Olá
Meu nome é Marat Gayanov, quero compartilhar com você minha solução para o problema do
concurso Best Reverser , para mostrar como criar keygen para este caso.
Descrição do produto
Nesta competição, os participantes recebem jogos de ROM para o Sega Mega Drive (
best_reverser_phd9_rom_v4.bin ).
Tarefa: pegar uma chave que, juntamente com o endereço de e-mail do participante, seja reconhecida como válida.
Então a solução ...
As ferramentas
Verificando o comprimento da chave
O programa não aceita todas as chaves: você precisa preencher o campo inteiro, são 16 caracteres. Se a chave for mais curta, você verá uma mensagem: “Comprimento errado! Tente novamente ... ".
Vamos tentar encontrar essa linha no programa, para o qual usaremos a pesquisa binária (Alt-B). O que vamos encontrar?
Encontraremos não apenas isso, mas também as outras linhas de serviço próximas: “Chave errada! Tente novamente ... ”e“ VOCÊ É O MELHOR REVERSOR! ”.
WRONG_KEY_MSG WRONG_LENGTH_MSG ,
YOU_ARE_THE_BEST_MSG e
WRONG_KEY_MSG por conveniência.
Interrompa a leitura do endereço
0x0000FDFA - descubra quem trabalha com a mensagem "Comprimento errado! Tente novamente ... ". E execute o depurador (ele irá parar várias vezes antes que a tecla possa ser inserida, basta pressionar F9 a cada parada). Digite seu e-mail, digite
ABCD .
O depurador leva a
0x00006FF0 tst.b (a1)+ :
Não há nada interessante no próprio bloco. É muito mais interessante quem transfere o controle aqui. Observamos a pilha de chamadas:
Clique e obtenha aqui - para a instrução
0x00001D2A jsr (sub_6FC0).l :
Vemos que todas as mensagens possíveis foram encontradas em um só lugar. Mas vamos descobrir para onde o controle é transferido no bloco
WRONG_KEY_LEN_CASE_1D1C . Não vamos definir quebras, basta mover o cursor sobre a seta que vai para o bloco. O chamador está localizado em
0x000017DE loc_17DE (que vou renomear para
CHECK_KEY_LEN ):
Coloque uma quebra no endereço
0x000017EC cmpi.b 0x20 (a0, d0.l) (a instrução neste contexto procura verificar se há um caractere vazio no final da matriz de caracteres chave), reinicie, digite novamente o correio e a chave
ABCD . O depurador para e mostra que a chave digitada está localizada no endereço
0x00FF01C7 (armazenada naquele momento no registro
a0 ):
Esta é uma boa descoberta, através dela vamos pegar tudo. Mas primeiro, marque os bytes da chave por conveniência:
Ao rolar para cima neste local, vemos que o email é armazenado ao lado da chave:
Mergulhamos cada vez mais fundo, e é hora de encontrar um critério para a correção da chave. Em vez disso, a primeira metade da chave.
Critério para a correção da primeira metade da chave
Cálculos preliminares
É lógico supor que imediatamente após a verificação do comprimento, outras operações com a tecla sejam seguidas. Considere o bloco imediatamente após a verificação:
Este bloco está passando por um trabalho preliminar. A função
get_hash_2b (no original era
sub_1526 ) é chamada duas vezes. Primeiro, o endereço do primeiro byte da chave é transmitido a ele (o registro
a0 contém o endereço
KEY_BYTE_0 ), na segunda vez - o quinto (
KEY_BYTE_4 ).
Chamei a função assim porque considera algo como um hash de 2 bytes. Este é o nome mais compreensível que escolhi.
Não considerarei a função em si, mas vou escrevê-la imediatamente em python. Ela faz coisas simples, mas sua descrição com capturas de tela ocupará muito espaço.
A coisa mais importante a dizer sobre isso: o endereço de entrada é fornecido à entrada e o trabalho está sendo feito em 4 bytes desse endereço. Ou seja, eles enviaram o primeiro byte da chave para a entrada e a função funcionará com o 1,2,3,4º. Arquivado em quinto, a função funciona com o 5,6,7,8º. Em outras palavras, neste bloco existem cálculos na primeira metade da chave. O resultado é gravado no registro
d0 .
Portanto, a função
get_hash_2b :
Escreva imediatamente uma função de decodificação de hash:
Não criei uma função de decodificação melhor e ela não está totalmente correta. Portanto, vou verificar assim (não agora, mas muito mais tarde):
key_4s == decode_hash_4s(get_hash_2b(key_4s))
Verifique a operação de
get_hash_2b . Estamos interessados no estado do registro
d0 após a execução da função.
0x000017FE quebras em
0x000017FE ,
0x00001808 , a chave que
0x00001808 ABCDEFGHIJKLMNOP .
