A identificação biométrica de uma pessoa é uma das idéias mais antigas para o reconhecimento de pessoas, que elas geralmente tentavam implementar tecnicamente. As senhas podem ser roubadas, espionadas, esquecidas, as chaves podem ser falsificadas. Mas as características únicas da própria pessoa são muito mais difíceis de falsificar e perder. Podem ser impressões digitais, voz, desenho dos vasos da retina, marcha e muito mais.

Claro, os sistemas biométricos estão tentando enganar! É sobre isso que falaremos hoje. Como os invasores tentam burlar os sistemas de reconhecimento facial personificando outra pessoa e como isso pode ser detectado.
Você pode assistir a uma versão em vídeo desta história aqui . Se você preferir ler e assistir, convido você a continuar
De acordo com as idéias dos diretores de Hollywood e dos escritores de ficção científica, é muito fácil enganar a identificação biométrica. Só é necessário apresentar ao sistema as “partes necessárias” do usuário real, individualmente ou levando-o como refém. Ou você pode "colocar a máscara" de outra pessoa, por exemplo, usando uma máscara de transplante físico ou, em geral, apresentando falsos sinais genéticos
Na vida real, os atacantes também tentam se apresentar como outra pessoa. Por exemplo, assalte um banco usando uma máscara de homem negro, como na figura abaixo.

O reconhecimento de rosto parece uma área muito promissora para uso no setor móvel. Se há muito tempo que todos estão acostumados a usar impressões digitais, e a tecnologia da voz está se desenvolvendo de forma gradual e razoavelmente previsível, então, com a identificação pela face, a situação se desenvolveu bastante incomum e digna de uma pequena digressão na história do problema.
Como tudo começou ou da ficção à realidade
Os sistemas de reconhecimento atuais demonstram uma tremenda precisão. Com o advento de grandes conjuntos de dados e arquiteturas complexas, tornou-se possível obter precisão de reconhecimento facial de até 0,000001 (um erro por milhão!) E agora eles são adequados para transferência para plataformas móveis. O gargalo era sua vulnerabilidade.
Para representar outra pessoa em nossa realidade técnica, e não no filme, as máscaras são usadas com mais frequência. Eles também tentam enganar o sistema de computador apresentando outra pessoa em vez de seu rosto. As máscaras podem ter uma qualidade completamente diferente, desde a foto de outra pessoa impressa na frente do rosto impressa na impressora a máscaras tridimensionais muito complexas com aquecimento. As máscaras podem ser apresentadas separadamente na forma de uma folha ou tela, ou usadas na cabeça.
Muita atenção foi atraída para o tópico por uma tentativa bem-sucedida de enganar o sistema Face ID no iPhone X com uma máscara bastante complexa de pó de pedra com inserções especiais ao redor dos olhos que imitam o calor de um rosto vivo usando radiação infravermelha.
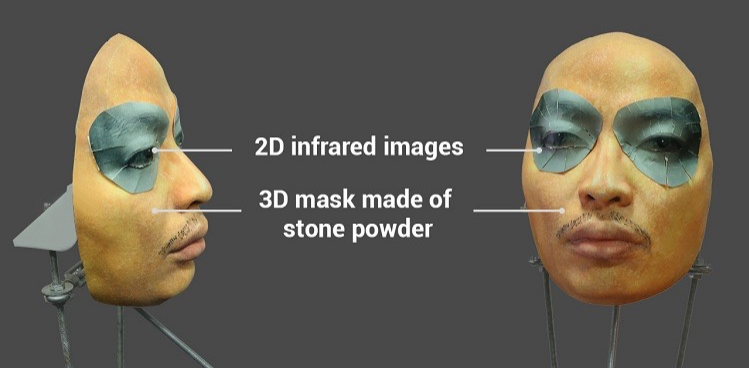
Alega-se que usando essa máscara foi possível enganar o Face ID no iPhone X. Vídeo e algum texto podem ser encontrados aqui
A presença de tais vulnerabilidades é muito perigosa para os sistemas bancários ou estaduais para autenticar um usuário pessoalmente, onde a penetração de um invasor acarreta perdas significativas.
Terminologia
O campo de pesquisa do anti-spoofing de face é bastante novo e ainda não pode se gabar nem da terminologia predominante.
Vamos concordar em chamar uma tentativa de enganar o sistema de identificação apresentando-o com um falso parâmetro biométrico (neste caso, uma pessoa) ataque de falsificação .
Consequentemente, um conjunto de medidas de proteção para combater esse engano será chamado de anti-spoofing . Ele pode ser implementado na forma de uma variedade de tecnologias e algoritmos que são incorporados ao transportador de um sistema de identificação.
A ISO oferece um conjunto de terminologias ligeiramente expandido, com termos como ataque de apresentação - tenta fazer com que o sistema identifique incorretamente o usuário ou permita que ele evite a identificação demonstrando uma imagem, um vídeo gravado etc. Normal (Bona Fide) - corresponde ao algoritmo usual do sistema, ou seja, tudo o que NÃO é um ataque. Instrumento de ataque de apresentação significa um meio de ataque, por exemplo, uma parte artificial do corpo. E, finalmente, a detecção de ataques de apresentação - meios automatizados de detectar esses ataques. No entanto, os próprios padrões ainda estão em desenvolvimento, por isso é impossível falar sobre quaisquer conceitos estabelecidos. A terminologia em russo está quase completamente ausente.
Para determinar a qualidade do trabalho, os sistemas geralmente usam a métrica HTER (Taxa de erro total da metade - metade do erro total), que é calculada como a soma dos coeficientes das identificações permitidas erroneamente (FAR - Taxa de aceitação falsa) e identificações proibidas erroneamente (FRR - Taxa de rejeição falsa), dividida ao meio.
HTER = (FAR + FRR) / 2
Vale dizer que, em sistemas biométricos, o FAR geralmente recebe a maior atenção, a fim de fazer todo o possível para impedir que um invasor entre no sistema. E eles estão fazendo um bom progresso nisso (lembra-se do milionésimo desde o início do artigo?) O outro lado é o aumento inevitável da FRR - o número de usuários comuns erroneamente classificados como intrusos. Se isso puder ser sacrificado por sistemas estatais, de defesa e outros sistemas similares, as tecnologias móveis que funcionam com sua enorme escala, uma variedade de dispositivos de assinante e, em geral, dispositivos orientados à perspectiva do usuário, são muito sensíveis a quaisquer fatores que podem fazer com que os usuários recusem serviços. Se você quiser reduzir o número de telefones esmagados contra a parede após a décima negação consecutiva de identificação, preste atenção ao FRR!
Tipos de ataques. Sistema de fraude

Por fim, vamos descobrir exatamente como os invasores enganam o sistema de reconhecimento e como isso pode ser combatido.
O meio mais popular de trapacear são as máscaras. Não há nada mais óbvio do que colocar a máscara de outra pessoa e apresentar seu rosto a um sistema de identificação (geralmente chamado de ataque de máscara).
