Todos os dias, dezenas de milhares de funcionários de milhares de organizações em todo o mundo trabalham na Pyrus. Consideramos a capacidade de resposta do serviço (a velocidade de processamento de solicitações) uma importante vantagem competitiva, pois afeta diretamente a experiência do usuário. A principal métrica para nós é a "porcentagem de consultas lentas". Estudando seu comportamento, notamos que, a cada minuto, nos servidores de aplicativos, ocorrem pausas de cerca de 1000 ms. Nesses intervalos, o servidor não responde e surge uma fila de várias dezenas de solicitações. A busca pelas causas e a eliminação de gargalos causados pela coleta de lixo no aplicativo serão discutidas neste artigo.

Linguagens de programação modernas podem ser divididas em dois grupos. Em linguagens como C / C ++ ou Rust, o gerenciamento manual de memória é usado, para que os programadores passem mais tempo escrevendo código, gerenciando a vida útil dos objetos e depois depurando. Ao mesmo tempo, os bugs devido ao uso inadequado da memória são alguns dos mais difíceis de depurar, portanto, o desenvolvimento mais moderno é realizado em linguagens com gerenciamento automático de memória. Isso inclui, por exemplo, Java, C #, Python, Ruby, Go, PHP, JavaScript etc. Os programadores economizam tempo de desenvolvimento, mas você precisa pagar um tempo de execução extra que o programa gasta regularmente na coleta de lixo - liberando memória ocupada por objetos para os quais não há links restantes no programa. Em pequenos programas, esse tempo é insignificante, mas à medida que o número de objetos aumenta e a intensidade de sua criação, a coleta de lixo começa a dar uma contribuição notável para o tempo total de execução do programa.
Os servidores da Web Pyrus são executados na plataforma .NET, que usa o gerenciamento automático de memória. A maioria das coletas de lixo é 'para o mundo', ou seja, no momento do trabalho, eles param todos os threads do aplicativo. Assemblies sem bloqueio (em segundo plano) também interrompem todos os threads, mas por um período muito curto. Durante o bloqueio do encadeamento, o servidor não processa solicitações, as solicitações existentes congelam, novas são adicionadas à fila. Como resultado, as solicitações que foram processadas no momento da coleta de lixo são diretamente mais lentas e as solicitações são processadas mais lentamente imediatamente após a coleta de lixo ser concluída devido às filas acumuladas. Isso piora a métrica "porcentagem de consultas lentas".
Armado com o livro recentemente publicado
Konrad Kokosa: Pro .NET Memory Management (sobre como trouxemos sua primeira cópia para a Rússia em 2 dias, você pode escrever uma postagem separada), totalmente dedicado ao tópico de gerenciamento de memória no .NET, começamos a estudar o problema.
Medição
Para criar um perfil do servidor da Web Pyrus, usamos o utilitário PerfView (
https://github.com/Microsoft/perfview ), aprimorado para criar perfis de aplicativos .NET. O utilitário é baseado no mecanismo ETW (Event Tracing for Windows) e tem um impacto mínimo no desempenho do aplicativo com perfil, o que permite que ele seja usado em um servidor de combate. Além disso, o impacto no desempenho depende de que tipos de eventos e de quais informações coletamos. Não coletamos nada - o aplicativo funciona normalmente. Além disso, o PerfView não requer recompilação ou reinicialização do aplicativo.
Execute o rastreamento PerfView com o parâmetro / GCCollectOnly (tempo de rastreamento 1,5 horas). Nesse modo, ele coleta apenas eventos de coleta de lixo e tem um impacto mínimo no desempenho. Vejamos o relatório de rastreamento Memory Group / GCStats e nele um resumo dos eventos do coletor de lixo:
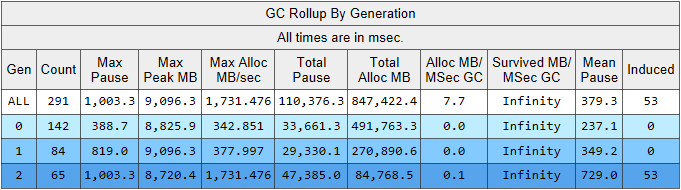
Aqui vemos vários indicadores interessantes ao mesmo tempo:
- O tempo médio de pausa na construção na 2ª geração é de 700 milissegundos e a pausa máxima é de cerca de um segundo. Esta figura mostra a hora em que todos os threads no aplicativo .NET param, em particular, essa pausa será adicionada a todas as solicitações processadas.
