Olá Habr! Apresento a você a tradução do artigo " Classificação da cobertura da terra com o e-learn: Parte 1 ", de Matic Lubej.
Parte 2
Parte 3
Prefácio
Cerca de seis meses atrás, o primeiro commit foi feito no repositório eo-learn no GitHub. Hoje, o eo-learn evoluiu para uma maravilhosa biblioteca de código aberto, pronta para ser usada por qualquer pessoa interessada em dados de OE (Observação da Terra - etc.). Todos na equipe do Sinergise aguardavam o momento da transição do estágio de construção das ferramentas necessárias para o estágio de uso para o aprendizado de máquina. É hora de apresentar uma série de artigos sobre a classificação da cobertura do solo usando o eo-learn
eo-learn é uma biblioteca Python de código aberto que atua como uma ponte que conecta a Observação da Terra / Sensoriamento Remoto ao ecossistema das bibliotecas de aprendizado de máquina Python. Já escrevemos um post separado em nosso blog , que recomendamos que você se familiarize. A biblioteca usa primitivas das bibliotecas numpy e shapely para armazenar e manipular dados de satélites. No momento, ele está disponível no repositório GitHub e a documentação está disponível no link apropriado para ReadTheDocs .

Imagem de satélite Sentinel-2 e máscara NDVI de uma pequena área na Eslovênia no inverno
Para demonstrar as capacidades do eo-learn , decidimos usar nosso transportador multitemporal para classificar a cobertura do território da República da Eslovênia (o país em que vivemos), usando dados para 2017. Como o procedimento completo pode ser muito complicado para um artigo, decidimos dividi-lo em três partes. Graças a isso, não há necessidade de pular as etapas e prosseguir imediatamente para o aprendizado de máquina - primeiro precisamos entender realmente os dados com os quais trabalhamos. Cada artigo será acompanhado por um exemplo do Jupyter Notebook. Além disso, para os interessados, já preparamos um exemplo completo que abrange todas as etapas.
- No primeiro artigo, orientaremos você no procedimento de seleção / divisão de uma área de interesse (doravante - AOI, área de interesse) e a obtenção das informações necessárias, como dados de sensores de satélite e máscaras de nuvem. Também mostramos um exemplo de como criar uma máscara raster de dados na cobertura real de um território a partir de dados vetoriais. Todos estes são passos necessários para obter um resultado confiável.
- Na segunda parte, mergulhamos de cabeça na preparação de dados para o procedimento de aprendizado de máquina. Esse processo inclui a coleta de amostras aleatórias para treinamento / validação de pixels, remoção de imagens em nuvem, interpolação de dados temporais para preencher “buracos” etc.
- Na terceira parte, consideraremos o treinamento e a validação do classificador, bem como, é claro, belos gráficos!

Imagem de satélite Sentinel-2 e máscara NDVI de uma pequena área na Eslovênia no verão
Área de interesse? Escolha!
A biblioteca eo-learn permite dividir a AOI em pequenos fragmentos que podem ser processados em condições de recursos computacionais limitados. Neste exemplo, a borda eslovena foi retirada da Terra natural , no entanto, você pode selecionar uma zona de qualquer tamanho. Também adicionamos um buffer à borda, após o qual a dimensão AOI era de aproximadamente 250x170 km. Usando a magia de geopandas e bibliotecas shapely , criamos uma ferramenta para quebrar a AOI. Nesse caso, dividimos o território em quadrados de 25x17 do mesmo tamanho e, como resultado, recebemos ~ 300 fragmentos de 1000x1000 pixels, em uma resolução de 10m. A decisão sobre a divisão em fragmentos é tomada dependendo do poder de computação disponível. Como resultado desta etapa, obtemos uma lista de quadrados que cobrem a AOI.

AOI (território da Eslovênia) é dividido em pequenos quadrados com um tamanho de aproximadamente 1000x1000 pixels em uma resolução de 10m.
Recebendo dados de satélites do Sentinel
Após determinar os quadrados, o eo-learn permite fazer o download automático de dados dos satélites do Sentinel. Neste exemplo, obtemos todas as imagens do Sentinel-2 L1C tiradas em 2017. Vale ressaltar que os produtos Sentinel-2 L2A, bem como fontes de dados adicionais (Landsat-8, Sentinel-1) podem ser adicionadas ao pipeline de maneira semelhante. Também é importante notar que o uso de produtos L2A pode melhorar os resultados da classificação, mas decidimos usar o L1C para a versatilidade da solução. Isso foi feito usando o sentinelhub-py , uma biblioteca que funciona como um wrapper nos serviços do Sentinel-Hub. O uso desses serviços é gratuito para institutos de pesquisa e empresas iniciantes, mas em outros casos é necessário se inscrever.