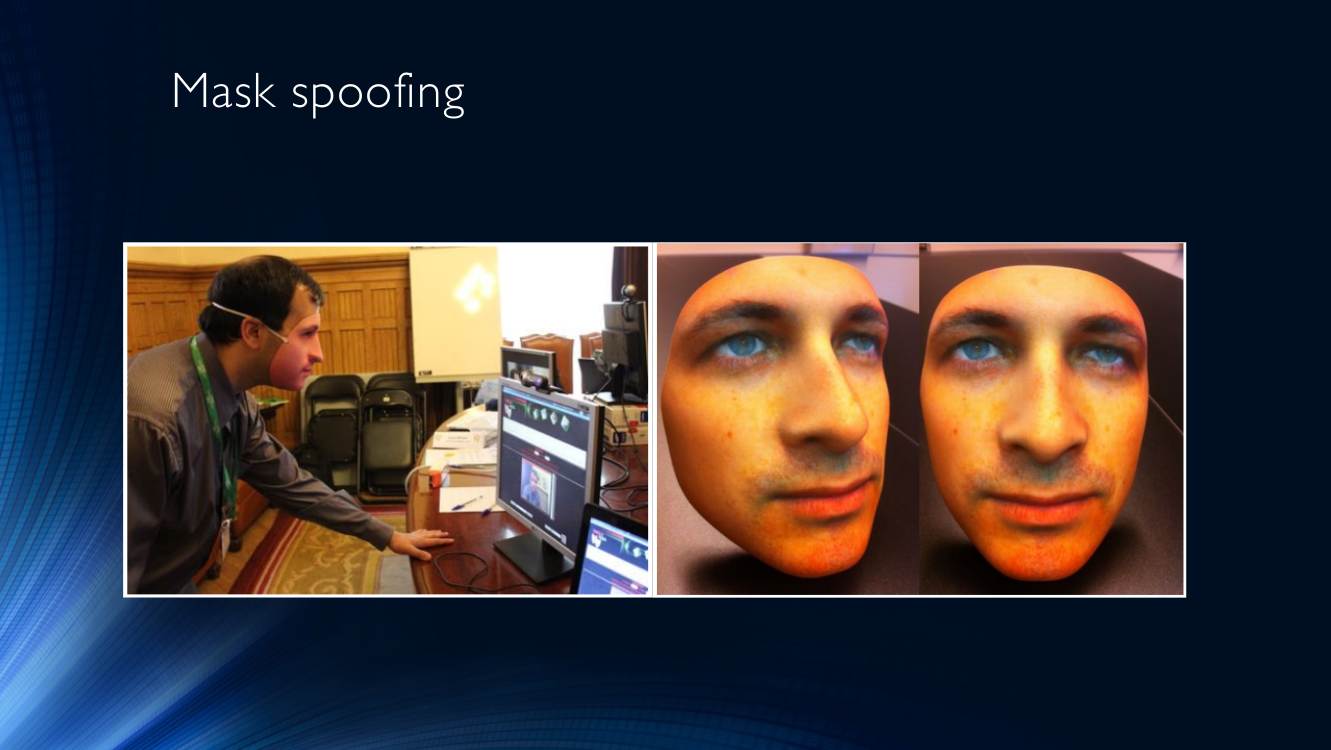
Você também pode imprimir uma foto sua ou de outra pessoa em um pedaço de papel e trazê-la para a câmera (vamos chamar esse tipo de ataque de ataque impresso).

Um pouco mais complicado é o ataque de repetição, quando o sistema é apresentado com a tela de outro dispositivo no qual um vídeo gravado anteriormente com outra pessoa é reproduzido. A complexidade da execução é compensada pela alta eficiência de um ataque desse tipo, já que os sistemas de controle costumam usar sinais baseados na análise de seqüências de tempo, por exemplo, rastreamento de piscar, micro-movimentos da cabeça, presença de expressões faciais, respiração e assim por diante. Tudo isso pode ser facilmente reproduzido em vídeo.

Ambos os tipos de ataques têm vários recursos característicos que permitem detectá-los e, assim, distinguem uma tela de tablet ou uma folha de papel de uma pessoa real.
Resumimos os recursos característicos que nos permitem identificar esses dois tipos de ataques em uma tabela:
Algoritmos de detecção de ataques. Bom velho clássico

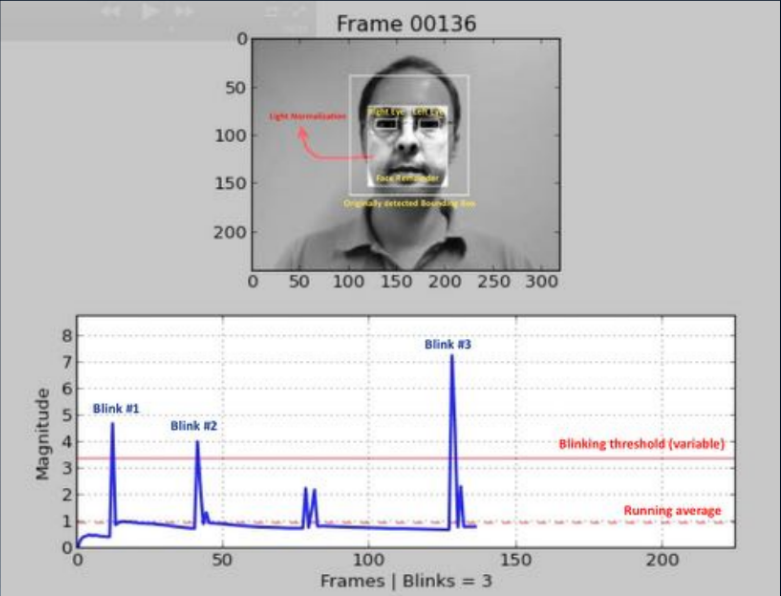
Uma das abordagens mais antigas (2007, 2008) baseia-se na detecção de piscadas humanas, analisando a imagem usando uma máscara. O objetivo é criar algum tipo de classificador binário que permita selecionar imagens com os olhos abertos e fechados em uma sequência de quadros. Isso pode ser uma análise do fluxo de vídeo usando a identificação de partes da face (detecção de ponto de referência) ou o uso de alguma rede neural simples. E hoje esse método é mais frequentemente usado; o usuário é solicitado a executar uma sequência de ações: vire a cabeça, pisque, sorria e muito mais. Se a sequência for aleatória, não é fácil para um invasor se preparar com antecedência. Infelizmente, para um usuário honesto, essa missão também nem sempre é superável, e o engajamento diminui acentuadamente.
Você também pode usar os recursos de deterioração da qualidade da imagem ao imprimir ou reproduzir na tela. Provavelmente, até alguns padrões locais, mesmo esquivos pelos olhos, serão detectados na imagem. Isso pode ser feito, por exemplo, contando padrões binários locais (LBP, padrão binário local) para diferentes áreas da face após a seleção no quadro ( PDF ). O sistema descrito pode ser considerado o fundador de toda a direção dos algoritmos de anti-spoofing de face com base na análise de imagem. Em poucas palavras, ao calcular o LBP, cada pixel da imagem, oito de seus vizinhos são capturados sequencialmente e sua intensidade é comparada. Se a intensidade for maior que no pixel central, um será atribuído, se menor, zero. Assim, para cada pixel é obtida uma sequência de 8 bits. Com base nas seqüências obtidas, é construído um histograma por pixel, que é alimentado na entrada do classificador SVM.
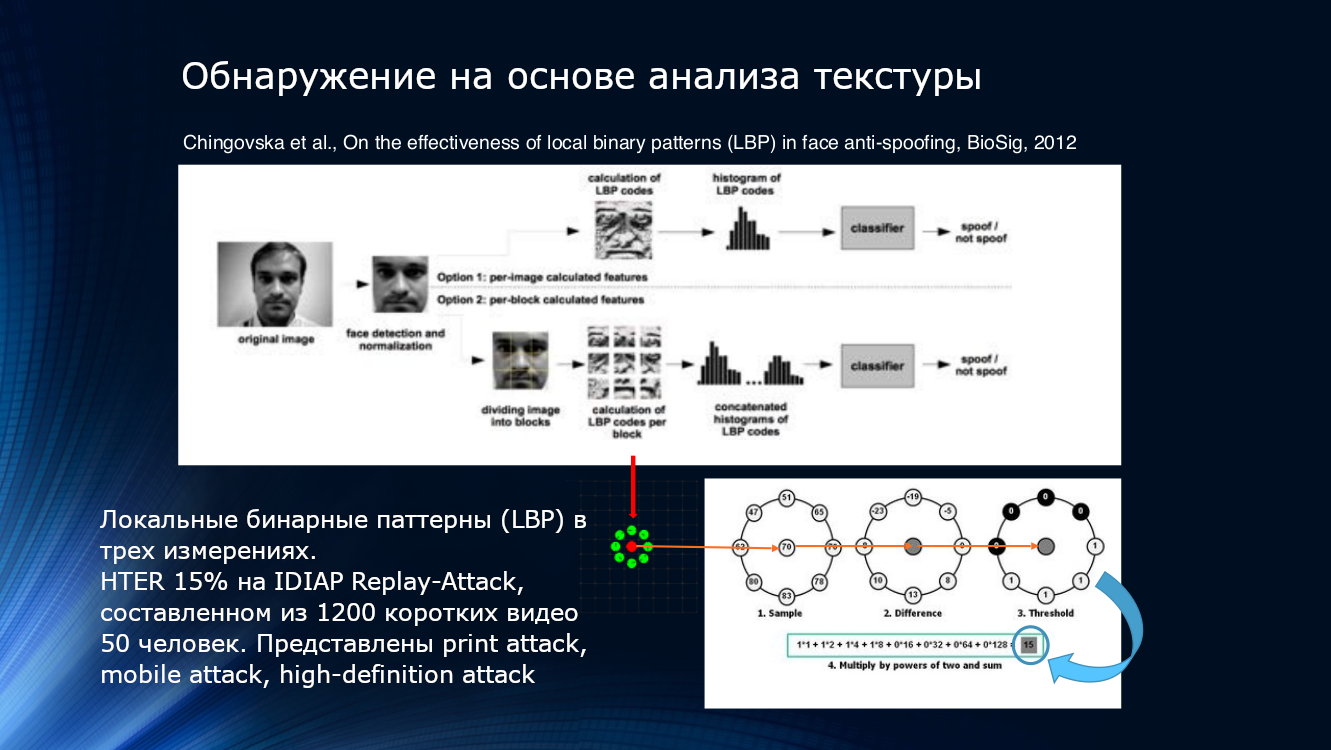
Padrões binários locais, histograma e SVM. Você pode se juntar aos clássicos atemporais aqui
O indicador de eficiência do HTER é de "até" 15% e significa que uma parte significativa dos atacantes supera a defesa sem muito esforço, embora deva-se reconhecer que muito é eliminado. O algoritmo foi testado no conjunto de dados IDIAP Replay-Attack , composto por 1200 vídeos curtos de 50 participantes e três tipos de ataques - ataque impresso, ataque móvel, ataque de alta definição.