- O número de montagens da 2ª geração é comparável à 1ª geração e é um pouco menor que o número de montagens da 0ª geração.
- A coluna Induzido lista 53 montagens na 2ª geração. Montagem induzida é o resultado de uma chamada explícita para GC.Collect (). Em nosso código, não encontramos uma única chamada para esse método, o que significa que algumas das bibliotecas usadas por nosso aplicativo são as culpadas.
Vamos explicar a observação sobre o número de coletas de lixo. A idéia de dividir objetos pela vida útil é baseada na
hipótese geracional : uma parte significativa dos objetos criados morre rapidamente e a maior parte do resto dura muito tempo (em outras palavras, poucos objetos com vida útil "média"). É nesse modo que o coletor de lixo .NET é aprisionado e, nesse modo, os assemblies de segunda geração devem ser muito menores que a geração 0. Ou seja, para a operação ideal do coletor de lixo, devemos adaptar o trabalho de nossa aplicação à hipótese geracional. Vamos formular a regra da seguinte maneira: os objetos devem morrer rapidamente, sem sobreviver à geração mais velha, ou viver para ela e viver lá para sempre. Esta regra também se aplica a outras plataformas que usam gerenciamento automático de memória com separação de gerações, como Java.
Os dados que nos interessam podem ser extraídos de outra tabela no relatório GCStats:

Aqui estão alguns casos em que um aplicativo tenta criar um objeto grande (nos objetos do .NET Framework> 85.000 bytes de tamanho são criados no LOH - Large Object Heap) e precisa aguardar a conclusão do assembly de 2ª geração, que ocorre paralelamente em segundo plano. Essas pausas do alocador não são tão críticas quanto as pausas do coletor de lixo, pois afetam apenas um encadeamento. Antes disso, usamos a versão do .NET Framework 4.6.1 e, na versão 4.7.1, a Microsoft finalizou o coletor de lixo, agora permite alocar memória no Large Object Heap durante a compilação em segundo plano da segunda geração:
https://docs.microsoft.com / ru-ru / dotnet / framework / whats-new / # common-language-runtime-clrPortanto, atualizamos para a versão mais recente 4.7.2 naquele momento.
Construções de 2ª Geração
Por que temos tantas construções da geração mais antiga? A primeira suposição é que temos um vazamento de memória. Para testar esta hipótese, vamos dar uma olhada no tamanho da segunda geração (configuramos o monitoramento dos contadores de desempenho correspondentes no Zabbix). A partir dos gráficos do tamanho da 2ª geração para 2 servidores Pyrus, pode-se ver que o tamanho aumenta primeiro (principalmente devido ao preenchimento de caches), mas depois se estabiliza (grandes falhas no gráfico - reinício regular do serviço da web para atualizar a versão):
