
1. Introdução
Nós do Shopify estávamos implantando o Istio como uma malha de serviço. Em princípio, tudo serve, exceto por uma coisa: é caro .
Os benchmarks publicados para o Istio dizem:
Com o Istio 1.1, o proxy consome aproximadamente 0,6 vCPUs (núcleos virtuais) por 1000 solicitações por segundo.
Para a primeira região da malha de serviço (2 proxies em cada lado da conexão), teremos 1200 núcleos apenas para proxies, à taxa de um milhão de solicitações por segundo. De acordo com a calculadora de custos do Google, você recebe cerca de US $ 40 / mês / kernel para a configuração n1-standard-64 , ou seja, somente esta região nos custará mais de US $ 50.000 por mês para 1 milhão de solicitações por segundo.
Ivan Sim ( Ivan Sim ) comparou claramente os atrasos da malha de serviço no ano passado e prometeu o mesmo para a memória e o processador, mas falhou:
Aparentemente, values-istio-test.yaml aumentará seriamente as solicitações do processador. Se eu calculei tudo corretamente, você precisará de cerca de 24 núcleos de processador para o painel de controle e 0,5 CPU para cada proxy. Eu não tenho muito Repetirei os testes quando mais recursos forem alocados para mim.
Eu queria ver por mim mesmo como o desempenho do Istio é semelhante a outra malha de serviço de código aberto: o Linkerd .
Instalação de malha de serviço
A primeira coisa que instalei no cluster SuperGloo foi :
$ supergloo init installing supergloo version 0.3.12 using chart uri https://storage.googleapis.com/supergloo-helm/charts/supergloo-0.3.12.tgz configmap/sidecar-injection-resources created serviceaccount/supergloo created serviceaccount/discovery created serviceaccount/mesh-discovery created clusterrole.rbac.authorization.k8s.io/discovery created clusterrole.rbac.authorization.k8s.io/mesh-discovery created clusterrolebinding.rbac.authorization.k8s.io/supergloo-role-binding created clusterrolebinding.rbac.authorization.k8s.io/discovery-role-binding created clusterrolebinding.rbac.authorization.k8s.io/mesh-discovery-role-binding created deployment.extensions/supergloo created deployment.extensions/discovery created deployment.extensions/mesh-discovery created install successful!
Eu usei o SuperGloo porque simplifica bastante a inicialização da malha de serviço. Eu não tinha quase nada para fazer. Na produção, não usamos o SuperGloo, mas é ideal para uma tarefa semelhante. Eu tive que aplicar apenas alguns comandos a cada malha de serviço. Eu usei dois clusters para isolamento - um para Istio e Linkerd.
O experimento foi conduzido no Google Kubernetes Engine. Usei o Kubernetes 1.12.7-gke.7 e o pool de nós n1-standard-4 com dimensionamento automático de nós (mínimo 4, máximo 16).
Em seguida, instalei as duas malhas de serviço na linha de comando.
Linkerd primeiro:
$ supergloo install linkerd --name linkerd +---------+--------------+---------+---------------------------+ | INSTALL | TYPE | STATUS | DETAILS | +---------+--------------+---------+---------------------------+ | linkerd | Linkerd Mesh | Pending | enabled: true | | | | | version: stable-2.3.0 | | | | | namespace: linkerd | | | | | mtls enabled: true | | | | | auto inject enabled: true | +---------+--------------+---------+---------------------------+
Então Istio:
$ supergloo install istio --name istio --installation-namespace istio-system --mtls=true --auto-inject=true +---------+------------+---------+---------------------------+ | INSTALL | TYPE | STATUS | DETAILS | +---------+------------+---------+---------------------------+ | istio | Istio Mesh | Pending | enabled: true | | | | | version: 1.0.6 | | | | | namespace: istio-system | | | | | mtls enabled: true | | | | | auto inject enabled: true | | | | | grafana enabled: true | | | | | prometheus enabled: true | | | | | jaeger enabled: true | +---------+------------+---------+---------------------------+
O ciclo de colisão levou vários minutos e os painéis de controle se estabilizaram.
