
Hoje, a alta disponibilidade de serviços é necessária sempre e em qualquer lugar, não apenas em grandes projetos caros. Sites temporariamente indisponíveis com a mensagem "Desculpe, a manutenção está sendo executada" ainda ocorrem, mas geralmente causam um sorriso condescendente. Adicione a isso a vida nas nuvens, quando iniciar um servidor adicional, você precisará de apenas uma chamada para a API e não precisará pensar na operação "de ferro". E não há mais desculpa para o fato de o sistema crítico não ter sido criado de maneira confiável usando tecnologias de cluster e redundância.
Nós lhe diremos quais as soluções que consideramos para garantir a confiabilidade dos bancos de dados em nossos serviços e para o que chegamos. Além de uma demonstração com conclusões de longo alcance.
Legado na arquitetura de alta disponibilidade
Isso é ainda melhor visto no contexto do desenvolvimento de vários sistemas de código-fonte aberto. As soluções antigas foram forçadas a adicionar tecnologias de alta disponibilidade à medida que a demanda aumentava. E a qualidade deles era diferente. As soluções de próxima geração colocam a alta disponibilidade no centro de sua arquitetura. Por exemplo, o MongoDB posiciona o cluster como o principal caso de uso. O cluster é dimensionado horizontalmente, o que é uma forte vantagem competitiva desse DBMS.
Voltar ao PostgreSQL. Este é um dos mais antigos projetos de código aberto populares, cujo primeiro lançamento ocorreu no 95º ano do século passado. Por um longo tempo, a equipe do projeto não considerou a alta disponibilidade como uma tarefa que precisa ser tratada pelo sistema. Portanto, a tecnologia de replicação para criar cópias de dados foi integrada apenas na versão 8.2 em 2006, mas foi arquivada (envio de log). Em 2010, a replicação de streaming apareceu na versão 9.0 e é a base para a criação de uma grande variedade de clusters. Na verdade, isso é muito surpreendente para as pessoas que conhecem o PostgreSQL após o Enterprise SQL ou o NoSQL moderno - a solução padrão da comunidade é apenas uma réplica master com replicação síncrona ou assíncrona. Ao mesmo tempo, o assistente é alternado manualmente no dreno, e também é proposto que o problema de alternar clientes seja resolvido independentemente.
Como decidimos criar PostgreSQL confiável e o que escolhemos para isso
No entanto, o PostgreSQL não se tornaria tão popular se não houvesse um grande número de projetos e ferramentas que ajudassem a criar uma solução tolerante a falhas que não requer atenção constante. Desde o lançamento do DBaaS, servidores PostgreSQL únicos e pares de réplicas principais com replicação assíncrona estão disponíveis no
Mail.ru Cloud Solutions (MCS).
Naturalmente, queríamos simplificar a vida de todos e disponibilizar a instalação do PostgreSQL, o que poderia servir de base para serviços altamente acessíveis que você não precisaria monitorar e acordar constantemente à noite para fazer a troca. Nesse segmento, existem soluções antigas e comprovadas e uma geração de novos utilitários que utilizam os últimos desenvolvimentos.
Hoje, o problema da alta disponibilidade não se baseia na redundância (nem é preciso dizer), mas no consenso - um algoritmo para a escolha de um líder (eleição do líder). Na maioria das vezes, acidentes graves ocorrem não por falta de servidores, mas por problemas de consenso: um novo líder não saiu, dois líderes apareceram em data centers diferentes etc. Um exemplo é uma falha no cluster MySQL do Github - eles escreveram um
post mortem detalhado .
A base matemática nesta questão é muito séria. Por um lado, existe um
teorema do CAP , que impõe restrições teóricas à possibilidade de construir soluções de HA, por outro lado, algoritmos de determinação de consenso matematicamente comprovados, como
Paxos e
Raft . Nesta base, existem DCS (sistemas de consenso descentralizados) bastante populares - Zookeeper, etcd, Consul. Portanto, se o sistema de tomada de decisão funcionar com algum algoritmo próprio, escrito de forma independente, você deve ser extremamente cuidadoso. Depois de analisar um grande número de sistemas, decidimos pelo Patroni - um sistema de código aberto, desenvolvido principalmente por Zalando.
Como digressão lírica, direi que também consideramos soluções multimestre, ou seja, clusters que podem ser escalados horizontalmente para gravação. No entanto, por dois motivos principais, eles decidiram não criar um cluster desse tipo. Em primeiro lugar, essas soluções têm alta complexidade e, consequentemente, mais vulnerabilidades. Será difícil tomar uma decisão estável para todos os casos. Em segundo lugar, neste caso, o PostgreSQL deixa de ser puro (nativo), algumas funções estarão indisponíveis, alguns aplicativos podem enfrentar bugs ocultos.
