Nos artigos anteriores, discutimos o
mecanismo de indexação do PostgreSQL, a interface dos métodos de acesso e os seguintes métodos:
índices de hash ,
árvores B ,
GiST ,
SP-GiST ,
GIN e
RUM . O tópico deste artigo é índices BRIN.
Brin
Conceito geral
Ao contrário dos índices com os quais já nos reunimos, a idéia do BRIN é evitar procurar linhas definitivamente inadequadas, em vez de encontrar rapidamente as correspondentes. Este é sempre um índice impreciso: não contém TIDs de linhas da tabela.
De maneira simplista, o BRIN funciona bem para colunas em que os valores se correlacionam com sua localização física na tabela. Em outras palavras, se uma consulta sem a cláusula ORDER BY retornar os valores da coluna virtualmente na ordem crescente ou decrescente (e não houver índices nessa coluna).
Esse método de acesso foi criado no escopo do
Axle , o projeto europeu para bancos de dados analíticos extremamente grandes, de olho em tabelas com vários terabytes ou dezenas de terabytes. Um recurso importante do BRIN que nos permite criar índices nessas tabelas é um tamanho pequeno e custos indiretos mínimos de manutenção.
Isso funciona da seguinte maneira. A tabela é dividida em
intervalos com várias páginas grandes (ou vários blocos grandes, iguais) - daí o nome: Índice de intervalo de blocos, BRIN. O índice armazena
informações resumidas nos dados em cada intervalo. Como regra, esses são os valores mínimos e máximos, mas são diferentes, conforme mostrado a seguir. Suponha que seja realizada uma consulta que contenha a condição para uma coluna; se os valores procurados não entrarem no intervalo, todo o intervalo poderá ser ignorado; mas se receberem, todas as linhas em todos os blocos deverão ser examinadas para escolher as linhas correspondentes entre elas.
Não será um erro tratar o BRIN não como um índice, mas como um acelerador da varredura seqüencial. Podemos considerar o BRIN como uma alternativa ao particionamento se considerarmos cada intervalo como uma partição "virtual".
Agora vamos discutir a estrutura do índice com mais detalhes.
Estrutura
A primeira página (mais exatamente, zero) contém os metadados.
As páginas com as informações resumidas estão localizadas em um determinado deslocamento dos metadados. Cada linha de índice nessas páginas contém informações resumidas em um intervalo.
Entre a meta página e os dados resumidos, estão localizadas as páginas com o
mapa de intervalo reverso (abreviado como "revmap"). Na verdade, essa é uma matriz de ponteiros (TIDs) para as linhas de índice correspondentes.
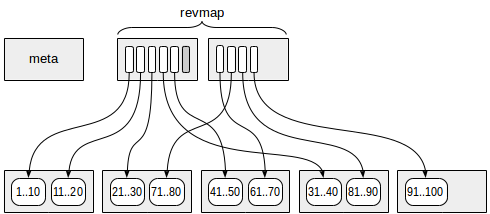
Para alguns intervalos, o ponteiro em "revmap" pode levar a nenhuma linha de índice (uma é marcada em cinza na figura). Nesse caso, considera-se que o intervalo ainda não possui informações resumidas.
Digitalizando o índice
Como o índice é usado se não contém referências às linhas da tabela? Esse método de acesso certamente não pode retornar linhas TID por TID, mas pode criar um bitmap. Pode haver dois tipos de páginas de bitmap: precisas para a linha e imprecisas para a página. É um bitmap impreciso usado.
O algoritmo é simples. O mapa de intervalos é varrido sequencialmente (ou seja, os intervalos são percorridos na ordem de sua localização na tabela). Os ponteiros são usados para determinar as linhas de índice com informações resumidas em cada intervalo. Se um intervalo não contiver o valor desejado, ele será ignorado e se puder conter o valor (ou as informações de resumo não estiverem disponíveis), todas as páginas do intervalo serão adicionadas ao bitmap. O bitmap resultante é então usado como de costume.
