De alguma forma, não consigo expressar meus pensamentos brevemente. No outono passado, havia um desejo de contar com mais detalhes sobre a arquitetura PSoC que eu dominava, o que resultou em uma série de artigos sobre ela. Agora estou envolvido na preparação do hardware para o nosso complexo de depuração remota Redd, que foi descrito
aqui , e quero jogar fora a experiência acumulada em forma de texto. Ainda não tenho certeza, mas parece-me que novamente não é apenas um artigo, mas um ciclo. Primeiro, é assim que irei documentar os métodos de desenvolvimento desenvolvidos que podem ser úteis para alguém, tanto ao trabalhar com o complexo quanto, em geral, e em segundo lugar, o conceito ainda é novo, ainda não estabelecido. Talvez, no processo de discussão de artigos, alguns comentários apareçam, dos quais se possa desenhar algo para expandi-lo (ou até mudar). Portanto, prosseguimos.

Introdução longa
Eu realmente não gosto de teorizar, preferindo apresentar algumas coisas práticas de uma só vez. Mas no começo do primeiro artigo, sem uma longa introdução em qualquer lugar. Nele, justifico a abordagem atual do desenvolvimento. E tudo girará em torno de uma coisa: a hora de trabalho é um recurso muito caro. E o assunto não está apenas nos termos alocados para o projeto. Ele é fisicamente caro. Se é gasto no desenvolvimento do produto final, bem, o que você pode fazer sem ele em lugar nenhum. Mas quando é gasto em trabalho auxiliar, isso, na minha opinião, é ruim. Lembro que tive uma disputa com um desenvolvedor que disse que, tendo feito protótipos por conta própria, ele economizaria dinheiro para sua empresa nativa. Argumentei que ele passaria cerca de 3 dias na fabricação. São 24 horas de trabalho. Tomamos o salário dele por esse horário, acrescentamos o imposto social que "o empregador paga", bem como o aluguel do escritório por esse horário. E ficamos surpresos ao ver que, ao encomendar placas ao lado, você pode obter custos mais baixos. Mas esse sou eu, exagero. Em geral, se os custos trabalhistas puderem ser evitados, eles deverão ser evitados.
Qual é o desenvolvimento de "firmware" para o complexo Redd? Este é um trabalho auxiliar. O projeto principal viverá feliz para sempre; deve ser feito da maneira mais eficiente possível, com excelente otimização etc. Mas gastar tempo e energia em coisas auxiliares que irão para o arquivo após o desenvolvimento é um desperdício. Foi de olho neste princípio que o desenvolvimento do equipamento Redd foi realizado. Todas as funções, se possível, são implementadas como itens padrão. Os barramentos SPI, I2C e UART são implementados em microcircuitos FTDI padrão e são programados através de drivers padrão, sem frescuras. O gerenciamento de bobinas é implementado no formato de uma porta COM virtual. Pode ser modificado, mas pelo menos tudo foi feito para que esse desejo não surja. Em geral, tudo o que é padrão, se possível, é implementado de maneira padrão. De um projeto para outro, os desenvolvedores simplesmente precisam escrever rapidamente um código típico para o PC acessar esses barramentos. A técnica de desenvolvimento em C ++ deve ser óbvia para quem desenvolve programas para microcontroladores (falaremos sobre alguns detalhes técnicos em outro artigo).
Mas o FPGA fica sozinho no complexo. Ele é adicionado ao sistema nos casos em que é necessário implementar qualquer protocolo não padrão com um requisito de alto desempenho. Se isso for necessário, você terá que fazer o "firmware" para isso. Trata-se da programação FPGA e quero falar especificamente, apenas para o mesmo objetivo - reduzir o tempo de desenvolvimento de coisas auxiliares.
Para não confundir o leitor, formularei o pensamento em um quadro:
Não é necessário conduzir o desenvolvimento de FPGAs em cada projeto. Se houver controladores de barramento suficientes conectados diretamente ao processador central para funcionar com o dispositivo de destino, você deverá usá-los.
O FPGA foi adicionado ao complexo para a implementação de protocolos não padrão.
Diagrama de blocos do complexo
Vejamos o diagrama de blocos do complexo

