Parte 1
Parte 3
Mover de dados para resultados sem sair do computador

Uma pilha de imagens de uma pequena zona na Eslovênia e um mapa com uma cobertura do solo classificada obtida usando os métodos descritos no artigo.
Prefácio
A segunda parte de uma série de artigos sobre classificação da cobertura do solo usando a biblioteca eo-learn. Lembramos que o primeiro artigo demonstrou o seguinte:
- Dividindo a AOI (área de interesse) em fragmentos chamados EOPatch
- Recebendo imagens e máscaras na nuvem dos satélites Sentinel-2
- Cálculo de informações adicionais, como NDWI , NDVI
- Criando uma máscara de referência e adicionando-a aos dados de origem
Além disso, realizamos um estudo de superfície dos dados, que é uma etapa extremamente importante antes de iniciar um mergulho no aprendizado de máquina. As tarefas acima foram complementadas por um exemplo na forma de um caderno Jupyter , que agora contém material deste artigo.
Neste artigo, concluiremos a preparação dos dados e também construiremos o primeiro modelo para a construção de mapas de cobertura da terra para a Eslovênia em 2017.
Preparação de dados
A quantidade de código diretamente relacionada ao aprendizado de máquina é muito pequena em comparação com o programa completo. A maior parte do trabalho é limpar os dados, manipular os dados de forma a garantir o uso contínuo com o classificador. Esta parte do trabalho será descrita abaixo.

Um diagrama de pipeline de aprendizado de máquina que mostra que o próprio código usando ML é uma pequena fração de todo o processo. Fonte
Filtragem de imagens na nuvem
Nuvens são entidades que geralmente aparecem em uma escala que excede nosso EOPatch médio (1000x1000 pixels, resolução 10m). Isso significa que qualquer site pode ser completamente coberto por nuvens em datas aleatórias. Como essas imagens não contêm informações úteis e consomem apenas recursos, as ignoramos com base na proporção de pixels válidos em relação ao número total e definimos um limite. Podemos chamar válidos todos os pixels que não são classificados como nuvens e estão localizados dentro de uma imagem de satélite. Observe também que não usamos as máscaras fornecidas com as imagens do Sentinel-2, pois elas são calculadas no nível de imagens completas (o tamanho da imagem S2 completa é 10980 × 10980 pixels, aproximadamente 110 × 110 km), o que significa que, na maioria das vezes, não é necessária para a nossa AOI. Para determinar as nuvens, usaremos o algoritmo do pacote s2cloudless para obter uma máscara de pixels da nuvem.
Em nosso notebook, o limite é definido como 0,8; portanto, selecionamos apenas as imagens preenchidas com dados normais em 80%. Isso pode parecer um valor bastante alto, mas como as nuvens não são um problema muito grande para a nossa AOI, podemos comprá-lo. Vale a pena considerar que essa abordagem não pode ser aplicada sem pensar em qualquer ponto do planeta, pois a área que você escolheu pode ser coberta de nuvens por uma parte significativa do ano.
Interpolação temporal
Devido ao fato de que as imagens podem ser puladas em algumas datas, bem como devido a datas inconsistentes de aquisição da AOI, a falta de dados é uma ocorrência muito comum no campo de observação da Terra. Uma maneira de resolver esse problema é mascarar a validade dos pixels (da etapa anterior) e interpolar os valores para "preencher buracos". Como resultado do processo de interpolação, os valores de pixel ausentes podem ser calculados para criar um EOPatch que contém capturas instantâneas em dias distribuídos uniformemente. Neste exemplo, usamos interpolação linear, mas existem outros métodos, alguns dos quais já estão implementados no eo-learn.

À esquerda, há uma pilha de imagens do Sentinel-2 de uma AOI selecionada aleatoriamente. Pixels transparentes significam dados ausentes devido a nuvens. A imagem à direita mostra a pilha após a interpolação, levando em consideração as máscaras da nuvem.
A informação temporal é extremamente importante na classificação da cobertura e ainda mais importante na tarefa de identificar uma cultura emergente. Tudo isso se deve ao fato de que uma grande quantidade de informações sobre a cobertura do solo está oculta na forma como a parcela muda ao longo do ano. Por exemplo, ao visualizar os valores NDVI interpolados, é possível ver que os valores nas florestas e campos atingem seus máximos na primavera / verão e caem fortemente no outono / inverno, enquanto a água e as superfícies artificiais mantêm esses valores aproximadamente constantes ao longo do ano. As superfícies artificiais têm valores de NDVI ligeiramente mais altos em comparação com a água e repetem parcialmente o desenvolvimento de florestas e campos, já que nas cidades geralmente é possível encontrar parques e outras vegetações. Você também deve levar em consideração as limitações associadas à resolução das imagens - geralmente na área coberta por um pixel, é possível observar vários tipos de cobertura ao mesmo tempo.
