Oi
Você sabia que as plataformas de anúncios costumam copiar o conteúdo dos concorrentes para aumentar o número de anúncios que eles hospedam? Eles fazem assim: chamam vendedores e oferecem a instalação na plataforma. E, às vezes, eles copiam completamente os anúncios sem a permissão do usuário. Avito é um local popular, e muitas vezes encontramos uma concorrência desleal. Leia sobre como estamos combatendo esse fenômeno, leia abaixo.

O problema
A cópia do conteúdo do Avito para outras plataformas existe em várias categorias de bens e serviços. Este artigo se concentrará apenas em carros. Em um post anterior, falei sobre como ocultamos números automaticamente em carros.

Mas, a julgar pelos resultados de pesquisa de outras plataformas, lançamos esse recurso imediatamente em três sites de anúncios.

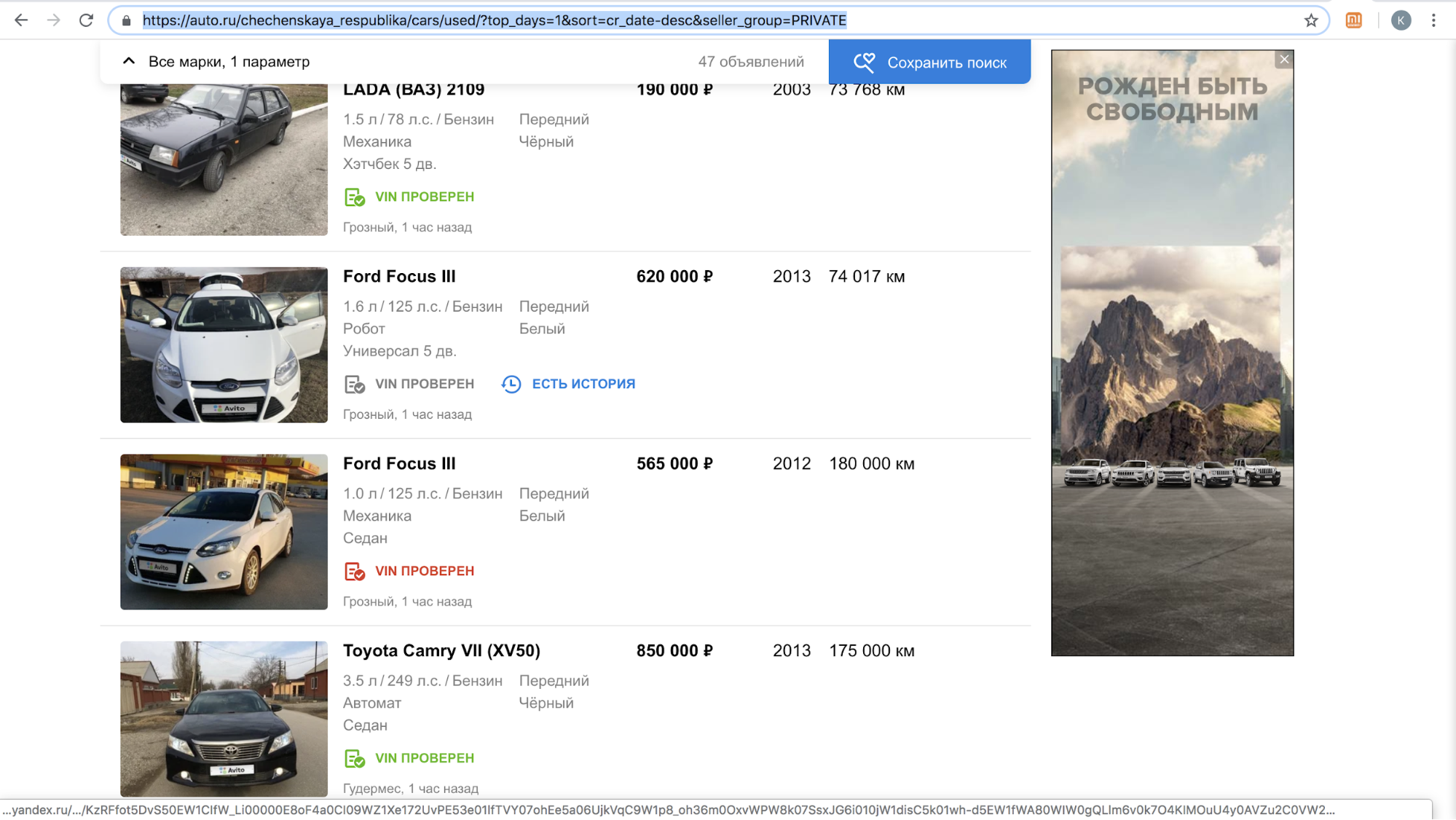
Após o lançamento de um recurso, um desses sites suspendeu temporariamente a chamada de nossos usuários com ofertas para copiar o anúncio em sua plataforma: havia muito conteúdo com o logotipo Avito em seu site, apenas em novembro de 2018, havia mais de 70.000 anúncios. Por exemplo, é assim que os resultados de suas pesquisas por dia na República Chechena se parecem.
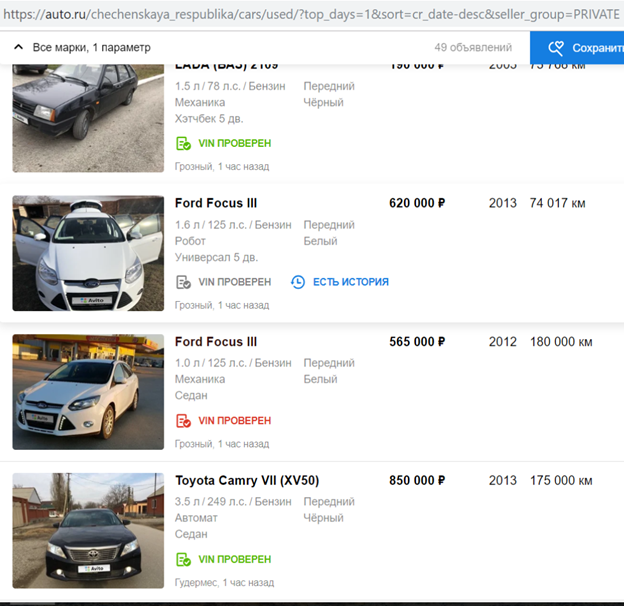
Depois de concluir seu algoritmo para ocultar placas de carros, para que ele detecte e feche automaticamente o logotipo Avito, eles retomaram o processo.

