
Se você administra uma infraestrutura virtual baseada no VMware vSphere (ou em qualquer outra pilha de tecnologia), provavelmente ouve reclamações dos usuários: "A máquina virtual está lenta!". Nesta série de artigos, analisarei as métricas de desempenho e explicarei o que e por que "desacelera" e como garantir que não "desacelere".
Vou considerar os seguintes aspectos de desempenho das máquinas virtuais:
Vou começar com a CPU.
Para análise de desempenho, precisamos de:
- Os contadores de desempenho do vCenter são contadores de desempenho cujos gráficos podem ser visualizados no vSphere Client. As informações sobre esses contadores estão disponíveis em qualquer versão do cliente (cliente "grosso" em C #, cliente da web no Flex e cliente da web em HTML5). Nesses artigos, usaremos capturas de tela do cliente C #, apenas porque elas ficam melhores em miniatura :)
- ESXTOP é um utilitário que é executado na linha de comando do ESXi. Com sua ajuda, você pode obter os valores dos contadores de desempenho em tempo real ou fazer upload desses valores por um determinado período em um arquivo .csv para análise posterior. Em seguida, vou falar mais sobre essa ferramenta e fornecer alguns links úteis para documentação e artigos relacionados.
Pouco de teoria
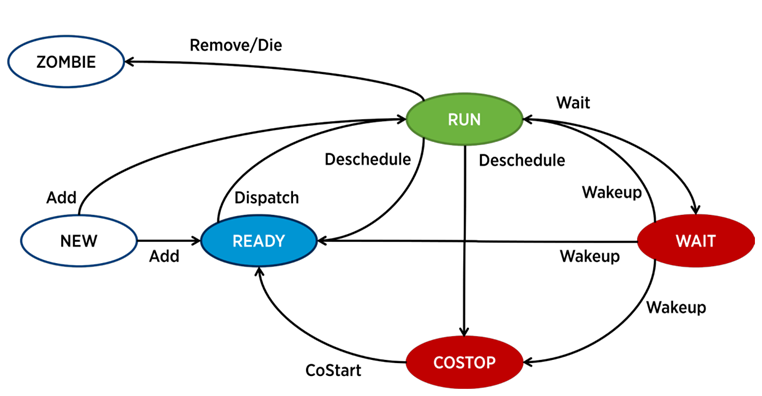
No ESXi, um processo separado é responsável pela operação de cada vCPU (núcleo da máquina virtual) - o mundo na terminologia VMware. Também existem processos de serviço, mas do ponto de vista da análise de desempenho da VM, eles são menos interessantes.
Um processo no ESXi pode estar em um dos quatro estados:
- Executar - o processo faz algum trabalho útil.
- Aguardar - o processo não realiza nenhum trabalho (inativo) ou está aguardando entrada / saída.
- Costop é uma condição que ocorre em máquinas virtuais com vários núcleos. Ocorre quando o agendador de CPU do hipervisor (ESXi CPU Scheduler) não pode agendar todos os núcleos ativos da máquina virtual para execução simultânea nos núcleos físicos do servidor. No mundo físico, todos os núcleos de processador funcionam em paralelo; o SO convidado na VM espera um comportamento semelhante; portanto, o hipervisor precisa desacelerar os núcleos da VM, que têm a capacidade de concluir a batida mais rapidamente. Nas versões modernas do ESXi, o agendador de CPU usa um mecanismo chamado co-agendamento relaxado: o hipervisor considera a lacuna entre o núcleo da máquina virtual mais rápido e mais lento (inclinação) Se a diferença exceder um determinado limite, o núcleo rápido entra no estado de custo. Se os núcleos da VM passarem muito tempo nesse estado, isso poderá causar problemas de desempenho.
- Pronto - o processo entra nesse estado quando o hypervisor não tem a capacidade de alocar recursos para sua execução. Valores altos prontos podem causar problemas de desempenho da VM.
Contadores básicos de desempenho da CPU de uma máquina virtual
Uso da CPU,%. Mostra a porcentagem de uso da CPU por um determinado período.