Imagens coloridas de um fragmento em dias diferentes. Algumas imagens estão nubladas, o que significa que um detector de nuvem é necessário.
Além dos dados do Sentinel, o eo-learn permite acessar de forma transparente os dados de probabilidade em nuvem e em nuvem, graças à biblioteca s2cloudless . Esta biblioteca fornece ferramentas para detectar automaticamente nuvens pixel por pixel . Os detalhes podem ser lidos aqui .
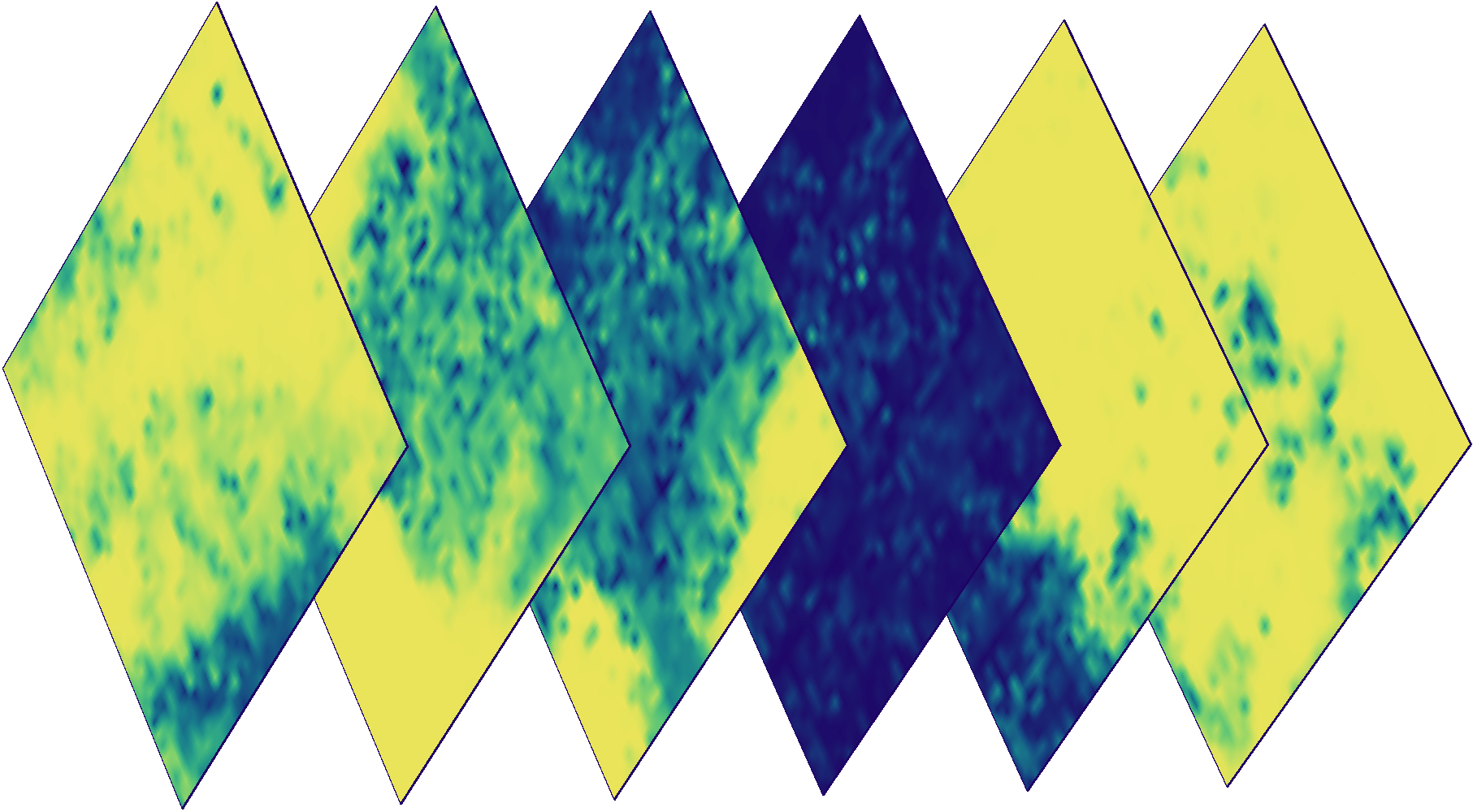
Máscaras em nuvem para as imagens acima. A cor indica a probabilidade de nebulosidade de um pixel específico (azul - baixa probabilidade, amarelo - alto).
