O título do artigo pode parecer estranho e por um bom motivo - é bonito exatamente porque não foi escrito por mim, mas pela rede neural do LSTM (ou melhor, sua parte antes do "ou").
(Esquema LSTM retirado de Noções básicas sobre redes LSTM )
E hoje vamos descobrir como você pode gerar os títulos dos artigos de Habr (e, em princípio, o próprio texto pode ser gerado pela mesma neuro-arquitetura). Todo o código está disponível para execução on-line em notebooks do Google. Os dados, como sempre, são abertos no github .
E aqui você pode executar o modelo já treinado na GPU do Google (de graça e sem SMS) e realmente gerar cabeçalhos.
Links principais
A teoria e descrição das redes neurais (em particular LSTM) neste artigo são baseadas em
Descrição dos dados
No total, foram coletados cerca de 40 mil títulos de artigos : cada título foi complementado com dois caracteres especiais <START_CHAR> e <END_CHAR> no início e no final, assim como <PADDING_CHAR> após <END_CHAR> no tamanho máximo do título.
Um exemplo dos dados coletados:
Google IT . Now it's official
Teoria LSTM
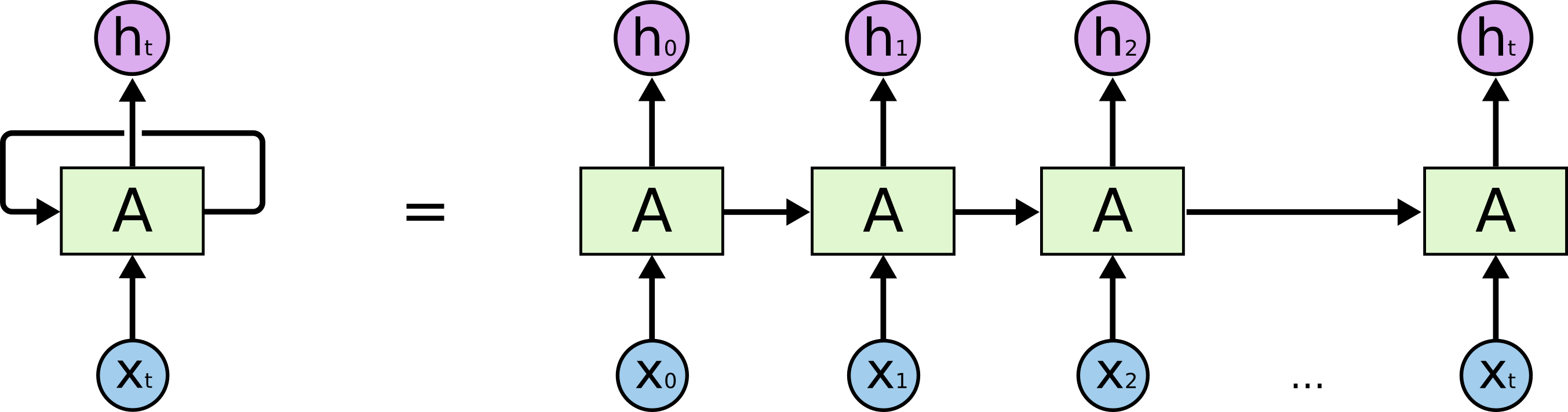
Vamos começar com a tarefa real que estamos resolvendo: queremos prever a (N + 1) quinta linha em N caracteres, ilustrativamente do ponto de vista do modelo LSTM, é semelhante à figura abaixo: X abaixo - dados de entrada; h i acima são fins de semana; entre eles está o estado interno da rede. Um pouco mais detalhadamente - a imagem à esquerda com um loop de feedback, equivalente a uma cadeia detalhada à direita.