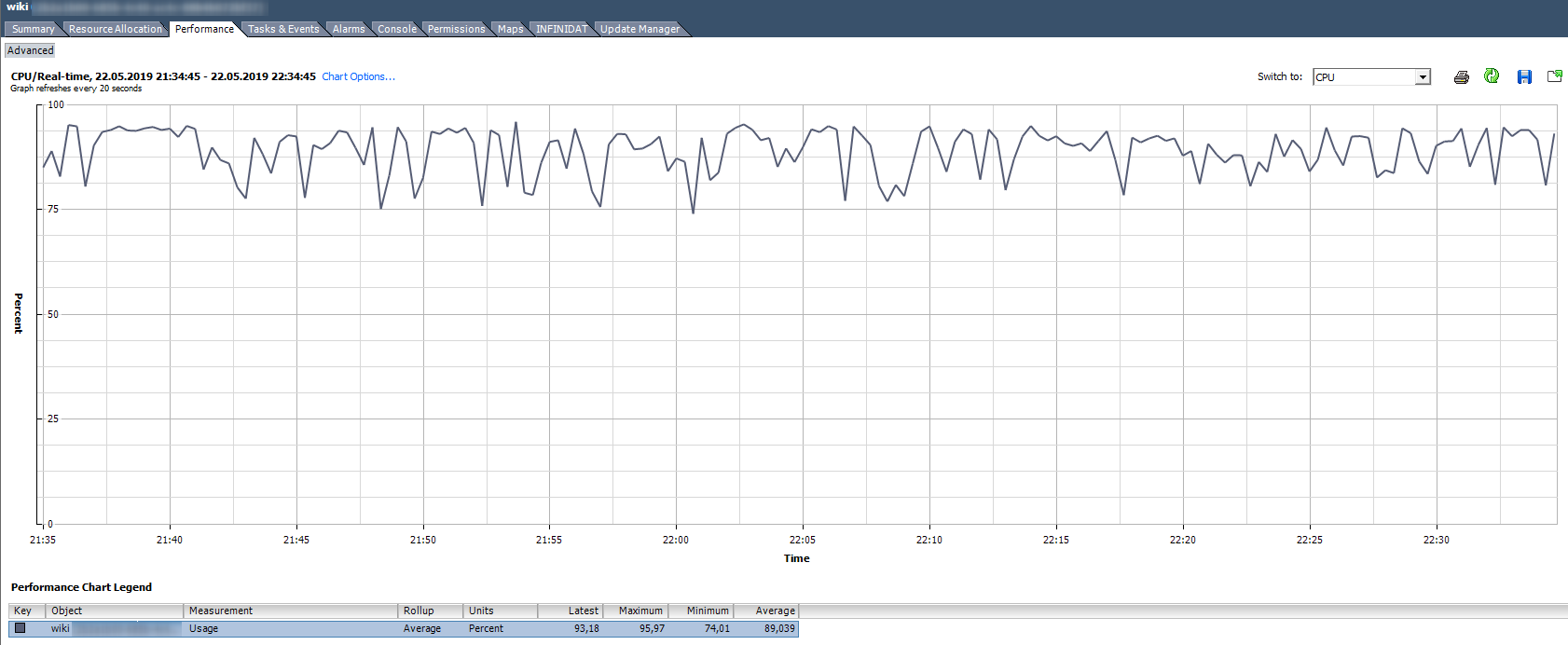 Como analisar?
Como analisar? Se a VM usar esta CPU de forma estável para 90% ou houver picos de até 100%, teremos problemas. Os problemas podem ser expressos não apenas na operação "lenta" do aplicativo dentro da VM, mas também na inacessibilidade da VM pela rede. Se o sistema de monitoramento mostrar que a VM cai periodicamente, preste atenção aos picos no gráfico Uso da CPU.
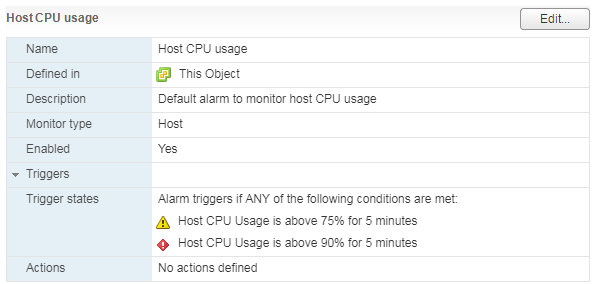
Há um alarme padrão, que mostra a carga da CPU da máquina virtual:
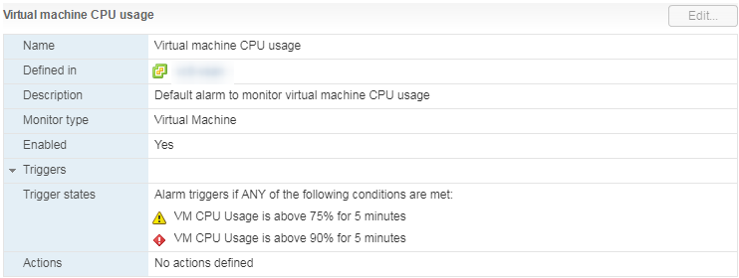 O que fazer
O que fazer Se o uso da CPU sobrecarregar constantemente a VM, você poderá aumentar o número de vCPUs (infelizmente, isso nem sempre ajuda) ou transferir as VMs para um servidor com processadores mais eficientes.