Idéias para analisar a textura da imagem foram continuadas. Em 2015, a Bukinafit desenvolveu um algoritmo para dividir alternativamente a imagem em canais, além do RGB tradicional, para os resultados cujos padrões binários locais foram novamente calculados, que, como no método anterior, foram alimentados na entrada do classificador SVN. A precisão do HTER, calculada nos conjuntos de dados CASIA e Replay-Attack, era impressionante na época, 3%.
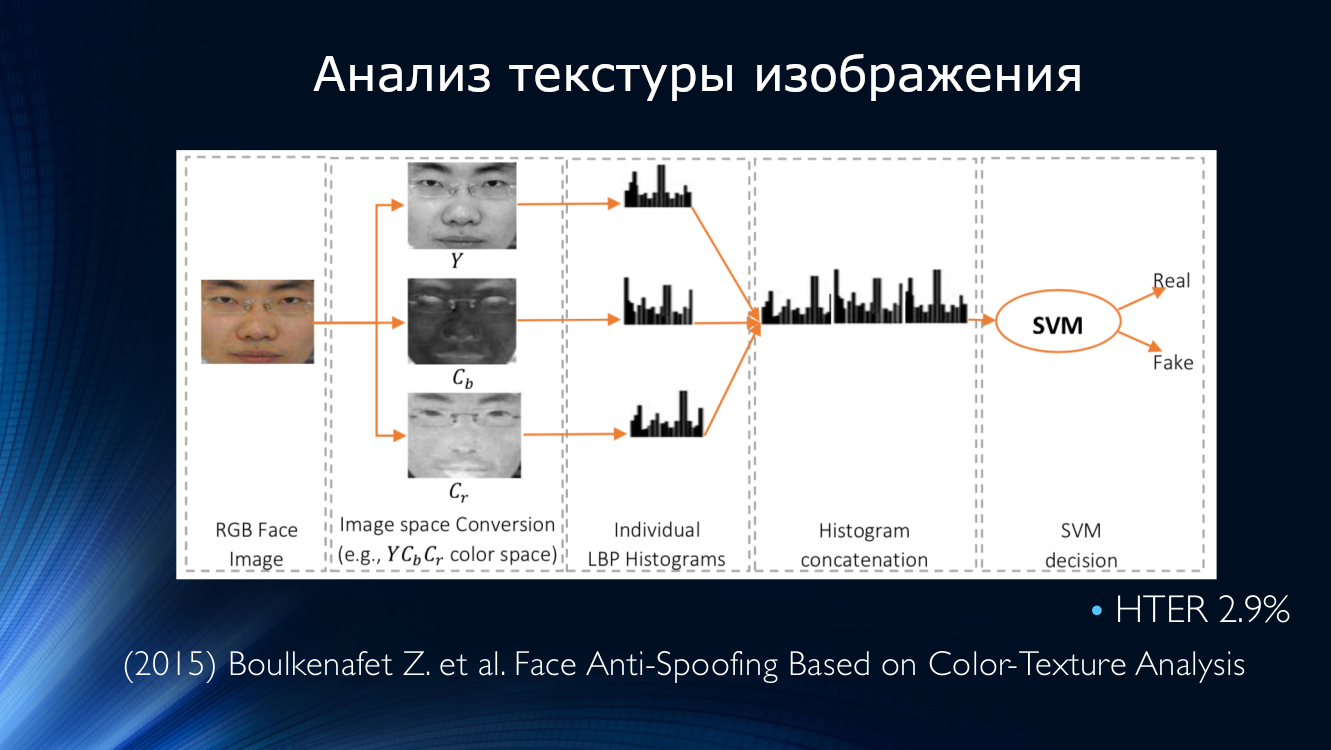
Ao mesmo tempo, apareceu um trabalho sobre a detecção de moiré. Patel publicou um artigo em que sugeria procurar artefatos de imagem na forma de um padrão periódico causado pela sobreposição de duas digitalizações. A abordagem acabou sendo viável, mostrando ao HTER cerca de 6% nos conjuntos de dados IDIAP, CASIA e RAFS. Foi também a primeira tentativa de comparar o desempenho de um algoritmo em diferentes conjuntos de dados.

Padrão periódico na imagem causado por varreduras de sobreposição
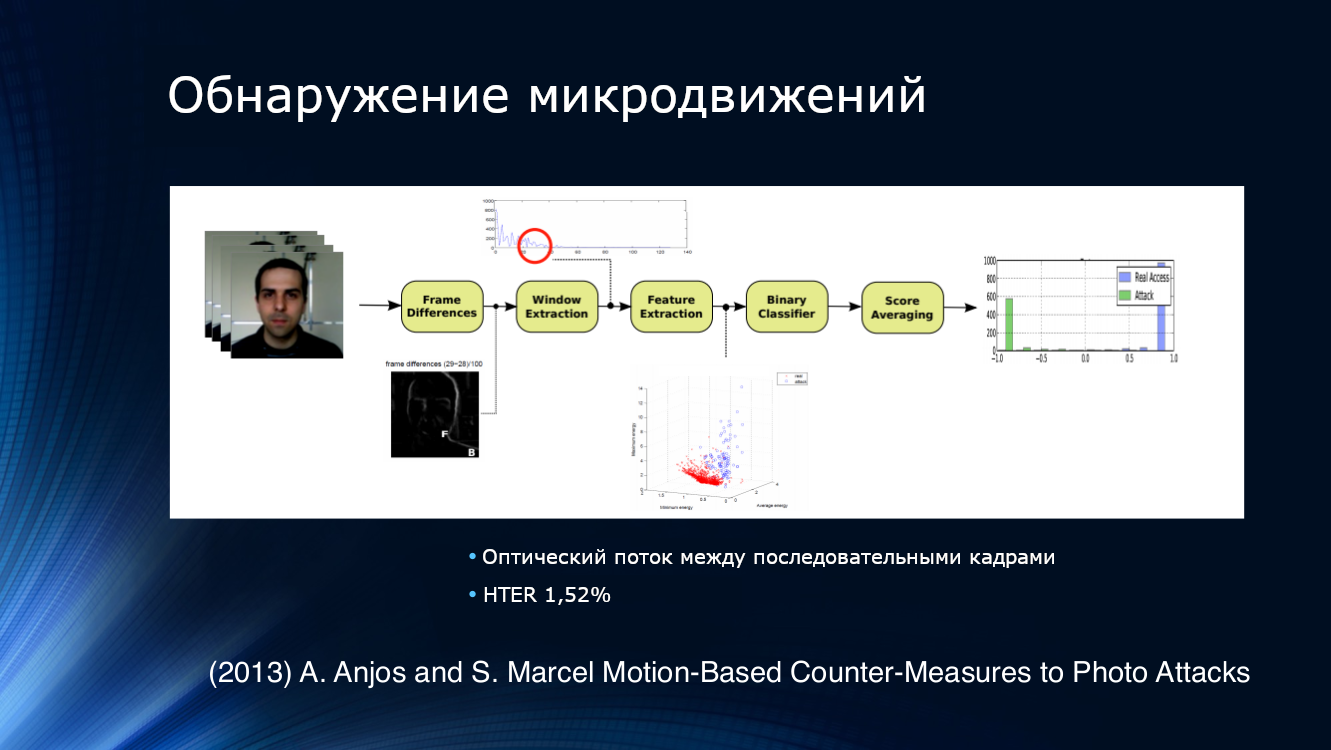
Para detectar tentativas de apresentação de fotos, a solução lógica era tentar analisar não uma imagem, mas sua sequência retirada do fluxo de vídeo. Por exemplo, Anjos e colegas sugeriram isolar recursos do fluxo óptico em pares adjacentes de quadros, alimentando o classificador binário na entrada e calculando a média dos resultados. A abordagem acabou sendo bastante eficaz, demonstrando um HTER de 1,52% em seu próprio conjunto de dados.