Atualizando o índice
É mais interessante como o índice é atualizado quando a tabela é alterada.
Ao
adicionar uma nova versão de uma linha a uma página da tabela, determinamos em qual intervalo ela está contida e usamos o mapa de intervalos para localizar a linha de índice com as informações de resumo. Todas essas são operações aritméticas simples. Por exemplo, permita que o tamanho de um intervalo seja quatro e, na página 13, ocorra uma versão de linha com o valor de 42. O número do intervalo (começando com zero) é 13/4 = 3, portanto, em "revmap", pegamos o ponteiro com o deslocamento 3 (seu número de ordem é quatro).
O valor mínimo para esse intervalo é 31 e o máximo é 40. Como o novo valor de 42 está fora do intervalo, atualizamos o valor máximo (veja a figura). Mas se o novo valor ainda estiver dentro dos limites armazenados, o índice não precisará ser atualizado.

Tudo isso se refere à situação em que a nova versão da página ocorre em um intervalo para o qual as informações de resumo estão disponíveis. Quando o índice é criado, as informações de resumo são calculadas para todos os intervalos disponíveis, mas enquanto a tabela é expandida, novas páginas podem ocorrer que caem fora dos limites. Duas opções estão disponíveis aqui:
- Normalmente, o índice não é atualizado imediatamente. Isso não é grande coisa: como já mencionado, ao verificar o índice, todo o intervalo será analisado. A atualização real é feita durante o "vácuo" ou pode ser feita manualmente chamando a função "brin_summarize_new_values".
- Se criarmos o índice com o parâmetro "autosummarize", a atualização será feita imediatamente. Mas quando as páginas do intervalo são preenchidas com novos valores, as atualizações podem ocorrer com muita frequência; portanto, esse parâmetro é desativado por padrão.
Quando novos intervalos ocorrem, o tamanho do "revmap" pode aumentar. Sempre que o mapa, localizado entre a meta página e os dados de resumo, precisar ser estendido por outra página, as versões de linha existentes serão movidas para algumas outras páginas. Portanto, o mapa de intervalos está sempre localizado entre a meta página e os dados resumidos.
Quando uma linha é
excluída , ... nada acontece. Podemos notar que, às vezes, o valor mínimo ou máximo será excluído; nesse caso, o intervalo poderá ser reduzido. Mas para detectar isso, teríamos que ler todos os valores no intervalo, e isso é caro.
A correção do índice não é afetada, mas a pesquisa pode exigir a busca por mais intervalos do que o necessário. Em geral, as informações de resumo podem ser recalculadas manualmente para essa zona (chamando as funções "brin_desummarize_range" e "brin_summarize_new_values"), mas como podemos detectar essa necessidade? De qualquer forma, nenhum procedimento convencional está disponível para esse fim.
Por fim,
atualizar uma linha é apenas uma exclusão da versão desatualizada e a adição de uma nova.
Exemplo
Vamos tentar construir nosso próprio mini data warehouse para os dados das tabelas do
banco de dados demo . Vamos supor que, para fins de relatórios de BI, seja necessária uma tabela não normalizada para refletir os vôos partidos de um aeroporto ou aterrissados no aeroporto com a precisão de um assento na cabine. Os dados de cada aeroporto serão adicionados à tabela uma vez por dia, quando é meia-noite no fuso horário apropriado. Os dados não serão atualizados nem excluídos.
A tabela terá a seguinte aparência:
demo=# create table flights_bi( airport_code char(3), airport_coord point,
Podemos simular o procedimento de carregamento dos dados usando loops aninhados: um externo por dias (consideraremos
um banco de dados grande , portanto, 365 dias) e um loop interno por fusos horários (de UTC + 02 a UTC + 12) . A consulta é bastante longa e não é de interesse particular, então eu a ocultarei sob o spoiler.