(Nota: o SuperGloo atualmente suporta apenas o Istio 1.0.x. Repeti o experimento com o Istio 1.1.3, mas não percebi nenhuma diferença perceptível.)
Configurando a implantação automática do Istio
Para o Istio instalar o side-car Envoy, usamos o injetor de side-car - MutatingAdmissionWebhook . Não falaremos sobre ele neste artigo. Só posso dizer que este é um controlador que monitora o acesso de todos os novos pods e adiciona dinamicamente um sidecar e o initContainer, responsável pelas tarefas das tabelas de ip.
Nós da Shopify escrevemos nosso controlador de acesso para implementar o sidecar, mas neste benchmark eu peguei o controlador que acompanha o Istio. O controlador injeta o sidecar por padrão quando existe o istio-injection: enabled no espaço para nome:
$ kubectl label namespace irs-client-dev istio-injection=enabled namespace/irs-client-dev labeled $ kubectl label namespace irs-server-dev istio-injection=enabled namespace/irs-server-dev labeled
Configurar a implantação automática do Linkerd
Para configurar a implementação do Linkerd sidecar s, usamos anotações (eu as adicionei manualmente através do kubectl edit ):
metadata: annotations: linkerd.io/inject: enabled
$ k edit ns irs-server-dev namespace/irs-server-dev edited $ k get ns irs-server-dev -o yaml apiVersion: v1 kind: Namespace metadata: annotations: linkerd.io/inject: enabled name: irs-server-dev spec: finalizers: - kubernetes status: phase: Active
Simulador de tolerância a falhas Istio
Criamos o simulador de tolerância a falhas do Istio para experimentar um tráfego exclusivo do Shopify. Precisávamos de uma ferramenta para criar uma topologia arbitrária que representasse uma certa parte do gráfico de nosso serviço com ajuste dinâmico para simular cargas de trabalho específicas.
A infraestrutura do Shopify está sob carga pesada durante as vendas instantâneas. Ao mesmo tempo, o Shopify recomenda que os vendedores realizem essas vendas com mais frequência . Às vezes, grandes clientes alertam para uma venda rápida planejada. Outros os gastam inesperadamente para nós a qualquer hora do dia ou da noite.
Queríamos que nosso simulador de tolerância a falhas modelasse fluxos de trabalho que correspondam às topologias e cargas de trabalho que sobrecarregaram a infraestrutura do Shopify no passado. O principal objetivo do uso da malha de serviço é que precisamos de confiabilidade e tolerância a falhas no nível da rede, e é importante para nós que a malha de serviço lide efetivamente com as cargas que interromperam anteriormente a operação dos serviços.
O simulador de failover é baseado em um nó de trabalho que atua como um nó de malha de serviço. O nó de trabalho pode ser configurado estaticamente na inicialização ou dinamicamente por meio da API REST. Usamos o ajuste dinâmico de nós de trabalho para criar fluxos de trabalho na forma de testes de regressão.
Aqui está um exemplo desse processo:
- Iniciamos 10 servidores como um serviço de
bar , que retorna uma resposta 200/OK após 100 ms. - Iniciamos 10 clientes - cada um envia 100 solicitações por segundo para
bar . - A cada 10 segundos, removemos 1 servidor, monitoramos os erros
5xx no cliente.
No final do fluxo de trabalho, estudamos os logs e métricas e verificamos se o teste passa. É assim que aprendemos sobre o desempenho de nossa malha de serviço e realizamos um teste de regressão para testar nossas suposições sobre tolerância a falhas.
(Observação: estamos pensando em abrir o código fonte do simulador de tolerância a falhas do Istio, mas ainda não estamos prontos para isso.)