Os valores
0xABCD ,
0xEF01 são inseridos no registro
d0 . E o que
get_hash_2b dará?
>>> first_hash = get_hash_2b("ABCD") >>> hex(first_hash) 0xabcd >>> second_hash = get_hash_2b("EFGH") >>> hex(second_hash) 0xef01
Verificação aprovada.
Então
xor eor.w d0, d5 produzido, o resultado é inserido em
d5 :
>>> hex(0xabcd ^ 0xef01) 0x44cc
A obtenção desse hash é
0x44CC e consiste em cálculos preliminares. Além disso, tudo só se torna mais complicado.
Para onde vai o hash
Não podemos ir mais longe se não soubermos como o programa funciona com o hash. Certamente ele passa de
d5 para a memória, porque O registro é útil em outro lugar. Podemos encontrar esse evento através do rastreamento (assistindo
d5 ), mas não manual, mas automático. O script a seguir ajudará:
#include <idc.idc> static main() { auto d5_val; auto i; for(;;) { StepOver(); GetDebuggerEvent(WFNE_SUSP, -1); d5_val = GetRegValue("d5"); // d5 if (d5_val != 0xFFFF44CC){ break; } } }
Deixe-me lembrá-lo de que agora estamos no último intervalo
0x00001808 eor.w d0, d5 . Cole o script (
Shift-F2 ), clique em
RunO script irá parar na instrução
0x00001C94 move.b (a0, a1.l), d5 , mas neste momento o
d5 já foi limpo. No entanto, vemos que o valor de
d5 movido pela instrução
0x00001C56 move.w d5,a6 : é gravado na memória no endereço
0x00FF0D46 (2 bytes).
Lembre-se: o hash é armazenado em 0x00FF0D46 .Pegamos as instruções lidas em
0x00FF0D46-0x00FF0D47 (estabelecemos uma pausa para leitura). Pegou 4 blocos:




Como escolher os certos / certos?
Volte ao começo:
Este bloco determina se o programa irá para
LOSER_CASE ou
WINNER_CASE :
Vemos que no registro
d1 deve ser zero para vencer.
Onde está definido o zero? Basta rolar para cima:
Se a
loc_1EEC for atendida no bloco
loc_1EEC :
*(a6 + 0x24) == *(a6 + 0x22)
então obtemos zero em
d5 .
Se colocarmos uma quebra na instrução
0x00001F16 beq.w loc_20EA , veremos que
a6 + 0x24 = 0x00FF0D6A e o valor
0x4840 é armazenado lá. E em
a6 + 0x22 = 0x00FF0D68 é armazenado.
Se
0xCB4C - chaves diferentes, e-mails, veremos que
0xCB4C - .
A primeira metade da chave será aceita apenas se em 0x00FF0D6A também 0xCB4C . Este é o critério para a correção da primeira metade da chave.Descobrimos quais blocos estão escritos em
0x00FF0D6A - coloque um intervalo no registro, digite o e-mail e a chave novamente.
E vamos encontrar esse bloco
loc_EAC (na verdade existem 3 deles, mas os dois primeiros zeram
0x00FF0D6A ):
Este bloco pertence à função
sub_E3E .
Através da pilha de chamadas, descobrimos que a função
sub_E3E chamada nos blocos
loc_1F94 ,
loc_203E :
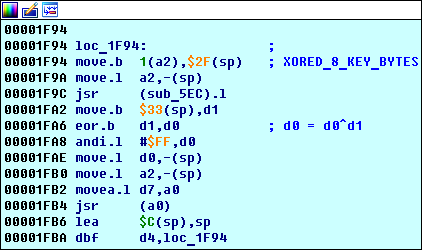

Lembra que encontramos 4 blocos antes?
loc_1F94 que vimos lá - este é o começo do principal algoritmo de processamento de chaves.
Primeiro loop importante loc_1F94
O fato de
loc_1F94 ser um ciclo é visível a partir do código: é executado
d4 vezes (consulte a instrução
0x00001FBA d4,loc_1F94 ):
O que procurar:
- Há uma função
sub_5EC . - A instrução 0x00001FB4 jsr (a0) chama a função sub_E3E (isso pode ser visto com um rastreamento simples).
O que está acontecendo aqui:
- A função
sub_5EC grava o resultado de sua execução no registro d0 (isso é discutido em uma seção separada abaixo). - O byte no endereço
sp+0x33 ( 0x00FFFF79 , informa o depurador) é armazenado no registro d1 , é igual ao segundo byte do endereço de hash da chave ( 0x00FF0D47 ). É fácil provar se você interrompe o registro em 0x00FFFF79 : ele funcionará nas instruções 0x00001F94 move.b 1(a2), 0x2F(sp) . No momento, o registro a2 armazena o endereço 0x00FF0D46 - o endereço do hash, ou seja, 0x1(a2) = 0x00FF0D46 + 1 - o endereço do segundo byte do hash. - O registro
d0 é escrito d0^d1 .