Um método interessante para rastrear movimentos, que é um pouco distante das abordagens convencionais. Como em 2013 o princípio “aplicar uma imagem bruta à entrada da rede convolucional e ajustar as camadas da grade para obter o resultado” não era usual nos projetos modernos de aprendizado profundo, Bharadzha aplicava consistentemente transformações preliminares mais complexas. Em particular, ele usou o algoritmo de ampliação de vídeo euleriano conhecido pelo trabalho de cientistas do MIT, que foi usado com sucesso para analisar as mudanças de cor na pele, dependendo do pulso. Substituí o LBP pelo HOOF (histogramas das direções ópticas de fluxo), tendo notado corretamente que, como queremos rastrear movimentos, precisamos de sinais apropriados, e não apenas de análise de textura. O mesmo SVM, tradicional na época, era usado como classificador. O algoritmo mostrou resultados extremamente impressionantes nos conjuntos de dados Print Attack (0%) e Replay Attack (1,25%).

Já vamos aprender a grade!

De algum ponto, ficou óbvio que a transição para o aprendizado profundo havia amadurecido. A notória "revolução do aprendizado profundo" superou a antifalsificação.
A “primeira andorinha” pode ser considerada o método de análise de mapas de profundidade em seções individuais (“remendos”) da imagem. Obviamente, um mapa de profundidade é um sinal muito bom para determinar o plano em que a imagem está localizada. Se apenas porque a imagem na folha de papel não tem "profundidade" por definição. No trabalho de Ataum em 2017, muitas pequenas seções separadas foram extraídas da imagem; mapas de profundidade foram calculados para eles, que depois se fundiram com o mapa de profundidade da imagem principal. Assinalou-se que dez amostras aleatórias de imagens faciais são suficientes para identificar de forma confiável o Ataque Impresso. Além disso, os autores reuniram os resultados de duas redes neurais convolucionais, a primeira das quais calculou mapas de profundidade para manchas e a segunda para a imagem como um todo. Durante o treinamento em conjuntos de dados, a classe Ataque Impresso foi associada a um mapa de profundidade zero e uma série de seções selecionadas aleatoriamente foi associada a um modelo de face tridimensional. Em geral, o mapa de profundidade em si não era tão importante, apenas uma determinada função indicadora foi usada, o que caracteriza a “profundidade da seção”. O algoritmo apresentou um valor HTER de 3,78%. Três conjuntos de dados públicos foram usados para treinamento - CASIA-MFSD, MSU-USSA e Replay-Attack.

Infelizmente, a disponibilidade de um grande número de excelentes estruturas para o aprendizado profundo levou ao surgimento de um grande número de desenvolvedores que estão tentando "resolver" o problema da antifalsificação de rosto de uma maneira bem conhecida de montar redes neurais. Geralmente, parece uma pilha de mapas de recursos nas saídas de várias redes pré-treinadas em alguns conjuntos de dados generalizados que são alimentados a um classificador binário.
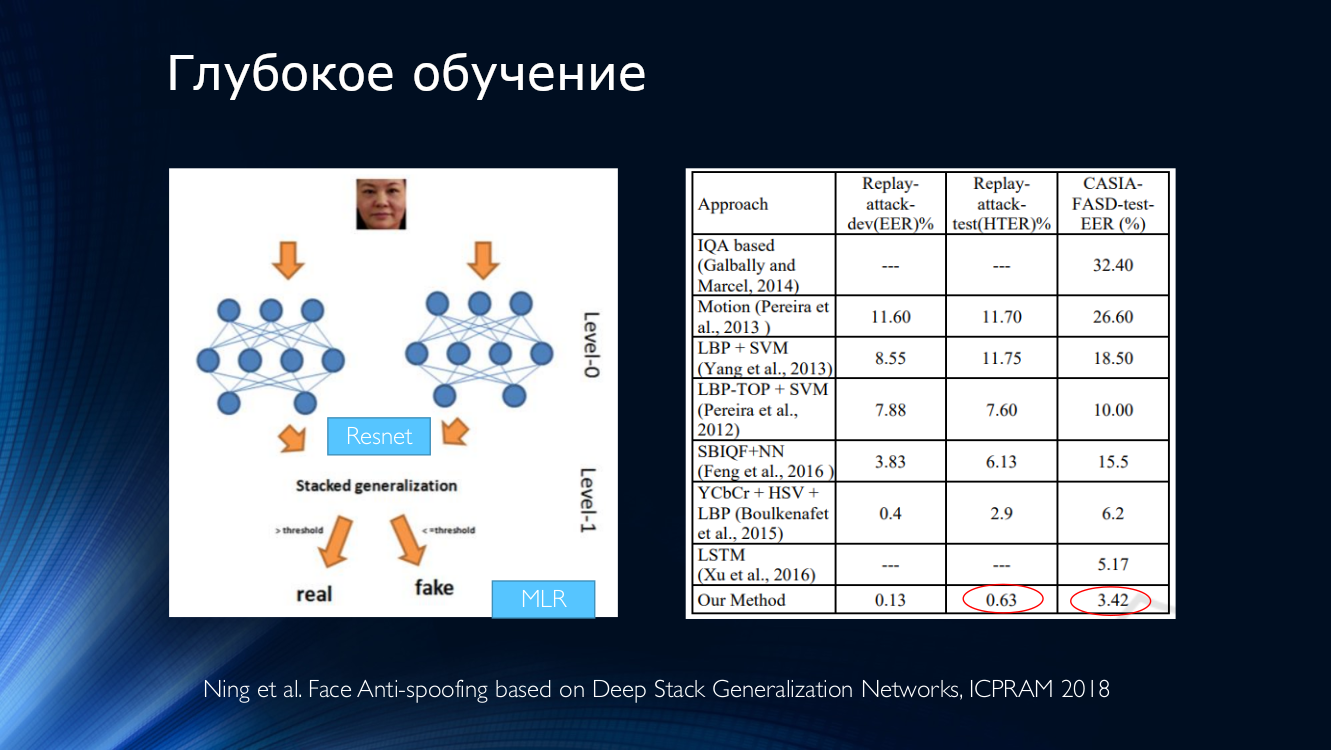
Em geral, vale a pena concluir que, até o momento, foram publicados alguns trabalhos, que geralmente apresentam bons resultados e que unem apenas um pequeno “mas”. Todos esses resultados são demonstrados em um conjunto de dados específico! A situação é agravada pela disponibilidade limitada de conjuntos de dados e, por exemplo, no notório Replay-Attack, não surpreende HTER 0%. Tudo isso leva ao surgimento de arquiteturas muito complexas, como essas , usando vários recursos engenhosos, algoritmos auxiliares montados na pilha, com vários classificadores, cujos resultados são calculados em média, e assim por diante ... Os autores obtêm HTER = 0,04% na saída!