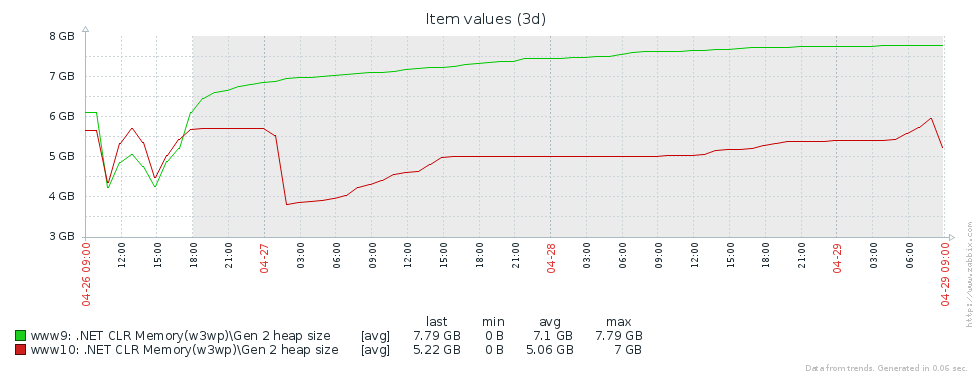
Isso significa que não há vazamentos de memória perceptíveis, ou seja, um grande número de assemblies de segunda geração ocorre por outro motivo. A próxima hipótese é que há muito tráfego de memória, ou seja, muitos objetos caem na 2ª geração e muitos objetos morrem lá. O PerfView possui um modo / GCOnly para encontrar esses objetos. Nos relatórios de rastreio, vamos prestar atenção às 'Pilhas de mortes por objetos da geração 2 (amostragem grossa)', que contêm uma seleção de objetos que morrem na 2ª geração, juntamente com pilhas de chamadas dos locais onde esses objetos foram criados. Aqui vemos os seguintes resultados:
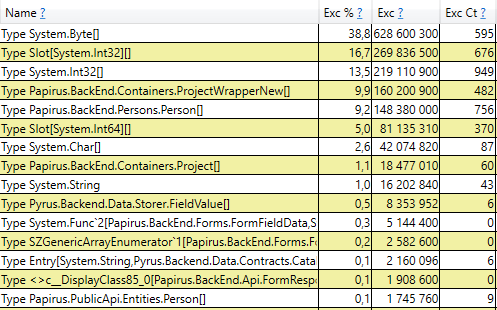
Após abrir a linha, no interior vemos uma pilha de chamadas desses lugares no código que criam objetos que vivem até a 2ª geração. Entre eles estão:
- System.Byte [] Se você olhar para dentro, veremos que mais da metade são buffers para serialização no JSON:
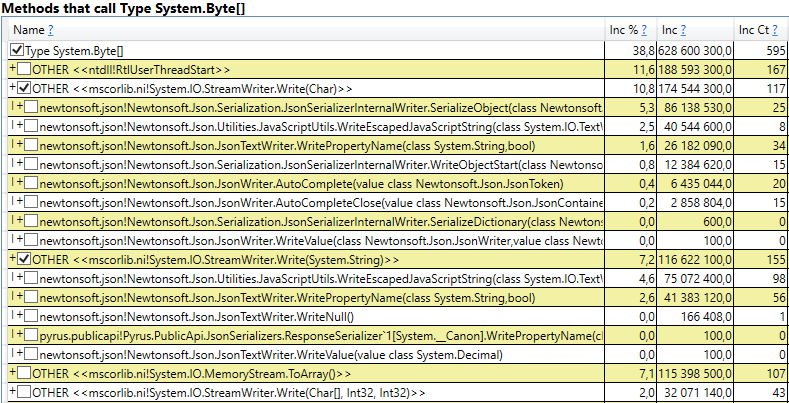
- Slot [System.Int32] [] (isso faz parte da implementação do HashSet), System.Int32 [] etc. Este é o nosso código que calcula caches de clientes - os diretórios, formulários, listas, amigos etc. que este usuário vê e que são armazenados em cache em seu navegador ou aplicativo móvel:

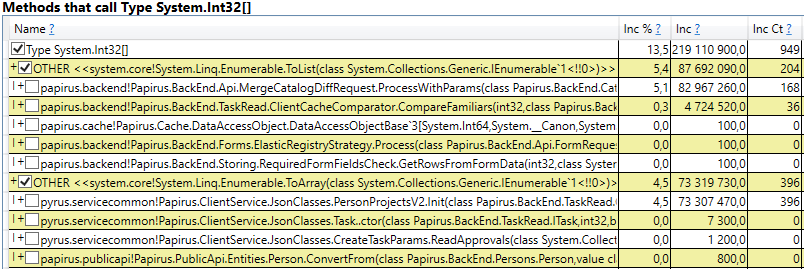
Curiosamente, os buffers para JSON e para calcular caches de clientes são todos objetos temporários que vivem na mesma solicitação. Por que eles vivem de acordo com a 2ª geração? Observe que todos esses objetos são matrizes de tamanho bastante grande. E em um tamanho> 85000 bytes, a memória para eles é alocada no Large Object Heap, que é coletado apenas em conjunto com a 2ª geração.
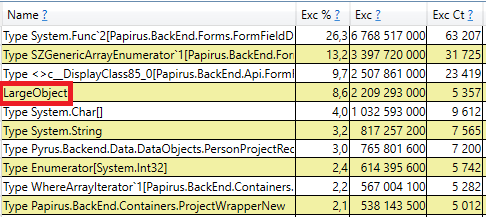
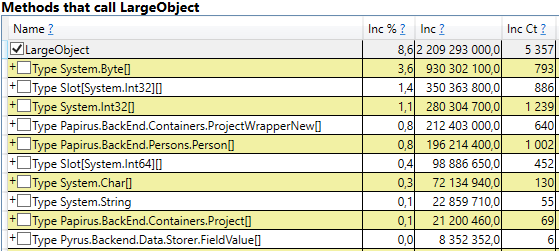
Para verificar, abra a seção 'Alocação de heap de GC ignora pilhas gratuitas (amostragem grossa)' nos resultados do perfview / GCOnly. Lá vemos a linha LargeObject, na qual o PerfView agrupa a criação de objetos grandes, e dentro vemos as mesmas matrizes que vimos na análise anterior. Reconhecemos a causa raiz dos problemas com o coletor de lixo: criamos muitos objetos grandes temporários.