Patroni
Então, como o Patroni funciona? Os desenvolvedores não reinventaram a roda e sugeriram o uso de uma das soluções DCS comprovadas como base. Todos os problemas com sincronização de configurações, escolha de um líder e quorum são dados a ele. Nós escolhemos o etcd para isso.
Além disso, o Patroni lida com a aplicação correta de todas as configurações no PostgreSQL e nas configurações de replicação, bem como a execução de comandos na alternância e failover (ou seja, assistentes de alternância regulares e não padrão). Especificamente, na nuvem MCS, você pode criar um cluster a partir de um assistente, uma réplica síncrona e uma ou mais réplicas assíncronas. A presença de uma réplica síncrona garante a segurança dos dados em pelo menos 2 servidores, e essa réplica será o principal "candidato ao mestre".
Como o etcd é implantado nos mesmos servidores, é recomendável que o número de servidores seja 3 ou 5, para obter o valor ideal do quorum. Esse cluster é dimensionado horizontalmente para leitura (escrevi sobre dimensionamento para a escrita acima). No entanto, deve-se ter em mente que as réplicas assíncronas estão atrasadas, especialmente em altas cargas.
O uso dessas réplicas de leitura em espera é justificado para tarefas de relatório ou analíticas e descarrega o servidor mestre.
Se você deseja criar um cluster assim, precisará:
- prepare 3 ou mais servidores, configure o endereçamento IP e regras de firewall entre eles;
- instalar pacotes para serviços etcd, Patroni, PostgreSQL;
- configurar o cluster etcd;
- configure o serviço patroni para trabalhar com o PostgreSQL.
Ou seja, no total, você precisa compor corretamente uma dúzia de arquivos de configuração e não cometer nenhum erro. Para fazer isso, definitivamente vale a pena usar uma ferramenta de gerenciamento de configuração como Ansible, por exemplo. No entanto, ainda não existe um balanceador de TCP altamente disponível. Fazer isso é um trabalho separado.
Para aqueles que precisam de um cluster pronto, mas não querem mexer com tudo isso, tentamos simplificar nossa vida e fizemos um cluster pronto no Patroni em nossa nuvem, ele pode ser testado gratuitamente. Além do próprio cluster, fizemos:
- Balanceador de TCP em portas diferentes, sempre aponta para a réplica mestre atual, síncrona ou assíncrona, respectivamente;
- API para alternar o assistente ativo do Patroni.
Eles podem ser conectados através da API da nuvem MCS e do console da web.
Demo
Para testar os recursos do cluster PostgreSQL na nuvem MCS, vamos ver como um aplicativo ativo se comporta em caso de problemas com o DBMS.