Na parte inferior do circuito é uma "calculadora". Na verdade, este é um PC padrão com Linux. Os desenvolvedores podem escrever programas regulares em C, C ++, Python, etc., que serão executados pelo computador. Na parte superior direita estão as portas padrão dos pneus padrão. À esquerda, há um comutador para dispositivos padrão (SPI Flash, cartão SD e vários relés de estado sólido de baixa corrente, que podem, por exemplo, simular o pressionamento de botões). E no centro está exatamente essa parte, cujo trabalho está planejado para ser considerado nesta série de artigos. Seu coração é o FPGA da classe FPGA, do qual as linhas retas (podem ser usadas como pares diferenciais ou linhas sem buffer comuns), as linhas GPIO com um nível lógico configurável e um barramento USB 2.0 implementado através do chip ULPI vão para o conector.
Continuação da introdução sobre a abordagem de programação FPGA
Ao desenvolver uma lógica de controle de alto desempenho para FPGAs, geralmente Sua Majestade é tocada como o primeiro violino por uma máquina de estado. É nas máquinas que é possível implementar lógica de alta velocidade, mas complexa. Mas, por outro lado, um autômato é desenvolvido mais lentamente que um programa para um processador, e sua modificação é outro processo. Existem sistemas que simplificam o desenvolvimento e a manutenção de máquinas. Um deles foi desenvolvido por nossa empresa, mas ainda assim, o processo de design para qualquer tipo de lógica complexa não é rápido. Quando o sistema desenvolvido é o produto final, faz sentido preparar, projetar uma boa máquina de controle e gastar tempo em sua implementação. Mas, como já observado, o desenvolvimento do Redd é um trabalho auxiliar. Ele foi projetado para facilitar o processo, não para complicá-lo. Portanto, foi decidido que o desenvolvimento não será automático, mas sim sistemas de processador.
Mas, por outro lado, ao desenvolver o hardware, a opção mais elegante até hoje, o FPGA com o núcleo ARM, foi rejeitada. Em primeiro lugar, por razões de preço. Uma placa de protótipo baseada no SoC do Cyclone V é moderadamente cara, mas, curiosamente, um FPGA separado é muito mais caro. Muito provavelmente, o preço das placas de prototipagem é reduzido para atrair os desenvolvedores a usar dados FPGA, e as placas são vendidas individualmente. A série terá que levar fichas individuais. Mas, além disso, há também um "segundo". Em segundo lugar, quando eu estava experimentando o Cyclone V SoC, descobriu-se que esse sistema de processador não é assim e é produtivo quando se trata de acesso único às portas. Lote - sim, o trabalho é rápido. E no caso de acessos únicos com uma freqüência de clock do núcleo do processador de 925 MHz, você pode obter acesso às portas com uma frequência de alguns megahertz. Para todos, proponho chamar a função padrão de inserir dados no FIFO do bloco UART, que verifica o estouro da fila, mas chamá-lo quando a fila está obviamente vazia, ou seja, nada interfere nas operações. Minha produtividade passou de um milhão para quinhentas mil chamadas por segundo (é claro, trabalhar com a memória foi na velocidade normal, todos os caches foram ajustados, até a variante de função que não verificou se o estouro do FIFO funcionava mais rápido, apenas a função em discussão misturou-se abundantemente escrever e ler de portas). Este é FIFO! De fato, o FIFO foi inventado para deixar os dados lá e esquecer! Desistir rapidamente! E não com desempenho, menos de uma megaoperação por segundo a uma frequência de processador de 925 MHz ...
A latência é a culpa. Entre o núcleo do processador e o equipamento está localizado a partir de três pontes ou mais. Além disso, a velocidade de acesso às portas depende do contexto (vários registros em uma linha irão rapidamente, mas a primeira leitura interromperá o processo até que os dados em cache sejam completamente descarregados, muitos registros em uma linha também desacelerarão, pois os buffers de gravação estão esgotados). Finalmente, o exame dos rastreamentos acumulados no buffer de depuração mostrou que a arquitetura
Cortex A pode executar a mesma parte para um número diferente de ciclos de clock devido ao complexo sistema de cache. Em resumo, considerando todos esses fatores (preço, redução de desempenho ao trabalhar com o equipamento, instabilidade da velocidade de acesso ao equipamento, dependência geral do contexto), foi decidido não colocar esse chip no complexo.