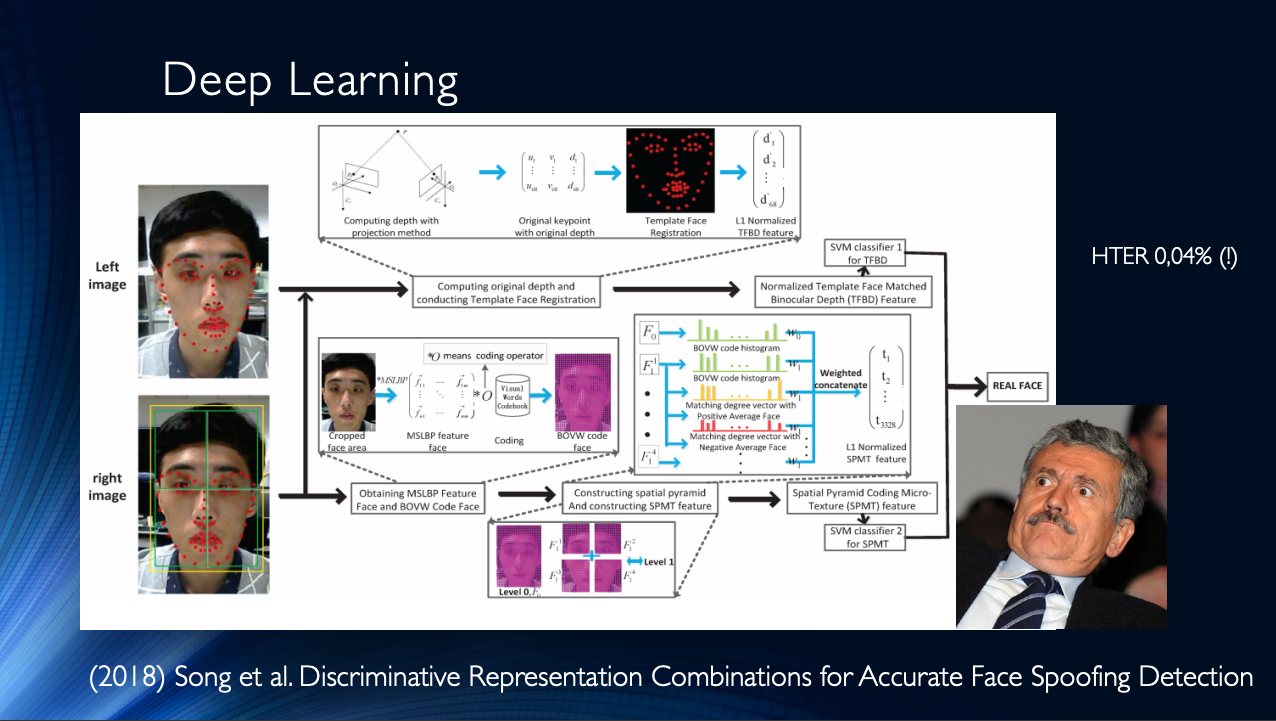
Isso sugere que o problema de antifalsificação de rosto foi resolvido em um conjunto de dados específico. Vamos trazer para a mesa vários métodos modernos baseados em redes neurais. É fácil ver que os "resultados de referência" foram alcançados por métodos muito diversos que surgiram apenas nas mentes questionadoras dos desenvolvedores.
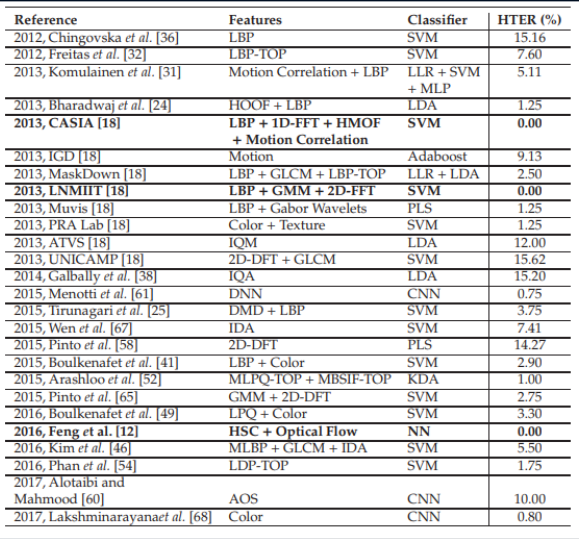
Resultados comparativos de vários algoritmos. A tabela é retirada daqui .
Infelizmente, o mesmo fator “pequeno” viola a boa imagem da luta por décimos de um por cento. Se você tentar treinar a rede neural em um conjunto de dados e aplicá-lo em outro, os resultados serão ... não tão otimistas. Pior ainda, as tentativas de aplicar classificadores na vida real não deixam nenhuma esperança.
Como exemplo, tomamos os dados de 2015, onde uma métrica de sua qualidade foi usada para determinar a autenticidade da imagem apresentada. Dê uma olhada em si mesmo:
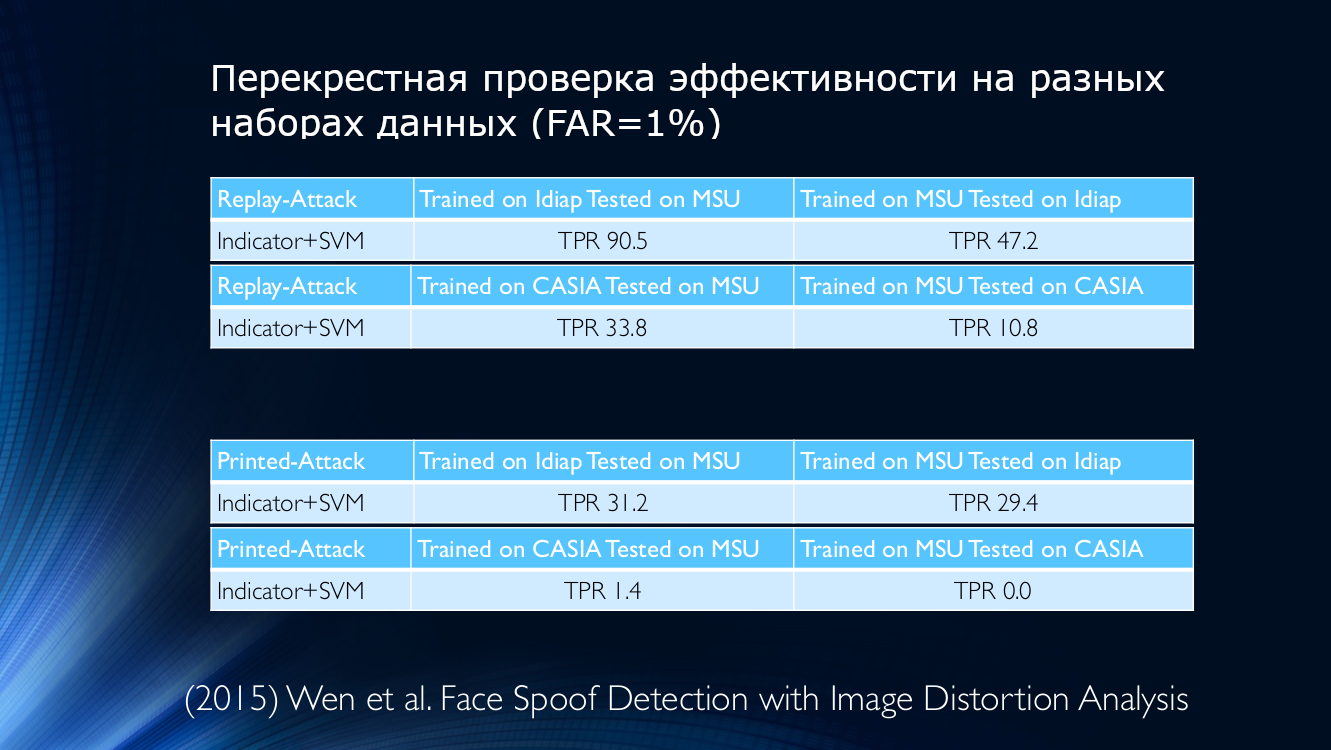
Em outras palavras, um algoritmo treinado nos dados do Idiap, mas aplicado no MSU, fornecerá uma taxa de detecção verdadeiramente positiva de 90,5%, e se você fizer o oposto (treinar no MSU e testar no Idiap), apenas 47,2 poderão ser determinados corretamente % (!) Para outras combinações, a situação piora ainda mais e, por exemplo, se você treina o algoritmo no MSU e o verifica no CASIA, o TPR será de 10,8%! Isso significa que um grande número de usuários honestos foi atribuído erroneamente aos atacantes, o que não pode deixar de ser deprimente. Mesmo o treinamento entre bancos de dados não conseguiu reverter a situação, o que parece ser uma saída perfeitamente razoável.