A seguir, está o código de um aplicativo que registrará eventos artificiais e reportará isso à tela. Em caso de erros, ele reportará isso e continuará seu trabalho em um ciclo até que paremos com a combinação Ctrl + C.
from __future__ import print_function from datetime import datetime from random import randint from time import sleep import psycopg2 def main(): try: connection = psycopg2.connect(user = "admin", password = "P@ssw0rd", host = "89.208.87.38", port = "5432", database = "myproddb") cursor = connection.cursor() cursor.execute("SELECT version();") record = cursor.fetchone() print("Connection opened to", record[0]) cursor.execute( "INSERT INTO log VALUES ({});".format(randint(1, 10000))) connection.commit() cursor.execute("SELECT COUNT(event_id) from log;") record = cursor.fetchone() print("Logged a value, overall count: {}".format(record[0])) except Exception as error: print ("Error while connecting to PostgreSQL", error) finally: if connection: cursor.close() connection.close() print("Connection closed") if __name__ == '__main__': try: while True: try: print(datetime.now()) main() sleep(3) except Exception as e: print("Caught error:\n", e) sleep(1) except KeyboardInterrupt: print("exit")
Uma aplicação precisa do PostgreSQL para funcionar. Crie um cluster na nuvem MCS usando a API. Em um terminal comum, onde a variável OS_TOKEN contém um token para acessar a API (você pode obtê-lo com o comando openstack token issue), digitamos os comandos:
Crie um cluster:
cat <<EF > pgc10.json {"cluster":{"name":"postgres10","allow_remote_access":true,"datastore":{"type":"postgresql","version":"10"},"databases":[{"name":"myproddb"}],"users":[{"databases":[{"name":"myproddb"}],"name":"admin","password":"P@ssw0rd"}],"instances":[{"key_name":"shared","availability_zone":"DP1","flavorRef":"d659fa16-c7fb-42cf-8a5e-9bcbe80a7538","nics":[{"net-id":"b91eafed-12b1-4a46-b000-3984c7e01599"}],"volume":{"size":50,"type":"DP1"}},{"key_name":"shared","availability_zone":"DP1","flavorRef":"d659fa16-c7fb-42cf-8a5e-9bcbe80a7538","nics":[{"net-id":"b91eafed-12b1-4a46-b000-3984c7e01599"}],"volume":{"size":50,"type":"DP1"}},{"key_name":"shared","availability_zone":"DP1","flavorRef":"d659fa16-c7fb-42cf-8a5e-9bcbe80a7538","nics":[{"net-id":"b91eafed-12b1-4a46-b000-3984c7e01599"}],"volume":{"size":50,"type":"DP1"}}]}} EOF curl -s -H "X-Auth-Token: $OS_TOKEN" \ -H 'Accept: application/json' \ -H 'Content-Type: application/json' \ -d @pgc10.json https://infra.mail.ru:8779/v1.0/ce2a41bbd1434013b85bdf0ba07c770f/clusters
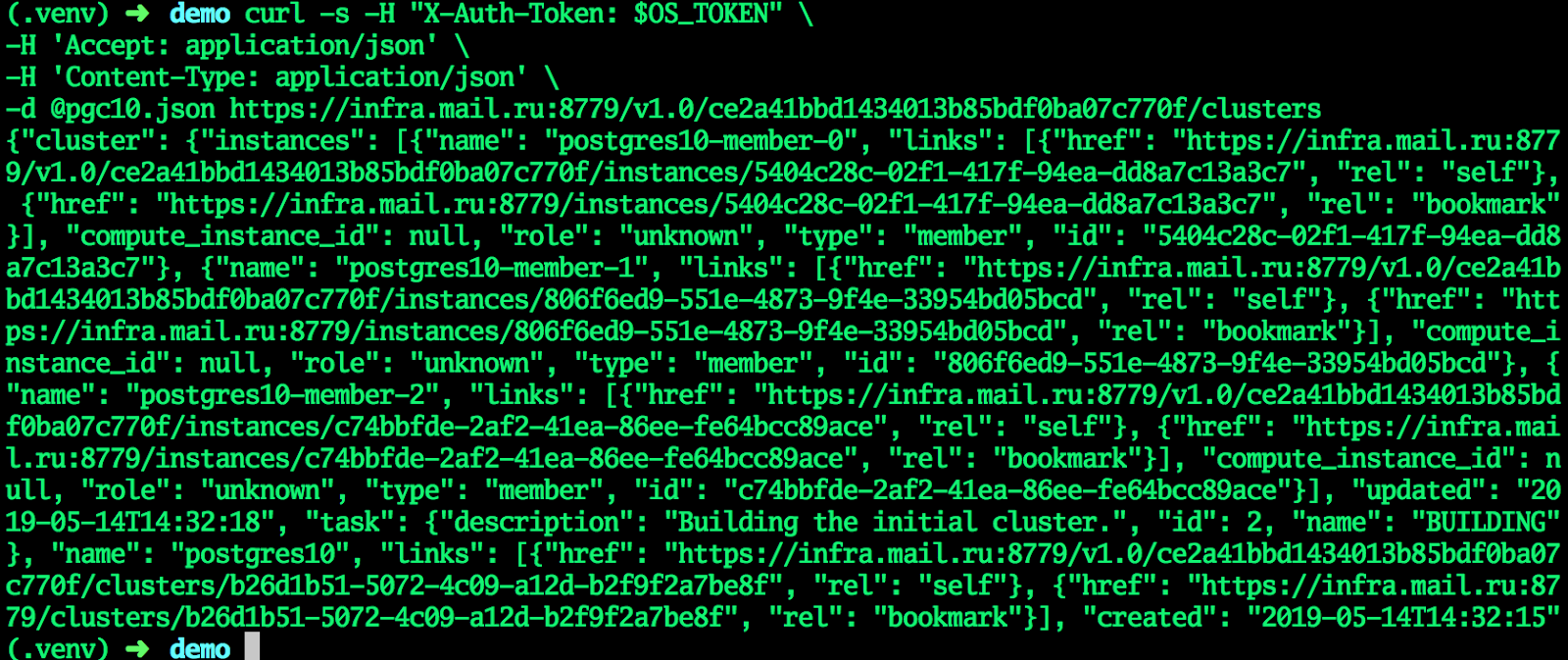
Quando o cluster entrar no status ATIVO, todos os campos receberão os valores atuais - o cluster está pronto.