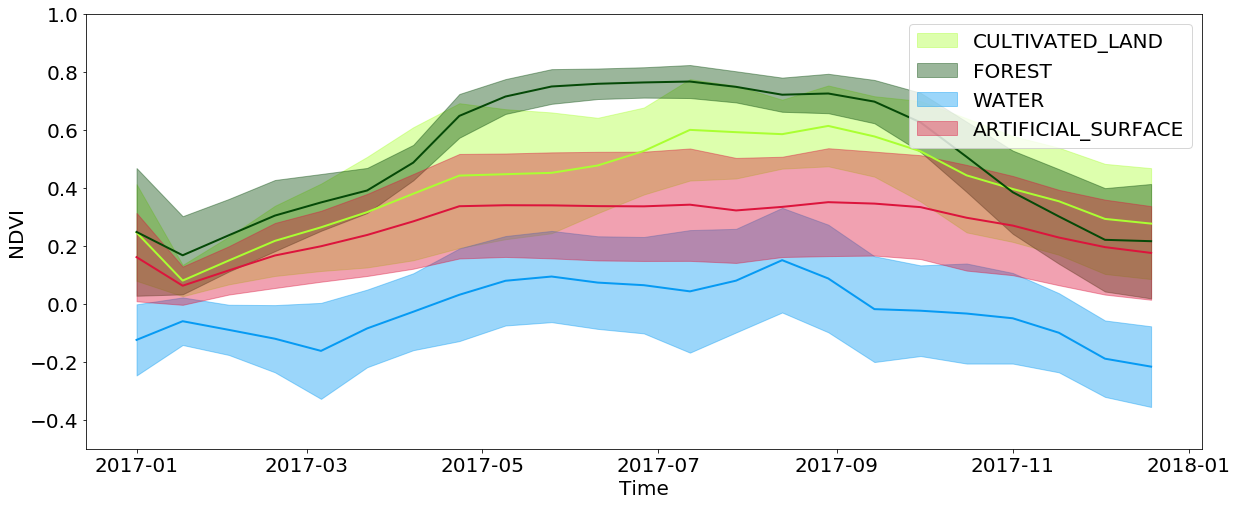
Desenvolvimento temporal dos valores NDVI para pixels de tipos específicos de cobertura do solo ao longo do ano
Buffer negativo
Embora uma resolução de imagem de 10m seja suficiente para uma ampla gama de tarefas, os efeitos colaterais de objetos pequenos são bastante significativos. Esses objetos estão na borda entre diferentes tipos de capa e esses pixels recebem os valores de apenas um dos tipos. Por isso, ao treinar o classificador, o excesso de ruído está presente nos dados de entrada, o que piora o resultado. Além disso, estradas e outros objetos com uma largura de 1 pixel estão presentes no mapa original, embora sejam extremamente difíceis de identificar a partir das imagens. Aplicamos buffer negativo de 1 pixel ao mapa de referência, removendo quase todas as áreas problemáticas da entrada.
Mapa de referência da AOI antes (esquerda) e depois (direita) do buffer negativo
Seleção aleatória de dados
Como mencionado em um artigo anterior, a AOI completa é dividida em aproximadamente 300 fragmentos, cada um dos quais consiste em ~ 1 milhão de pixels. Essa é uma quantidade impressionante desses mesmos pixels; portanto, usamos aproximadamente 40.000 pixels para cada EOPatch para obter um conjunto de dados de 12 milhões de cópias. Como os pixels são tirados uniformemente, um grande número não importa no mapa de referência, pois esses dados são desconhecidos (ou foram perdidos após a etapa anterior). Faz sentido filtrar esses dados para simplificar o treinamento do classificador, pois não precisamos ensiná-lo a definir o rótulo "sem dados". O mesmo procedimento é repetido para o conjunto de testes, pois esses dados degradam artificialmente os indicadores de qualidade das previsões do classificador.
Dividimos os dados de entrada em conjuntos de treinamento / teste na proporção de 80/20%, respectivamente, no nível EOPatch, o que nos garante que esses conjuntos não se cruzam. Também dividimos os pixels do conjunto para treinamento em conjuntos para teste e validação cruzada da mesma maneira. Após a separação, obtemos uma matriz numpy.ndarray de dimensão (p,t,w,h,d) , em que:
p é o número de EOPatch no conjunto de dados
t - o número de imagens interpoladas para cada EOPatch
* w, h, d - largura, altura e o número de camadas nas imagens, respectivamente.