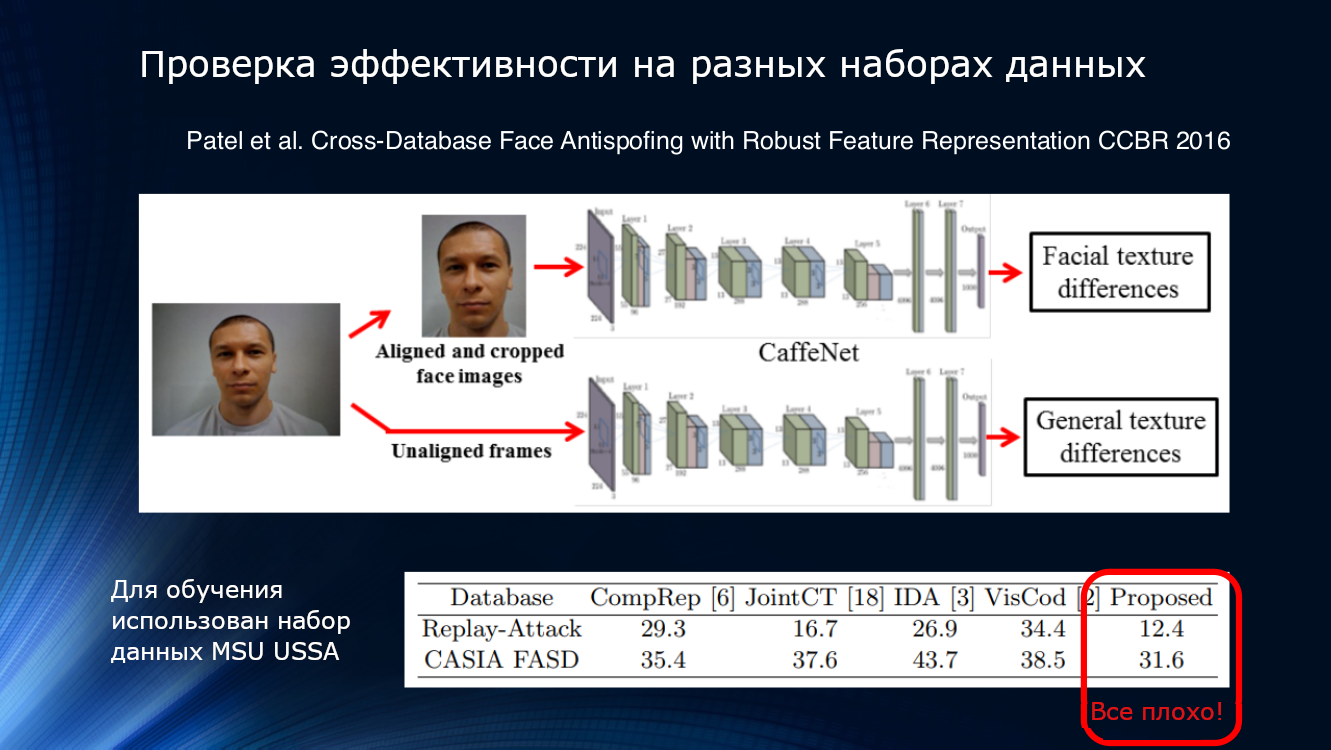
Vamos ver mais. Os resultados apresentados no artigo de Patel em 2016 mostram que, mesmo com pipelines de processamento bastante complexos e com a seleção de recursos confiáveis, como pisca e textura, os resultados em conjuntos de dados desconhecidos não podem ser considerados satisfatórios. Então, em algum momento, ficou bastante óbvio que os métodos propostos não eram desesperadamente suficientes para resumir os resultados.
E se você organizar uma competição ...
Claro, no campo da cara anti-spoofing não foi sem concorrência. Em 2017, foi realizada uma competição na Universidade de Oulu, na Finlândia, com seu próprio novo conjunto de dados com protocolos bastante interessantes, orientados especificamente para uso no campo de aplicativos móveis.
- Protocolo 1: Há uma diferença na iluminação e no fundo. Os conjuntos de dados são gravados em vários locais e diferem em segundo plano e iluminação.
Protocolo 2: Vários modelos de impressoras e telas foram usados para ataques. Portanto, no conjunto de dados de verificação, é utilizada uma técnica que não é encontrada no conjunto de treinamento
Protocolo 3: Intercambiabilidade de sensores. Vídeos e ataques de usuários reais são gravados em cinco smartphones diferentes e usados em um conjunto de dados de treinamento. , .
- 4: .
. , , , - . , , 10%. :
GRADIENT
- ( HSV YCbCr), .
- .
- HSV YCbCr, . ROI (region-of-interest) 160×160 ..
- ROI 3×3 5×5 , LBP , 6018.
- (Recursive Feature Elimination) 6018 1000.
- SVM .|
SZCVI
Recod
- SqueezeNet Imagenet
- Transfer learning : CASIA UVAD
- 224×224 pixels. , , , CNN.
- .
CPqD
- Inception-v3, ImageNet
- C
- , , 224×224 RGB |
, . LBP, , , .. GRADIANT , , , . .
. , . -, ( 15 NUAA 1140 MSU-USSA) , , , , . , , , , . -, . , CASIA , . , , , , … , , , .
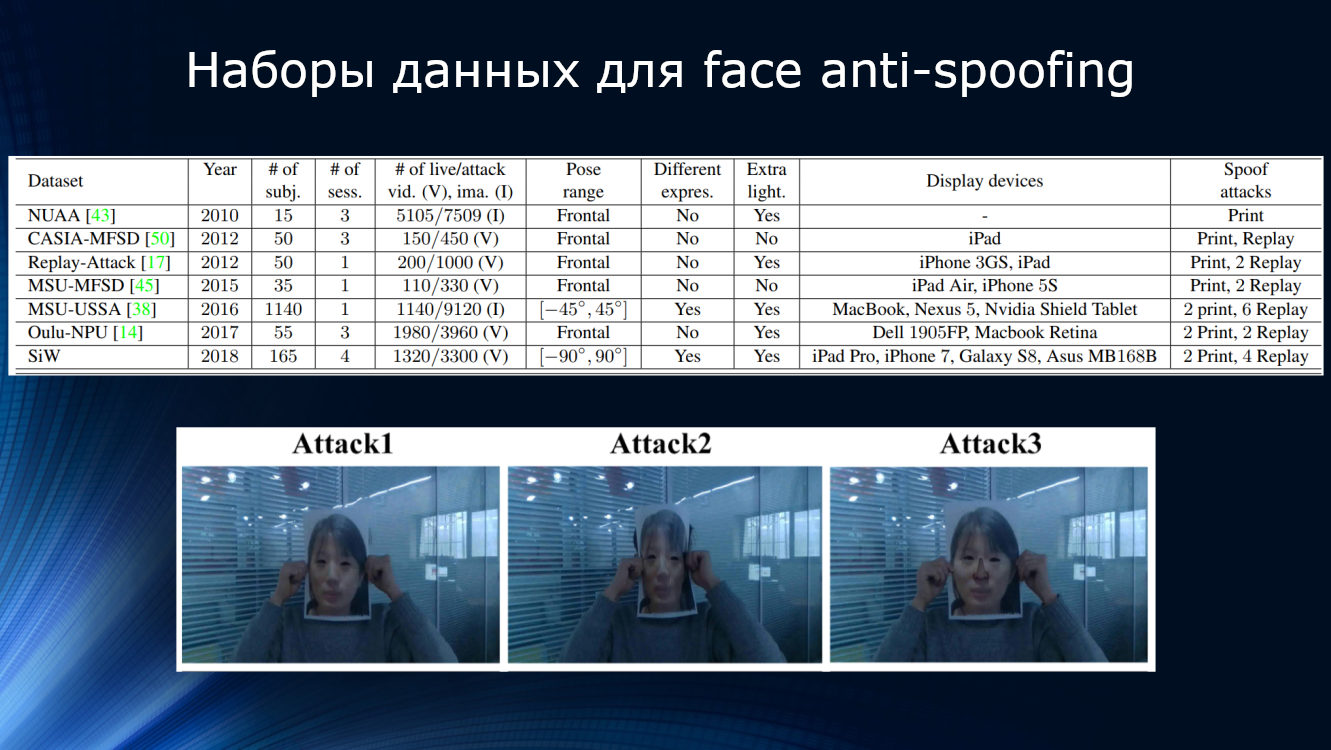
30 . , , . , .
, , « ». . , (rPPG – remote photoplethysmography), . , , -, – . . , , , . , , . , , , .


O trabalho mostrou um valor de HTER de cerca de 10%, confirmando a principal aplicabilidade do método. Existem vários trabalhos que confirmam as perspectivas dessa abordagem.