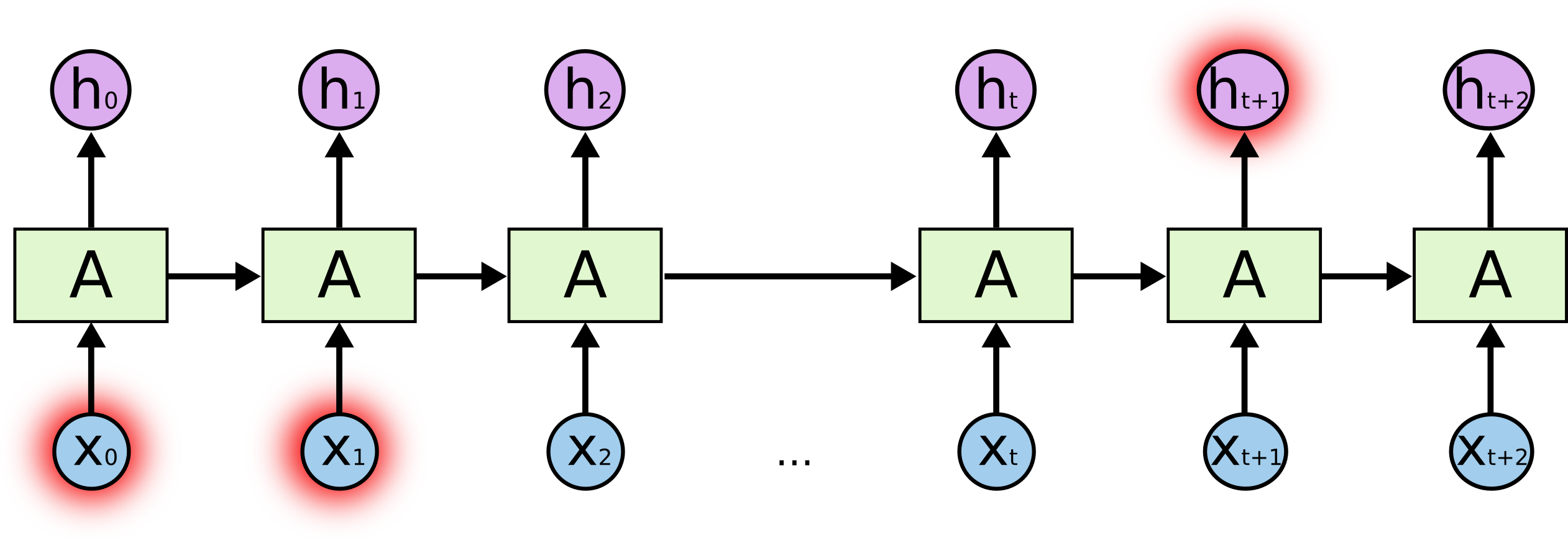
O que é o sal? Ao prever um caractere destacado no final, os caracteres destacados no início podem desempenhar um papel fundamental - daí o termo Dependências de Longo Prazo. É claro que muitas vezes os personagens imediatamente ao lado deles desempenham um papel significativo - essas dependências são chamadas de Dependências de Curto Prazo.
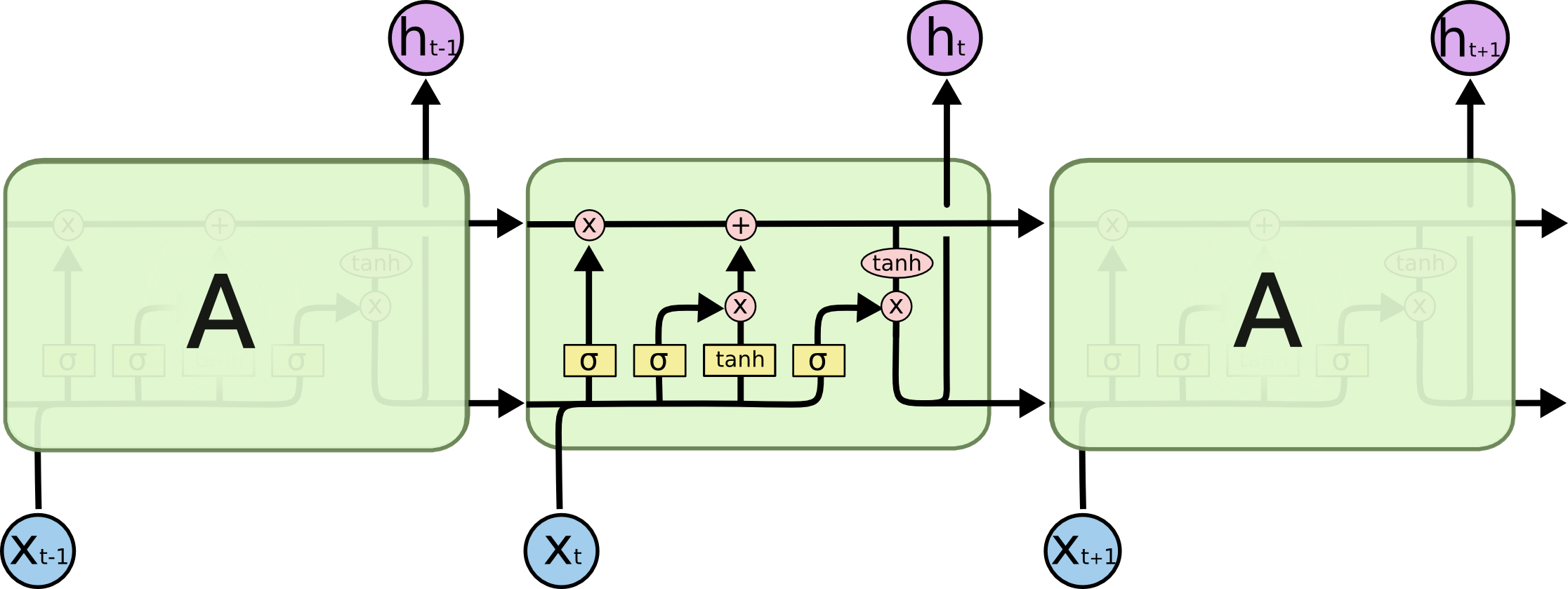
Internos de células LSTM:
A célula inteira contém quatro elementos básicos.
- Portas do esquecimento - um elemento decide que ficará sem memória