Uso da CPU em Mhz
Nos gráficos de uso do vCenter em%, você pode ver apenas a máquina virtual inteira, não há gráficos para núcleos individuais (o Esxtop possui valores em% para núcleos). Para cada núcleo, você pode ver Uso em MHz.
Como analisar? Acontece que o aplicativo não é otimizado para a arquitetura multinúcleo: ele usa 100% apenas um núcleo e o restante fica ocioso sem carga. Por exemplo, com as configurações de backup padrão, o MS SQL inicia o processo em apenas um núcleo. Como resultado, o backup é mais lento, não devido à velocidade lenta do disco (é sobre isso que o usuário reclamou inicialmente), mas porque o processador não pode lidar com isso. O problema foi resolvido alterando os parâmetros: o backup começou a ser executado em paralelo em vários arquivos (respectivamente, em vários processos).
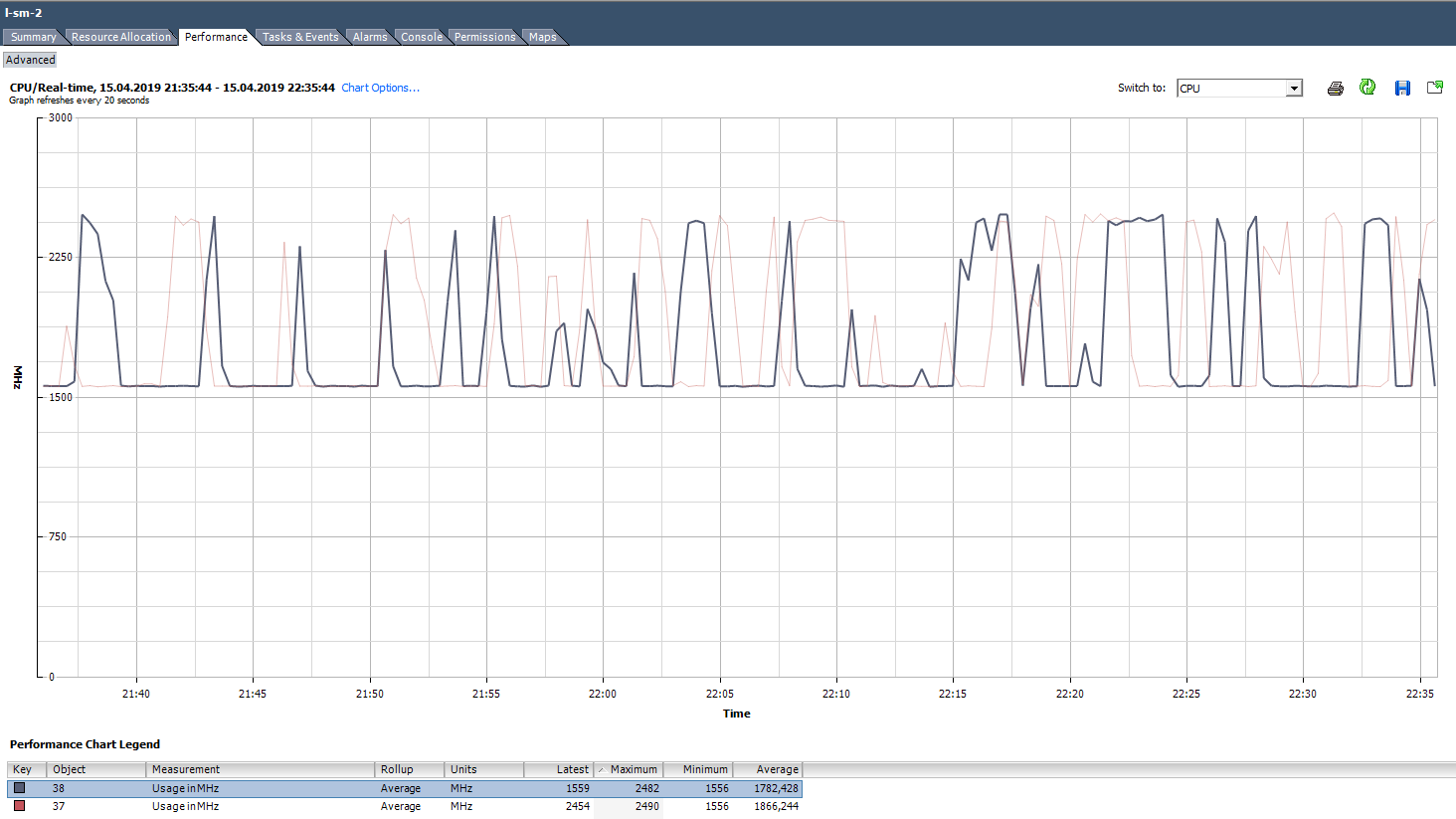 Um exemplo de uma carga desigual de núcleos.