Adicionando dados reais
Ensinar com um professor exige um cartão com dados reais ou verdade . O último termo não deve ser tomado literalmente, porque, na realidade, os dados são apenas uma aproximação do que está na superfície. Infelizmente, o comportamento do classificador depende fortemente da qualidade desta placa ( no entanto, como na maioria das outras tarefas de aprendizado de máquina ). Os mapas rotulados geralmente estão disponíveis como dados vetoriais no formato shapefile (por exemplo, fornecidos pelo estado ou pela comunidade ). eo-learn contém ferramentas para rasterizar dados vetoriais na forma de uma máscara raster.

O processo de rasterizar dados em máscaras usando o exemplo de um quadrado. Os polígonos em um arquivo vetorial são mostrados na imagem à esquerda, as máscaras de varredura para cada etiqueta são mostradas no meio - as cores preto e branco indicam a presença e a ausência de um atributo específico, respectivamente. A imagem à direita mostra uma máscara de varredura combinada, na qual cores diferentes indicam rótulos diferentes.
Juntando tudo
Todas essas tarefas se comportam como blocos de construção que podem ser combinados em uma sequência conveniente de ações executadas para cada quadrado. Devido ao número potencialmente extremamente grande desses fragmentos, a automação de pipeline é absolutamente necessária
Conhecer os dados reais é o primeiro passo para trabalhar com tarefas desse tipo. Usando máscaras de nuvem combinadas com dados do Sentinel-2, você pode determinar o número de observações de qualidade de todos os pixels, bem como a probabilidade média de nuvens em uma área específica. Graças a isso, você pode entender melhor os dados existentes e usá-los ao depurar outros problemas.

Imagem colorida (esquerda), máscara do número de medições de qualidade para 2017 (centro) e probabilidade média de cobertura de nuvens para 2017 (direita) para um fragmento aleatório da AOI.
Alguém pode estar interessado no NDVI médio para uma zona arbitrária, ignorando as nuvens. Usando máscaras de nuvem, você pode calcular o valor médio de qualquer recurso, ignorando pixels sem dados. Assim, graças às máscaras, podemos limpar imagens de ruído para quase qualquer recurso em nossos dados.
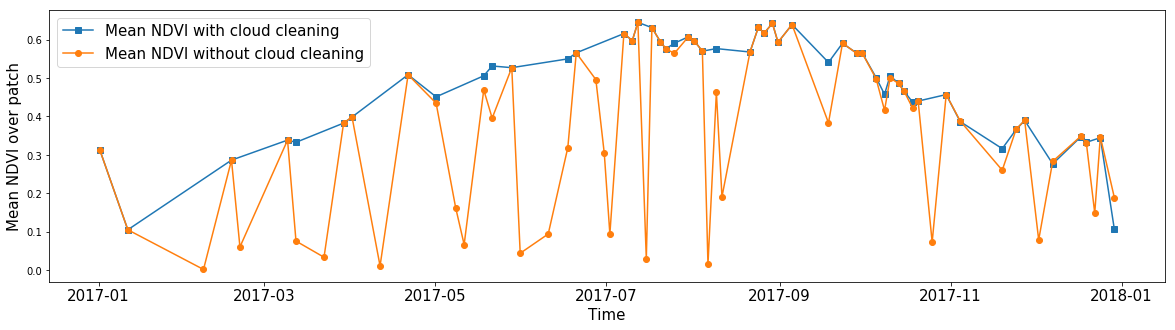
O NDVI médio de todos os pixels em um fragmento AOI aleatório ao longo do ano. A linha azul mostra o resultado do cálculo obtido se ignorar os valores dentro das nuvens. A linha laranja mostra o valor médio quando todos os pixels são levados em consideração.
"Mas e a escala?"
Depois de configurar nosso transportador usando o exemplo de um fragmento, tudo o que precisa ser feito é iniciar um procedimento semelhante para todos os fragmentos automaticamente (em paralelo, se os recursos permitirem), enquanto você relaxa com uma xícara de café e pensa no tamanho do chefe que ficará surpreso os resultados do seu trabalho. Após o final do pipeline, você pode exportar os dados em que está interessado em uma única imagem no formato GeoTIFF. O script gdal_merge.py recebe as imagens e as combina, resultando em uma imagem que cobre todo o país.