Do nosso ponto de vista, copiar o conteúdo dos concorrentes e usá-lo para fins comerciais é antiético e inaceitável. Recebemos reclamações de nossos usuários, descontentes com isso, em nosso suporte. E aqui está um exemplo de reação em uma das histórias.
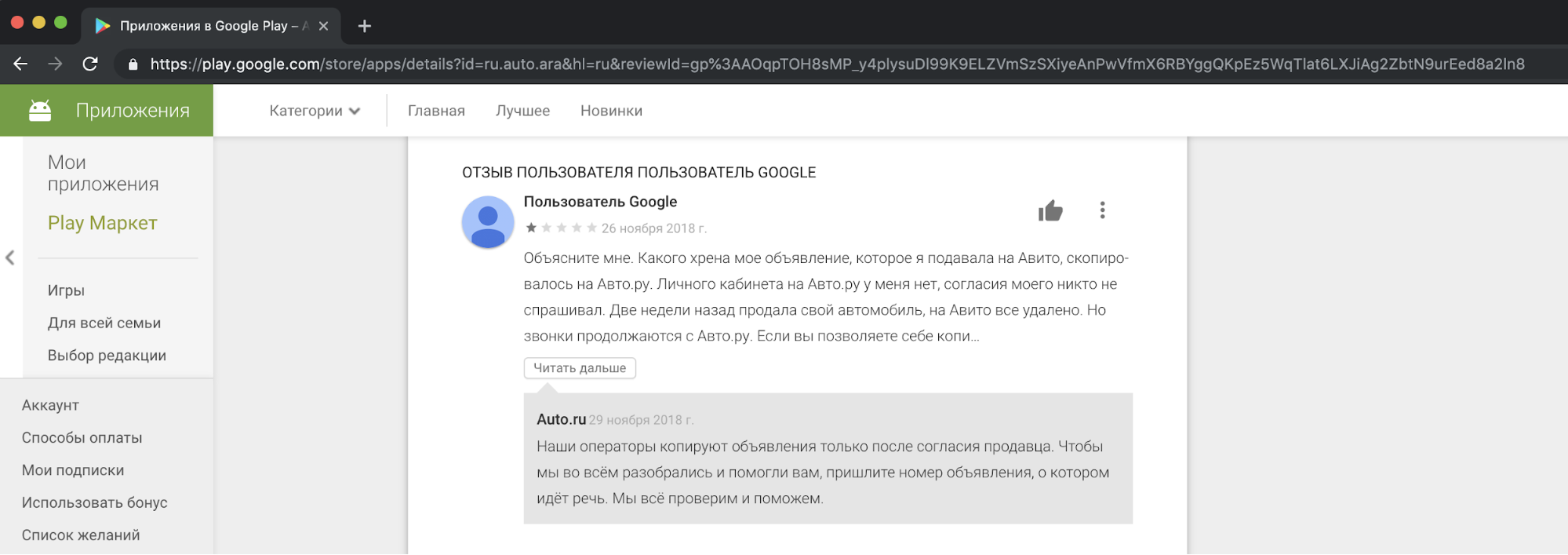
Devo dizer que o pedido de consentimento das pessoas para copiar anúncios não justifica tais ações. Isso é uma violação das leis "Sobre publicidade" e "Sobre dados pessoais", regras da Avito, direitos de marca registrada e banco de dados de anúncios.
Não conseguimos concordar pacificamente com um concorrente, mas não queríamos deixar a situação como está.
Maneiras de resolver o problema
O primeiro método é legal. Precedentes semelhantes já foram encontrados em outros países. Por exemplo, o conhecido classificador americano Craigslist apreendeu grandes quantias de dinheiro de sites que copiam conteúdo dele.
A segunda maneira de resolver o problema da cópia é adicionar uma marca d'água grande à imagem para que ela não possa ser cortada.
O terceiro método é tecnológico. Podemos complicar o processo de cópia de nosso conteúdo. É lógico supor que algum modelo esteja envolvido em ocultar o logotipo Avito dos concorrentes. Também é sabido que muitos modelos são propensos a "ataques" que os impedem de funcionar corretamente. Este artigo será sobre apenas eles.
Ataque adversário