Experimentos com o PSoC da Cypress mostraram que o
núcleo do
Cortex M fornece resultados mais previsíveis e repetíveis, mas a capacidade lógica e a frequência máxima de operação desses controladores não correspondiam às especificações técnicas, portanto também foram descartadas.
Foi decidido instalar um FPGA típico do Cyclone IV de baixo custo e recomendar o uso de um núcleo de processador NIOS II sintetizado. Bem, e se necessário - para conduzir o desenvolvimento usando quaisquer outros métodos (máquinas automáticas, lógica rígida, etc.).
Mencionarei separadamente (e até destacarei este parágrafo) que o processador principal do complexo é x86 (x64). É ele quem é o processador central do sistema. É nele que a lógica principal do complexo é executada. O sistema do processador, que será discutido abaixo, foi projetado para simplesmente fornecer a lógica da operação do equipamento "flashed" no FPGA. Além disso, este equipamento é vendido apenas se os desenvolvedores não tiverem módulos de tempo integral suficientes conectados diretamente ao processador central.
O processo de desenvolvimento e depuração de "firmware"
Se o complexo Redd estiver executando o Linux, isso não significa que o desenvolvimento deve ser realizado neste SO. Redd é um executor remoto, e o desenvolvimento deve ser realizado no seu computador, independentemente do sistema operacional. Quem tem Linux é mais fácil, mas quem está acostumado com o Windows (eu costumava gostar muito do WIN 3.1, mas fui forçado a trabalhar, mas em algum momento do WIN95 OSR2 eu me acostumei e agora é inútil combatê-lo, é mais fácil aceitar) , eles podem continuar a liderar o desenvolvimento.
Como minha amizade com o Linux não deu certo, não darei instruções passo a passo para configurar o ambiente, mas me limitarei a palavras gerais. Quem trabalha com este sistema operacional será suficiente para isso e para o resto ... Acredite, é mais fácil entrar em contato com os administradores do sistema. No final, eu fiz exatamente isso. Mas mesmo assim.
Você deve baixar e instalar o Quartus Prime Programmer and Tools da mesma versão do seu ambiente de desenvolvimento. Se as versões não corresponderem, pode haver surpresas. Passei a noite inteira para compreender esse fato. Portanto, basta baixar a ferramenta da mesma versão que o ambiente de desenvolvimento.
Após a instalação, insira o diretório em que o programa foi instalado, o subdiretório bin. Em geral, o arquivo mais importante deve ser jtagconfig. Se você executá-lo sem argumentos (a propósito, solicitei persistentemente inserir ./jtagconfig e somente isso), uma lista de programadores disponíveis no sistema e FPGAs conectados a eles será exibida. Deve haver um USB Blaster. E o primeiro problema que o sistema apresenta não é o direito de acesso suficiente para funcionar com USB. Como resolvê-lo sem recorrer ao sudo é descrito aqui:
radiotech.kz/threads/nastrojka-altera-usb-blaster-v-ubuntu-16-04.1244Mas aqui está uma lista de dispositivos exibidos. Agora você deve escrever:
./jtagconfig --enableremote <password>
após o qual o servidor é iniciado, acessível de qualquer lugar da rede.
Tudo ficaria bem, mas o firewall do sistema não permitirá que ninguém veja este servidor. Uma verificação no Google mostrou que, para cada tipo de Linux (dos quais existem muitos), as portas do firewall se abrem à sua maneira, e tantos feitiços devem ser lançados que prefiro entrar em contato com os administradores.
Também vale a pena considerar que, se o jtagd não estiver registrado na execução automática, quando você abrir o acesso remoto, será informado que é impossível definir uma senha. Para impedir que isso aconteça, o jtagd deve ser iniciado não por meio do próprio jtagconfig, mas antes dele.
Em geral, o xamanismo está no xamanismo. Deixe-me apenas corrigir a tese:
Obviamente, existe um caminho semelhante que percorre a interface da GUI, mas é mais lógico fazer tudo em lote. Portanto, descrevi uma versão em lote. Quando todas essas teses foram concluídas (e os administradores do sistema as concluíram), lançamos o programador em nossa máquina, vemos uma mensagem sobre a falta de equipamento. Clique em Configuração de hardware:
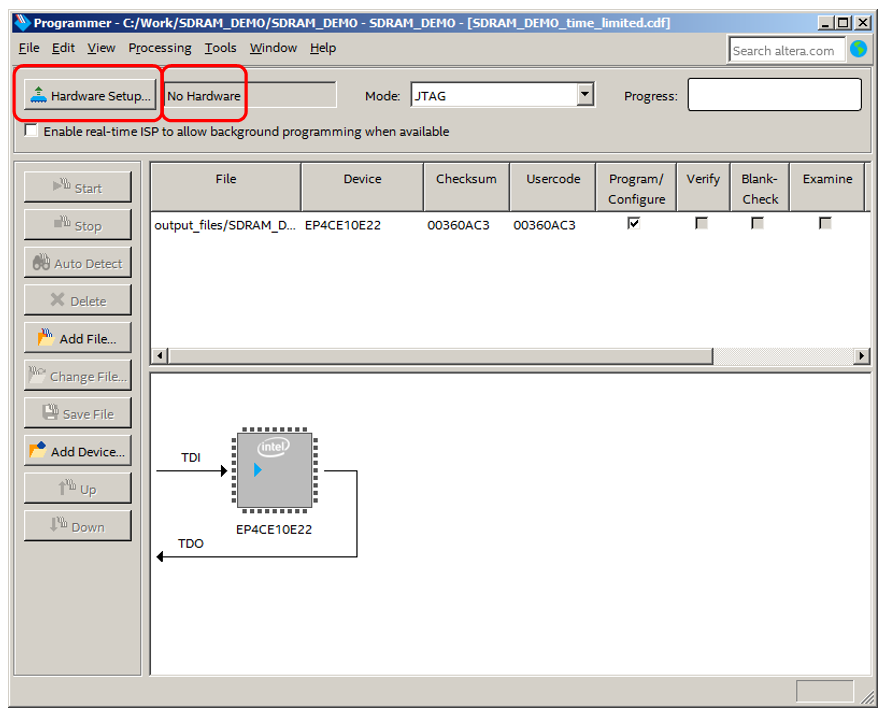
Vá para a guia JTAG Settings e clique em Add Server:
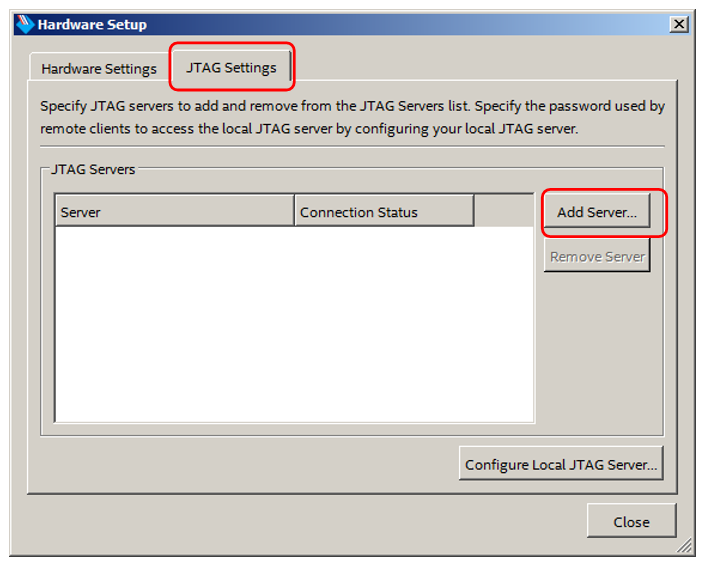
Nós inserimos o endereço de rede de Redd (para mim é 192.168.1.100) e a senha:

Garantimos que a conexão foi bem-sucedida.
Passei três férias em maio para conseguir isso e, em seguida, os administradores decidiram tudo.

Alterne para a guia Configurações de hardware, abra a lista suspensa e selecione o programador remoto:
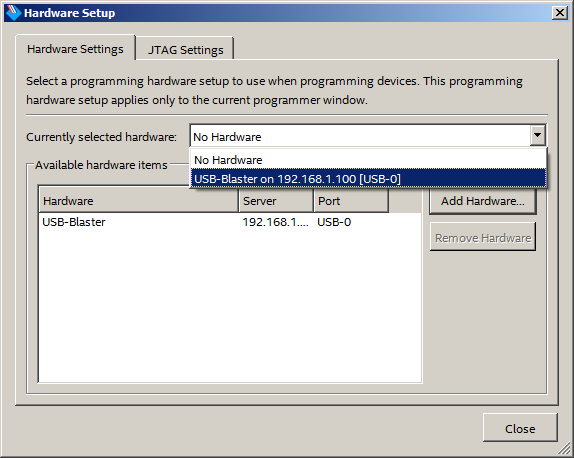
Tudo, agora pode ser usado. O botão Iniciar está desbloqueado.
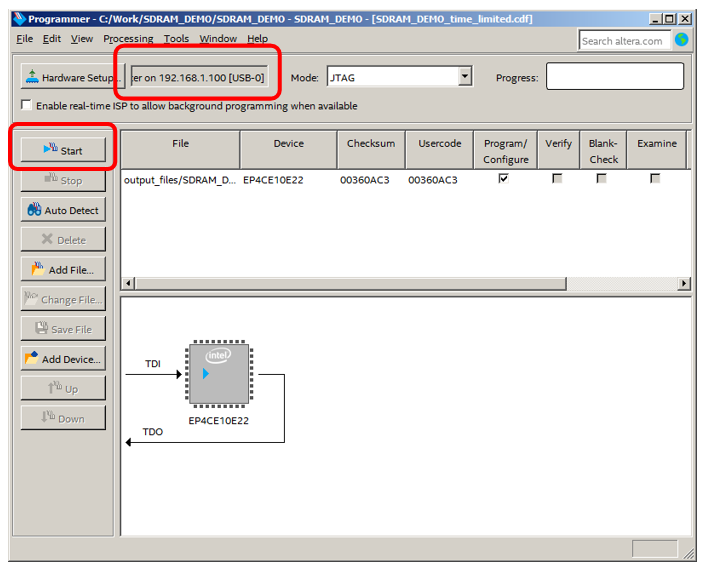
O primeiro "firmware"
Bem então. Para que o artigo tenha um valor prático real, vamos analisar o "firmware" mais simples feito usando os métodos acima. A coisa mais simples que realmente consegui implementar para o complexo é um teste do chip SDRAM. Aqui neste exemplo e prática.
Existem vários núcleos amadores para oferecer suporte à SDRAM, mas todos eles são de alguma forma complicados. E explicar todos os truques é trabalho. Vamos tentar usar soluções prontas que podem ser inseridas no sistema de computação do NIOS II; portanto, usaremos o SDRAM Controller Core padrão. O núcleo em si é descrito no documento
Embedded Peripherals IP User Guide , e muito espaço na descrição é dedicado ao turno do clock da SDRAM em relação ao core clock. São apresentados cálculos e fórmulas teóricas complexas, mas o que fazer não é particularmente relatado. O que fazer pode ser encontrado no documento
Usando a SDRAM na placa DE0 da Altera com desenhos da Verilog . No curso da análise, aplicarei o conhecimento deste documento.
Eu estarei desenvolvendo a versão gratuita do Quartus Prime 17.0. Eu me concentro nisso, pois durante a montagem, eles me dizem que, no futuro, o núcleo do
SDRAM Controller será expulso da versão gratuita. Se isso já aconteceu no seu ambiente de desenvolvimento, ninguém se preocupa em baixar a 17ª versão gratuita e instalá-la em uma máquina virtual. O trabalho principal é feito onde quer que você esteja acostumado, e o firmware do Redd com SDRAM está na 17ª versão. Bem, se você usar as opções gratuitas. Ninguém ameaçou jogá-lo fora dos pagos ainda. Mas eu estava distraído. Crie um novo projeto:

Vamos chamá-lo de SDRAM_DEMO. O nome deve ser lembrado: vou realizar um desenvolvimento super rápido, para que o sistema do processador esteja no nível superior, sem nenhuma camada Verilog. E para que isso aconteça, o nome do sistema do processador deve corresponder ao nome do projeto. Então lembre-se disso.