Simulação de carregamento de dados no armazenamento DO $$ <<local>> DECLARE curdate date := (SELECT min(scheduled_departure) FROM flights); utc_offset interval; BEGIN WHILE (curdate <= bookings.now()::date) LOOP utc_offset := interval '12 hours'; WHILE (utc_offset >= interval '2 hours') LOOP INSERT INTO flights_bi WITH flight ( airport_code, airport_coord, flight_id, flight_no, scheduled_time, actual_time, aircraft_code, flight_type ) AS ( ;
demo=# select count(*) from flights_bi;
count ---------- 30517076 (1 row)
demo=# select pg_size_pretty(pg_total_relation_size('flights_bi'));
pg_size_pretty ---------------- 4127 MB (1 row)
Temos 30 milhões de linhas e 4 GB. Um tamanho não tão grande, mas bom o suficiente para um laptop: a varredura seqüencial levou cerca de 10 segundos.
Em quais colunas devemos criar o índice?
Como os índices BRIN têm um tamanho pequeno e os custos indiretos moderados e as atualizações ocorrem com pouca frequência, se houver, surge uma rara oportunidade de criar muitos índices "por precaução", por exemplo, em todos os campos nos quais os usuários analistas podem criar suas consultas ad-hoc . Não será útil - não importa, mas mesmo um índice que não é muito eficiente funcionará melhor do que a varredura seqüencial, com certeza. Obviamente, existem campos nos quais é absolutamente inútil criar um índice; o puro senso comum os motivará.
Mas deve ser estranho nos limitar a esse conselho, portanto, vamos tentar estabelecer um critério mais preciso.
Já mencionamos que os dados devem se correlacionar um pouco com sua localização física. Aqui faz sentido lembrar que o PostgreSQL reúne estatísticas da coluna da tabela, que incluem o valor da correlação. O planejador usa esse valor para selecionar entre uma verificação de índice regular e uma verificação de bitmap, e podemos usá-lo para estimar a aplicabilidade do índice BRIN.
No exemplo acima, os dados são evidentemente ordenados por dias (por "horário_ agendado" e também por "horário_atual" - não há muita diferença). Isso ocorre porque quando as linhas são adicionadas à tabela (sem exclusões e atualizações), elas são dispostas no arquivo uma após a outra. Na simulação do carregamento de dados, nem usamos a cláusula ORDER BY; portanto, as datas dentro de um dia podem, em geral, ser misturadas de maneira arbitrária, mas a ordem deve estar em vigor. Vamos verificar isso:
demo=# analyze flights_bi; demo=# select attname, correlation from pg_stats where tablename='flights_bi' order by correlation desc nulls last;
attname | correlation --------------------+------------- scheduled_time | 0.999994 actual_time | 0.999994 fare_conditions | 0.796719 flight_type | 0.495937 airport_utc_offset | 0.438443 aircraft_code | 0.172262 airport_code | 0.0543143 flight_no | 0.0121366 seat_no | 0.00568042 passenger_name | 0.0046387 passenger_id | -0.00281272 airport_coord | (12 rows)
O valor que não está muito próximo de zero (idealmente, próximo de mais um menos, como neste caso), nos diz que o índice BRIN será apropriado.
A classe de viagem "fare_condition" (a coluna contém três valores exclusivos) e o tipo de voo "flight_type" (dois valores exclusivos) inesperadamente pareciam estar no segundo e no terceiro lugares. Isso é uma ilusão: formalmente, a correlação é alta, enquanto, em várias páginas sucessivas, todos os valores possíveis serão encontrados com certeza, o que significa que o BRIN não fará nenhum bem.
O fuso horário "airport_utc_offset" segue a seguir: no exemplo considerado, em um ciclo diário, os aeroportos são ordenados por fusos horários "por construção".
São esses dois campos, horário e fuso horário, que iremos experimentar mais adiante.
Possível enfraquecimento da correlação
A correlação que é o local "por construção" pode ser facilmente enfraquecida quando os dados são alterados. E o problema aqui não está na alteração de um valor específico, mas na estrutura do controle de simultaneidade multiversão: a versão da linha desatualizada é excluída em uma página, mas uma nova versão pode ser inserida sempre que houver espaço livre disponível. Devido a isso, linhas inteiras se misturam durante as atualizações.