Após selecionar os subconjuntos, a largura w corresponde ao número de pixels selecionados (por exemplo, 40.000), enquanto a dimensão h é 1. A diferença na forma da matriz não muda nada, esse procedimento é necessário apenas para simplificar o trabalho com imagens.
Os dados dos sensores e da máscara d em qualquer imagem t determinam os dados de entrada para treinamento, onde essas instâncias totalizam p*w*h . Para converter os dados em um formulário digerível pelo classificador, devemos reduzir a dimensão da matriz de 5 para a matriz do formulário (p*w*h, d*t) . Isso é fácil de usar, usando o seguinte código:
import numpy as np p, t, w, h, d = features_array.shape
Esse procedimento tornará possível fazer uma previsão de novos dados da mesma forma e, em seguida, convertê-los novamente e visualizá-los por meios padrão.
Criando um modelo de aprendizado de máquina
A escolha ideal do classificador depende fortemente da tarefa específica e, mesmo com a escolha certa, não devemos esquecer os parâmetros de um modelo específico, que devem ser alterados de tarefa para tarefa. Geralmente é necessário realizar muitas experiências com diferentes conjuntos de parâmetros para dizer com precisão o que é necessário em uma situação específica.
Nesta série de artigos, usamos o pacote LightGBM , porque é uma estrutura intuitiva, rápida, distribuída e produtiva para a construção de modelos baseados em árvores de decisão. Para selecionar os hiperparâmetros do classificador, pode-se usar abordagens diferentes, como a pesquisa em grade , que deve ser testada em um conjunto de testes. Por uma questão de simplicidade, pularemos esta etapa e usaremos os parâmetros padrão.
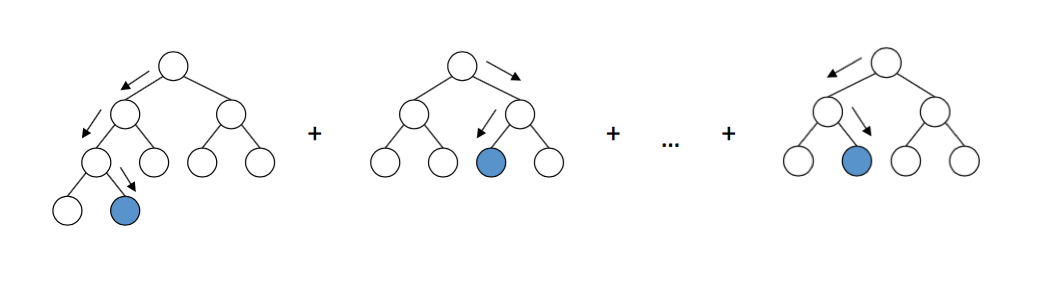
O esquema do trabalho das árvores de decisão no LightGBM. Fonte
A implementação do modelo é bastante simples e, como os dados já vêm na forma de uma matriz, simplesmente alimentamos esses dados na entrada do modelo e aguardamos. Parabéns! Agora você pode dizer a todos que está envolvido em aprendizado de máquina e será o cara mais elegante de uma festa, enquanto sua mãe ficará nervosa com a rebelião de robôs e a morte da humanidade.
Validação de modelo
Modelos de treinamento em aprendizado de máquina são fáceis. A dificuldade é treiná-los bem . Para isso, precisamos de um algoritmo adequado, um cartão de referência confiável e uma quantidade suficiente de recursos de computação. Mas mesmo nesse caso, os resultados podem não ser o que você queria, portanto, verificar o classificador com matrizes de erro e outras métricas é absolutamente necessário para pelo menos alguma confiança nos resultados do seu trabalho.