Simulador de tolerância a falhas Istio para referência de malha de serviço
Configuramos vários nós de trabalho do simulador:
irs-client-loadgen : 3 réplicas que enviam 100 solicitações por segundo ao irs-client .irs-client : 3 réplicas que recebem a solicitação aguardam 100 ms e redirecionam a solicitação ao irs-server .irs-server : 3 réplicas que retornam 200/OK após 100 ms.
Com essa configuração, podemos medir um fluxo de tráfego estável entre 9 pontos de extremidade. Os irs-client-loadgen em irs-client-loadgen e irs-server recebem 100 solicitações por segundo e irs-client - 200 (entrada e saída).
Rastreamos o uso de recursos por meio do DataDog porque não temos um cluster do Prometheus.
Resultados
Painéis de controle
Primeiro, examinamos o consumo da CPU.

Painel de Controle Linkerd ~ 22M
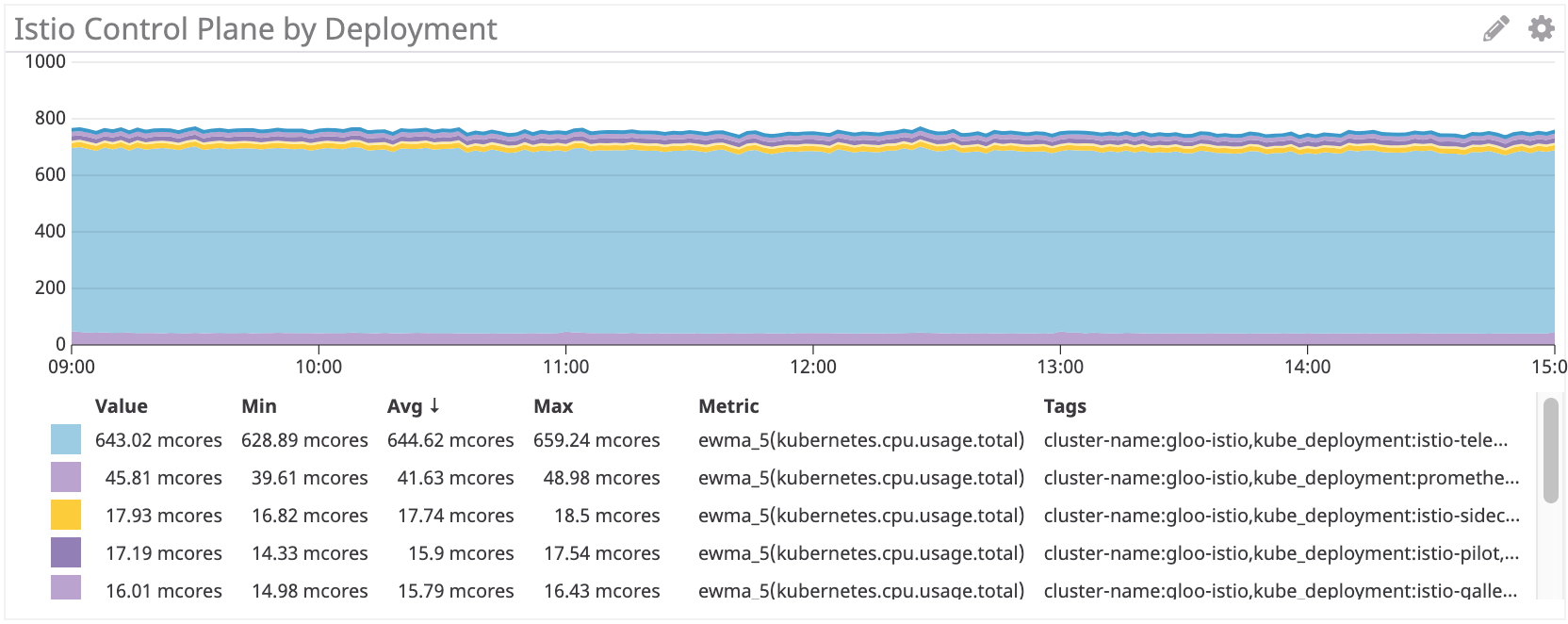
Painel de controle Istio: ~ 750 milhões de núcleos
O painel de controle do Istio usa aproximadamente 35 vezes mais recursos de processador que o Linkerd. Obviamente, tudo é definido por padrão e a istio-telemetria consome muitos recursos do processador (você pode desativá-lo abandonando algumas funções). Se você remover esse componente, ele ainda será mais do que 100 multicore, ou seja, quatro vezes mais que o Linkerd.