Idealmente, o exemplo contraditório para a rede parece um ruído indistinguível pelo olho humano, mas, para o classificador, ele adiciona um sinal suficiente à classe que não está na imagem. Como resultado, uma imagem, por exemplo, com um panda, é classificada com alta confiança como gibão. A criação de ruído adversário é possível não apenas para redes de classificação de imagens, mas também para segmentação e detecção. Um exemplo interessante é um trabalho recente da Keen Labs: eles enganaram um piloto automático da Tesla com pontos na calçada e um detector de chuva, exibindo exatamente esse ruído adversário . Também existem ataques para outros domínios, por exemplo, o som: o conhecido ataque ao Amazon Alexa e outros assistentes de voz consistia em jogar em equipes indistinguíveis pelo ouvido humano (crackers ofereceram comprar algo na Amazon).
A criação de ruído contraditório para os modelos que analisam imagens é possível devido ao uso não padronizado do gradiente necessário para o treinamento do modelo. Normalmente, no método de propagação reversa de erros, usando o gradiente calculado da função objetivo, apenas os pesos das camadas da rede são alterados para que sejam menos confundidos com o conjunto de dados de treinamento. Assim como nas camadas de rede, você pode calcular o gradiente da função objetivo a partir da imagem de entrada e alterá-la. A alteração da imagem de entrada usando um gradiente foi usada para vários algoritmos conhecidos. Lembra do Deepdream ?