Um exemplo de uma carga desigual de núcleos.Também existe uma situação (como no gráfico acima) quando os núcleos são carregados de maneira desigual e alguns deles têm picos de 100%. Assim como o carregamento de apenas um núcleo, o alarme no uso da CPU não funcionará (está presente em toda a VM), mas haverá problemas de desempenho.
O que fazer Se o software na máquina virtual carrega os kernels de maneira desigual (usa apenas um núcleo ou parte dos kernels), não há sentido em aumentar seu número. Nesse caso, é melhor mover a VM para um servidor com processadores mais eficientes.
Você também pode tentar verificar as configurações de energia no BIOS do servidor. Muitos administradores ativam o modo de alto desempenho no BIOS e, assim, desativam as tecnologias de economia de energia dos estados C e P. Os modernos processadores Intel usam a tecnologia Turbo Boost, que aumenta a frequência de núcleos de processadores individuais devido a outros núcleos. Mas ele funciona apenas com as tecnologias de economia de energia incluídas. Se os desligarmos, o processador não poderá reduzir o consumo de energia dos kernels que não estão carregados.
A VMware recomenda não desativar as tecnologias de economia de energia nos servidores, mas escolher modos que maximizem o gerenciamento de energia para o hipervisor. Ao mesmo tempo, nas configurações de energia do hipervisor, você precisa selecionar Alto desempenho.
Se você tiver VMs (ou núcleos de VM) separados em sua infraestrutura que exijam uma frequência de CPU aumentada, a configuração correta do consumo de energia poderá melhorar significativamente seu desempenho.
Pronto para CPU (prontidão)
Se o núcleo da VM (vCPU) estiver no estado Pronto, ele não fará um trabalho útil. Essa condição ocorre quando o hypervisor não encontra um núcleo físico livre ao qual o processo de vCPU da máquina virtual pode ser designado.
Como analisar? Normalmente, se os núcleos da máquina virtual estiverem no estado Pronto por mais de 10% do tempo, você notará problemas de desempenho. Simplificando, mais de 10% do tempo que uma VM espera pela disponibilidade de recursos físicos.
No vCenter, você pode ver 2 contadores associados ao CPU Ready:
Os valores de ambos os contadores podem ser visualizados em toda a VM e em kernels individuais.
A prontidão mostra o valor imediatamente em porcentagem, mas apenas em tempo real (dados da última hora, intervalo de medição 20 segundos). Esse contador é melhor usado apenas para procurar problemas "em busca".
Os valores dos contadores prontos também podem ser visualizados em perspectiva histórica. Isso é útil para estabelecer padrões e para uma análise mais profunda do problema. Por exemplo, se uma máquina virtual começar a ter problemas de desempenho em algum momento específico, você poderá comparar os intervalos do valor de CPU Ready travado com a carga total no servidor em que a VM está sendo executada e tomar medidas para reduzir a carga (se o DRS não conseguir lidar).