Matriz de erro
Matrizes de erro são as primeiras coisas a serem observadas ao avaliar a qualidade dos classificadores. Eles mostram o número de tags previstas correta e incorretamente para cada tag do cartão de referência e vice-versa. Geralmente, uma matriz normalizada é usada, onde todos os valores nas linhas são divididos pela quantidade total. Isso mostra se o classificador não possui um viés em relação a um determinado tipo de cobertura em relação a outro
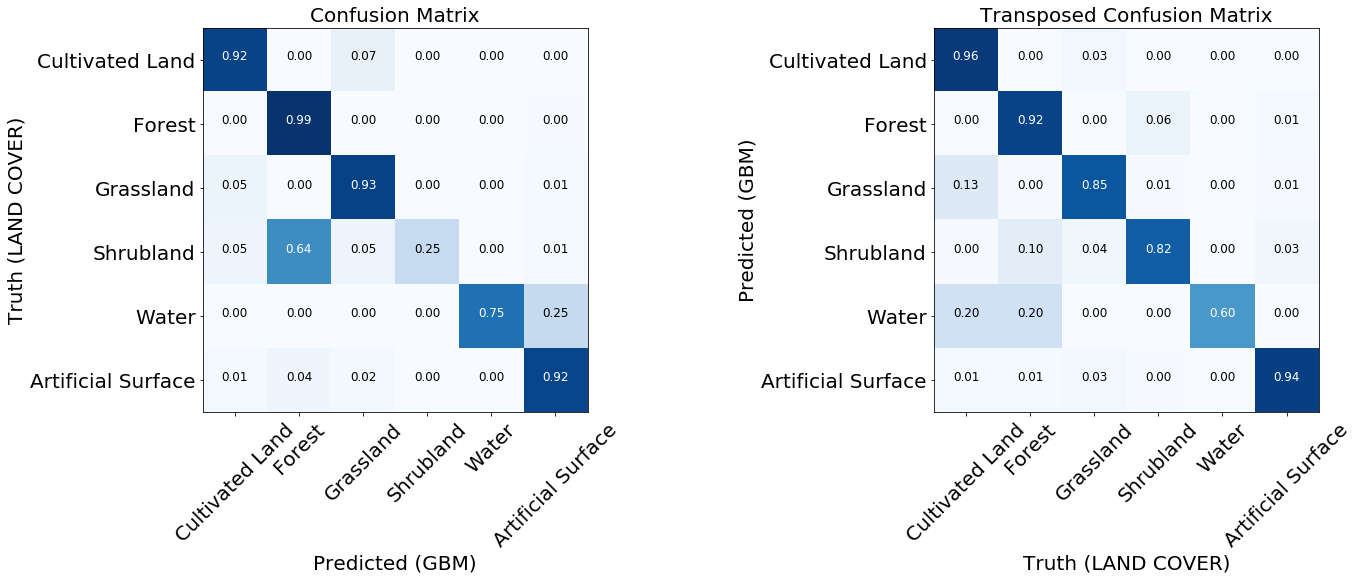
Duas matrizes de erro normalizadas do modelo treinado.
Para a maioria das classes, o modelo mostra bons resultados. Para algumas classes, os erros ocorrem devido ao desequilíbrio nos dados de entrada. Vimos que o problema é, por exemplo, arbustos e água, para os quais o modelo geralmente confunde rótulos de pixel e os identifica incorretamente. Por outro lado, o que é marcado como mato ou água se correlaciona bastante bem com o mapa de referência. A partir da imagem a seguir, podemos observar que surgem problemas para as classes que possuem um pequeno número de instâncias de treinamento - isso se deve principalmente à pequena quantidade de dados em nosso exemplo, mas esse problema pode ocorrer em qualquer tarefa real.
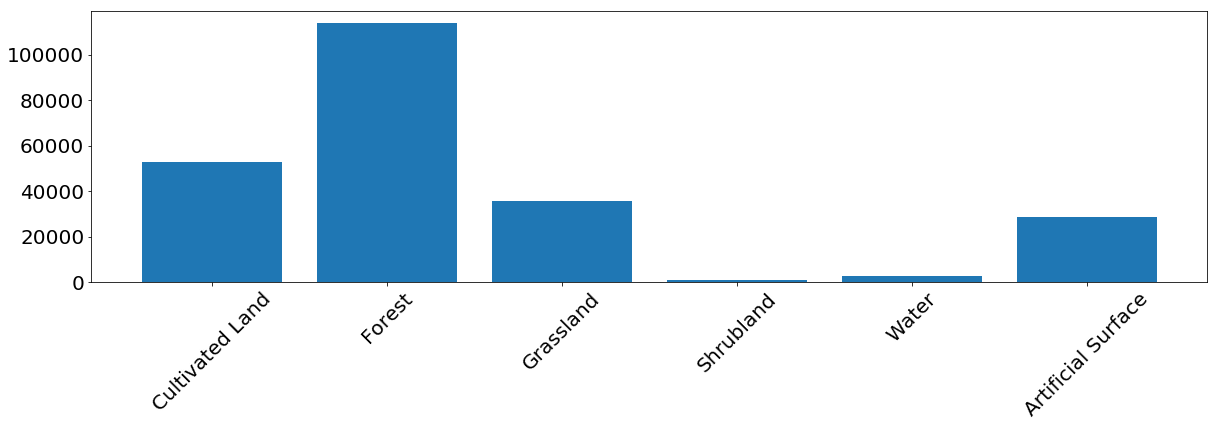
A frequência de ocorrência de pixels de cada classe no conjunto de treinamento.
