
Oi Neste artigo, quero explicar, em termos leigos, como o
roubo aparece nas VMs e falar sobre alguns dos artefatos menos do que óbvios que encontramos durante a pesquisa sobre o tópico em que eu estava envolvido como CTO do
Mail. com a plataforma
Cloud Solutions . A plataforma executa o KVM.
Tempo de roubo de CPU é o tempo durante o qual uma VM não recebe os recursos necessários para operar. Esse tempo só pode ser calculado em um sistema operacional convidado em ambientes de virtualização. Não é muito claro onde os recursos alocados são perdidos, como em situações da vida real. No entanto, decidimos descobrir e realizamos uma série de testes para fazer isso. Isso não quer dizer que sabemos tudo sobre
roubar, mas há algumas coisas fascinantes que gostaríamos de compartilhar com você.
1. O que é roubo ?
Roubar é uma métrica que indica uma falta de tempo de CPU para processos de VM. Conforme descrito no
patch do
kvm do
KVM ,
roubo é o tempo que um hipervisor gasta executando outros processos em um sistema operacional host, enquanto o processo da VM está em uma fila de execução. Em outras palavras, o
roubo é calculado como a diferença entre o momento em que um processo está pronto para ser executado e o momento em que o tempo da CPU é alocado para o processo.
O kernel da VM obtém a métrica de
roubo do hipervisor. O hypervisor não especifica quais processos ele está executando. Apenas diz: "Estou ocupado e não posso alocar nenhum tempo para você". Em uma KVM, o cálculo de
roubo é suportado em
patches . Existem dois pontos principais em relação a isso:
- Uma VM aprende sobre roubo do hipervisor. Isso significa que, em termos de perdas, o roubo é uma medida indireta que pode ser distorcida de várias maneiras.
- O hypervisor não compartilha com as informações da VM sobre o que está ocupado. O ponto mais crucial é que ele não aloca tempo para isso. A própria VM, portanto, não pode detectar distorções na métrica de roubo , que pode ser estimada pela natureza dos processos concorrentes.
2. O que afeta o roubo ?
2.1 Calculando roubo
Essencialmente, o
roubo é calculado mais ou menos da mesma maneira que o tempo de utilização da CPU. Não há muitas informações sobre como a utilização é calculada. Provavelmente porque a maioria dos profissionais acha óbvio. No entanto, existem algumas armadilhas. O processo é descrito em
um artigo de Brendann Gregg . Ele discute uma série de nuances sobre como calcular a utilização e os cenários nos quais o cálculo estará errado:
- Superaquecimento e limitação da CPU.
- Ativar / desativar o Turbo Boost, resultando em uma alteração na taxa de clock da CPU.
- A mudança de intervalo de tempo que ocorre quando as tecnologias de economia de energia da CPU, por exemplo, SpeedStep, são usadas.
- Problemas relacionados ao cálculo de médias: medir a utilização por um minuto a 80% da energia pode ocultar um aumento de 100% no curto prazo.
- Um spinlock que resulta em um cenário no qual o processador é utilizado, mas o processo do usuário não progride. Como resultado, a utilização calculada da CPU será 100%, mas o processo não consumirá realmente o tempo da CPU.
Não encontrei nenhum artigo descrevendo esses cálculos de
roubo (se você souber de algum, compartilhe-o na seção de comentários). Como você pode ver no código-fonte, o mecanismo de cálculo é o mesmo da utilização. A única diferença é que outro contador é adicionado especificamente para o processo KVM (processo VM), que calcula quanto tempo o processo KVM aguarda o tempo da CPU. O contador obtém dados da CPU de suas especificações e verifica se todos os seus ticks estão sendo utilizados pelo processo da VM. Se todos os ticks estiverem sendo usados, a CPU estará ocupada apenas com o processo da VM. Caso contrário, sabemos que a CPU estava fazendo outra coisa e o
roubo aparece.
O processo pelo qual o
roubo é calculado está sujeito aos mesmos problemas que o cálculo regular da utilização. Esses problemas não são tão comuns, mas podem parecer bastante confusos.
2.2 Tipos de virtualização KVM
Em geral, existem três tipos de virtualização e todos são suportados por uma KVM. O mecanismo pelo qual o
roubo ocorre pode depender do tipo de virtualização.
