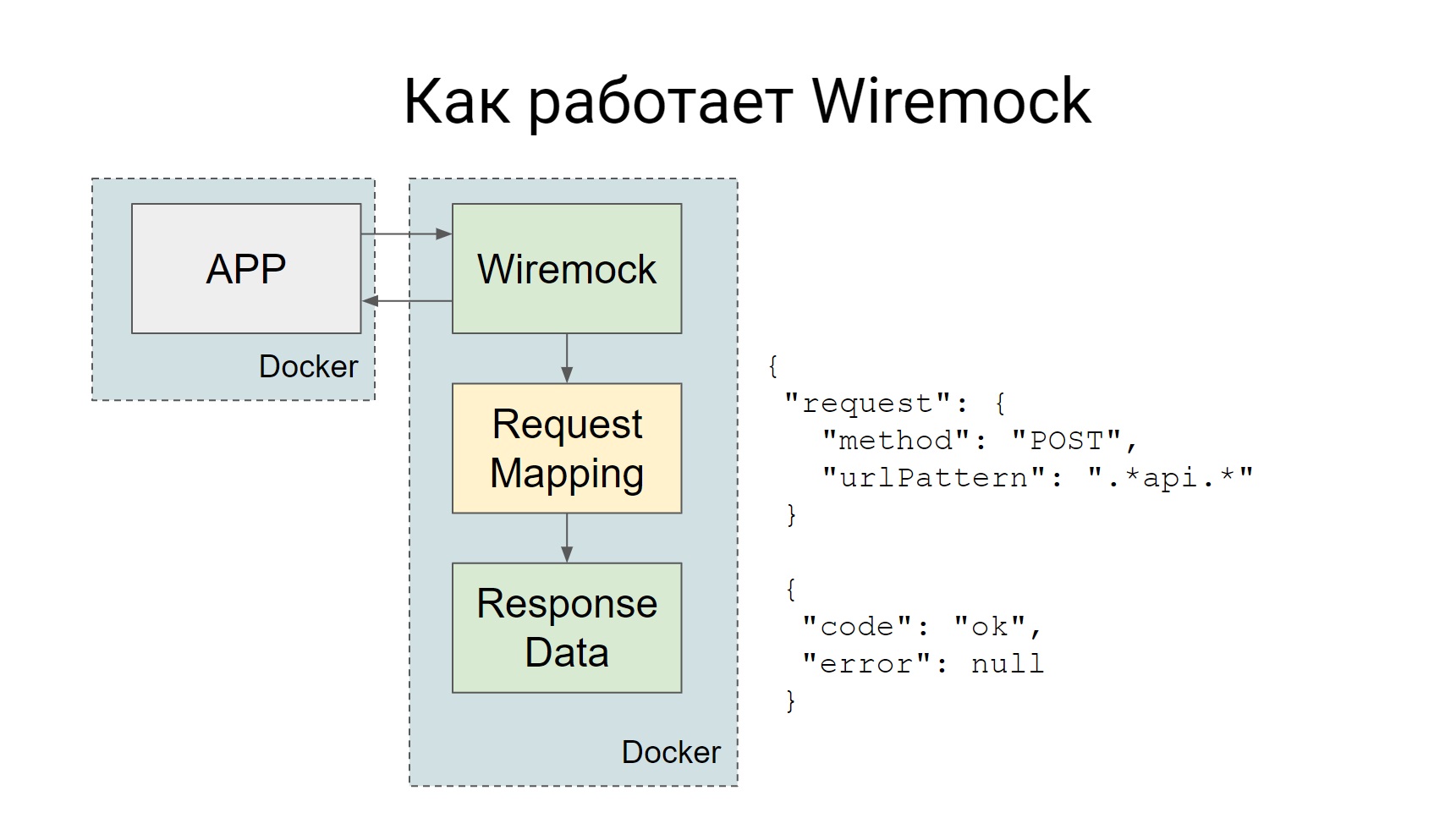
Wiremock, se você olhar para o slide - existe uma caixa, Mapeamento de Solicitações, que possui um conjunto de mapeamentos que afirmam que, se uma solicitação chegar, você precisará fornecer uma resposta. Tudo é muito simples: um pedido chegou - recebeu uma farsa.
As simulações podem ser criadas estaticamente e, em seguida, o contêiner, quando já estiver com a Wiremock, essas simulações estarão disponíveis e poderão ser usadas em testes manuais. Você pode criar dinamicamente, diretamente no código, em algum tipo de teste.
Aqui está um exemplo de como criar uma simulação dinamicamente, veja bem, a descrição é bastante declarativa, fica imediatamente claro a partir do código que tipo de simulação estamos criando: uma simulação para o método GET que chega a esse URL e, de fato, o que retornar.

Além do fato de que esse mock pode ser criado, a Wiremock tem a oportunidade de verificar qual solicitação foi enviada para esse mock. Isso também é muito útil em testes.
Sobre a codecepção em si, provavelmente, tudo, e algumas palavras sobre como nossos testes são executados, e um pouco de infraestrutura.
O que estamos usando?

Bem, primeiro, todos os serviços que temos no Docker, portanto, o lançamento de um ambiente de teste está aumentando os contêineres certos.
Make é usado para comandos internos, Bamboo é usado como IC.
Como é a execução do teste de IC?

Primeiro, criamos a versão desejada do aplicativo, depois aumentamos o ambiente - esse é o aplicativo, todos os serviços necessários, como Kafka, Rabbit, o banco de dados e rolamos a migração para o banco de dados.
Todo esse ambiente é criado com a ajuda do Docker Compose. É no CI, no prod que todos os contêineres giram sob o Kubernetes. Em seguida, execute os testes e execute.
Quanto tempo isso leva?
Tudo depende do serviço específico, mas, como regra, elevar o ambiente antes de executar os testes é de 5 a 10 minutos, testes - de 6 a 30 minutos.

Avisarei imediatamente essa pergunta enquanto todos os testes estiverem em um único thread.
Bem, essa pergunta. Com que frequência os testes devem ser executados? Obviamente, quanto mais frequentemente, melhor. Quanto mais cedo você conseguir detectar um problema, mais rápido poderá resolvê-lo.
2 . , , unit, unit-. - , .
, . .
- — , , Codeception, . , .