Característica de Operação do Receptor - Curva ROC
Os classificadores preveem rótulos com uma certa certeza, mas esse limite para um rótulo específico pode ser alterado. A curva ROC mostra a capacidade do classificador de fazer previsões corretas ao alterar o limiar de sensibilidade. Normalmente, este gráfico é usado para sistemas binários , mas pode ser usado em nosso caso se calcularmos a característica "rótulo versus todos os outros" para cada classe. O eixo x mostra resultados falso-positivos (precisamos minimizar o número deles), e o eixo y mostra resultados positivos positivos (precisamos aumentar o número) em diferentes limites. Um bom classificador pode ser descrito por uma curva sob a qual a área da curva é máxima. Este indicador também é conhecido como área sob curva, AUC. A partir dos gráficos das curvas ROC, pode-se tirar as mesmas conclusões sobre um número insuficiente de exemplos da classe "mato", embora a curva para a água pareça muito melhor - isso se deve ao fato de que visualmente a água é muito diferente de outras classes, mesmo com um número insuficiente de exemplos nos dados.

Curvas ROC do classificador, na forma de "um contra todos" para cada classe. Os números entre parênteses são valores da AUC.
A importância dos sintomas
Se você deseja aprofundar-se nas complexidades do classificador, pode olhar para o gráfico de importância do recurso, que nos diz quais dos sinais influenciaram mais o resultado final. Alguns algoritmos de aprendizado de máquina, como o que usamos neste artigo, retornam esses valores. Para outros modelos, essa métrica deve ser considerada por nós mesmos.

A matriz de importância das características para o classificador do exemplo
Embora outros sinais na primavera (NDVI) sejam geralmente mais importantes, vemos que há uma data exata em que um dos sinais (B2 - azul) é o mais importante. Se você olhar as fotos, verifica-se que a AOI durante esse período estava coberta de neve. Pode-se concluir que a neve revela informações sobre a cobertura subjacente, o que ajuda muito o classificador a determinar o tipo de superfície. Vale lembrar que esse fenômeno é específico da AOI observada e, em geral, não pode ser invocado.

3x3 EOPatch AOI parte coberta de neve
Resultados de previsão
Após a validação, entendemos melhor os pontos fortes e fracos do nosso modelo. Se não estivermos satisfeitos com a situação atual, você pode fazer alterações no pipeline e tentar novamente. Após otimizar o modelo, definimos uma EOTask simples que aceita o EOPatch e o modelo classificador, faz uma previsão e a aplica ao fragmento.
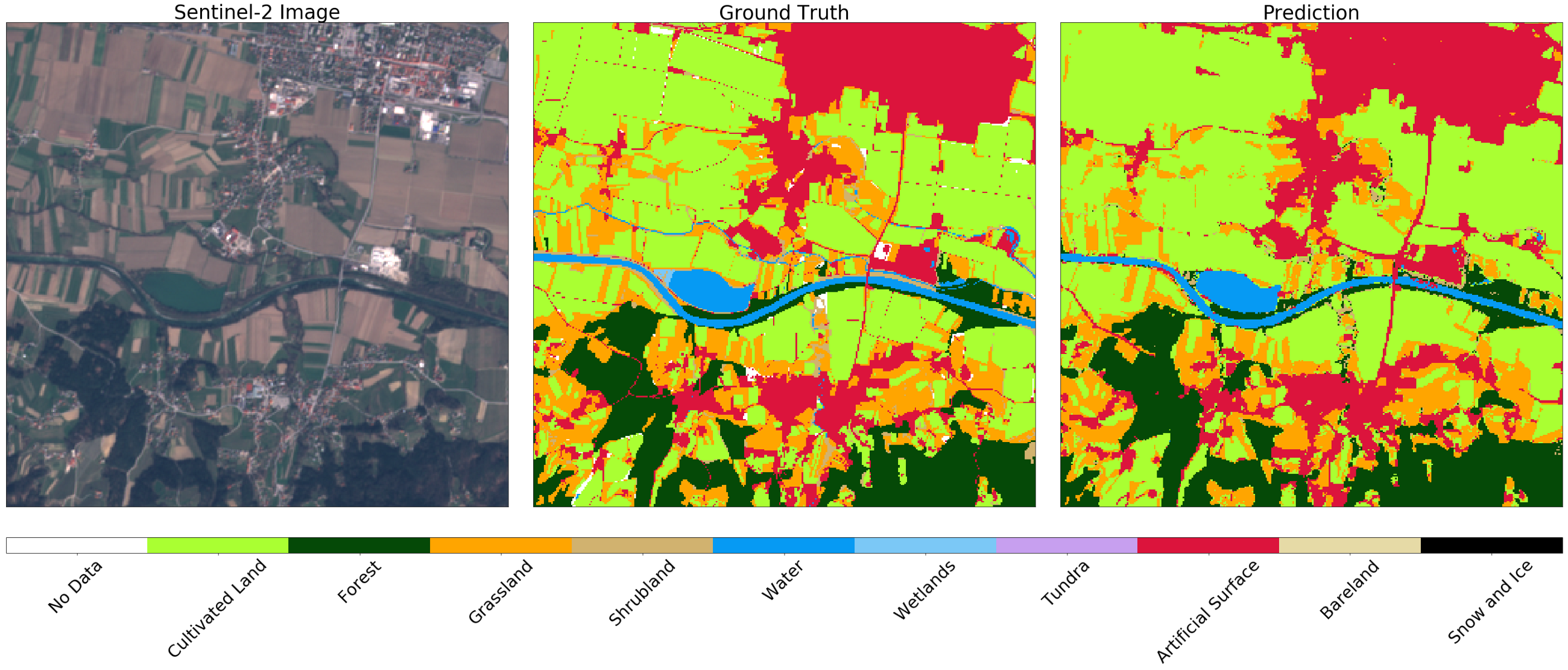
Imagem do Sentinel-2 (esquerda), verdade (centro) e previsão (direita) de um fragmento aleatório da AOI. Você pode notar algumas diferenças nas imagens, que podem ser explicadas pelo uso de buffer negativo no mapa original. Em geral, o resultado para este exemplo é satisfatório.