Alterações no sistema Pyrus
Com base nos resultados da medição, identificamos as principais áreas de trabalho adicional: a luta contra objetos grandes ao calcular caches de clientes e serialização em JSON. Existem várias soluções para esse problema:
- A coisa mais simples é não criar objetos grandes. Por exemplo, se o buffer grande B for usado nas transformações sequenciais de dados A-> B-> C, algumas vezes essas transformações poderão ser combinadas, transformando-as em A-> C e eliminando a criação do objeto B. Essa opção nem sempre é aplicável, mas o mais simples e mais eficaz.
- Pool de objetos. Em vez de criar constantemente novos objetos e jogá-los fora, carregando o coletor de lixo, podemos armazenar uma coleção de objetos gratuitos. No caso mais simples, quando precisamos de um novo objeto, o retiramos do pool ou criamos um novo se o pool estiver vazio. Quando não precisamos mais do objeto, devolvemo-lo à piscina. Um bom exemplo é o ArrayPool no .NET Core, que também está disponível no .NET Framework como parte do pacote System.Buffers Nuget.
- Use objetos pequenos em vez de objetos grandes.
Vamos considerar separadamente os dois casos de objetos grandes - computando caches de clientes e serializando em JSON.
Cálculo do cache do cliente
O cliente da Web Pyrus e os aplicativos móveis armazenam em cache os dados disponíveis para o usuário (projetos, formulários, usuários, etc.) O cache é usado para acelerar o trabalho, também é necessário para trabalhar no modo offline. Os caches são calculados no servidor e transferidos para o cliente. Eles são individuais para cada usuário, pois dependem de seus direitos de acesso e geralmente são atualizados, por exemplo, ao alterar diretórios aos quais ele tem acesso.
Portanto, muitos cálculos de cache do cliente são realizados regularmente no servidor e muitos objetos temporários de vida curta são criados. Se o usuário for uma organização grande, ele poderá acessar muitos objetos, respectivamente, os caches do cliente para ele serão grandes. Por isso, vimos a alocação de memória para grandes matrizes temporárias no Large Object Heap.
Vamos analisar as opções propostas para se livrar da criação de objetos grandes:
- Descarte completo de objetos grandes. Essa abordagem não é aplicável, pois os algoritmos de preparação de dados usam, entre outras coisas, classificação e união de conjuntos e requerem buffers temporários.
- Usando um pool de objetos. Essa abordagem tem dificuldades:
- A variedade de coleções usadas e os tipos de elementos nelas: HashSet, List e Array são usados (os dois últimos podem ser combinados). Int32, Int64, bem como todos os tipos de classes de dados são armazenados em coleções. Para cada tipo usado, você precisará de seu próprio pool, que também armazenará coleções de tamanhos diferentes.
- Tempo de vida difícil das coleções. Para obter benefícios do pool, os objetos nele deverão ser devolvidos após o uso. Isso pode ser feito se o objeto for usado em um método. Mas, no nosso caso, a situação é mais complicada, pois muitos objetos grandes viajam entre métodos, são colocados em estruturas de dados, transferidos para outras estruturas etc.
- Implementação. Existe o ArrayPool da Microsoft, mas ainda precisamos de List e HashSet. Como não encontramos nenhuma biblioteca adequada, teríamos que implementar as classes por conta própria.
- Uso de objetos pequenos. Uma matriz grande pode ser dividida em várias partes pequenas, que não serão carregadas no Large Object Heap, mas serão criadas na 0ª geração e depois seguirão o caminho padrão na 1ª e 2ª. Esperamos que eles não atendam à 2ª, mas sejam coletados pelo coletor de lixo na 0ª ou, em casos extremos, na 1ª geração. A vantagem dessa abordagem é que as alterações no código existente são mínimas. Dificuldades:
- Implementação. Como não encontramos bibliotecas adequadas, teríamos que escrever as classes. A falta de bibliotecas é compreensível, pois o cenário “coleções que não carregam o heap de objetos grandes” é um escopo muito restrito.
Decidimos seguir no terceiro caminho e
inventar nossa bicicleta para escrever List e HashSet, sem carregar o Large Object Heap.