Tradução Nesse caso, o sistema operacional da VM funcionará com dispositivos de hipervisor físico da seguinte maneira:
- O SO convidado envia um comando para seu dispositivo convidado.
- O driver de dispositivo convidado aceita o comando, cria uma solicitação de dispositivo do BIOS e envia o comando ao hipervisor.
- O processo do hypervisor converte o comando em um comando de dispositivo físico, tornando-o mais seguro, entre outras coisas.
- O driver de dispositivo físico aceita o comando modificado e o encaminha para o próprio dispositivo físico.
- Os resultados da execução do comando retornam seguindo o mesmo caminho.
A vantagem da tradução é que ela nos permite emular qualquer dispositivo e não requer nenhuma preparação especial do kernel do SO. Mas isso ocorre às custas do desempenho.
Virtualização de hardware. Nesse caso, um dispositivo recebe comandos do sistema operacional no nível do hardware. Este é o melhor método mais rápido e geral. Infelizmente, nem todos os dispositivos físicos, hipervisores e sistemas operacionais convidados são compatíveis. Por enquanto, os principais dispositivos que suportam a virtualização de hardware são CPUs.
Paravirtualização. A opção mais comum para virtualização de dispositivos em um KVM e o tipo mais difundido de virtualização para sistemas operacionais convidados. Sua principal característica é que ele trabalha com alguns subsistemas de hipervisor (por exemplo, rede ou pilha de unidades) e aloca páginas de memória usando uma API de hipervisor sem converter comandos de baixo nível. A desvantagem desse método de virtualização é a necessidade de modificar o kernel do sistema operacional convidado para permitir a interação com o hipervisor usando a mesma API. A solução mais comum para esse problema é instalar drivers especiais no sistema operacional convidado. Em uma KVM, essa API é chamada de
API virtio .
Quando a paravirtualização é usada, o caminho para o dispositivo físico é muito menor do que nos casos em que a tradução é usada, porque os comandos são enviados diretamente da VM para o processo do hypervisor no host. Isso acelera a execução de todas as instruções na VM. Em um KVM, uma API virtio é responsável por isso. Funciona apenas para alguns dispositivos, como adaptadores de rede e unidade. É por isso que os drivers virtio são instalados nas VMs.
O outro lado dessa aceleração é que nem todos os processos executados em uma VM permanecem na VM. Isso resulta em vários efeitos, que podem causar
roubo . Se você quiser saber mais, comece com
Uma API para E / S virtual: virtio .
2.3 Programação justa
Uma VM em um hypervisor é, de fato, um processo regular, sujeito a leis de agendamento (distribuição de recursos entre processos) em um kernel Linux. Vamos dar uma olhada mais de perto nisso.
O Linux usa o chamado CFS, Completely Fair Scheduler, que se tornou o padrão no kernel 2.6.23. Para entender esse algoritmo, leia Linux Kernel Architecture ou o código fonte. A essência do CFS reside na distribuição do tempo da CPU entre os processos, dependendo do tempo de execução. Quanto mais tempo de CPU um processo requer, menor é o tempo de CPU. Isso garante a execução "justa" de todos os processos e ajuda a evitar que um processo ocupe todos os processadores, o tempo todo e permita que outros processos também sejam executados.
Às vezes, esse paradigma resulta em artefatos interessantes. Os usuários antigos do Linux, sem dúvida, se lembrarão de como um editor de texto comum na área de trabalho congelaria ao executar aplicativos com muitos recursos, como um compilador. Isso aconteceu porque tarefas leves de recursos, como aplicativos de desktop, estavam competindo com tarefas que usavam muitos recursos, como um compilador. O CFS considera isso injusto e, portanto, interrompe o editor de texto periodicamente e permite que a CPU processe as tarefas do compilador. Isso foi corrigido usando o mecanismo
sched_autogroup ; existem, no entanto, muitas outras peculiaridades da distribuição de tempo da CPU. Este artigo não é realmente sobre o quão ruim é o CFS. É uma tentativa de chamar a atenção para o fato de que a distribuição "justa" do tempo da CPU não é a tarefa mais trivial.