O caminho mais adiante é claro. É necessário repetir o procedimento para todos os fragmentos. Você pode até exportá-los no formato GeoTIFF e colá-los usando gdal_merge.py .
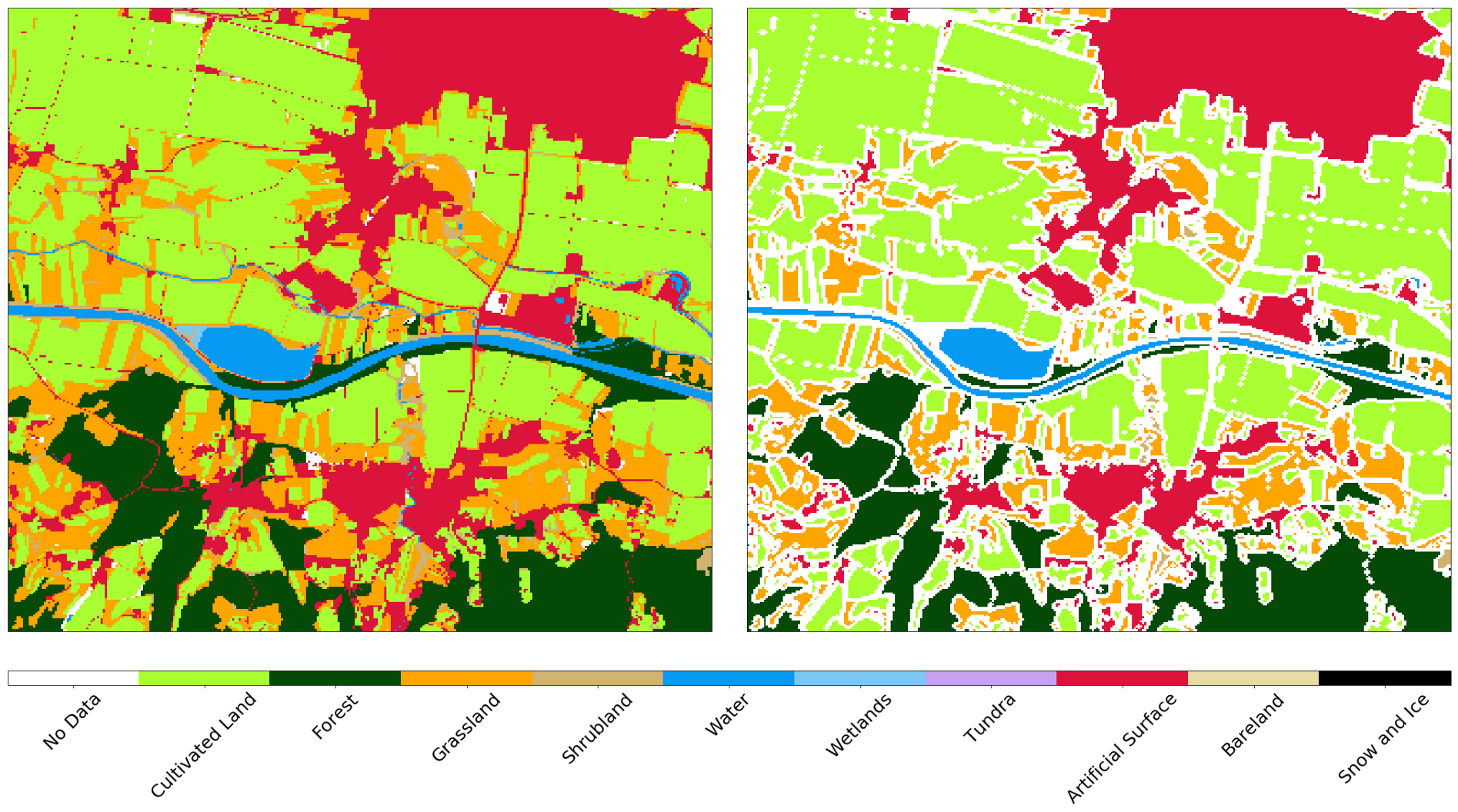
Fizemos upload do GeoTIFF colado no nosso portal GeoPedia, você pode ver os resultados em detalhes aqui
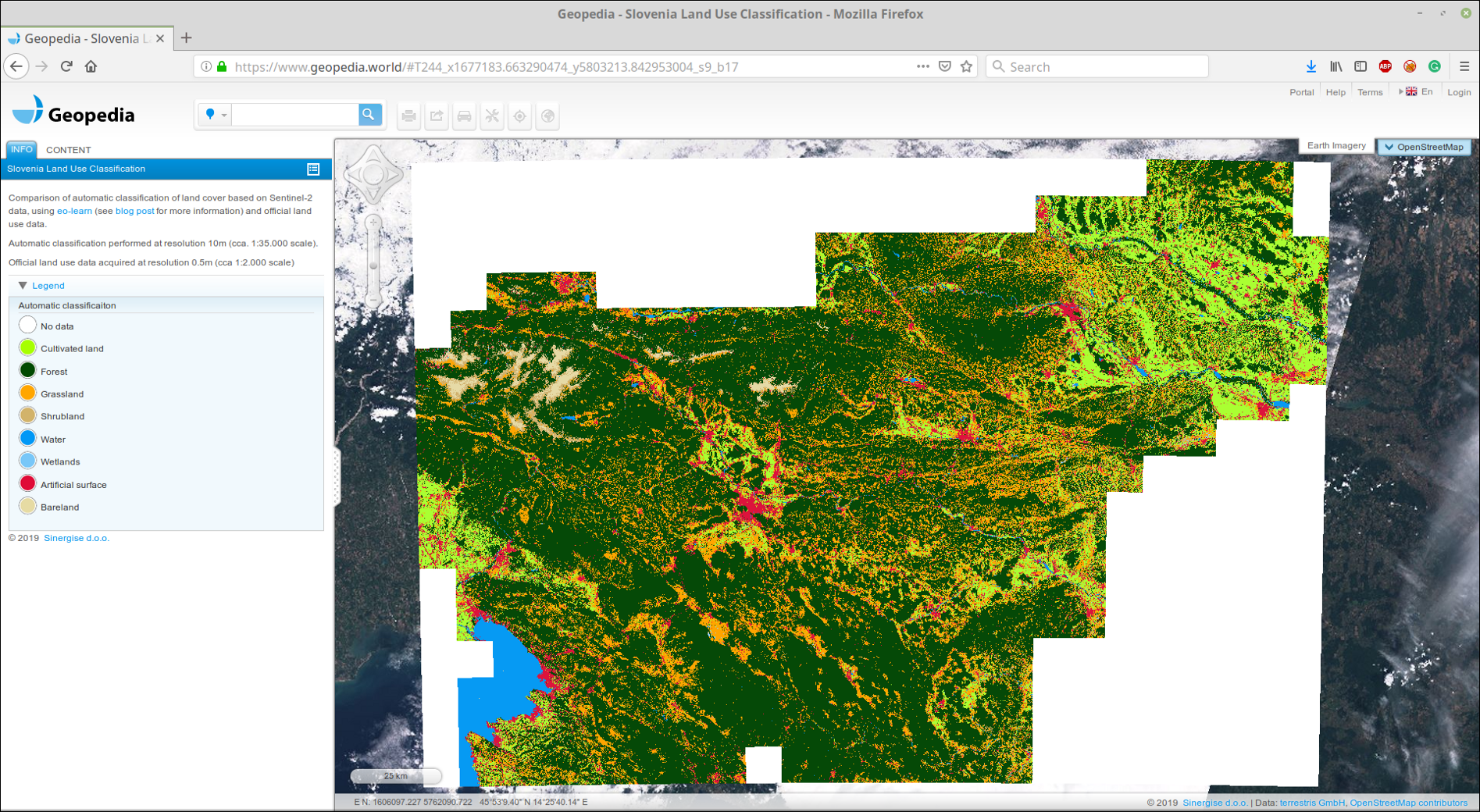
Captura de tela da previsão de cobertura da terra na Eslovênia 2017 usando a abordagem deste post. Disponível em formato interativo no link acima
Você também pode comparar dados oficiais com o resultado do classificador. Preste atenção à diferença entre os conceitos de uso e cobertura do solo , que geralmente são encontrados em tarefas de aprendizado de máquina - nem sempre é fácil mapear dados de registros oficiais para aulas na natureza. Como exemplo, mostramos dois aeroportos na Eslovênia. O primeiro é Levets, perto da cidade de Celje . Este aeroporto é pequeno, usado principalmente para jatos particulares e é coberto de grama. Oficialmente, o território é marcado como superfície artificial, embora o classificador seja capaz de identificar corretamente o território como grama, veja abaixo.