Lista de peças
Nosso ChunkedList <T> implementa interfaces padrão, incluindo IList <T>, que requer alterações mínimas no código existente. Sim, e a biblioteca Newtonsoft.Json que usamos é automaticamente capaz de serializá-la, uma vez que implementa IEnumerable <T>:
public sealed class ChunkedList<T> : IList<T>, ICollection<T>, IEnumerable<T>, IEnumerable, IList, ICollection, IReadOnlyList<T>, IReadOnlyCollection<T> {
A lista padrão <T> possui os seguintes campos: matriz para elementos e o número de elementos preenchidos. No ChunkedList <T>, há uma matriz de matrizes de elementos, o número de matrizes completamente preenchidas, o número de elementos na última matriz. Cada uma das matrizes de elementos com menos de 85.000 bytes:

private T[][] chunks; private int currentChunk; private int currentChunkSize;
Como o ChunkedList <T> é bastante complicado, escrevemos testes detalhados sobre ele. Qualquer operação deve ser testada em pelo menos 2 modos: em "pequena" quando a lista inteira se encaixa em uma peça de até 85.000 bytes de tamanho e "grande" quando consiste em mais de uma peça. Além disso, para métodos que alteram o tamanho (por exemplo, Adicionar), os cenários são ainda maiores: "pequeno" -> "pequeno", "pequeno" -> "grande", "grande" -> "grande", "grande" -> " pequeno. " Aqui existem alguns casos de fronteira confusos que os testes de unidade fazem bem.
A situação é simplificada pelo fato de que alguns dos métodos da interface IList não são usados e podem ser omitidos (como Inserir, Remover). Sua implementação e teste seriam bastante gerais. Além disso, a escrita de testes de unidade é simplificada pelo fato de não precisarmos apresentar novas funcionalidades. O ChunkedList <T> deve se comportar da mesma forma que a Lista <T>. Ou seja, todos os testes estão organizados da seguinte maneira: crie uma Lista <T> e ChunkedList <T>, execute as mesmas operações nelas e compare os resultados.
Medimos o desempenho usando a biblioteca BenchmarkDotNet para garantir que não reduzimos muito o nosso código ao mudar de Lista <T> para ChunkedList <T>. Vamos testar, por exemplo, adicionando itens à lista:
[Benchmark] public ChunkedList<int> ChunkedList() { var list = new ChunkedList<int>(); for (int i = 0; i < N; i++) list.Add(i); return list; }
E o mesmo teste usando a Lista <T> para comparação. Resultados ao adicionar 500 elementos (tudo se encaixa em uma matriz):
Resultados ao adicionar 50.000 elementos (divididos em várias matrizes):
Descrição detalhada das colunas nos resultados BenchmarkDotNet=v0.11.4, OS=Windows 10.0.17763.379 (1809/October2018Update/Redstone5) Intel Core i7-8700K CPU 3.70GHz (Coffee Lake), 1 CPU, 12 logical and 6 physical cores [Host] : .NET Framework 4.7.2 (CLR 4.0.30319.42000), 64bit RyuJIT-v4.7.3324.0 DefaultJob : .NET Framework 4.7.2 (CLR 4.0.30319.42000), 64bit RyuJIT-v4.7.3324.0
Se você olhar a coluna 'Média', que exibe o tempo médio de execução do teste, poderá ver que nossa implementação é apenas 2-2,5 vezes mais lenta que o padrão. Considerando que no código real, as operações com listas são apenas uma pequena parte de todas as ações executadas, essa diferença se torna insignificante. Mas a coluna 'Gen 2 / 1k op' (o número de montagens da 2ª geração para 1000 execuções de teste) mostra que atingimos o objetivo: com um grande número de elementos, o ChunkedList não cria lixo na segunda geração, que era nossa tarefa.
Conjunto de peças
Da mesma forma, ChunkedHashSet <T> implementa a interface ISet <T>. Ao escrever o ChunkedHashSet <T>, reutilizamos a lógica de pequeno pedaço já implementada no ChunkedList. Para fazer isso, adotamos uma implementação pronta do HashSet <T> da .NET Reference Source, disponível sob a licença MIT, e substituímos as matrizes por ChunkedLists.
Nos testes de unidade, também usamos o mesmo truque das listas: compararemos o comportamento de ChunkedHashSet <T> com a referência HashSet <T>.