Pronto, diferente da prontidão, é mostrado não em porcentagens, mas em milissegundos. Este é um contador do tipo Somatório, ou seja, mostra quanto tempo o núcleo da VM ficou no estado Pronto durante o período de medição. Você pode converter esse valor em porcentagem por uma fórmula simples:
(Valor da soma da CPU pronta / (intervalo de atualização padrão do gráfico em segundos * 1000)) * 100 =% da CPU pronta
Por exemplo, para VMs no gráfico abaixo, o valor de pico de Pronto para toda a máquina virtual é o seguinte:
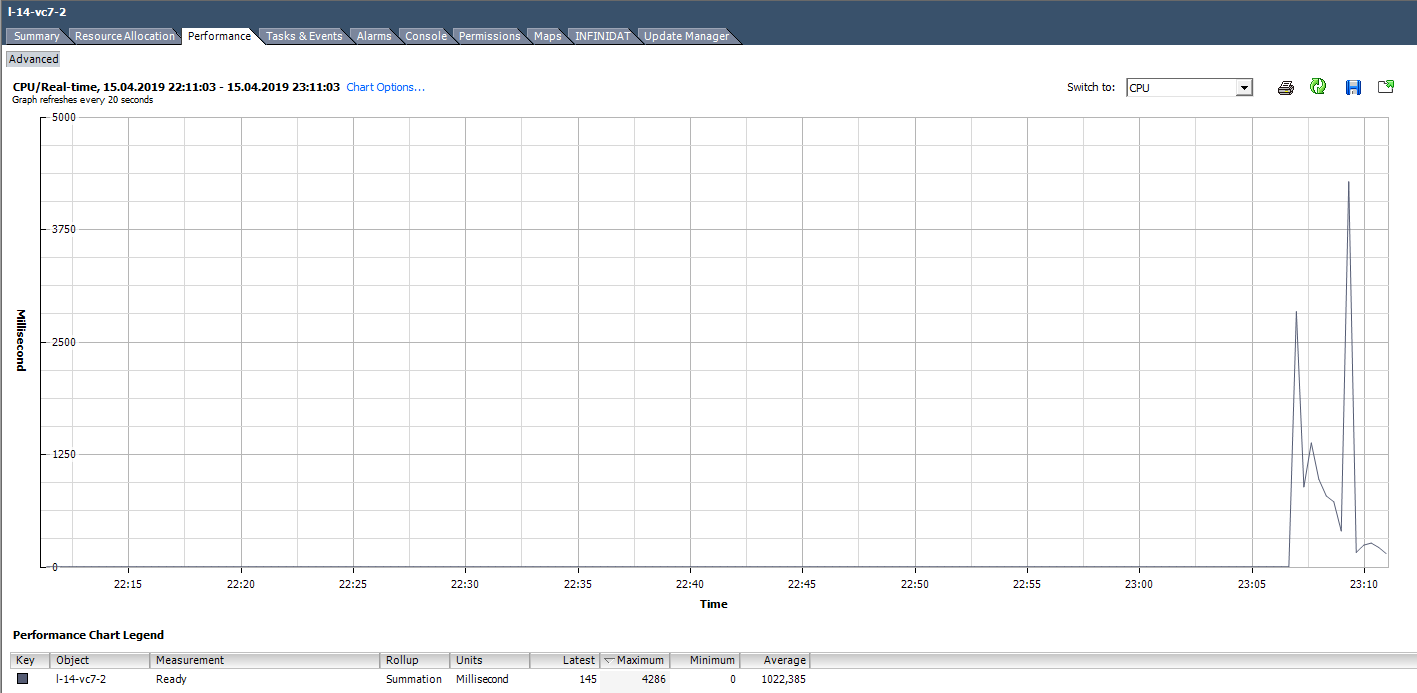
Ao calcular o valor Pronto como uma porcentagem, você deve prestar atenção a dois pontos:
- O valor de Ready em toda a VM é a soma de Ready entre os núcleos.
- Intervalo de medição. Em tempo real, são 20 segundos e, por exemplo, nos gráficos diários, são 300 segundos.
Com a solução de problemas ativa, esses pontos simples podem ser facilmente perdidos e um tempo valioso pode ser gasto na solução de problemas inexistentes.