- O resultado xor'a resultante é dado à função
sub_E3E , cujo comportamento depende de seus cálculos anteriores (mostrado abaixo). - Repita.
Quantas vezes esse ciclo é executado?
Descubra isso. Execute o seguinte script:
#include <idc.idc> static main() { auto pc_val, d4_val, counter=0; while(pc_val != 0x00001F16) { StepOver(); GetDebuggerEvent(WFNE_SUSP, -1); pc_val = GetRegValue("pc"); if (pc_val == 0x00001F92){ counter++; d4_val = GetRegValue("d4"); print(d4_val); } } print(counter); }
0x00001F92 subq.l 0x1,d4 - aqui é determinado o que acontecerá em
d4 imediatamente antes do loop:
Lidamos com a função sub_5EC.
sub_5EC
Parte significativa do código:
onde
0x2c(a2) sempre
0x00FF1D74 .
Esta peça pode ser reescrita assim no pseudo-código:
d0 = a2 + 0x2C *(a2+0x2C) = *(a2+0x2C) + 1 #*(0x00FF1D74) = *(0x00FF1D74) + 1 result = *(d0) & 0xFF
Ou seja, 4 bytes de
0x00FF1D74 são o endereço, porque eles são tratados como um ponteiro.
Como reescrever a função
sub_5EC em python?
- Ou faça um despejo de memória e trabalhe com ele.
- Ou apenas anote todos os valores retornados.
O segundo método eu gosto mais, mas e se, com diferentes dados de autorização, os valores retornados forem diferentes? Veja isso.
O script ajudará nisso:
#include <idc.idc> static main() { auto pc_val=0, d0_val; while(pc_val != 0x00001F16){ pc_val = GetRegValue("pc"); if (pc_val == 0x00001F9C) StepInto(); else StepOver(); GetDebuggerEvent(WFNE_SUSP, -1); if (pc_val == 0x00000674){ d0_val = GetRegValue("d0") & 0xFF; print(d0_val); } } }
Acabei de comparar as saídas para o console com chaves diferentes, e-mails.
Executando o script várias vezes com chaves diferentes, veremos que a função
sub_5EC sempre retorna o próximo valor da matriz:
def sub_5EC_gen(): dump = [0x92, 0x8A, 0xDC, 0xDC, 0x94, 0x3B, 0xE4, 0xE4, 0xFC, 0xB3, 0xDC, 0xEE, 0xF4, 0xB4, 0xDC, 0xDE, 0xFE, 0x68, 0x4A, 0xBD, 0x91, 0xD5, 0x0A, 0x27, 0xED, 0xFF, 0xC2, 0xA5, 0xD6, 0xBF, 0xDE, 0xFA, 0xA6, 0x72, 0xBF, 0x1A, 0xF6, 0xFA, 0xE4, 0xE7, 0xFA, 0xF7, 0xF6, 0xD6, 0x91, 0xB4, 0xB4, 0xB5, 0xB4, 0xF4, 0xA4, 0xF4, 0xF4, 0xB7, 0xF6, 0x09, 0x20, 0xB7, 0x86, 0xF6, 0xE6, 0xF4, 0xE4, 0xC6, 0xFE, 0xF6, 0x9D, 0x11, 0xD4, 0xFF, 0xB5, 0x68, 0x4A, 0xB8, 0xD4, 0xF7, 0xAE, 0xFF, 0x1C, 0xB7, 0x4C, 0xBF, 0xAD, 0x72, 0x4B, 0xBF, 0xAA, 0x3D, 0xB5, 0x7D, 0xB5, 0x3D, 0xB9, 0x7D, 0xD9, 0x7D, 0xB1, 0x13, 0xE1, 0xE1, 0x02, 0x15, 0xB3, 0xA3, 0xB3, 0x88, 0x9E, 0x2C, 0xB0, 0x8F] l = len(dump) offset = 0 while offset < l: yield dump[offset] offset += 1
Então, o
sub_5EC está pronto.
sub_E3E linha é
sub_E3E .
sub_E3E
Parte significativa do código:
Descriptografar:
, d2, . a2 0xFF0D46, a2 + 0x34 = 0xFF0D7A d0 = *(a2 + 0x34) *(a2 + 0x34) = *(a2 + 0x34) + 1 , a0 a0 = d0 *(a0) = d2 offset, d2. a2 0xFF0D46, a2 + 0x24 = 0xFF0D6A - , (. ) 0x00000000, d0 = *(a2 + 0x24) d2 = d0 ^ d2 d2 = d2 & 0xFF d2 = d2 + d2 - 2 0x00011FC0 + d2, ROM, 0x00011FC0 + d2 a0 = 0x00011FC0 d2 = *(a0 + d2) 8 d0 = d0 >> 8 d2 = d0 ^ d2 *(a2 + 0x24) = d2
A função
sub_E3E resume a estas etapas:
- Salve o argumento de entrada em uma matriz.