Imagem do Sentinel-2 (esquerda), verdadeira (centro) e previsão (direita) da área em torno do pequeno aeroporto esportivo. O classificador define a pista como grama, embora seja marcada como superfície artificial nos dados atuais.
Por outro lado, no maior aeroporto da Eslovênia, Liubliana , as zonas marcadas como superfície artificial no mapa são estradas. Nesse caso, o classificador distingue entre estruturas, enquanto distingue corretamente grama e campos no território vizinho.
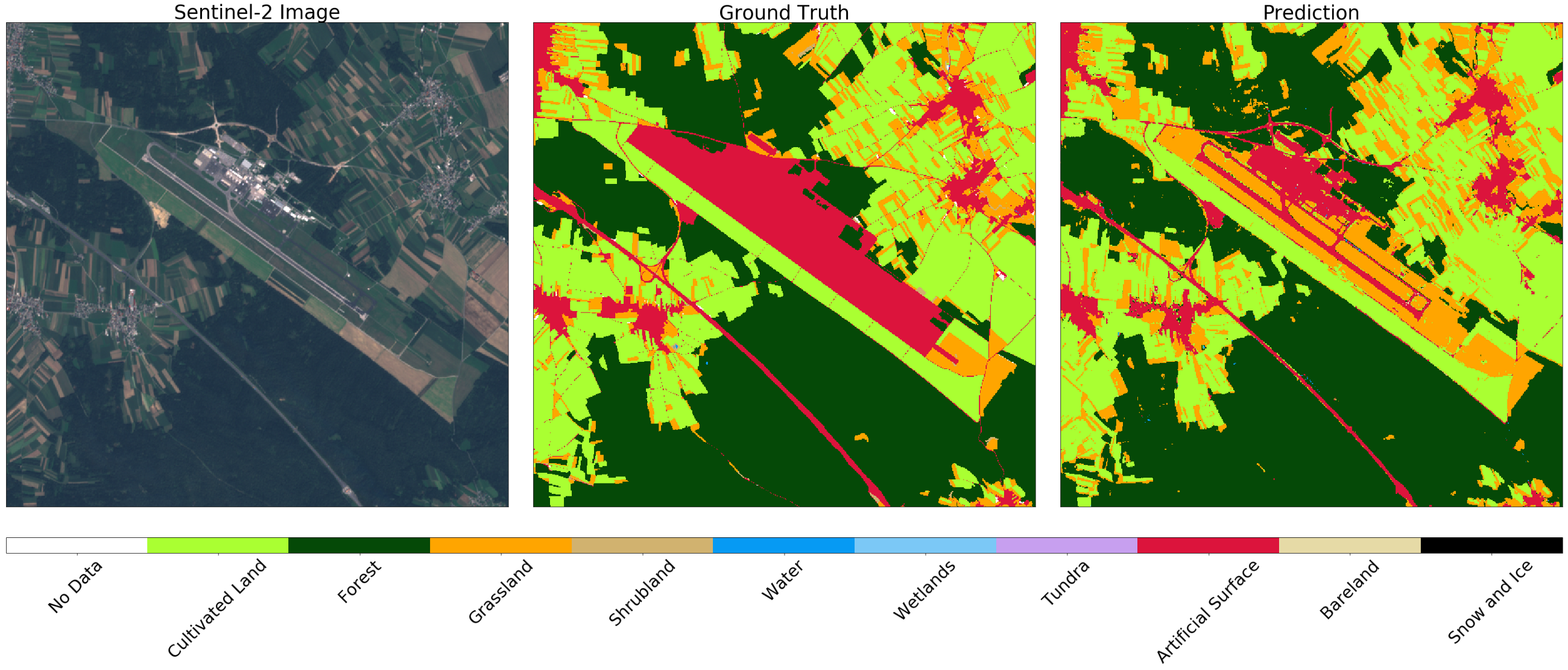
Imagem do Sentinel-2 (esquerda), verdade (centro) e previsão (direita) da área em torno de Lubliana. O classificador determina a pista e as estradas, enquanto distingue corretamente grama e campos na vizinhança
Voila!
Agora você sabe como criar um modelo confiável em escala nacional! Lembre-se de adicionar isso ao seu currículo.