Concordando com os valores padrão em algumas etapas, chegamos à escolha de um cristal. Selecionamos o EP4CE10E22C7 usado no complexo.

Na próxima etapa, por hábito, escolho modelar no ModelSim-Altera. Hoje não modelamos nada, mas tudo pode ser útil. É melhor desenvolver esse hábito e segui-lo:
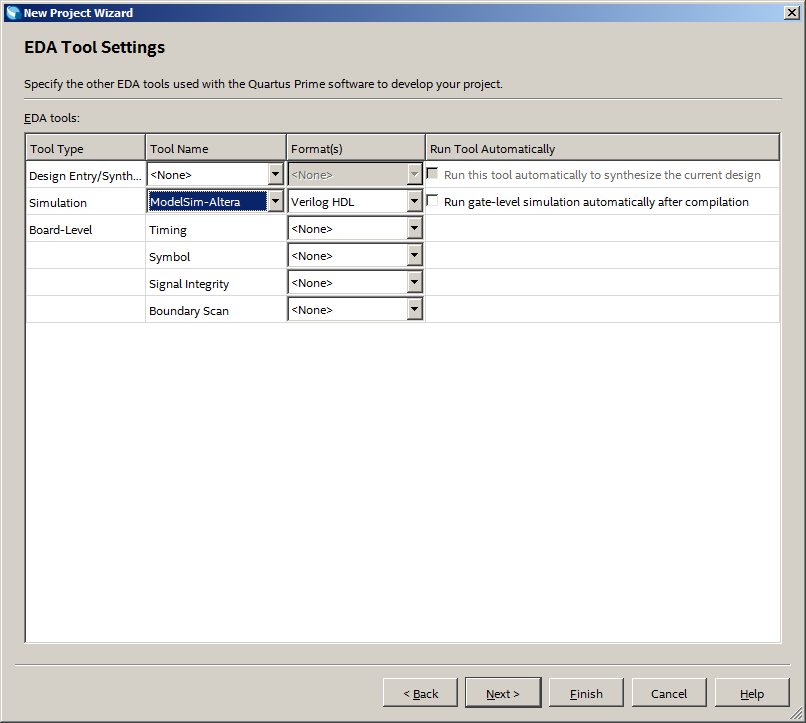
O projeto é criado. Vá imediatamente para a criação do sistema do processador (Ferramentas-> Platform Designer):
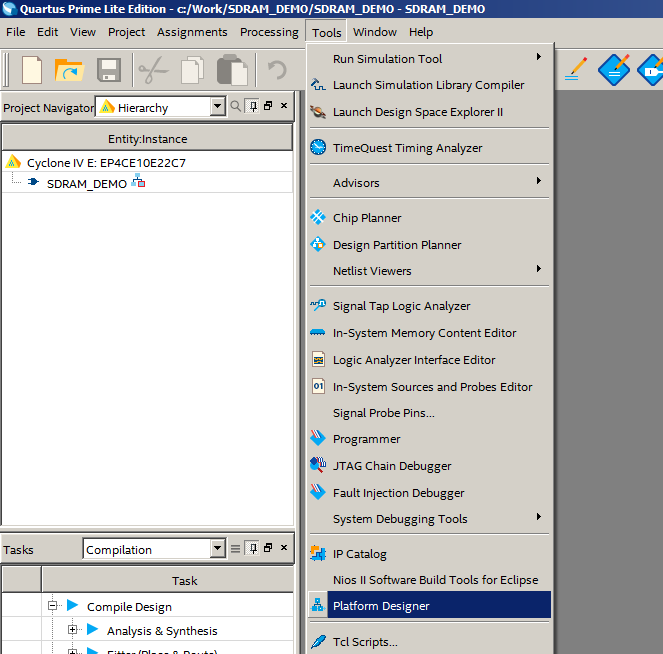
Criamos um sistema que contém um relógio e um módulo de redefinição:

Mas, como eu já mencionei, é necessário um relógio especial para o núcleo da SDRAM. Portanto, o módulo padrão é impiedosamente jogado fora
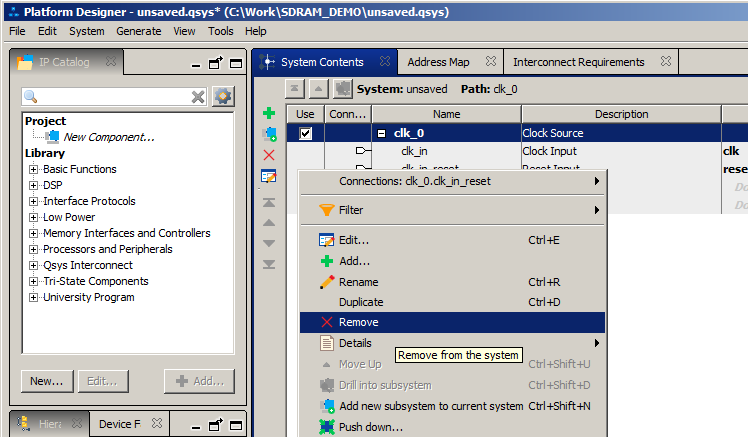
Em vez disso, adicione o bloco University Program-> System e SDRAM Clock for DE-series:
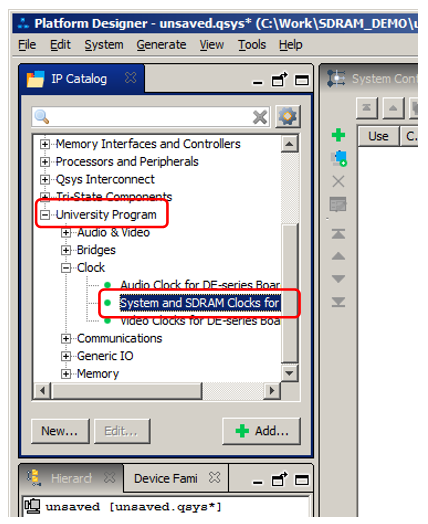
Nas propriedades, selecione DE0-Nano, pois a inspiração para o circuito de comutação SDRAM foi extraída desta placa de ensaio:

Começamos a encher nosso sistema de processador. Obviamente, a primeira coisa a acrescentar é o próprio núcleo do processador. Que seja Processador E Periféricos-> Processadores Incorporados-> Processador NIOS II.
Para ele, ainda não preenchemos nenhuma propriedade. Basta clicar em Concluir, mesmo que tenhamos formado uma série de mensagens de erro. Até o momento, não há equipamentos que eliminem esses erros.
Agora adicione a SDRAM real. Interfaces e controladores de memória-> SDRAM-> Controlador SDRAM.
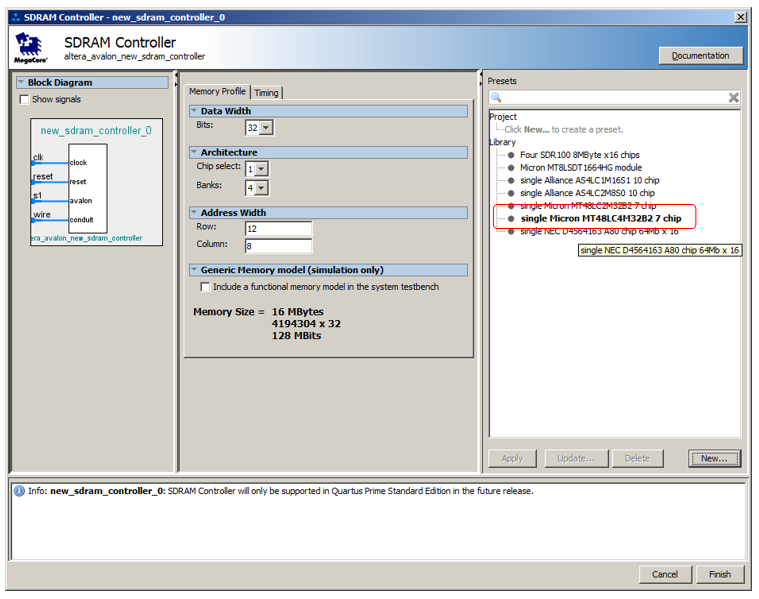
Aqui temos que nos apegar ao preenchimento das propriedades. Selecione o microcircuito mais próximo, similar na organização, na lista e clique em Apppy. Suas propriedades se enquadram nos campos Perfil da memória:
Agora, alteramos a largura do barramento de dados para 16, o número de linhas de endereço para 13 e as colunas para 9.
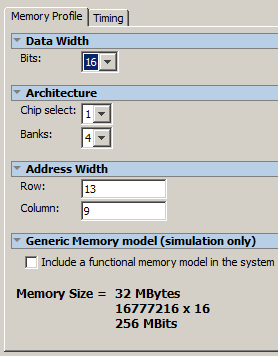
Ainda não estou corrigindo os horários, talvez no futuro essa recomendação seja alterada.
O sistema do processador implica um programa. O programa deve ser armazenado em algum lugar. Vamos testar o chip SDRAM. No momento, não podemos confiar nela. Portanto, para armazenar o programa, adicione memória com base no bloco RAM FPGA. Funções básicas-> Memória no chip-> Memória no chip (RAM ou ROM):

Volume ... Bem, sejam 32 kilobytes.