Proxy Sidecar
Em seguida, verificamos o uso de proxies. Deve haver uma dependência linear do número de solicitações, mas para cada side-car existem algumas despesas gerais que afetam a curva.

Linkerd: ~ 100Mnuclear para irs-client, ~ 50Mnuclear para irs-client-loadgen
Os resultados parecem lógicos, porque o proxy do cliente recebe o dobro do tráfego que o proxy loadgen: para cada solicitação de saída do loadgen, o cliente tem uma entrada e uma saída.
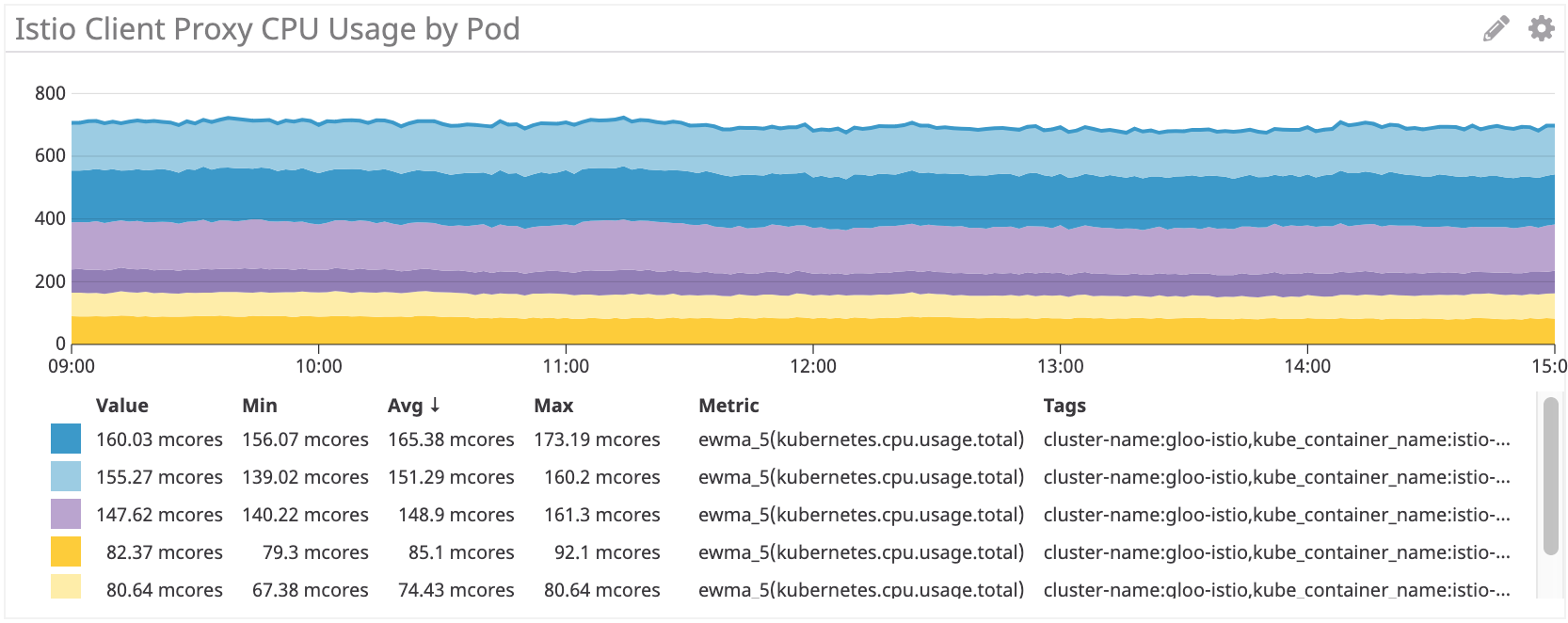
Istio / Envoy: ~ 155 milionários para irs-client, ~ 75 milionários para irs-client-loadgen
Vemos resultados semelhantes para o carro lateral Istio.
