Todos nós sabemos como é um hash, mas você já se perguntou quantas vezes um personagem em particular é encontrado em um hash? Eu pensei. E eu decidi verificar. Esboçou um script Python para contar, e aqui está o que aconteceu.
Primeiro, gerei uma sequência aleatória de caracteres (comprimento de 0 a 1000).
def random_string(from_int, to_int): return str(''.join(random.SystemRandom().choice(string.ascii_letters + string.digits + string.punctuation) for _ in range(random.randint(from_int, to_int))))
Em seguida, peguei o hash MD5 da string.
def md5_from_string(string): return hashlib.md5(string.encode('utf-8')).hexdigest()
Depois - calculei quantos dígitos de 0 a 9 estão no hash. Em uma amostra de 1000 hashes, recebi os seguintes dados:
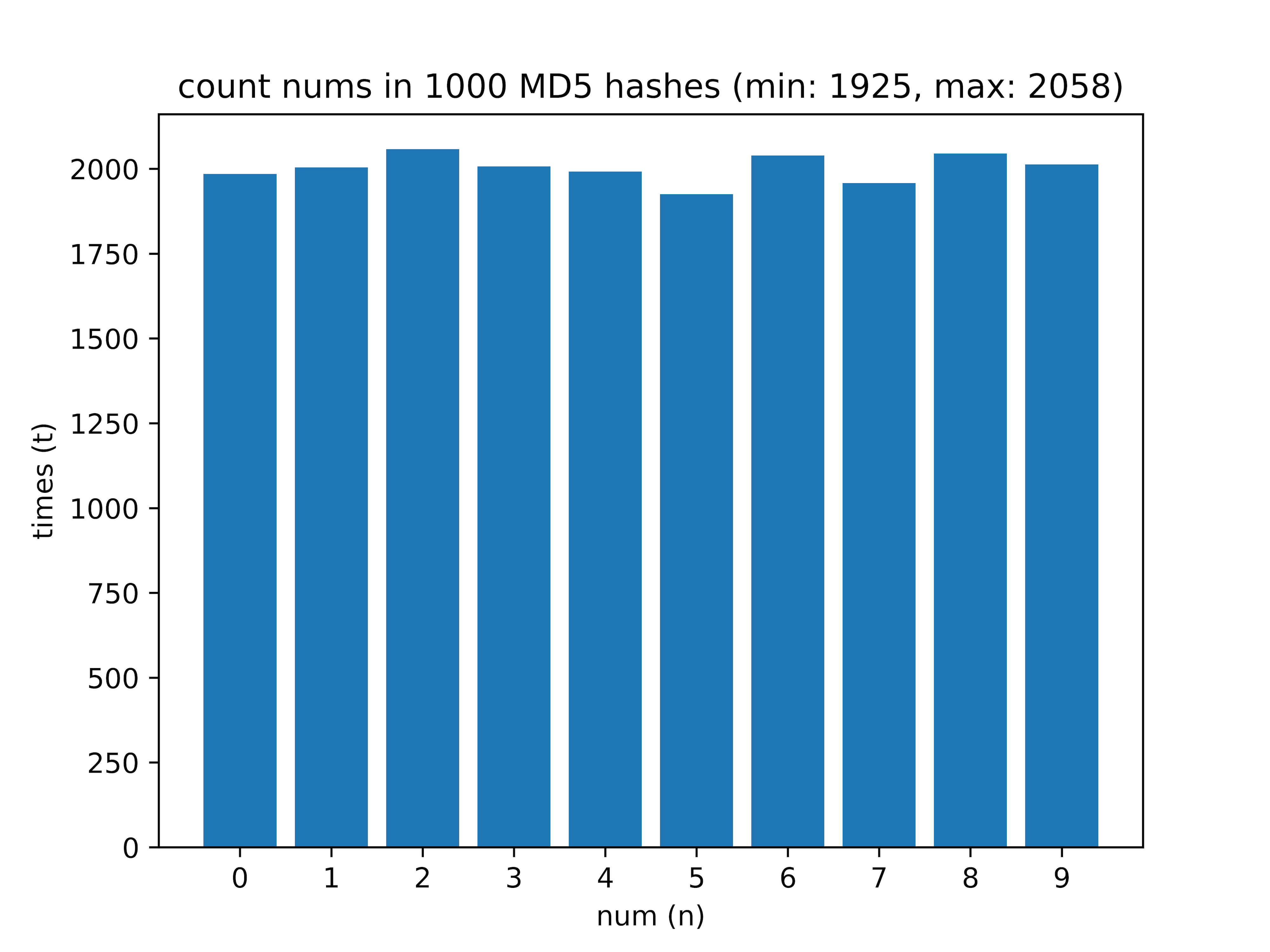
Aqui, a diferença entre o dígito encontrado com mais frequência e o mais raro (valor delta) é interessante.

Além disso, para rastrear a alteração no valor delta, ele fez amostras de 10.000, 100.000, 1.000.000, 10.000.000 de hashes.

A seguir, é apresentada uma lista com os valores dos números mínimo e máximo e o valor delta em amostras com diferentes números de hashes MD5:
- 100 - min: 179, máx: 230, delta: 22,17%
- 1000 - min: 1925, máx: 2058, delta: 6,46%
- 10000 - min: 19769, máx: 20251, delta: 2,38%
- 100000 - min: 199297, máx: 200846, delta: 0,77%
- 1.000.000 - min: 1997650, máx: 2001690, delta: 0,20%
- 10000000 - min: 19991830, máx: 20004818, delta: 0,06%
O que temos: com um aumento no número de hashes na matriz, o valor delta diminui e qualquer dígito com quase a mesma probabilidade cairá na matriz. Assim, quanto maior a amostra, menor a diferença entre números encontrados com frequência e raramente vistos. Consequentemente, a probabilidade de obter um dígito específico em um hash tende à uniformidade.
Essas informações formaram a base do algoritmo que implementamos na
plataforma de competição
bepeam.com