Podemos controlar parcialmente esse efeito, reduzindo o valor do parâmetro de armazenamento "fillfactor" e, dessa forma, deixando espaço livre em uma página para futuras atualizações. Mas queremos aumentar o tamanho de uma mesa já grande? Além disso, isso não resolve o problema das exclusões: elas também "configuram traps" para novas linhas, liberando espaço em algum lugar nas páginas existentes. Por esse motivo, as linhas que, de outra forma, chegariam ao final do arquivo, serão inseridas em algum local arbitrário.
A propósito, este é um fato curioso. Como o índice BRIN não contém referências às linhas da tabela, sua disponibilidade não deve impedir as atualizações HOT, mas sim.
Portanto, o BRIN é projetado principalmente para tabelas de tamanhos grandes e até enormes, que não são atualizadas ou são levemente atualizadas. No entanto, ele lida perfeitamente com a adição de novas linhas (no final da tabela). Isso não é surpreendente, pois esse método de acesso foi criado com vista a data warehouses e relatórios analíticos.
Qual o tamanho de um intervalo que precisamos selecionar?
Se lidarmos com uma tabela de terabytes, nossa principal preocupação ao selecionar o tamanho de um intervalo provavelmente não será tornar o índice BRIN muito grande. No entanto, em nossa situação, podemos nos permitir analisar dados com mais precisão.
Para fazer isso, podemos selecionar valores exclusivos de uma coluna e ver quantas páginas elas ocorrem. A localização dos valores aumenta as chances de sucesso na aplicação do índice BRIN. Além disso, o número encontrado de páginas solicitará o tamanho de um intervalo. Mas se o valor for "espalhado" por todas as páginas, o BRIN será inútil.
Obviamente, devemos usar essa técnica observando atentamente a estrutura interna dos dados. Por exemplo, não faz sentido considerar cada data (mais exatamente, um carimbo de data / hora, incluindo também a hora) como um valor único - precisamos arredondá-lo para dias.
Tecnicamente, essa análise pode ser feita observando o valor da coluna "ctid" oculta, que fornece o ponteiro para uma versão de linha (TID): o número da página e o número da linha dentro da página. Infelizmente, não existe uma técnica convencional para decompor o TID em seus dois componentes; portanto, temos que converter tipos através da representação de texto:
demo=# select min(numblk), round(avg(numblk)) avg, max(numblk) from ( select count(distinct (ctid::text::point)[0]) numblk from flights_bi group by scheduled_time::date ) t;
min | avg | max ------+------+------ 1192 | 1500 | 1796 (1 row)
demo=# select relpages from pg_class where relname = 'flights_bi';
relpages ---------- 528172 (1 row)
Podemos ver que cada dia é distribuído pelas páginas de maneira bastante uniforme, e os dias são levemente misturados entre si (1500 vezes 365 = 547500, que é apenas um pouco maior que o número de páginas na tabela 528172). Isso é realmente claro "por construção" de qualquer maneira.
Informações valiosas aqui são um número específico de páginas. Com um tamanho de intervalo convencional de 128 páginas, cada dia preencherá de 9 a 14 intervalos. Isso parece realista: com uma consulta para um dia específico, podemos esperar um erro em torno de 10%.
Vamos tentar:
demo=# create index on flights_bi using brin(scheduled_time);
O tamanho do índice é tão pequeno quanto 184 KB:
demo=# select pg_size_pretty(pg_total_relation_size('flights_bi_scheduled_time_idx'));
pg_size_pretty ---------------- 184 kB (1 row)
Nesse caso, dificilmente faz sentido aumentar o tamanho de um intervalo com o custo de perder a precisão. Mas podemos reduzir o tamanho, se necessário, e a precisão aumentará (pelo contrário, juntamente com o tamanho do índice).