Finalmente, testes de desempenho. A principal operação que usamos é a união de conjuntos, e é por isso que estamos testando:
public ChunkedHashSet<int> ChunkedHashSet(int[][] source) { var set = new ChunkedHashSet<int>(); foreach (var arr in source) set.UnionWith(arr); return set; }
E exatamente o mesmo teste para o HashSet padrão. Primeiro teste para pequenos conjuntos:
var source = new int[][] { Enumerable.Range(0, 300).ToArray(), Enumerable.Range(100, 600).ToArray(), Enumerable.Range(300, 1000).ToArray(), }
O segundo teste para conjuntos grandes que causaram um problema com vários objetos grandes:
var source = new int[][] { Enumerable.Range(0, 30000).ToArray(), Enumerable.Range(10000, 60000).ToArray(), Enumerable.Range(30000, 100000).ToArray(), }
Os resultados são semelhantes às listagens. O ChunkedHashSet é mais lento em 2-2,5 vezes, mas, ao mesmo tempo, em conjuntos grandes, ele carrega menos a 2ª geração 2 ordens de magnitude.
Serialização em JSON
O servidor web Pyrus fornece várias APIs que usam serialização diferente. Descobrimos a criação de objetos grandes na API usada pelos bots e no utilitário de sincronização (a seguir denominada API pública). Observe que basicamente a API usa sua própria serialização, que não é afetada por esse problema. Escrevemos sobre isso no artigo
https://habr.com/en/post/227595/ , na seção "2. Você não sabe onde está o gargalo do seu aplicativo. " Ou seja, a API principal já está funcionando bem, e o problema apareceu na API pública à medida que o número de solicitações e a quantidade de dados nas respostas aumentaram.
Vamos otimizar a API pública. Usando o exemplo da API principal, sabemos que você pode retornar uma resposta ao usuário no modo de streaming. Ou seja, você não precisa criar buffers intermediários contendo a resposta inteira, mas grave a resposta imediatamente no fluxo.
Após uma inspeção mais detalhada, descobrimos que, no processo de serialização da resposta, criamos um buffer temporário para o resultado intermediário ('content' é uma matriz de bytes que contém JSON na codificação UTF-8):
var serializer = Newtonsoft.Json.JsonSerializer.Create(...); byte[] content; var sw = new StreamWriter(new MemoryStream(), new UTF8Encoding(false)); using (var writer = new Newtonsoft.Json.JsonTextWriter(sw)) { serializer.Serialize(writer, result); writer.Flush(); content = ms.ToArray(); }
Vamos ver onde o conteúdo é usado. Por motivos históricos, a API pública é baseada no WCF, para o qual XML é o formato padrão de solicitação e resposta. No nosso caso, a resposta XML possui um único elemento 'Binário', dentro do qual o JSON codificado em Base64 é gravado:
public class RawBodyWriter : BodyWriter { private readonly byte[] _content; public RawBodyWriter(byte[] content) : base(true) { _content = content; } protected override void OnWriteBodyContents(XmlDictionaryWriter writer) { writer.WriteStartElement("Binary"); writer.WriteBase64(_content, 0, _content.Length); writer.WriteEndElement(); } }
Observe que um buffer temporário não é necessário aqui. O JSON pode ser gravado imediatamente no buffer XmlWriter que o WCF nos fornece, codificando-o no Base64 em tempo real. Assim, seguiremos o primeiro caminho, eliminando a alocação de memória:
protected override void OnWriteBodyContents(XmlDictionaryWriter writer) { var serializer = Newtonsoft.Json.JsonSerializer.Create(...); writer.WriteStartElement("Binary"); Stream stream = new Base64Writer(writer); Var sw = new StreamWriter(stream, new UTF8Encoding(false)); using (var jsonWriter = new Newtonsoft.Json.JsonTextWriter(sw)) { serializer.Serialize(jsonWriter, _result); jsonWriter.Flush(); } writer.WriteEndElement(); }
Aqui, o Base64Writer é um invólucro simples sobre o XmlWriter que implementa a interface Stream, que grava no XmlWriter como Base64. Ao mesmo tempo, a partir de toda a interface, basta implementar apenas um método Write, chamado no StreamWriter:
public class Base64Writer : Stream { private readonly XmlWriter _writer; public Base64Writer(XmlWriter writer) { _writer = writer; } public override void Write(byte[] buffer, int offset, int count) { _writer.WriteBase64(buffer, offset, count); } <...> }
GC induzido
Vamos tentar lidar com coleções de lixo induzidas misteriosas. Verificamos novamente nosso código 10 vezes para as chamadas GC.Collect, mas isso falhou. Consegui capturar esses eventos no PerfView, mas a pilha de chamadas não é muito indicativa (evento DotNETRuntime / GC / Triggered):
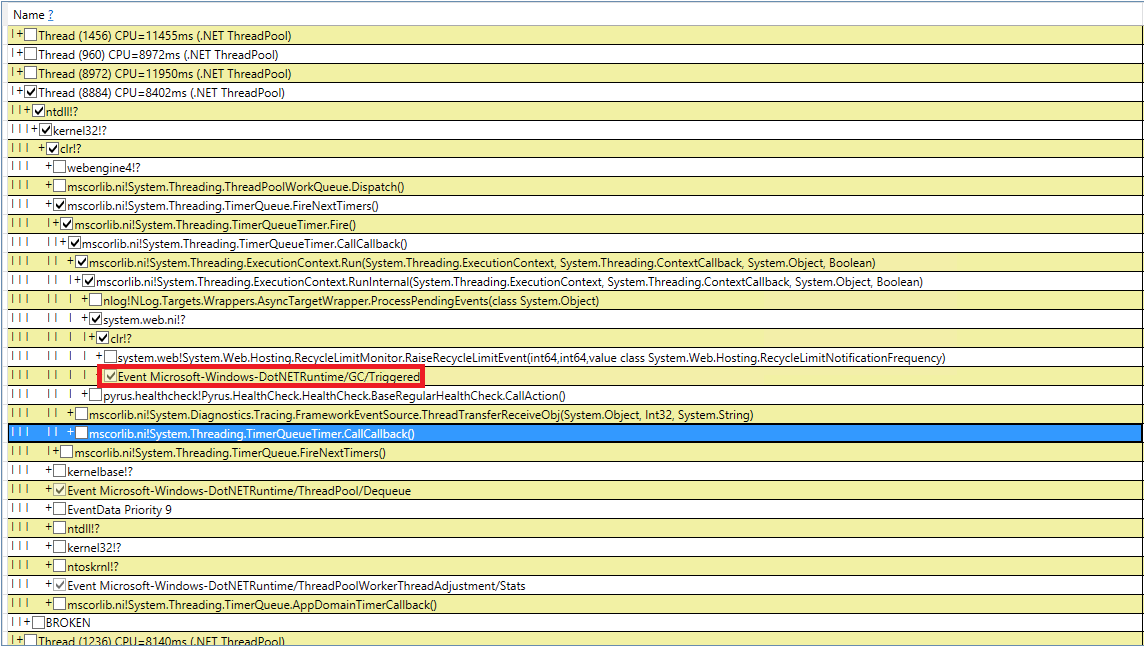
Há uma pequena pista - chamar RecycleLimitMonitor.RaiseRecycleLimitEvent antes da coleta de lixo induzida. Vamos rastrear a pilha de chamadas para o método RaiseRecycleLimitEvent:
RecycleLimitMonitor.RaiseRecycleLimitEvent(...) RecycleLimitMonitor.RecycleLimitMonitorSingleton.AlertProxyMonitors(...) RecycleLimitMonitor.RecycleLimitMonitorSingleton.CollectInfrequently(...) RecycleLimitMonitor.RecycleLimitMonitorSingleton.PBytesMonitorThread(...)
Os nomes dos métodos são consistentes com suas funções:
- No construtor de RecycleLimitMonitor.RecycleLimitMonitorSingleton, é criado um timer que chama PBytesMonitorThread em um determinado intervalo.
- PBytesMonitorThread coleta estatísticas sobre o uso de memória e, sob algumas condições, chama CollectInfrequently.
- CollectInfrequently chama AlertProxyMonitors, obtém um bool como resultado e chama GC.Collect () se for verdadeiro. Ele também monitora o tempo decorrido desde a última chamada para o coletor de lixo e não a chama com muita frequência.
- AlertProxyMonitors percorre a lista de aplicativos Web em execução do IIS, pois cada um deles gera o objeto RecycleLimitMonitor correspondente e chama RaiseRecycleLimitEvent.
- RaiseRecycleLimitEvent gera a lista IObserver <RecycleLimitInfo>. Os manipuladores recebem como um parâmetro RecycleLimitInfo, no qual eles podem definir o sinalizador RequestGC, que retorna para CollectInfrequently, causando uma coleta de lixo induzida.
Uma investigação mais aprofundada revela que os manipuladores IObserver <RecycleLimitInfo> são adicionados ao método RecycleLimitMonitor.Subscribe (), chamado no método AspNetMemoryMonitor.Subscribe (). Além disso, o manipulador padrão IObserver <RecycleLimitInfo> (a classe RecycleLimitObserver) fica suspenso na classe AspNetMemoryMonitor, que limpa os caches do ASP.NET e às vezes solicita a coleta de lixo.
