
A tecnologia de Harry Potter sobreviveu até hoje. Agora, para criar um vídeo completo de uma pessoa, basta uma de suas fotos ou fotografias. Pesquisadores de aprendizado de máquina do Skolkovo e do Samsung AI Center em Moscou publicaram seu trabalho sobre a criação desse sistema, juntamente com vários vídeos de celebridades e objetos de arte que receberam uma nova vida.

O texto do trabalho científico pode ser lido aqui . Tudo é bem interessante lá, com muitas fórmulas, mas o significado é simples: o sistema deles é guiado por "pontos de referência", visões do rosto, como nariz, dois olhos, duas sobrancelhas e a linha do queixo. Então ela instantaneamente entende o que é uma pessoa. E pode transferir todo o resto (cor, textura do rosto, bigode, barba por fazer etc.) para o vídeo de qualquer outra pessoa. Adaptar o rosto antigo a novas situações.
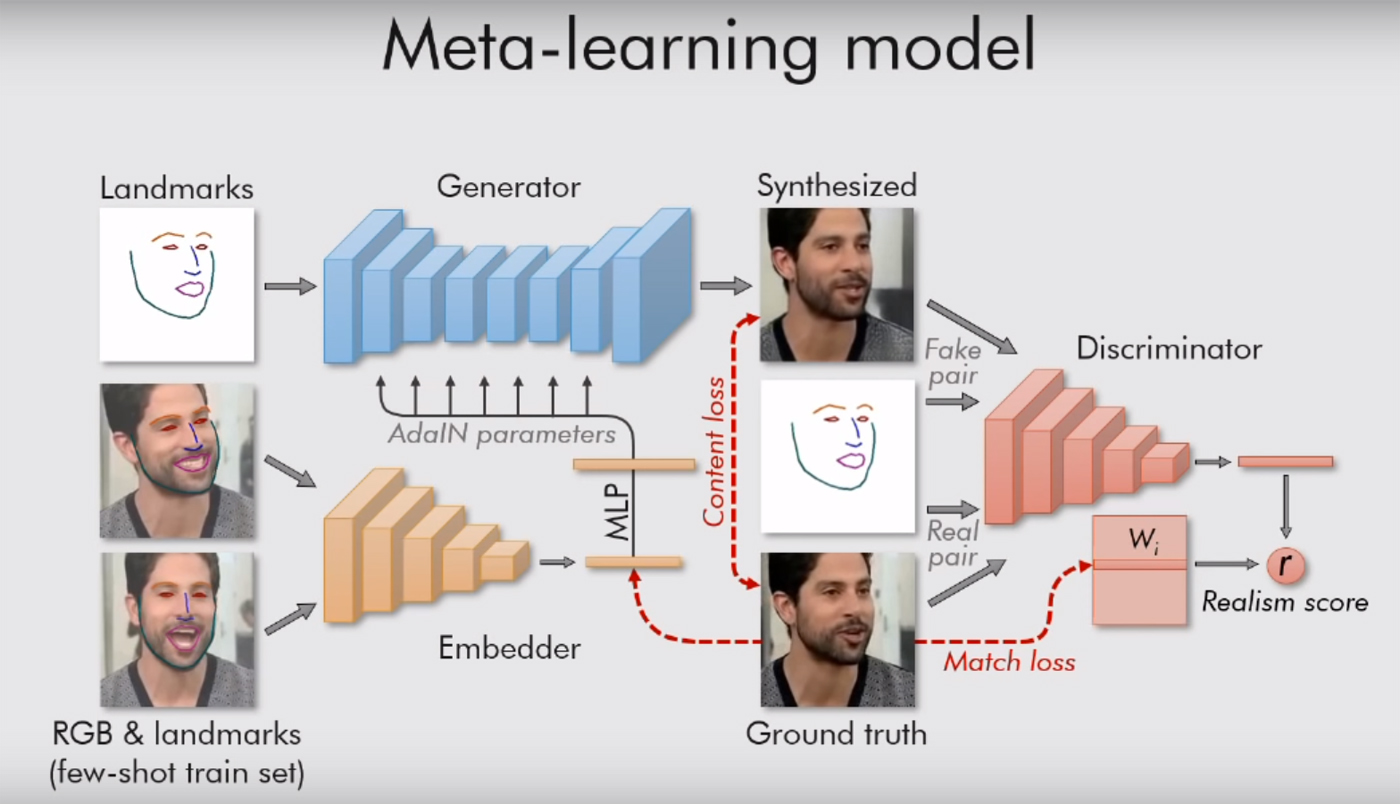
Obviamente, isso só funciona em retratos. O modelo precisa de apenas uma pessoa, com o rosto virado para nós, para que ele possa pelo menos ver os dois olhos. Então o sistema pode fazer qualquer coisa com ele, transmitir qualquer expressão facial para ele. É o suficiente para lhe dar um vídeo adequado (com outra pessoa com a cabeça na mesma posição).
Antes, a IA já havia aprendido a fazer diphakes, e os internautas zombavam das celebridades inserindo seus rostos no pornô e fazendo memes com Nicholas Cage. Mas para isso, eles tiveram que treinar os algoritmos em megabytes (ou melhor - gigabytes) de dados, encontrar o maior número possível de imagens e vídeos com os rostos das celebridades para produzir um resultado mais ou menos decente. O criador do Deepfakes disse que leva de 8 a 12 horas para compilar um pequeno vídeo. O novo sistema gera o resultado instantaneamente e, na entrada, precisa de apenas uma imagem.
Com o sistema anterior, nunca poderíamos olhar para a Mona Lisa viva, temos apenas um ângulo. Agora, com algoritmos de benchmarking, isso está se tornando possível. O ideal não é alcançado, mas algo já está próximo.

Os pesquisadores de Moscou também usam uma rede geradora-adversária. Dois modelos do algoritmo estão lutando entre si. Cada um tenta enganar o oponente e provar a ele que o vídeo que ele cria é real. Dessa maneira, um certo nível de realismo é alcançado: uma imagem de um rosto humano não é divulgada “para a luz” se o modelo crítico não tiver mais de 90% de certeza de sua autenticidade. Como dizem os autores em seu trabalho, dezenas de milhões de parâmetros são regulados nas imagens, mas devido a esse sistema, o trabalho ferve muito rapidamente.

Se houver várias fotos, o resultado será aprimorado. Novamente, a maneira mais fácil é trabalhar com celebridades que já são tiradas de todos os ângulos possíveis. Para alcançar o "realismo ideal", são necessárias 32 fotos. Nesse caso, as fotos AI geradas em baixa resolução serão indistinguíveis das fotos humanas reais. Pessoas não treinadas neste estágio não são mais capazes de identificar uma farsa - talvez as chances permaneçam com especialistas ou com parentes próximos do "experimental" de todas essas imagens.
Se houver apenas uma foto ou imagem, o resultado nem sempre é o melhor. Você pode ver artefatos no vídeo quando a cabeça está em movimento sem problemas. Os próprios pesquisadores dizem que seu ponto mais fraco é o olhar. O modelo baseado nos marcos do rosto nem sempre entende como e onde uma pessoa deve procurar.