Agora vamos ver os fusos horários. Aqui também não podemos usar uma abordagem de força bruta. Todos os valores devem ser divididos pelo número de ciclos do dia, pois a distribuição é repetida em cada dia. Além disso, como existem apenas alguns fusos horários, podemos observar toda a distribuição:
demo=# select airport_utc_offset, count(distinct (ctid::text::point)[0])/365 numblk from flights_bi group by airport_utc_offset order by 2;
airport_utc_offset | numblk --------------------+-------- 12:00:00 | 6 06:00:00 | 8 02:00:00 | 10 11:00:00 | 13 08:00:00 | 28 09:00:00 | 29 10:00:00 | 40 04:00:00 | 47 07:00:00 | 110 05:00:00 | 231 03:00:00 | 932 (11 rows)
Em média, os dados para cada fuso horário preenchem 133 páginas por dia, mas a distribuição é altamente não uniforme: Petropavlovsk-Kamchatskiy e Anadyr cabem apenas seis páginas, enquanto Moscou e seus arredores exigem centenas delas. O tamanho padrão de um intervalo não é bom aqui; vamos, por exemplo, configurá-lo para quatro páginas.
demo=# create index on flights_bi using brin(airport_utc_offset) with (pages_per_range=4); demo=# select pg_size_pretty(pg_total_relation_size('flights_bi_airport_utc_offset_idx'));
pg_size_pretty ---------------- 6528 kB (1 row)
Plano de execução
Vejamos como nossos índices funcionam. Vamos selecionar um dia, digamos, uma semana atrás (no banco de dados demo, "hoje" é determinado pela função "booking.now"):
demo=# \set d 'bookings.now()::date - interval \'7 days\'' demo=# explain (costs off,analyze) select * from flights_bi where scheduled_time >= :d and scheduled_time < :d + interval '1 day';
QUERY PLAN -------------------------------------------------------------------------------- Bitmap Heap Scan on flights_bi (actual time=10.282..94.328 rows=83954 loops=1) Recheck Cond: ... Rows Removed by Index Recheck: 12045 Heap Blocks: lossy=1664 -> Bitmap Index Scan on flights_bi_scheduled_time_idx (actual time=3.013..3.013 rows=16640 loops=1) Index Cond: ... Planning time: 0.375 ms Execution time: 97.805 ms
Como podemos ver, o planejador usou o índice criado. Qual é a precisão? A proporção do número de linhas que atendem às condições da consulta ("linhas" do nó Bitmap Heap Scan) e o número total de linhas retornadas usando o índice (o mesmo valor mais Linhas removidas pela verificação do índice) nos informa sobre isso. Nesse caso, 83954 / (83954 + 12045), que é de aproximadamente 90%, conforme o esperado (esse valor será alterado de um dia para outro).
De onde se origina o número 16640 em "linhas reais" do nó Bitmap Index Scan? O fato é que esse nó do plano cria um bitmap impreciso (página por página) e não tem conhecimento de quantas linhas o bitmap tocará, enquanto algo precisa ser mostrado. Portanto, em desespero, assume-se que uma página contém 10 linhas. O bitmap contém 1664 páginas no total (esse valor é mostrado em "Heap Blocks: lossy = 1664"); então, obtemos 16640. No total, esse é um número sem sentido, ao qual não devemos prestar atenção.
E os aeroportos? Por exemplo, vamos usar o fuso horário de Vladivostok, que preenche 28 páginas por dia:
demo=# explain (costs off,analyze) select * from flights_bi where airport_utc_offset = interval '8 hours';
QUERY PLAN ---------------------------------------------------------------------------------- Bitmap Heap Scan on flights_bi (actual time=75.151..192.210 rows=587353 loops=1) Recheck Cond: (airport_utc_offset = '08:00:00'::interval) Rows Removed by Index Recheck: 191318 Heap Blocks: lossy=13380 -> Bitmap Index Scan on flights_bi_airport_utc_offset_idx (actual time=74.999..74.999 rows=133800 loops=1) Index Cond: (airport_utc_offset = '08:00:00'::interval) Planning time: 0.168 ms Execution time: 212.278 ms
O planejador novamente usa o índice BRIN criado. A precisão é pior (cerca de 75% nesse caso), mas isso é esperado, pois a correlação é menor.