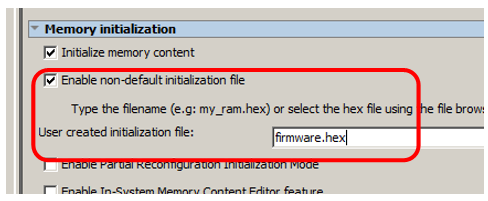
Essa memória deve estar carregando de algum lugar. Para que isso ocorra, marque a caixa Ativar arquivo de inicialização não padrão e insira um nome de arquivo significativo. Digamos firmware.hex:
O artigo já é complicado, por isso não o sobrecarregaremos. Nós simplesmente produziremos o resultado físico do teste na forma de linhas PASS / FAIL (e veremos o resultado lógico com minha depuração JTAG favorita). Para fazer isso, adicione a porta GPIO. Processadores e periféricos-> Periféricos-> PIO (IO paralelo):
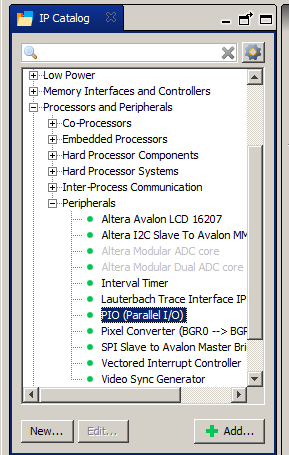
Nas propriedades que definimos 2 bits, também gosto de marcar a caixa para controle individual dos bits. Também apenas um hábito.

Temos um sistema com vários erros:

Começamos a eliminá-los. Para começar, vamos quebrar o relógio e redefinir. No relógio e na unidade de redefinição, as entradas devem ser descartadas. Para fazer isso, existem campos que dizem "Clique duas vezes para exportar":

Clicamos, mas fornecemos nomes mais ou menos abreviados.

Você também precisa jogar fora a saída do relógio SDRAM:

Agora dividimos sys_clk em todas as entradas de clock e reset_source em todas as linhas de redefinição. Você pode acertar suavemente os pontos que conectam as linhas correspondentes com o “mouse” ou pode ir para a saída correspondente, clicar com o botão direito do mouse e depois acessar o submenu Conexões no menu suspenso e selecionar as conexões.
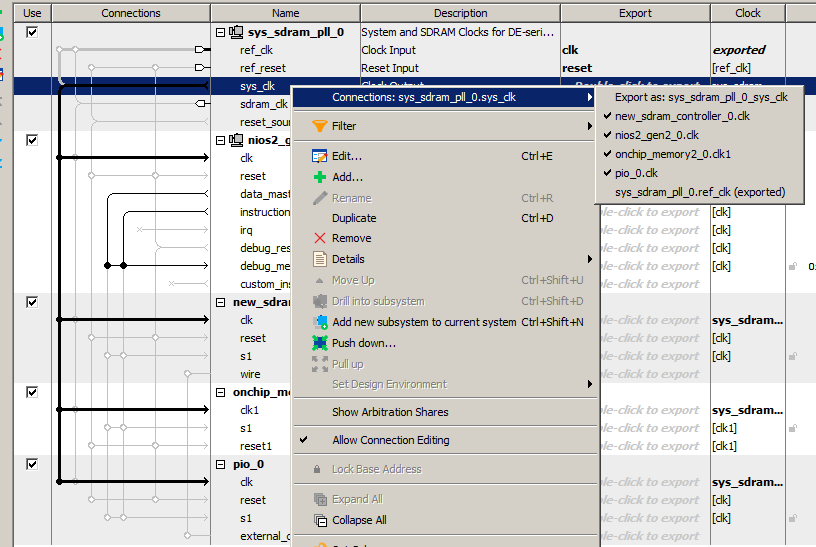

Então conectamos os pneus. Conectamos o Data Master a todos os barramentos de todos os dispositivos e o Inctruction Master - a quase todos. Não é necessário conectá-lo ao barramento PIO_0. A partir daí, as instruções definitivamente não serão lidas.

Agora você pode resolver conflitos de endereço. Para fazer isso, selecione o item de menu Sistema-> Atribuir endereços base:

E quando temos endereços, também podemos atribuir vetores. Para fazer isso, vá para as propriedades do núcleo do processador (aponte para ele, pressione o botão direito do mouse e selecione o item de menu Editar) e configure os vetores na memória Onchip. Basta selecionar esse tipo de memória nas listas suspensas, os números serão substituídos por eles mesmos.

Não há mais erros. Mas dois avisos permanecem. Esqueci de exportar as linhas SDRAM e PIO.

Como já fizemos no bloco de redefinição e relógio, clique duas vezes nas pernas necessárias e forneça os nomes mais curtos (mas compreensíveis):

Tudo, não há mais erros ou avisos. Salve o sistema. Além disso, o nome deve coincidir com o nome do projeto, para que o sistema do processador se torne um elemento de nível superior no projeto. Não se esqueceu do que chamamos?


Bem, pressionamos o botão mais importante - gerar HDL.