O enigma do GC induzido está quase resolvido. Resta descobrir a questão de por que essa coleta de lixo é chamada. O RecycleLimitMonitor monitora o uso da memória do IIS (mais precisamente, o número de bytes particulares) e, quando seu uso se aproxima de um determinado limite, ele inicia com um algoritmo bastante confuso para aumentar o evento RaiseRecycleLimitEvent. O valor de AspNetMemoryMonitor.ProcessPrivateBytesLimit é usado como limite de memória e, por sua vez, contém a seguinte lógica:
- Se o Pool de aplicativos no IIS estiver definido como 'Limite de memória privada (KB)'), o valor em kilobytes será obtido a partir daí
- Caso contrário, para sistemas de 64 bits, 60% da memória física é consumida (para sistemas de 32 bits, a lógica é mais complicada).
A conclusão da investigação é a seguinte: o ASP.NET está chegando ao limite de memória e começa a chamar regularmente a coleta de lixo. O 'Limite de memória privada (KB)') não foi definido; portanto, o ASP.NET estava limitado a 60% da memória física. O problema foi mascarado pelo fato de que, no servidor do Gerenciador de tarefas, ele mostrava muita memória livre e parecia que estava faltando. Aumentamos o valor 'Limite de memória privada (KB)') nas configurações do pool de aplicativos no IIS para 80% da memória física. Isso incentiva o ASP.NET a usar mais memória disponível. Também adicionamos o monitoramento do contador de desempenho '.NET CLR Memory / # Induced GC', para não perder na próxima vez que o ASP.NET decidir que está se aproximando do limite de uso da memória.
Medições repetidas
Vamos ver o que aconteceu com a coleta de lixo após todas essas alterações. Vamos começar com perfview / GCCollectOnly (tempo de rastreamento - 1 hora), o relatório GCStats:
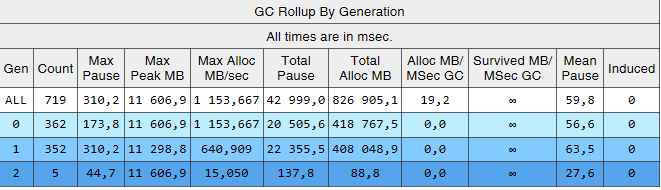
Pode-se ver que as assembléias da 2ª geração são agora 2 ordens de magnitude menores que a 0ª e a 1ª. Além disso, o tempo dessas assembléias diminuiu. Montagens induzidas não são mais observadas. Vejamos a lista de montagens da 2ª geração:
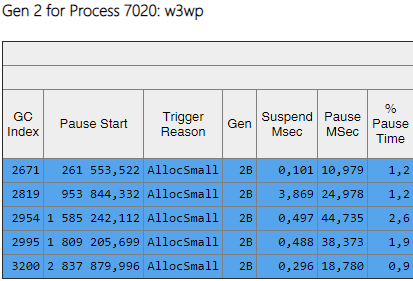
A coluna Ger mostra que todos os conjuntos da 2ª geração se tornaram em segundo plano ('2B' significa 2ª geração, em segundo plano). Ou seja, a maior parte do trabalho é executada em paralelo com a execução do aplicativo e todos os threads são bloqueados por um curto período de tempo (coluna 'Pausar MSec'). Vejamos as pausas ao criar objetos grandes:

Pode-se observar que o número de pausas ao criar objetos grandes caiu significativamente.
Sumário
Graças às alterações descritas no artigo, foi possível reduzir significativamente o número e a duração das montagens da 2ª geração. Consegui encontrar a causa das montagens induzidas e me livrar delas. O número de montagens da 0ª e 1ª geração aumentou, mas a duração média diminuiu (de ~ 200 ms para ~ 60 ms). A duração máxima de montagem da 0ª e 1ª geração diminuiu, mas não de maneira tão perceptível. Os conjuntos de 2ª geração ficaram mais rápidos, longas pausas de até 1000ms desapareceram completamente.
Quanto à métrica principal - "porcentagem de consultas lentas", ela diminuiu 40% após todas as alterações.
Graças ao nosso trabalho, percebemos quais contadores de desempenho são necessários para avaliar a situação com memória e coleta de lixo, adicionando-os ao Zabbix para monitoramento contínuo. Aqui está uma lista dos mais importantes que prestamos atenção e descobrimos o motivo (por exemplo, um aumento no fluxo de solicitações, uma grande quantidade de dados transmitidos, um bug no aplicativo):