Na GUI:
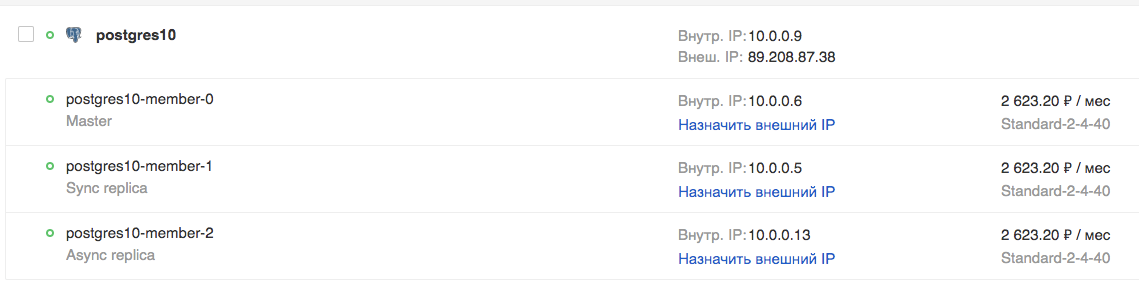
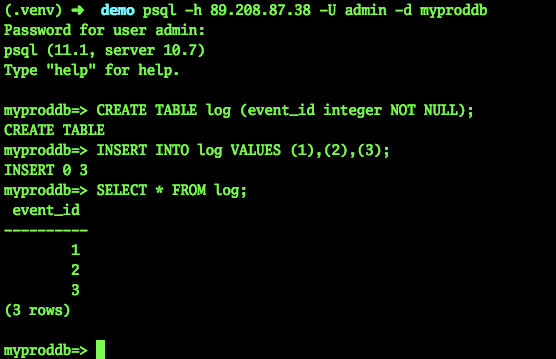
Vamos tentar conectar e criar uma tabela:
psql -h 89.208.87.38 -U admin -d myproddb Password for user admin: psql (11.1, server 10.7) Type "help" for help. myproddb=> CREATE TABLE log (event_id integer NOT NULL); CREATE TABLE myproddb=> INSERT INTO log VALUES (1),(2),(3); INSERT 0 3 myproddb=> SELECT * FROM log; event_id ---------- 1 2 3 (3 rows) myproddb=>
Na aplicação, indicamos as configurações atuais para conectar ao PostgreSQL. Nós especificaremos o endereço do balanceador de TCP, eliminando assim a necessidade de alternar manualmente para o endereço do assistente. Execute-o. Como você pode ver, os eventos são registrados com sucesso no banco de dados.

Interruptor mestre agendado
Agora, testaremos a operação do nosso aplicativo durante a alternância planejada do assistente:
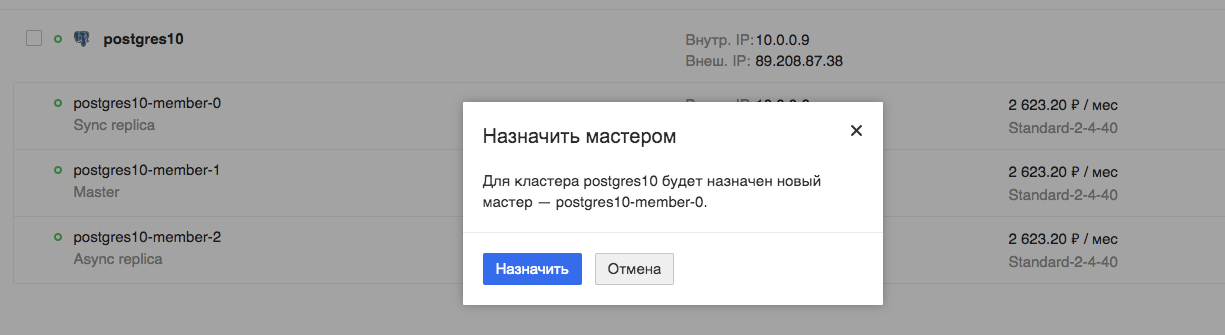
Estamos assistindo o aplicativo. Vemos que o aplicativo está realmente interrompido, mas leva apenas alguns segundos, nesse caso em particular, no máximo 9.