- Portão de entrada - cria um conjunto de "valores candidatos" que podemos usar para escrever e atualizar a memória
- Memória - um elemento decide o que realmente é e como economizamos
- Elemento de saída - define a saída do modelo
Designações:

Portão do esquecimento
Se estamos tentando prever o final de uma palavra - é importante saber o sexo do substantivo atual, se vimos um novo substantivo - vale a pena esquecer o significado anterior:

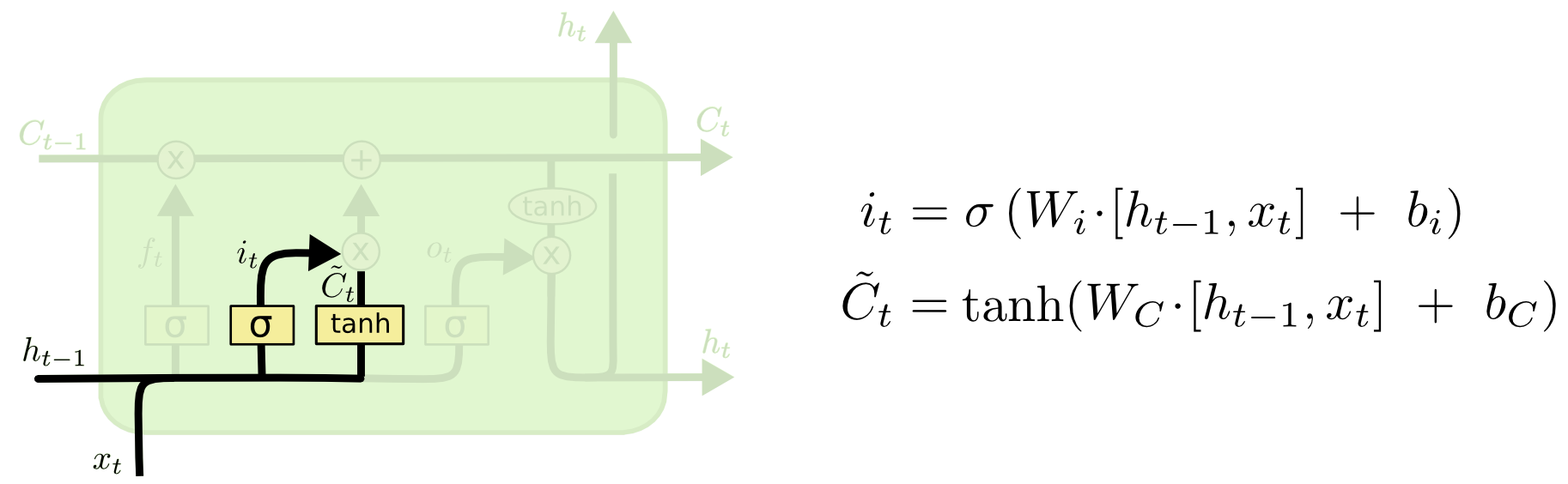
Portão de entrada
Em seguida, calculamos i t , que determinará quais valores da célula de memória queremos atualizar e
calcula os valores candidatos para a atualização.