Se calcularmos iterativamente o gradiente da função objetivo a partir da imagem de entrada e adicionarmos esse gradiente a ela, mais informações sobre a classe predominante do ImageNet aparecerão na imagem: mais faces de cães aparecerão, devido ao qual o valor da função de perda diminui e o modelo se torna mais confiante na classe "cão". Por que o cachorro está no exemplo? Apenas no ImageNet de 1000 aulas - 120 aulas de cães . Uma abordagem semelhante à modificação da imagem foi usada no algoritmo de transferência de estilo, conhecido principalmente devido à aplicação Prisma.
Para criar um exemplo contraditório, você também pode usar o método iterativo de alterar a imagem de entrada.
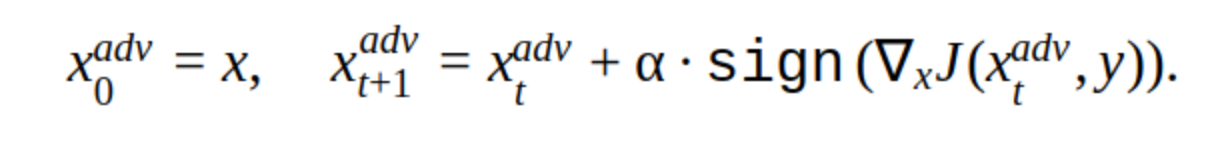
Existem várias modificações nesse método, mas a idéia básica é simples: a imagem original é deslocada iterativamente na direção do gradiente da perda da função classificadora J (porque apenas o sinal é usado) com a etapa α. 'y' é a classe representada na imagem para reduzir a confiança da rede na resposta correta. Esse ataque é chamado de não direcionado. Você pode escolher a etapa e o número ideais de iterações para que a alteração na imagem de entrada seja indistinguível da habitual para uma pessoa. Mas, do ponto de vista dos custos de tempo, esse ataque não nos convém. 5-10 iterações para uma imagem no prod são demoradas.
Uma alternativa aos métodos iterativos é o método FGSM.

Este é um método de disparo único, ou seja, Para usá-lo, você precisa calcular o gradiente da função de perda para a imagem de entrada uma vez e o ruído adversário está pronto para ser adicionado à imagem. Este método é obviamente mais produtivo. Pode ser usado na produção.
Criando exemplos contraditórios
Decidimos começar invadindo nosso próprio modelo.
Esta é a imagem que reduz a probabilidade de encontrar uma placa para o nosso modelo.

É evidente que este método tem uma desvantagem: as alterações adicionadas à imagem são visíveis aos olhos. Além disso, esse método não é direcionado, mas pode ser alterado para fazer um ataque direcionado. Em seguida, o modelo irá prever o local da placa em outro local. Este é o método T-FGSM.
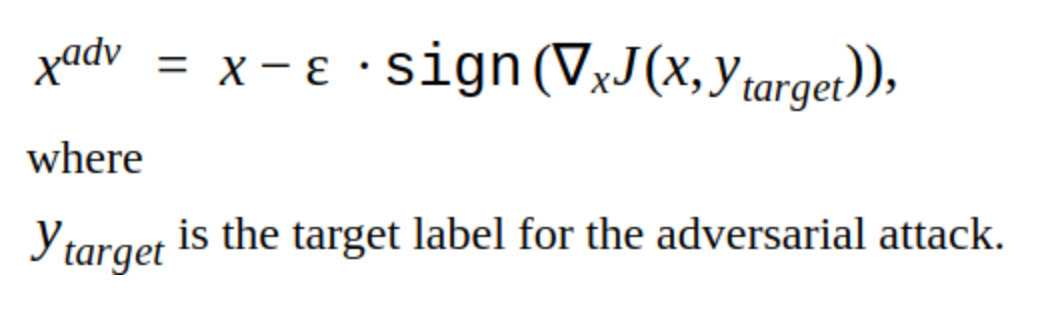
Para quebrar nosso modelo com esse método, você precisa alterar a imagem de entrada um pouco mais visivelmente.

Ainda não é possível afirmar que os resultados são ideais, mas pelo menos a eficiência dos métodos foi verificada. Também tentamos bibliotecas prontas para invadir redes Foolbox, CleverHans e ART-IBM, mas com a ajuda delas não foi possível interromper nossa rede para detecção. Os métodos dados são melhores para redes de classificação. Essa é uma tendência geral nos hackers de rede: é mais difícil tornar um ataque mais difícil para a detecção de objetos, especialmente quando se trata de modelos complexos, por exemplo, Mask RCNN.
Teste de ataque
Tudo o que foi descrito até agora não foi além de nossas experiências internas, mas foi necessário descobrir como testar ataques nos detectores de outras plataformas de anúncios.
Acontece que, ao solicitar uma das plataformas, a placa é detectada automaticamente, para que você possa fazer upload de fotos várias vezes e verificar como o algoritmo de detecção lida com o novo exemplo de adversário.
Isso é ótimo! Mas ...
Nenhum dos ataques que funcionou em nosso modelo funcionou ao testar em outra plataforma. Por que isso aconteceu? Isso é conseqüência das diferenças de modelos e da generalização de ataques adversos mal-intencionados em diferentes arquiteturas de rede. Devido à complexidade da reprodução dos ataques, eles são divididos em dois grupos: caixa branca e caixa preta.