Outro aspecto importante de um agendador é a preempção. Isso é necessário para livrar a CPU de qualquer processo excessivo e permitir que outros trabalhem também. Isso é chamado de
alternância de contexto . Todo o contexto da tarefa é mantido: status da pilha, registradores etc., após o qual o processo é deixado em espera e é substituído por outro processo. Esta é uma operação cara para um sistema operacional. É raramente usado, mas na verdade não é ruim. A alternância frequente de contexto pode ser um indicador de um problema no SO, mas geralmente ocorre continuamente e não é sinal de nenhum problema em particular.
Esse longo discurso foi necessário para explicar um fato: em um planejador Linux justo, quanto mais recursos de CPU o processo consome, mais rápido ele será parado para permitir que outros processos funcionem. Se isso é certo ou não, é uma questão complexa, e a solução é diferente dependendo da carga. Até recentemente, o agendador do Windows priorizava os aplicativos da área de trabalho, o que resultava em processos de segundo plano mais lentos. No Sun Solaris, havia cinco classes diferentes de agendadores. Quando a virtualização foi introduzida, eles adicionaram outro, o
agendador de compartilhamento justo , porque os outros não estavam funcionando corretamente com a virtualização do Solaris Zones. Para aprofundar isso, recomendo começar com
Solaris Internals: Solaris 10 e OpenSolaris Kernel Architecture ou
Entendendo o kernel do Linux .
2.4 Como podemos monitorar o roubo ?
Assim como qualquer outra métrica da CPU, é fácil monitorar o
roubo dentro de uma VM. Você pode usar qualquer ferramenta de medição métrica da CPU. O principal é que a VM deve estar no Linux. Por alguma razão, o Windows não fornece essas informações ao usuário. :(
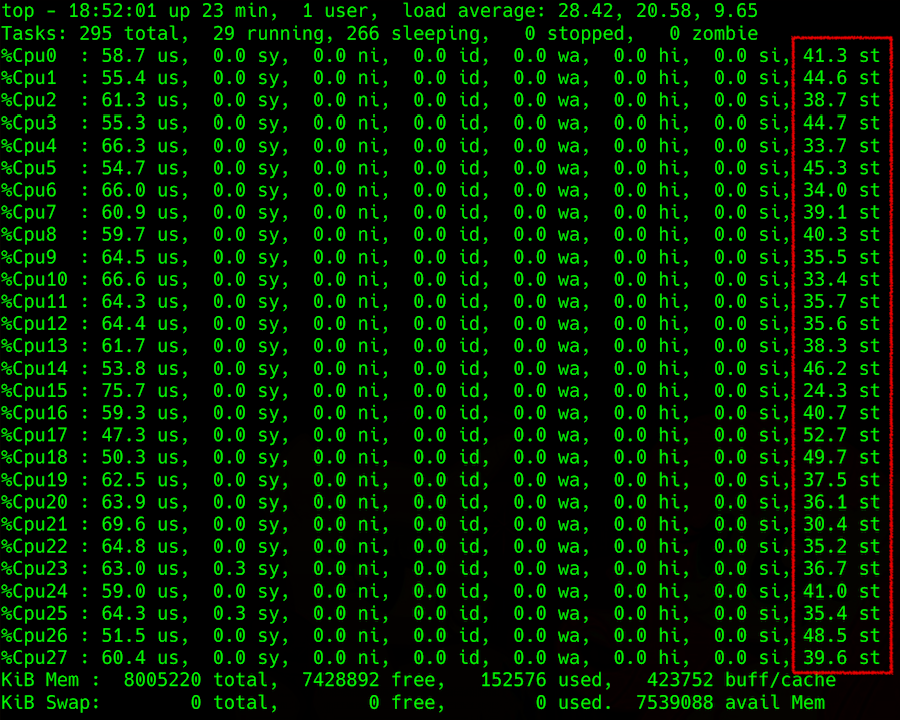 saída superior: especificação da carga da CPU com roubo na coluna da direita
saída superior: especificação da carga da CPU com roubo na coluna da direitaAs coisas ficam complicadas ao tentar obter essas informações de um hipervisor. Você pode tentar prever
roubo em uma máquina host, usando Load Average (LA), por exemplo. Este é o valor médio do número de processos na fila de execução. O método de cálculo para esse parâmetro não é simples, mas, em geral, se um AL padronizado de acordo com o número de encadeamentos da CPU for maior que 1, isso significa que o servidor Linux está sobrecarregado.