(CVPR 2018) JH-Ortega et al. Análise do tempo do rosto anti-falsificação baseado em pulso em visível e NIR
(2016) X. Li. et al. Anti-falsificação de rosto generalizada, detectando o pulso de vídeos de rosto
(2016) J. Chen et al. Realsense = frequência cardíaca real: estimativa invariável da frequência cardíaca a partir de vídeos
(2014) HE Tasli et al. Medição remota de sinais vitais baseada em PPG usando regiões faciais adaptáveis
Em 2018, Liu e colegas da Universidade de Michigan propuseram abandonar a classificação binária em favor da abordagem que eles chamaram de “supervisão binária” - ou seja, usar uma estimativa mais complexa baseada em um mapa de profundidade e em fotopletismografia remota. Para cada uma dessas imagens faciais, um modelo tridimensional foi reconstruído usando uma rede neural e nomeado com um mapa de profundidade. As imagens falsas receberam um mapa de profundidade composto por zeros, no final, é apenas um pedaço de papel ou uma tela de dispositivo! Essas características foram tomadas como “verdade”; as redes neurais foram treinadas em seu próprio conjunto de dados SiW. Em seguida, uma máscara facial tridimensional foi sobreposta à imagem de entrada, um mapa de profundidade e um pulso foram calculados, e tudo isso foi amarrado em um transportador bastante complicado. Como resultado, o método mostrou uma precisão de cerca de 10% no conjunto de dados competitivo da OULU. Curiosamente, o vencedor da competição organizada pela Universidade de Oulu construiu o algoritmo em padrões de classificação binária, rastreamento intermitente e outros sinais "projetados à mão", e sua solução também teve uma precisão de cerca de 10%. O ganho foi de apenas meio por cento! A nova tecnologia combinada é suportada pelo fato de o algoritmo ter sido treinado em seu próprio conjunto de dados e testado no OULU, melhorando o resultado do vencedor. Isso indica uma certa portabilidade dos resultados do conjunto de dados para o conjunto de dados e, o que diabos não está brincando, é possível para a vida real. No entanto, ao tentar executar o treinamento em outros conjuntos de dados - CASIA e ReplayAttack, o resultado foi novamente cerca de 28%. Obviamente, isso excede o desempenho de outros algoritmos ao treinar em vários conjuntos de dados, mas com esses valores de precisão, não se pode falar em nenhum uso industrial!
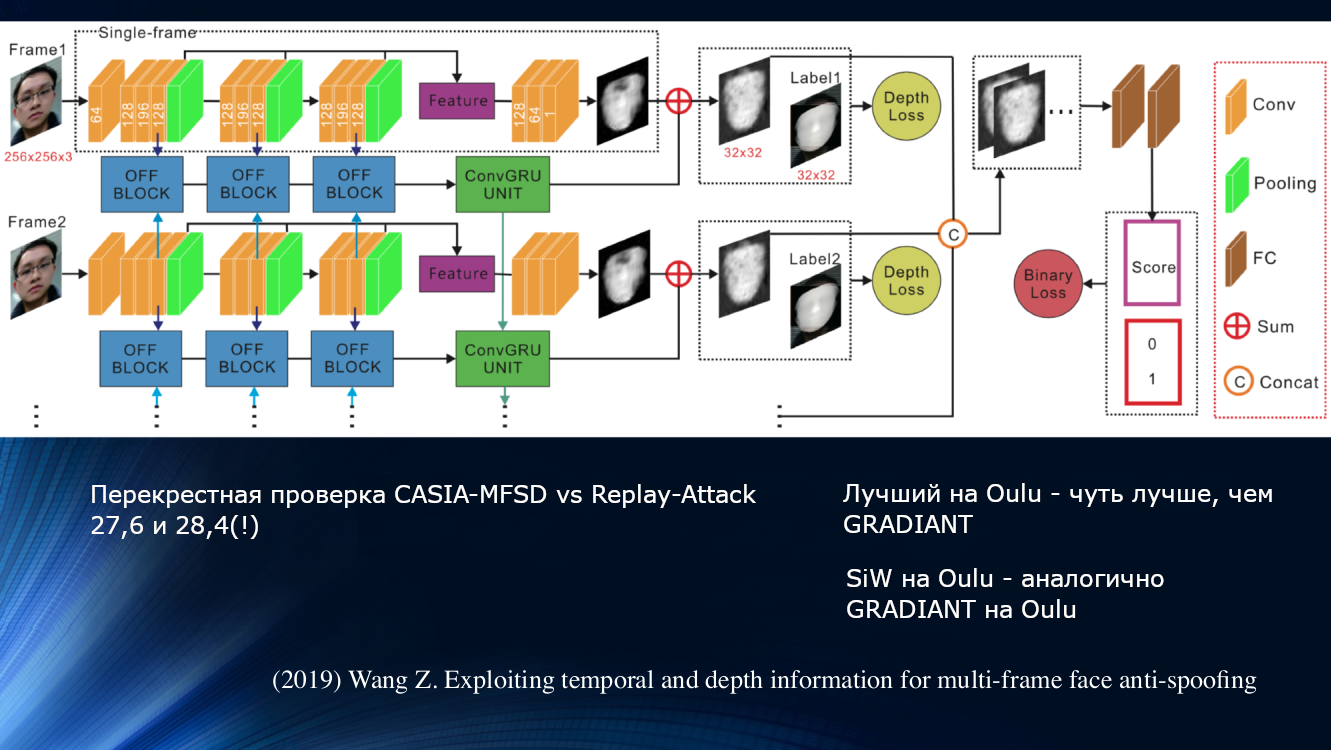
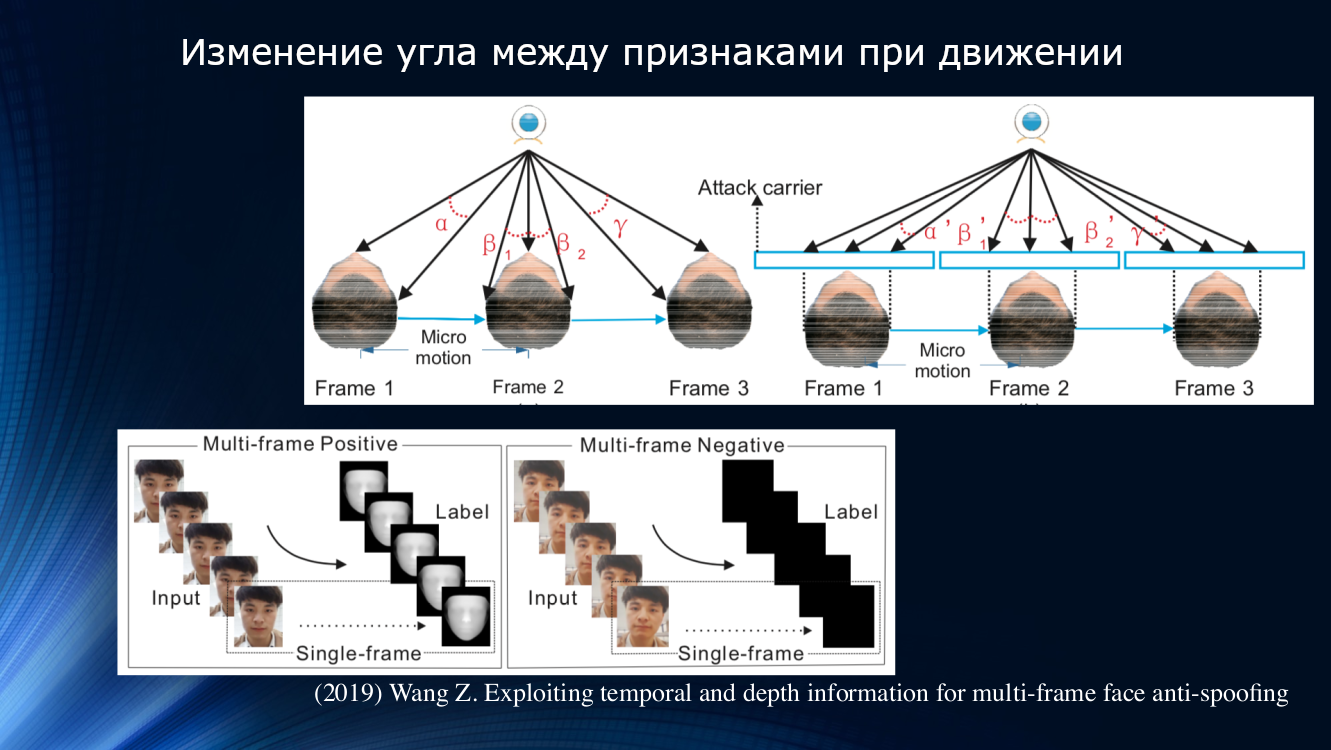
Uma abordagem diferente foi proposta por Wang e colegas em um trabalho recente de 2019. Observou-se que, na análise da micromoção da face, são notáveis rotações e deslocamentos da cabeça, levando a uma mudança característica nos ângulos e distâncias relativas entre os sinais na face. Portanto, quando o rosto é deslocado horizontalmente, o ângulo entre o nariz e a orelha aumenta. Porém, se você trocar uma folha de papel com uma imagem da mesma maneira, o ângulo diminuirá! Para ilustração, vale a pena citar um desenho da obra.