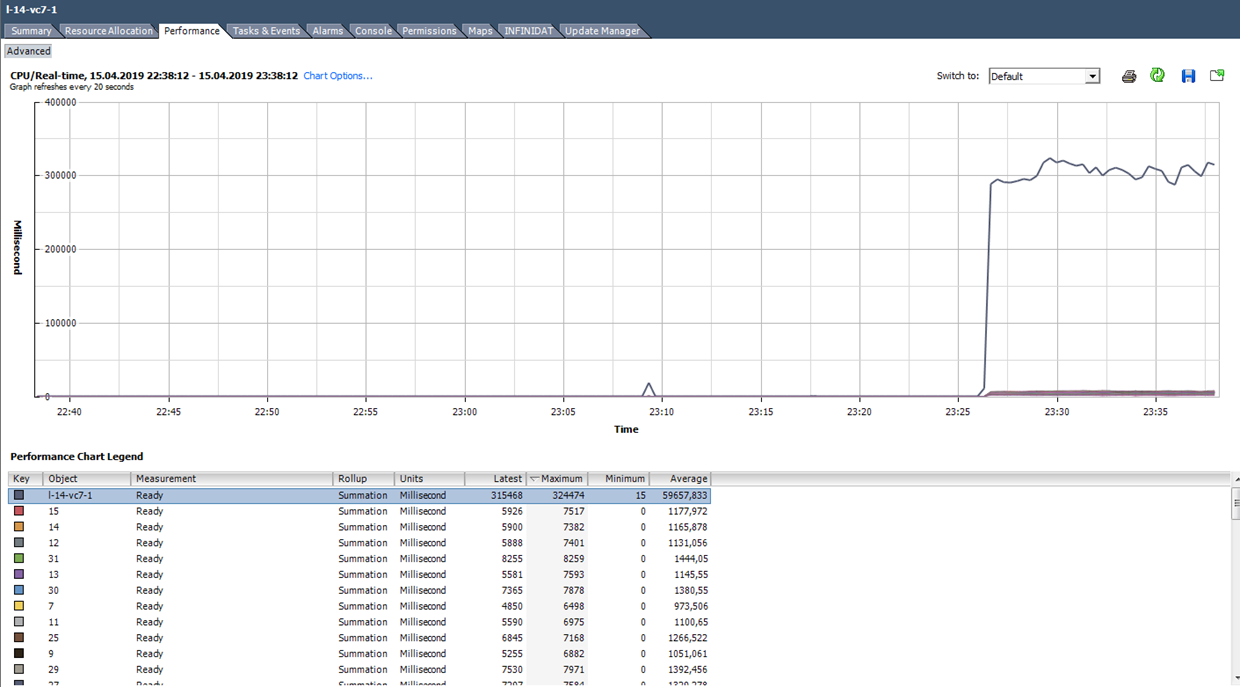
Calculamos Ready com base nos dados do gráfico abaixo. (324474 / (20 * 1000)) * 100 = 1622% para toda a VM. Se você olhar para os núcleos, será menos assustador: 1622/64 = 25% por núcleo. Nesse caso, detectar um truque é bastante simples: o valor Pronto é irrealista. Mas se falamos de 10 a 20% para toda a VM com vários núcleos, então para cada núcleo, o valor pode estar dentro do intervalo normal.
 O que fazer
O que fazer Um valor alto de Pronto indica que o servidor não possui recursos de processador suficientes para a operação normal de máquinas virtuais. Nessa situação, resta apenas reduzir a sobrescrição no processador (vCPU: pCPU). Obviamente, isso pode ser alcançado reduzindo os parâmetros das VMs existentes ou migrando parte da VM para outros servidores.
Co-stop
Como analisar? Esse contador também tem o tipo de soma e se traduz em porcentagens como Pronto:
(Valor de soma de parada da CPU / (intervalo de atualização padrão do gráfico em segundos * 1000)) * 100 =% de parada da CPU
Aqui você também precisa prestar atenção ao número de núcleos por VM e ao intervalo de medição.
No estado costop, o kernel não faz um trabalho útil. Com a seleção correta do tamanho da VM e carga normal no servidor, o contador de co-parada deve estar próximo de zero.
 Nesse caso, a carga é claramente anormal :)O que fazer
Nesse caso, a carga é claramente anormal :)O que fazer Se várias VMs com um grande número de núcleos estiverem em execução no mesmo hipervisor e houver excesso de assinatura na CPU, o contador de co-stop poderá aumentar, o que levará a problemas com o desempenho dessas VMs.
Além disso, a co-parada aumentará se os threads forem usados para kernels ativos de uma VM no mesmo núcleo do servidor físico com a hipertrilha ativada. Essa situação pode surgir, por exemplo, se a VM tiver mais núcleos do que fisicamente no servidor em que trabalha ou se a configuração "preferHT" estiver ativada para a VM. Você pode ler sobre essa configuração
aqui .
Para evitar problemas com o desempenho da VM devido à alta co-parada, selecione o tamanho da VM de acordo com as recomendações do fabricante do software que é executado nesta VM e com os recursos do servidor físico em que a VM está sendo executada.
Não adicione kernels na reserva, isso pode causar problemas de desempenho, não apenas na própria VM, mas também nos vizinhos do servidor.