Mas, no geral, os proxies do Istio / Envoy consomem cerca de 50% mais recursos do processador que o Linkerd.
Vemos o mesmo esquema no lado do servidor:
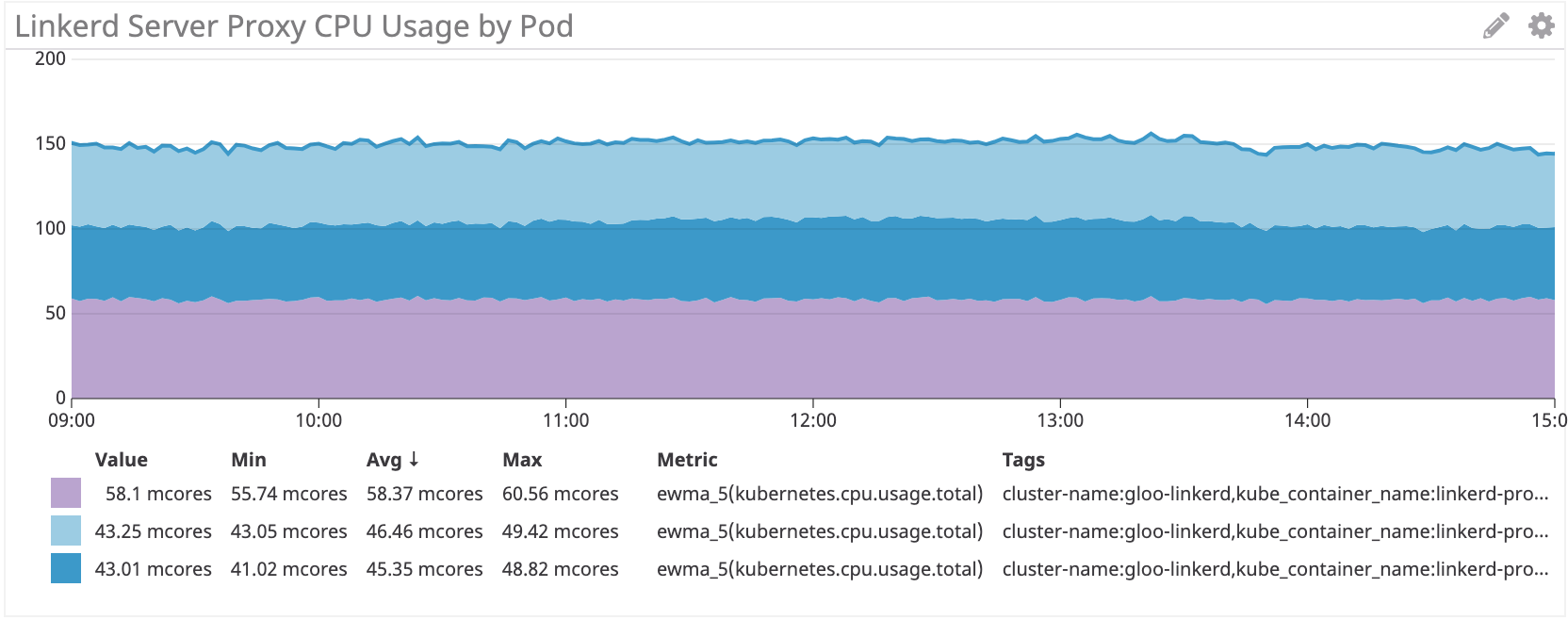
Linkerd: ~ 50 multicore para irs-server
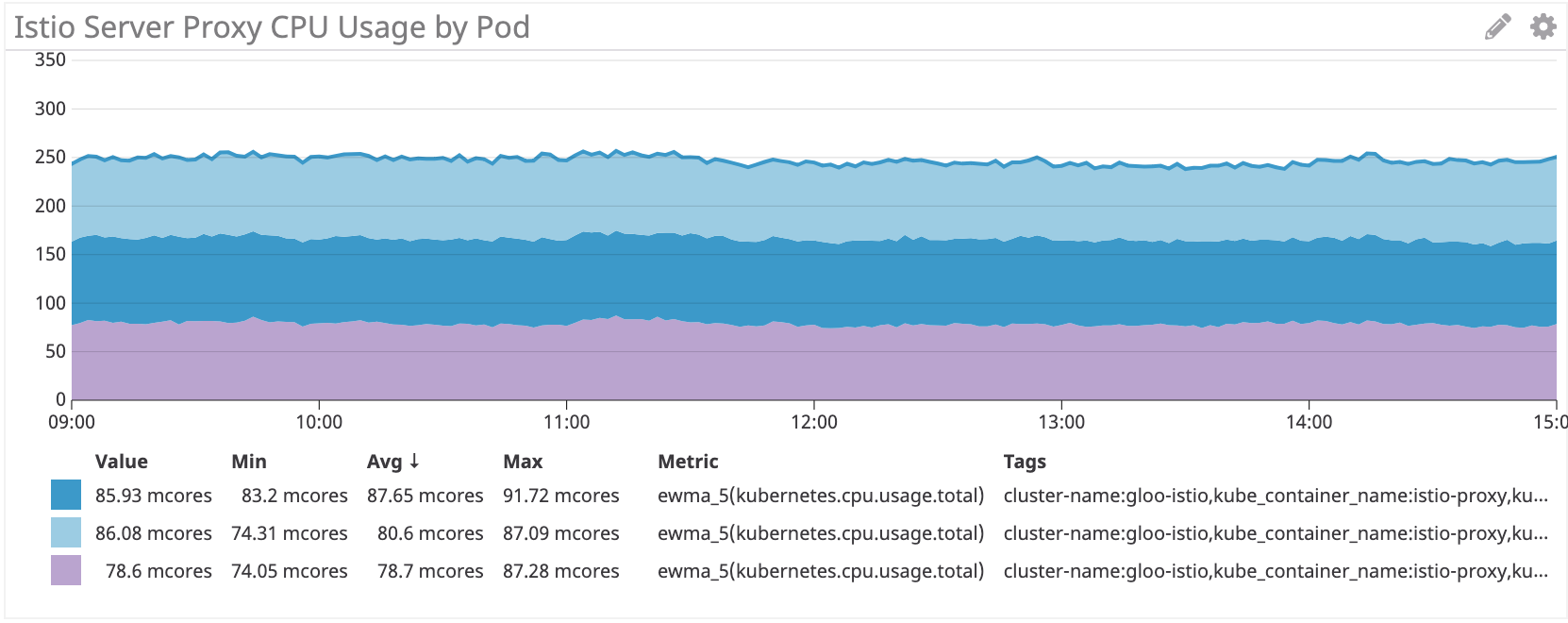
Istio / Envoy: ~ 80 multicore para o servidor irs
No lado do servidor, o Istio / Envoy sidecar consome cerca de 60% mais recursos de processador que o Linkerd.
Conclusão
O proxy Istio Envoy consome 50% a mais de CPU que o Linkerd em nossa carga de trabalho simulada. O painel de controle do Linkerd consome muito menos recursos que o Istio, especialmente para os principais componentes.
Ainda estamos pensando em como reduzir esses custos. Se você tem alguma idéia, compartilhe!