Aqueles ataques que fizemos no nosso modelo - era uma caixa branca. O que precisamos é de uma caixa preta com restrições adicionais à inferência: não há API, tudo o que você pode fazer é enviar manualmente fotos e verificar ataques. Se houvesse uma API, você poderia criar um modelo substituto.

A idéia é criar um conjunto de dados de imagens de entrada e respostas do modelo de caixa preta, no qual você possa treinar vários modelos de arquiteturas diferentes, para aproximar o modelo de caixa preta. Em seguida, você pode realizar um ataque de caixa branca nesses modelos e é mais provável que funcionem em uma caixa preta. No nosso caso, isso implica muito trabalho manual, portanto essa opção não nos convinha.
Quebrando o impasse
Em busca de trabalhos interessantes sobre o tema de ataques de caixas pretas, foi encontrado um artigo ShapeShifter: Ataque Adversário Físico Robusto no Detector de Objetos R-CNN mais Rápido
Os autores do artigo fizeram ataques à detecção de objetos em uma rede de máquinas autônomas, adicionando iterativamente outras imagens que não a classe verdadeira ao plano de fundo do sinal de parada.


Tal ataque é claramente visível ao olho humano, no entanto, interrompe com êxito o trabalho da rede de detecção de objetos, que é o que precisamos. Portanto, decidimos negligenciar a invisibilidade desejada do ataque em prol da capacidade de trabalho.
Queríamos verificar quanto o modelo de detecção é treinado novamente, ele usa informações sobre o carro ou é apenas a placa Avito que é necessária?
Para fazer isso, criou a seguinte imagem:

Fizemos o upload como uma máquina para uma plataforma de anúncios com um modelo de caixa preta. Recebido:

Isso significa que você só pode alterar a placa Avito, o restante das informações na imagem de entrada não é necessário para a detecção do modelo da caixa preta.
Após várias tentativas, surgiu a idéia de adicionar à placa Avito o ruído adverso obtido pelo método FGSM, que quebrou nosso próprio modelo, mas com um coeficiente ε bastante grande. Aconteceu assim:

De carro, fica assim:

Carregamos uma foto na plataforma com um modelo de caixa preta. O resultado foi bem sucedido.

Aplicando esse método a várias outras fotos, descobrimos que ele não funciona com frequência. Depois de várias tentativas, decidimos nos concentrar na outra parte mais visível da questão - a fronteira. Sabe-se que as camadas convolucionais iniciais da rede têm ativações em objetos simples como linhas, ângulos. Ao "romper" a linha de fronteira, podemos impedir que a rede detecte corretamente a área do número. Isso pode ser feito, por exemplo, adicionando ruído na forma de quadrados brancos de tamanho aleatório por toda a borda da sala.

Ao fazer o upload dessa imagem para uma plataforma com um modelo de caixa preta, obtivemos um exemplo adversário bem-sucedido.

Tendo tentado essa abordagem em um conjunto de outras fotos, descobrimos que o modelo da caixa preta não pode mais detectar a placa Avito (o conjunto foi montado manualmente, há menos de cem fotos e, é claro, não é representativo, mas leva muito tempo para fazer mais). Uma observação interessante: o ataque é bem-sucedido apenas ao combinar ruído nas letras Avito e quadrados brancos aleatórios em um quadro, o uso desses métodos separadamente não produz um resultado bem-sucedido.
Como resultado, lançamos esse algoritmo no produto, e aqui está o que saiu dele :)
Vários anúncios encontrados


Algo mais fresco:
Chegamos até à plataforma de publicidade:
Total
Como resultado, conseguimos fazer um ataque adversário, o que em nossa implementação não aumenta o tempo de processamento da imagem. O tempo que gastamos na criação do ataque é de duas semanas antes do Ano Novo. Se não fosse possível fazê-lo durante esse período, eles teriam colocado uma marca d'água. Agora a matrícula do adversário está desativada, porque agora um concorrente liga para os usuários, oferece a eles que eles mesmos enviem fotos para o anúncio ou substituam fotos do carro por fotos da Internet.