Outras métricas úteis da CPU
Executar - quanto tempo (ms) para o período de medição da vCPU estava no estado RUN, ou seja, realmente executou um trabalho útil.
Inativo - quanto tempo (ms) para o período de medição da vCPU ficou inativo. Valores altos de inatividade não são um problema, apenas a vCPU não tinha "nada a ver".
Aguarde - quanto tempo (ms) para o período de medição da vCPU estava no estado Aguardar. Como IDLE está incluído neste contador, os altos valores de espera também não indicam um problema. Porém, se a espera for alta, o IDLE estiver baixo, a VM aguardará a conclusão das operações de E / S, e isso, por sua vez, poderá indicar um problema com o desempenho do disco rígido ou de alguns dispositivos virtuais da VM.
Máximo limitado - quanto tempo (ms) para o período de medição da vCPU estava no estado Pronto devido ao limite de recursos definido. Se o desempenho for inexplicavelmente baixo, é útil verificar o valor desse contador e o limite da CPU nas configurações da VM. As VMs podem realmente ter limites dos quais você não está ciente. Por exemplo, isso acontece quando a VM foi inclinada do modelo no qual o limite da CPU foi definido.
Espera de troca - quanto tempo a vCPU aguardou pela operação com o VMkernel Swap durante o período de medição. Se os valores desse contador estiverem acima de zero, a VM definitivamente terá problemas de desempenho. Falaremos mais sobre SWAP no artigo sobre contadores de RAM.
ESXTOP
Se os contadores de desempenho no vCenter são bons para analisar dados históricos, a análise on-line do problema é melhor realizada no ESXTOP. Aqui, todos os valores são apresentados na forma finalizada (sem necessidade de traduzir nada) e o período mínimo de medição é de 2 segundos.
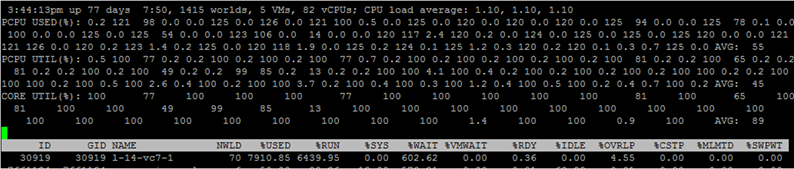
A tela ESXTOP na CPU é chamada pela tecla "c" e fica assim:

Por conveniência, você pode deixar apenas os processos da máquina virtual pressionando Shift-V.
Para ver as métricas dos núcleos individuais da VM, pressione “e” e digite o GID da VM em que você está interessado (30919 na captura de tela abaixo):

Consulte brevemente as colunas que são apresentadas por padrão. Colunas adicionais podem ser adicionadas pressionando “f”.
NWLD (número de mundos) - o número de processos no grupo. Para expandir o grupo e ver as métricas de cada processo (por exemplo, para cada núcleo de uma VM com vários núcleos), pressione "e". Se um grupo tiver mais de um processo, os valores das métricas para o grupo serão iguais à soma das métricas para os processos individuais.
% USADO - quantos ciclos a CPU do servidor usa um processo ou grupo de processos.
% RUN - quanto tempo durante o período de medição o processo estava no estado RUN, ou seja, realizou um trabalho útil. Difere de% USADO, pois não leva em consideração o hyperthreading, a escala de frequência e o tempo gasto nas tarefas do sistema (% SYS).
% SYS - tempo gasto em tarefas do sistema, por exemplo: manipulação de interrupções, entrada / saída, operação de rede etc. O valor pode ser alto se houver muita entrada / saída na VM.
% OVRLP - quanto tempo o núcleo físico no qual o processo da VM está executando gastou nas tarefas de outros processos.
Essas métricas estão relacionadas da seguinte maneira:
% USADO =% RUN +% SYS -% OVRLP.
Normalmente, a métrica% USED é mais informativa.
% WAIT - quanto tempo durante o período de medição o processo ficou no estado Wait. Inclui IDLE.
% IDLE - quanto tempo o processo ficou no estado IDLE durante o período de medição.
% SWPWT - quanto tempo a vCPU aguardou a operação com o VMkernel Swap durante o período de medição.
% VMWAIT - quanto tempo a vCPU ficou no estado de espera de um evento (geralmente E / S) durante o período de medição. Não há contador semelhante no vCenter. Valores altos indicam problemas com entrada / saída para a VM.