Então, o que todos esses processos estão esperando? Obviamente, a CPU. Essa resposta não é muito precisa, no entanto, porque às vezes a CPU é livre e o LA é muito alto. Lembre-se de
que o NFS cai e o LA aumenta ao mesmo tempo . Uma situação semelhante pode ocorrer com a unidade e outros dispositivos de entrada / saída. De fato, os processos podem estar aguardando o fim de um bloqueio: físico (relacionado a dispositivos de entrada / saída) ou lógico (um objeto mutex, por exemplo). O mesmo vale para bloqueios no nível do hardware (por exemplo, resposta do disco) ou bloqueios no nível lógico (chamados "primitivas de bloqueio"), que incluem várias entidades, adaptabilidade e rotação mutex, semáforos, variáveis de condição, bloqueios rw, bloqueios de ipc ...).
Outra característica do LA é que ele é calculado como um valor médio dentro do sistema operacional. Por exemplo, se 100 processos competem por um arquivo, o LA é 50. Esse grande número pode parecer ruim para o sistema operacional. No entanto, para códigos mal escritos, isso pode ser normal. Somente esse código específico seria ruim e o restante do sistema operacional pode ser bom.
Devido a essa média (por menos de um minuto), determinar qualquer coisa usando um AL não é a melhor ideia, pois pode produzir resultados extremamente ambíguos em alguns casos. Se você tentar descobrir mais sobre isso, descobrirá que a Wikipedia e outros recursos disponíveis descrevem apenas os casos mais simples, e o processo não é descrito em detalhes. Se você estiver interessado nisso, visite
Brendann Gregg e siga os links.
3. efeitos especiais
Agora vamos aos principais casos de
roubo que encontramos. Permitam-me explicar como eles resultam do exposto acima e como eles se correlacionam com as métricas do hipervisor.
Superutilização. O caso mais simples e mais comum: o hypervisor está sendo superutilizado. De fato, com muitas VMs executando e consumindo muitos recursos da CPU, a concorrência é alta e a utilização de acordo com o LA é maior que 1 (padronizada de acordo com os threads da CPU). Tudo fica dentro de todas as VMs.
O roubo enviado pelo hypervisor também cresce. Você precisa redistribuir a carga ou desativar algo. No geral, tudo isso é lógico e direto.
Paravirtualização vs instâncias únicas. Há apenas uma VM em um hypervisor. A VM consome uma pequena parte dela, mas fornece alta carga de entrada / saída, por exemplo, para uma unidade. Inesperadamente, um pequeno
roubo de menos de 10% aparece (como mostram alguns dos testes que realizamos).
Este é um caso curioso. Aqui, o
roubo aparece devido a bloqueios no nível dos dispositivos paravirtualizados. Dentro da VM, um ponto de interrupção é criado. Isso é processado pelo driver e vai para o hipervisor. Devido ao processamento do ponto de interrupção no hypervisor, a VM vê isso como uma solicitação enviada. Está pronto para ser executado e aguarda a CPU, mas não recebe tempo de CPU. A VM pensa que o tempo foi roubado.
Isso acontece quando o buffer é enviado. Ele vai para o espaço do kernel do hypervisor e esperamos por ele. Do ponto de vista da VM, ela deve retornar imediatamente. Portanto, de acordo com nosso algoritmo de cálculo de
roubo , esse tempo é considerado roubado. É provável que outros mecanismos possam estar envolvidos nisso (por exemplo, o processamento de outras
chamadas do sistema ), mas eles não devem diferir em grau significativo.
Agendador vs VMs altamente carregadas. Quando uma VM sofre mais
roubos do que as outras, isso é conectado diretamente ao agendador. Quanto maior a carga que um processo coloca em uma CPU, mais rápido o agendador a joga fora, para permitir que outros processos funcionem. Se a VM estiver consumindo pouco, quase não haverá
roubo. Seu processo está parado e esperando, e precisa ser concedido mais tempo. Se a VM colocar uma carga máxima em todos os núcleos, o processo será descartado com mais frequência e a VM terá menos tempo.