Vários índices BRIN (como qualquer outro) certamente podem ser unidos no nível de bitmap. Por exemplo, a seguir estão os dados no fuso horário selecionado para um mês (observe o nó "BitmapAnd"):
demo=# \set d 'bookings.now()::date - interval \'60 days\'' demo=# explain (costs off,analyze) select * from flights_bi where scheduled_time >= :d and scheduled_time < :d + interval '30 days' and airport_utc_offset = interval '8 hours';
QUERY PLAN --------------------------------------------------------------------------------- Bitmap Heap Scan on flights_bi (actual time=62.046..113.849 rows=48154 loops=1) Recheck Cond: ... Rows Removed by Index Recheck: 18856 Heap Blocks: lossy=1152 -> BitmapAnd (actual time=61.777..61.777 rows=0 loops=1) -> Bitmap Index Scan on flights_bi_scheduled_time_idx (actual time=5.490..5.490 rows=435200 loops=1) Index Cond: ... -> Bitmap Index Scan on flights_bi_airport_utc_offset_idx (actual time=55.068..55.068 rows=133800 loops=1) Index Cond: ... Planning time: 0.408 ms Execution time: 115.475 ms
Comparação com b-tree
E se criarmos um índice de árvore B regular no mesmo campo que o BRIN?
demo=# create index flights_bi_scheduled_time_btree on flights_bi(scheduled_time); demo=# select pg_size_pretty(pg_total_relation_size('flights_bi_scheduled_time_btree'));
pg_size_pretty ---------------- 654 MB (1 row)
Parecia ser
milhares de vezes maior que o nosso BRIN! No entanto, a consulta é realizada um pouco mais rápido: o planejador usou as estatísticas para descobrir que os dados estão ordenados fisicamente e não é necessário criar um bitmap e, principalmente, que a condição do índice não precisa ser verificada novamente:
demo=# explain (costs off,analyze) select * from flights_bi where scheduled_time >= :d and scheduled_time < :d + interval '1 day';
QUERY PLAN ---------------------------------------------------------------- Index Scan using flights_bi_scheduled_time_btree on flights_bi (actual time=0.099..79.416 rows=83954 loops=1) Index Cond: ... Planning time: 0.500 ms Execution time: 85.044 ms
É o que há de mais maravilhoso no BRIN: sacrificamos a eficiência, mas ganhamos muito espaço.
Classes de operadores
minmax
Para tipos de dados cujos valores podem ser comparados entre si, as informações de resumo consistem
nos valores mínimo e máximo . Os nomes das classes de operadores correspondentes contêm "minmax", por exemplo, "date_minmax_ops". Na verdade, esses são os tipos de dados que estávamos considerando até agora e a maioria deles é desse tipo.
inclusivo
Operadores de comparação não são definidos para todos os tipos de dados. Por exemplo, eles não estão definidos para pontos (tipo "ponto"), que representam as coordenadas geográficas dos aeroportos. A propósito, é por esse motivo que as estatísticas não mostram a correlação para esta coluna.
demo=# select attname, correlation from pg_stats where tablename='flights_bi' and attname = 'airport_coord';
attname | correlation ---------------+------------- airport_coord | (1 row)
Mas muitos desses tipos nos permitem introduzir um conceito de "área delimitadora", por exemplo, um retângulo delimitador para formas geométricas. Discutimos em detalhes como o índice
GiST usa esse recurso. Da mesma forma, o BRIN também permite reunir informações de resumo em colunas com tipos de dados como estes:
a área delimitadora para todos os valores dentro de um intervalo é apenas o valor de resumo.