Sob esse princípio, os autores construíram uma unidade de aprendizado inteira para transferir dados entre as camadas de uma rede neural. Ele levou em consideração “compensações incorretas” para cada quadro em uma sequência de dois quadros, e isso permitiu que os resultados fossem usados no próximo bloco de análise de dependência de longo prazo com base na Unidade Recorrente Fechada GRU. Todos os sinais foram concatenados, a função de perda foi calculada e a classificação final foi realizada. Isso nos permitiu melhorar um pouco o resultado no conjunto de dados da OULU, mas o problema de dependência dos dados de treinamento permaneceu, pois para o par CASIA-MFSD e Replay-Attack, os indicadores eram 17,5 e 24%, respectivamente.
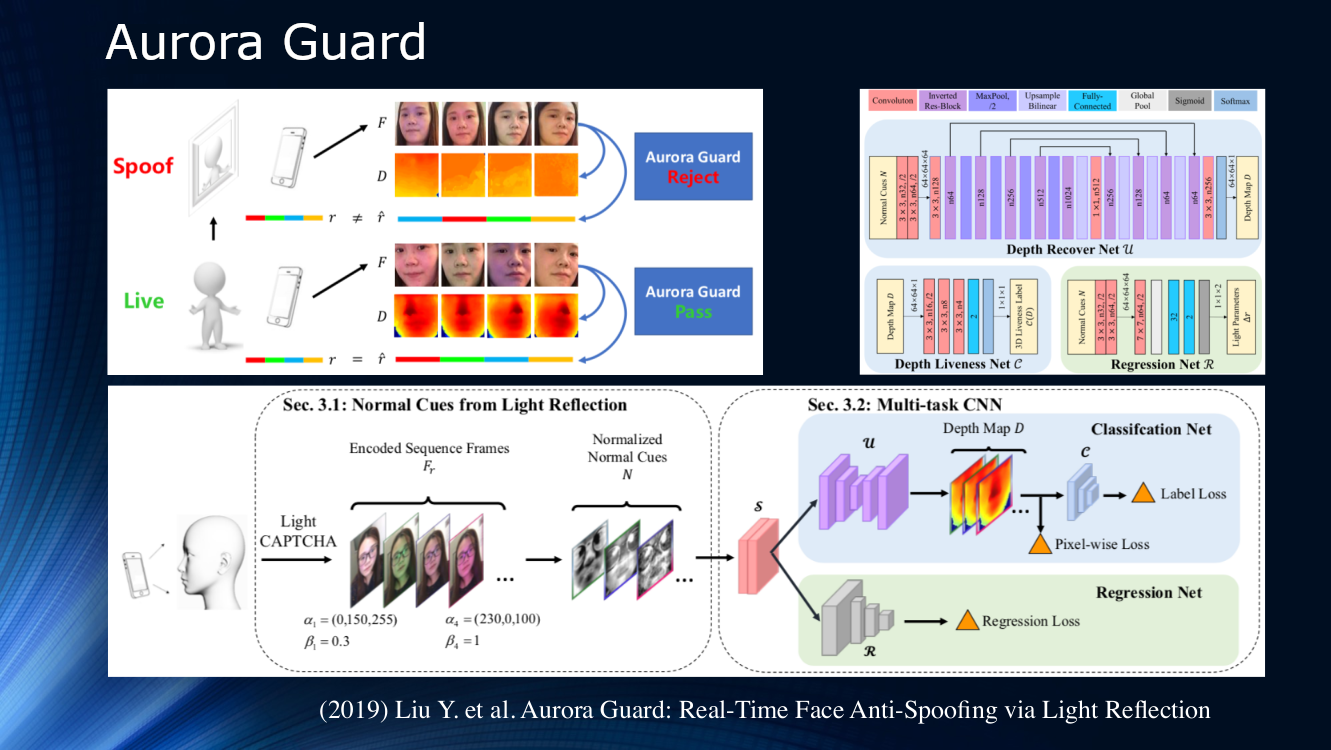
No final, vale a pena observar o trabalho dos especialistas da Tencent, que propuseram alterar a maneira como a imagem de vídeo de origem é recebida. Em vez de observar passivamente a cena, eles sugeriram iluminar dinamicamente o rosto e ler reflexões. O princípio da irradiação ativa de um objeto há muito tempo é aplicado em sistemas de localização de vários tipos; portanto, seu uso no estudo da face parece muito lógico. Obviamente, para uma identificação confiável na própria imagem, não há sinais suficientes, e iluminar a tela do telefone ou tablet com uma sequência de símbolos de luz (CAPTCHA de luz de acordo com a terminologia dos autores) pode ajudar bastante. A seguir, é determinada a diferença de dispersão e reflexão sobre um par de quadros, e os resultados são alimentados em uma rede neural multitarefa para processamento adicional no mapa de profundidade e cálculo de várias funções de perda. No final, é realizada uma regressão dos quadros de luz normalizados. Os autores não analisaram a capacidade de generalização de seu algoritmo em outros conjuntos de dados e o treinaram em seu próprio conjunto de dados privado. O resultado é de cerca de 1% e é relatado que o modelo já foi implantado para uso real.
Até 2017, a área antifalsificação de rosto não era muito ativa. Mas 2019 já apresentou uma série de trabalhos, que estão associados à promoção agressiva de tecnologias móveis de identificação facial, principalmente pela Apple. Além disso, os bancos estão interessados em tecnologias de reconhecimento facial. Muitas pessoas novas vieram para o setor, o que nos permite esperar um progresso rápido. Mas até agora, apesar dos belos títulos das publicações, a capacidade de generalização dos algoritmos permanece muito fraca e não nos permite falar sobre qualquer adequação para uso prático.
Conclusão E finalmente, eu direi isso ...
- Os padrões binários locais, rastreamento de piscar, respiração, movimentos e outros sinais projetados manualmente não perderam seu significado. Isso se deve principalmente ao fato de o treinamento profundo no campo da anti-falsificação de rosto ainda ser muito ingênuo.
- É claro que, na "mesma solução", vários métodos serão mesclados. Análise de reflexão, dispersão e mapas de profundidade devem ser usados juntos. Provavelmente, a adição de um canal de dados adicional ajudará, por exemplo, gravação de voz e algum tipo de abordagem do sistema que permitirá coletar várias tecnologias em um único sistema
- Quase todas as tecnologias usadas para reconhecimento de rosto encontram aplicação em anti-falsificação de rosto (cap!) Tudo o que foi desenvolvido para reconhecimento de face, de uma forma ou de outra, encontrou aplicação para análise de ataques
- Os conjuntos de dados existentes atingiram a saturação. Dos dez conjuntos de dados básicos em cinco, erro zero foi atingido. Isso já fala, por exemplo, da eficiência de métodos baseados em mapas de profundidade, mas não permite melhorar a capacidade de generalização. Precisamos de novos dados e novas experiências sobre eles
- Há um claro desequilíbrio entre o grau de desenvolvimento do reconhecimento de rosto e o anti-spoofing de rosto. As tecnologias de reconhecimento estão significativamente à frente dos sistemas de proteção. Além disso, é a falta de sistemas de proteção confiáveis que inibe o uso prático dos sistemas de reconhecimento facial. Aconteceu que a principal atenção foi dada especificamente ao reconhecimento de rosto, e os sistemas de detecção de ataques permaneceram um pouco distantes
- Existe uma forte necessidade de uma abordagem sistemática no campo da anti-falsificação de rosto. A competição anterior da Universidade de Oulu mostrou que, ao usar um conjunto de dados não representativo, é possível derrotar com um simples ajuste competente das soluções estabelecidas, sem desenvolver novas. Talvez uma nova competição possa mudar a maré
- Com o crescente interesse no assunto e a introdução de tecnologias de reconhecimento facial por grandes players, surgiram “janelas de oportunidade” para novas equipes ambiciosas, pois há uma séria necessidade de uma nova solução no nível arquitetural