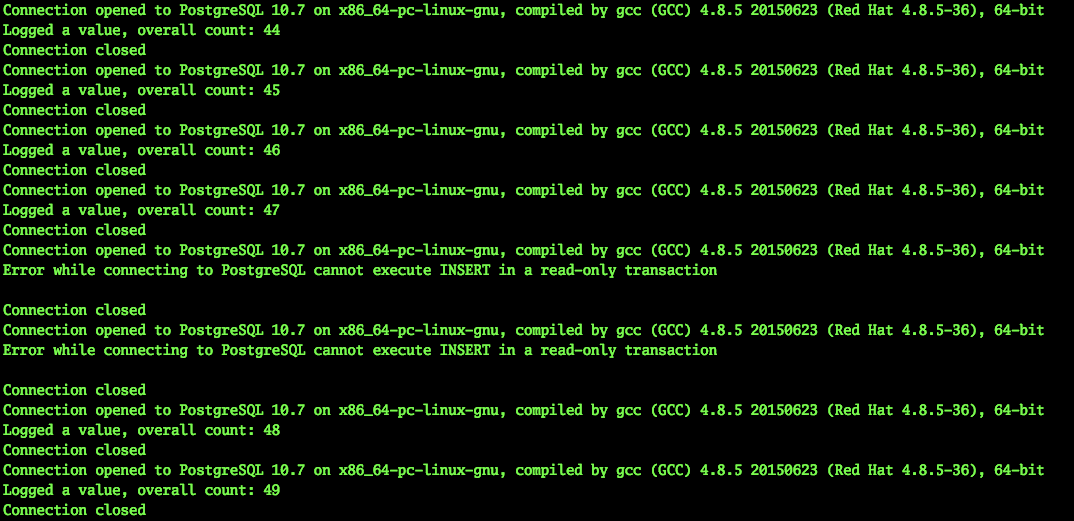
Queda de carro
Agora vamos tentar simular a queda de uma máquina virtual, o mestre atual. Seria possível simplesmente desligar a máquina virtual através da interface Horizon, mas será um desligamento regular. Essa troca será processada por todos os serviços, incluindo a Patroni.
Precisamos de um desligamento imprevisível. Portanto, pedi aos nossos administradores para fins de teste que desligassem a máquina virtual - o mestre atual - de maneira anormal.
Ao mesmo tempo, nosso aplicativo continuou funcionando. Naturalmente, esse interruptor de emergência do mestre não pode passar despercebido.
2019-03-29 10:45:56.071234 Connection opened to PostgreSQL 10.7 on x86_64-pc-linux-gnu, compiled by gcc (GCC) 4.8.5 20150623 (Red Hat 4.8.5-36), 64-bit Logged a value, overall count: 453 Connection closed 2019-03-29 10:45:59.205463 Connection opened to PostgreSQL 10.7 on x86_64-pc-linux-gnu, compiled by gcc (GCC) 4.8.5 20150623 (Red Hat 4.8.5-36), 64-bit Logged a value, overall count: 454 Connection closed 2019-03-29 10:46:02.661440 Error while connecting to PostgreSQL server closed the connection unexpectedly This probably means the server terminated abnormally before or while processing the request. Caught error: local variable 'connection' referenced before assignment ……………………………………………………….. - - 2019-03-29 10:46:30.930445 Error while connecting to PostgreSQL server closed the connection unexpectedly This probably means the server terminated abnormally before or while processing the request. Caught error: local variable 'connection' referenced before assignment 2019-03-29 10:46:31.954399 Connection opened to PostgreSQL 10.7 on x86_64-pc-linux-gnu, compiled by gcc (GCC) 4.8.5 20150623 (Red Hat 4.8.5-36), 64-bit Logged a value, overall count: 455 Connection closed 2019-03-29 10:46:35.409800 Connection opened to PostgreSQL 10.7 on x86_64-pc-linux-gnu, compiled by gcc (GCC) 4.8.5 20150623 (Red Hat 4.8.5-36), 64-bit Logged a value, overall count: 456 Connection closed ^Cexit
Como você pode ver, o aplicativo conseguiu continuar seu trabalho em menos de 30 segundos. Sim, um certo número de usuários do serviço terá tempo para perceber problemas. No entanto, esta é uma falha grave do servidor, isso não ocorre com tanta frequência. Ao mesmo tempo, a pessoa (administrador) dificilmente conseguiria reagir tão rapidamente, a menos que estivesse sentado no console pronto com um script de comutação.
Conclusão
Parece-me que esse cluster oferece uma tremenda vantagem para os administradores. De fato, falhas graves e mau funcionamento dos servidores de banco de dados não serão perceptíveis para o aplicativo e, consequentemente, para o usuário. Você não precisará reparar algo com pressa e mudar para configurações temporárias, servidores etc. E se você usar esta solução na forma de um serviço pronto na nuvem, não precisará perder tempo preparando-a. Será possível fazer algo mais interessante.