Diferentemente do GiST, o valor de resumo para BRIN deve ser do mesmo tipo que os valores que estão sendo indexados. Portanto, não podemos construir o índice para pontos, embora seja claro que as coordenadas possam funcionar no BRIN: a longitude está intimamente ligada ao fuso horário. Felizmente, nada impede a criação do índice em uma expressão após transformar pontos em retângulos degenerados. Ao mesmo tempo, definiremos o tamanho de um intervalo para uma página, apenas para mostrar o caso limite:
demo=# create index on flights_bi using brin (box(airport_coord)) with (pages_per_range=1);
O tamanho do índice é tão pequeno quanto 30 MB, mesmo em uma situação tão extrema:
demo=# select pg_size_pretty(pg_total_relation_size('flights_bi_box_idx'));
pg_size_pretty ---------------- 30 MB (1 row)
Agora podemos fazer consultas que limitam os aeroportos por coordenadas. Por exemplo:
demo=# select airport_code, airport_name from airports where box(coordinates) <@ box '120,40,140,50';
airport_code | airport_name --------------+----------------- KHV | Khabarovsk-Novyi VVO | Vladivostok (2 rows)
O planejador, no entanto, se recusará a usar nosso índice.
demo=# analyze flights_bi; demo=# explain select * from flights_bi where box(airport_coord) <@ box '120,40,140,50';
QUERY PLAN --------------------------------------------------------------------- Seq Scan on flights_bi (cost=0.00..985928.14 rows=30517 width=111) Filter: (box(airport_coord) <@ '(140,50),(120,40)'::box)
Porque Vamos desativar a varredura sequencial e ver o que acontece:
demo=# set enable_seqscan = off; demo=# explain select * from flights_bi where box(airport_coord) <@ box '120,40,140,50';
QUERY PLAN -------------------------------------------------------------------------------- Bitmap Heap Scan on flights_bi (cost=14079.67..1000007.81 rows=30517 width=111) Recheck Cond: (box(airport_coord) <@ '(140,50),(120,40)'::box) -> Bitmap Index Scan on flights_bi_box_idx (cost=0.00..14072.04 rows=30517076 width=0) Index Cond: (box(airport_coord) <@ '(140,50),(120,40)'::box)
Parece que o índice
pode ser usado, mas o planejador supõe que o bitmap precise ser construído em toda a tabela (veja "linhas" do nó Bitmap Index Scan) e não é de admirar que o planejador escolha a varredura seqüencial em neste caso. A questão aqui é que, para os tipos geométricos, o PostgreSQL não coleta nenhuma estatística, e o planejador precisa ir às cegas:
demo=# select * from pg_stats where tablename = 'flights_bi_box_idx' \gx
-[ RECORD 1 ]----------+------------------- schemaname | bookings tablename | flights_bi_box_idx attname | box inherited | f null_frac | 0 avg_width | 32 n_distinct | 0 most_common_vals | most_common_freqs | histogram_bounds | correlation | most_common_elems | most_common_elem_freqs | elem_count_histogram |
Infelizmente. Mas não há reclamações sobre o índice - ele funciona e funciona bem:
demo=# explain (costs off,analyze) select * from flights_bi where box(airport_coord) <@ box '120,40,140,50';
QUERY PLAN ---------------------------------------------------------------------------------- Bitmap Heap Scan on flights_bi (actual time=158.142..315.445 rows=781790 loops=1) Recheck Cond: (box(airport_coord) <@ '(140,50),(120,40)'::box) Rows Removed by Index Recheck: 70726 Heap Blocks: lossy=14772 -> Bitmap Index Scan on flights_bi_box_idx (actual time=158.083..158.083 rows=147720 loops=1) Index Cond: (box(airport_coord) <@ '(140,50),(120,40)'::box) Planning time: 0.137 ms Execution time: 340.593 ms
A conclusão deve ser assim: PostGIS é necessário se algo não trivial for necessário para a geometria. Ele pode coletar estatísticas de qualquer maneira.
Internals
A extensão convencional "pageinspect" nos permite examinar o índice BRIN.