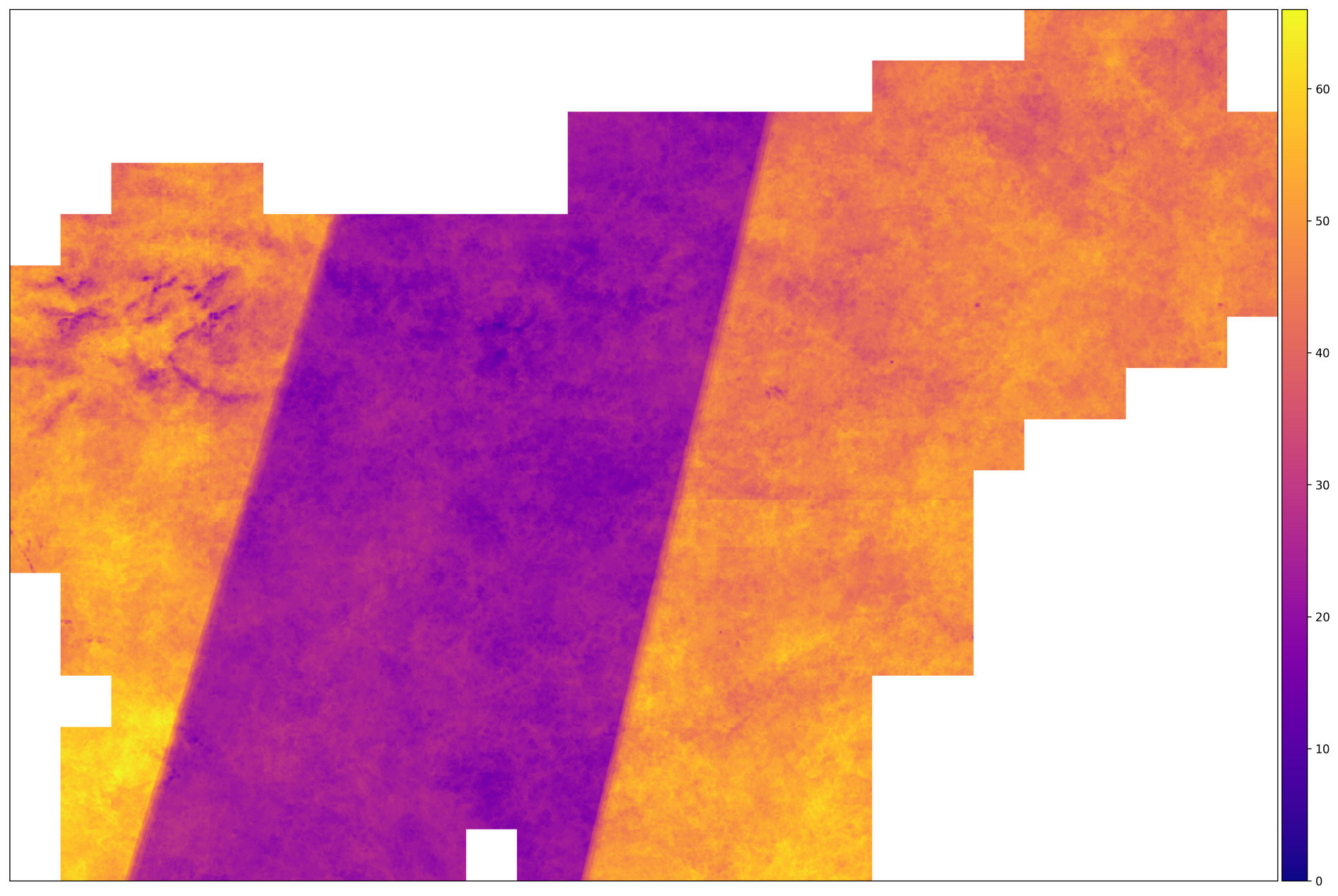
O número de disparos corretos para a AOI em 2017. As regiões com um grande número de imagens estão localizadas no território onde a trajetória dos satélites Sentinel-2A e Sentinel-2B se cruzam. No meio disso não acontece.
A partir da imagem acima, podemos concluir que os dados de entrada são heterogêneos - para alguns fragmentos, o número de imagens é duas vezes maior que em outros. Isso significa que precisamos tomar medidas para normalizar os dados - como interpolação ao longo do eixo do tempo.
A execução do pipeline especificado leva aproximadamente 140 segundos para um fragmento, o que totaliza aproximadamente 12 horas ao iniciar o processo em toda a AOI. A maior parte desse tempo está baixando dados de satélite. O fragmento médio não compactado com a configuração descrita leva cerca de 3 GB, o que no total fornece ~ 1 TB de espaço para toda a AOI.
Exemplo em um notebook Jupyter
Para uma introdução mais simples ao código eo-learn , preparamos um exemplo que cobre os tópicos discutidos neste post. O exemplo foi projetado como um bloco de notas Jupyter e você pode encontrá-lo no diretório de exemplos do pacote eo-learn .