É ainda pior quando os processos dentro da VM tentam obter mais CPU, porque eles não podem processar os dados. Em seguida, o sistema operacional no hipervisor fornecerá menos tempo de CPU por causa da otimização justa. Esse processo processa bolas de neve e
rouba ondas no céu, enquanto outras VMs podem nem perceber. Quanto mais núcleos existem, pior é a infeliz VM. Em resumo, as VMs altamente carregadas com muitos núcleos sofrem mais.
LA baixo, mas
roubo está presente. Se o AL for de cerca de 0,7 (o que significa que o hipervisor parece estar sobrecarregado), mas há
roubos em algumas VMs:
- O exemplo de paravirtualização mencionado acima se aplica. A VM pode estar recebendo métricas que indicam roubo , enquanto o hipervisor não tem problemas. De acordo com os resultados de nossos testes, esse roubo não costuma exceder 10% e não tem um impacto significativo no desempenho do aplicativo na VM.
- O parâmetro LA foi calculado incorretamente. Mais precisamente, foi calculado corretamente em um momento específico, mas, na média, é mais baixo do que deveria ser por um minuto. Por exemplo, se uma VM (um terço do hypervisor) consumir todas as CPUs por 30 segundos, o LA por um minuto será 0,15. Quatro dessas VMs, trabalhando ao mesmo tempo, resultarão em um valor de 0,6. Com base no LA, você não seria capaz de deduzir que, por 30 segundos para cada um deles, o roubo era quase 25%.
- Novamente, isso aconteceu por causa do agendador, que decidiu que alguém estava "comendo" demais e os fez esperar. Enquanto isso, ele alternará contexto, processará pontos de interrupção e atenderá a outros assuntos importantes do sistema. Como resultado, algumas VMs não enfrentam problemas e outras sofrem perdas significativas de desempenho.
4. Outras distorções
Há um milhão de razões possíveis para distorção da alocação justa do tempo da CPU em uma VM. Por exemplo, hyperthreading e NUMA adicionam complexidade aos cálculos. Eles complicam a escolha do núcleo usado para executar um processo porque um planejador usa coeficientes; isto é, pesos, o que complica ainda mais os cálculos ao alternar contextos.
Existem distorções que surgem de tecnologias como o Turbo Boost ou seu oposto, o modo de economia de energia, que pode aumentar ou diminuir artificialmente a velocidade do núcleo da CPU e até a fatia de tempo. Ativando o Turbo Boost, diminuindo a produtividade de um thread da CPU devido a um aumento de desempenho em outro. Nesse momento, as informações sobre a velocidade atual do clock da CPU não são enviadas para a VM, que pensa que alguém está roubando seu tempo (por exemplo, solicitou 2 GHz e obteve metade do valor).
De fato, pode haver muitas razões para distorção. Você pode encontrar algo totalmente diferente em qualquer sistema. Eu recomendo começar com os livros vinculados acima e obter estatísticas do hypervisor usando ferramentas como perf, sysdig, systemtap e
dezenas de outras .
5. Conclusões
- Alguns roubos podem aparecer devido à paravirtualização e isso pode ser considerado normal. Fontes online dizem que esse valor pode ser de 5 a 10%. Depende do aplicativo em uma VM e da carga que a VM coloca em seus dispositivos físicos. É importante prestar atenção em como os aplicativos se sentem dentro de uma VM.
- A correlação entre a carga no hypervisor e o roubo dentro de uma VM nem sempre é certa. Os dois cálculos de roubo podem estar errados em alguns casos e com cargas diferentes.
- O Agendador não favorece processos que solicitam muitos recursos. Ele tenta dar menos àqueles que pedem mais. Grandes instâncias são más.
- Um pouco de roubo também pode ser normal sem paravirtualização (levando em consideração a carga na VM, as particularidades das cargas dos vizinhos, a distribuição da carga entre os threads e outros fatores).
- Se você deseja calcular o roubo em um sistema específico, pesquise as várias possibilidades, colete métricas, analise-as minuciosamente e pense em como distribuir a carga de maneira justa. Independentemente, pode haver desvios, que devem ser verificados usando testes ou visualizados em um depurador do kernel.