Célula de memória
Em seguida, os valores da memória são uma superposição do que esquecemos no estado atual e do que adicionamos

Saída do modelo
O que é inferência de modelo - uma combinação de três coisas: o símbolo de entrada atual, previsão anterior e memória de modelo

Código
A lógica básica do modelo é apresentada abaixo, como regra - isso representa cerca de 5 a 10% de todo o código, o restante do código é limpeza, preparação e processamento de dados, bem como saída de forma legível por humanos.
Aqui você pode executar o código com um modelo já treinado.
model = Sequential()
Exemplos de cabeçalhos criados
Amostragem pessoal:
python powershell
(referências aleatórias de modelos ao Dr. Strangelove são especialmente agradáveis)
O que é temperatura (no contexto da DL)
Na saída, o modelo gera os pesos x w das palavras w - temos opções de como transformar esses pesos em probabilidades p (w), por exemplo, usando a fórmula:
Onde T é um parâmetro livre (em física, é assim que a temperatura é estatisticamente determinada - daí o nome), quanto menor a temperatura - maior o expoente e os pesos mais altos tiram toda a probabilidade, ou seja, o modelo prevê apenas algumas palavras com o máximo pesos, se a temperatura estiver alta, a distribuição passará para um uniforme e mais "criativo". Isso nos dá a oportunidade de controlar o equilíbrio entre seguir com precisão os dados disponíveis e a criatividade condicional do modelo.
Exemplo de saída do modelo using temperature 0.03 python sql azure federations 2 temperature 0.04 devcon 2013 temperature 0.05 python temperature 0.06 jbreak 2 10 19 temperature 0.07 temperature 0.08 php 10 temperature 0.09 unix oracle temperature 0.1 php temperature 0.11 android android studio github vue js php ruby temperature 0.12 asp net temperature 0.13 google glass using temperature 0.14 android temperature 0.15 python android sql azure federations 2 temperature 0.16 windows python using temperature 0.17 scala apache solr 1 c, 2 3 temperature 0.18 python cpatext content security policy temperature 0.190 52 28 27 nes c 1 3 scanner temperature 0.2 google chrome ms ie
Conclusões
- Modelos de arquitetura LSTM sequências bem e claramente
- A gramática e a lógica costumam sofrer - provavelmente problemas em dois lugares: primeiro, o dispositivo de memória é bastante simples e não pode capturar todas as regras e contexto; segundo, o poder do caso - o conjunto de dados é bem pequeno e não muito diversificado
- Seria interessante olhar para a versão de Better Language Models e suas implicações no grande caso de idioma russo - para entender se a arquitetura e um caso mais poderoso resolvem esses problemas.
- Algumas das manchetes foram incrivelmente ridículas e auto-irônicas, por exemplo, "... e por que a culpa disso"
- Vemos certos padrões nos títulos do Habr, por exemplo, "nós criamos \ construímos", um indicador claro de que as pessoas gostam de compartilhar histórias pessoais sobre o Habr