Primeiro, a metainformação nos solicitará o tamanho de um intervalo e quantas páginas estão alocadas para "revmap":
demo=# select * from brin_metapage_info(get_raw_page('flights_bi_scheduled_time_idx',0));
magic | version | pagesperrange | lastrevmappage ------------+---------+---------------+---------------- 0xA8109CFA | 1 | 128 | 3 (1 row)
As páginas 1-3 aqui são alocadas para "revmap", enquanto o restante contém dados resumidos. No "revmap", podemos obter referências a dados resumidos para cada intervalo. Digamos, as informações do primeiro intervalo, incorporando as primeiras 128 páginas, estão localizadas aqui:
demo=# select * from brin_revmap_data(get_raw_page('flights_bi_scheduled_time_idx',1)) limit 1;
pages --------- (6,197) (1 row)
E este é o próprio resumo dos dados:
demo=# select allnulls, hasnulls, value from brin_page_items( get_raw_page('flights_bi_scheduled_time_idx',6), 'flights_bi_scheduled_time_idx' ) where itemoffset = 197;
allnulls | hasnulls | value ----------+----------+---------------------------------------------------- f | f | {2016-08-15 02:45:00+03 .. 2016-08-15 17:15:00+03} (1 row)
Próximo intervalo:
demo=# select * from brin_revmap_data(get_raw_page('flights_bi_scheduled_time_idx',1)) offset 1 limit 1;
pages --------- (6,198) (1 row)
demo=# select allnulls, hasnulls, value from brin_page_items( get_raw_page('flights_bi_scheduled_time_idx',6), 'flights_bi_scheduled_time_idx' ) where itemoffset = 198;
allnulls | hasnulls | value ----------+----------+---------------------------------------------------- f | f | {2016-08-15 06:00:00+03 .. 2016-08-15 18:55:00+03} (1 row)
E assim por diante
Para classes "inclusão", o campo "valor" exibirá algo como
{(94.4005966186523,69.3110961914062),(77.6600036621,51.6693992614746) .. f .. f}
O primeiro valor é o retângulo de incorporação, e as letras "f" no final denotam a falta de elementos vazios (o primeiro) e a falta de valores imersos (o segundo). Na verdade, os únicos valores não substituíveis são os endereços "IPv4" e "IPv6" (tipo de dados "inet").
Propriedades
Lembrando as consultas que
já foram fornecidas .
A seguir estão as propriedades do método de acesso:
amname | name | pg_indexam_has_property --------+---------------+------------------------- brin | can_order | f brin | can_unique | f brin | can_multi_col | t brin | can_exclude | f
Os índices podem ser criados em várias colunas. Nesse caso, suas próprias estatísticas de resumo são reunidas para cada coluna, mas são armazenadas juntas para cada intervalo. Obviamente, esse índice faz sentido se um e o mesmo tamanho de um intervalo for adequado para todas as colunas.
As seguintes propriedades da camada de índice estão disponíveis:
name | pg_index_has_property ---------------+----------------------- clusterable | f index_scan | f bitmap_scan | t backward_scan | f
Evidentemente, apenas a verificação de bitmap é suportada.
No entanto, a falta de cluster pode parecer confusa. Aparentemente, como o índice BRIN é sensível à ordem física das linhas, seria lógico poder agrupar dados de acordo com o índice. Mas isso não é verdade. Só podemos criar um índice "regular" (árvore B ou GiST, dependendo do tipo de dados) e agrupar de acordo com ele. A propósito, você deseja agrupar uma tabela supostamente enorme, levando em consideração bloqueios exclusivos, tempo de execução e consumo de espaço em disco durante a reconstrução?
A seguir estão as propriedades da camada de coluna:
name | pg_index_column_has_property --------------------+------------------------------ asc | f desc | f nulls_first | f nulls_last | f orderable | f distance_orderable | f returnable | f search_array | f search_nulls | t
A única propriedade disponível é a capacidade de manipular NULLs.
Continue lendo .