Tudo, a parte do processador é criada. Clique em Finish. Lembramos que seria bom adicionar este sistema de processador ao projeto:

Adicionar:

E aí, usando o botão Adicionar, obtemos a seguinte imagem:
O arquivo SIP ainda não foi criado. Sim, e não precisamos disso na estrutura deste artigo.
Uhhhh O primeiro passo foi dado. Esboçamos o projeto para que o sistema descubra a hierarquia do projeto e as etapas usadas. Erros de compilação não são assustadores. Apenas na versão gratuita do ambiente, foram criados kernels que funcionam apenas enquanto o adaptador JTAG está conectado. Mas no complexo Redd, ele está sempre conectado, pois é divorciado em um quadro comum, ou seja, não temos nada a temer. Portanto, ignoramos esses erros.

Agora, de volta à descrição do kernel da SDRAM. Diz que a linha CKE não é usada e está sempre conectada à unidade. De fato, dentro da estrutura do complexo, as pernas FPGA não são apenas caras, mas um recurso precioso. E seria tolice estender a perna, que está sempre na unidade (e no quadro DE0-NANO também não é divorciado). Haveria uma camada Verilog, a cadeia correspondente poderia ser cortada lá, mas eu economizo tempo (risos nervosos, olhando o volume do documento já obtido, mas sem salvar, o resultado seria ainda mais). Portanto, não há camada. Como ser Vá para o Editor de atribuição. Está nele, pois no Pin Planner, a julgar pelas descrições, não há funcionalidade semelhante.

Ainda não há linha. Bom Crie um novo

Selecionamos o seguinte ícone:

No sistema de pesquisa que definimos, clique em Lista e, nos resultados da pesquisa, encontramos nossa CKE:
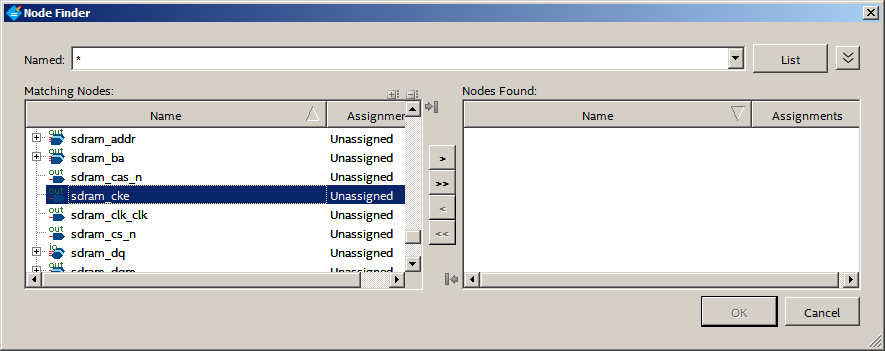
Adicione-o à coluna da direita, clique em OK.
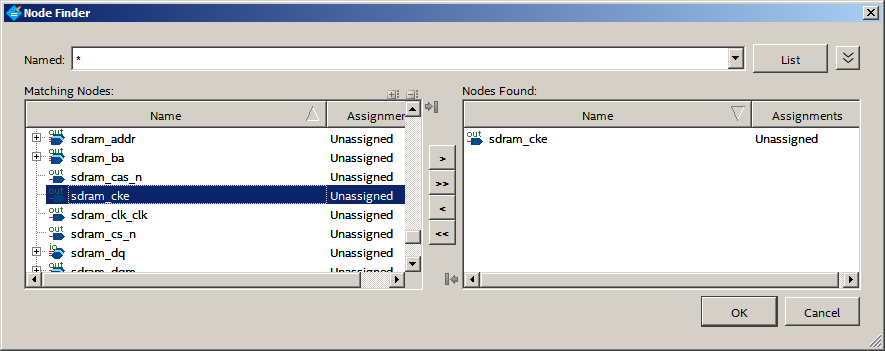
Temos a seguinte lista:

No campo amarelo, clique na lista suspensa e localize o PIN virtual. Nós escolhemos. O amarelo mudou-se para outra célula:

Lá, selecionamos Ativado:
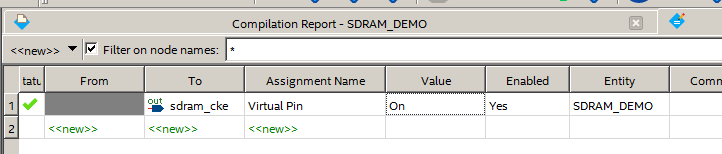
Todo o amarelo se foi. E a cadeia agora está marcada como virtual, o que significa que não requer uma perna física. Portanto, não podemos atribuí-lo à conclusão física do FPGA. Feche o Editor de atribuição, abra o Planejador de pinos. Você pode atribuir as pernas, consultando a figura, ou pode obter a lista do arquivo * .qsf, que faz parte do projeto, que anexarei ao artigo.

É isso aí, feche o Pin Planner, realizamos a compilação final do projeto. O hardware está pronto, prosseguimos com o desenvolvimento do software para o sistema de processador resultante. Mas o artigo ficou tão grande que vamos fazê-lo na
próxima vez .