% WAIT =% VMWAIT +% IDLE +% SWPWT.
Se a VM não usar o VMkernel Swap, ao analisar problemas de desempenho, é recomendável examinar% VMWAIT, pois essa métrica não leva em consideração o tempo em que a VM não fez nada (% IDLE).
% RDY - quanto tempo o processo ficou no estado Pronto durante o período de medição.
% CSTP - quanto tempo o processo ficou no estado pós durante o período de medição.
% MLMTD - quanto tempo durante o período de medição da vCPU estava no estado Pronto devido ao limite de recursos definido.
% WAIT +% RDY +% CSTP +% RUN = 100% - o núcleo da VM está sempre em um desses quatro estados.
CPU no hypervisor
Também existem contadores de desempenho da CPU para o hypervisor no vCenter, mas eles não representam nada de interessante - é apenas a soma dos contadores de todas as VMs no servidor.
A maneira mais conveniente de ver o status da CPU no servidor é na guia Resumo:

Para o servidor, bem como para a máquina virtual, há um alarme padrão:
Com uma carga alta na CPU do servidor, as VMs em execução nele começam a ter problemas de desempenho.
No ESXTOP, os dados de utilização da CPU do servidor são apresentados na parte superior da tela. Além da carga padrão da CPU, que não é informativa para os hipervisores, há mais três métricas:
NÚCLEO UTIL (%) - carregando o núcleo do servidor físico. Este contador mostra quanto tempo o kernel executou o trabalho durante o período de medição.
PCPU UTIL (%) - se o
hyperthreading estiver ativado, haverá dois threads (PCPU) para cada núcleo físico. Essa métrica mostra quanto tempo cada thread fez o trabalho.
PCPU USADO (%) é o mesmo que PCPU UTIL (%), mas leva em consideração o escalonamento de frequência (diminuindo a frequência central para economia de energia ou aumentando a frequência central devido à tecnologia Turbo Boost) e o hyperthreading.
PCPU_USED% = PCPU_UTIL% * frequência central efetiva / frequência nominal central.
 Nesta captura de tela, para alguns núcleos, devido à operação do Turbo Boost, o valor USED é superior a 100%, pois a frequência do núcleo é superior ao nominal.
Nesta captura de tela, para alguns núcleos, devido à operação do Turbo Boost, o valor USED é superior a 100%, pois a frequência do núcleo é superior ao nominal.Algumas palavras sobre como o hiperencadeamento é levado em consideração. Se os processos executam 100% do tempo nos dois segmentos do núcleo físico do servidor, enquanto o núcleo é executado na frequência nominal, então:
- O CORE UTIL para o kernel será 100%,
- O PCPU UTIL para os dois segmentos será 100%,
- PCED USADO para os dois segmentos será de 50%.
Se os dois threads não funcionaram 100% do tempo durante o período de medição, nos períodos em que os threads funcionaram em paralelo, a PCPU USADA para núcleos é dividida pela metade.
O ESXTOP também possui uma tela com os parâmetros de consumo de energia do servidor da CPU. Aqui você pode ver se o servidor usa tecnologias de economia de energia: estados C e estados P. Chamado pela tecla p:

Problemas comuns de desempenho da CPU
Por fim, analisarei os motivos típicos de problemas com o desempenho da VM da CPU e darei breves dicas para resolvê-los:
Velocidade do clock do núcleo insuficiente. Se não houver maneira de transferir VMs para kernels mais eficientes, tente alterar as configurações de energia para fazer o Turbo Boost funcionar com mais eficiência.
Dimensionamento incorreto da VM (muitos / poucos núcleos). Se você colocar poucos núcleos, haverá uma carga alta na CPU da VM. Se muito, pegue um co-stop alto.
Excesso de assinatura grande na CPU no servidor. Se a VM estiver alta Pronta, reduza a assinatura em excesso na CPU.
Topologia NUMA incorreta em VMs grandes. A topologia NUMA que a VM vê (vNUMA) deve corresponder à topologia do servidor NUMA (pNUMA). Os diagnósticos e as possíveis soluções para esse problema estão escritos, por exemplo, no livro
"Deep Dive do VMware vSphere 6.5 Host Resources" . Se você não quiser ir mais fundo e não tiver restrições de licenciamento no sistema operacional instalado na VM, execute vários soquetes virtuais na VM em um único núcleo. Você não vai perder muito :)
Isso é tudo para a CPU. Faça perguntas. Na
próxima parte , falarei sobre RAM.