- Calcule o deslocamento de deslocamento.
- Puxe 2 bytes no endereço
0x00011FC0 + offset (ROM). - Resultado =
( >> 8) ^ (2 0x00011FC0 + offset) .
Imagine a função
sub_E3E neste formato:
def sub_E3E(prev_sub_E3E_result, d2, d2_storage): def calc_offset(): return 2 * ((prev_sub_E3E_result ^ d2) & 0xff) d2_storage.append(d2) offset = calc_offset() with open("dump_00011FC0", 'rb') as f: dump_00011FC0_4096b = f.read() some = dump_00011FC0_4096b[offset:offset + 2] some = int.from_bytes(some, byteorder="big") prev_sub_E3E_result = prev_sub_E3E_result >> 8 return prev_sub_E3E_result ^ some
dump_00011FC0 é apenas um arquivo em que salvei 4096 bytes de
[0x00011FC0:00011FC0+4096] .
Atividade em torno de 1FC4
Ainda não vimos o endereço
0x00001FC4 , mas é fácil de encontrar, porque o bloco passa quase imediatamente após o primeiro ciclo.
Esse bloco altera o conteúdo no endereço
0x00FF0D46 (registrador
a2 ), e é aí que o hash da chave é armazenado; portanto, agora estamos estudando esse bloco. Vamos ver o que acontece aqui.
- A condição que determina se o ramo esquerdo ou direito está selecionado é:
( ) & 0b1 != 0 . Ou seja, o primeiro bit do hash é verificado. - Se você olhar para os dois ramos, verá:
- Nos dois casos, ocorre uma mudança para a direita em 1 bit.
- No ramo esquerdo, a operação de hash é executada
0x8000 . - Nos dois casos, o valor do hash processado é gravado no endereço
0x00FF0D46 , ou seja, o hash é substituído por um novo valor. - Cálculos adicionais não são críticos, porque, grosso modo, não há operações de gravação em
(a2) (não há instruções onde o segundo operando seria (a2) ).
Imagine um bloco como este:
def transform(hash_2b): new = hash_2b >> 1 if hash_2b & 0b1 != 0: new = new | 0x8000 return new
O segundo loop importante é loc_203E
loc_203E - loop, porque
0x0000206C bne.s loc_203E .
Esse ciclo calcula o hash e aqui está sua principal característica:
jsr (a0) é uma chamada para a função
sub_E3E que já examinamos - ela se baseia no resultado anterior de seu próprio trabalho e em algum argumento de entrada (foi passado pelo registro
d2 acima e aqui por
d0 )
Vamos descobrir o que é passado a ela através do registro
d0 .
Já encontramos a construção
0x34(a2) - a função
sub_E3E salva o argumento passado lá. Isso significa que argumentos passados anteriormente são usados nesse loop. Mas não todos.
Descriptografe a parte do código:
2 a2+0x1C move.w 0x1C(a2), d0 neg.l d0 a0 sub_E3E movea.l 0x34(a2), a0 , d0 2 a0-d0( d0 ) move.b (a0, d0.l), d0
A linha inferior é uma ação simples: a cada iteração, execute
d0 argumento armazenado no final da matriz. Ou seja, se 4 é armazenado em
d0 , pegamos o quarto elemento do final.
Se sim, o que exatamente
d0 ? Aqui eu fiz sem scripts, mas simplesmente os escrevi, colocando uma pausa no início deste bloco. Aqui estão eles:
0x04, 0x04, 0x04, 0x1C, 0x1A, 0x1A, 0x06, 0x42, 0x02 .
Agora, temos tudo para escrever uma função completa de cálculo de hash da chave.
Função de cálculo completo de hash
def finish_hash(hash_2b):
Verificação de integridade
- No depurador, definimos uma quebra no endereço
0x0000180A move.l 0x1000,(sp) (imediatamente após o cálculo do hash). - Quebre para o endereço
0x00001F16 beq.w loc_20EA (comparação do hash final com a constante 0xCB4C ). - No programa, digite a tecla
ABCDEFGHIJKLMNOP , pressione Enter . - O depurador para em
0x0000180A e vemos que o valor 0xFFFF44CC é 0x44CC registro d5 , 0x44CC é o primeiro hash. - Iniciamos o depurador ainda mais.
- Paramos em
0x00001F16 e vemos que em 0x00FF0D6A está 0x4840 - o hash final
- Agora confira nossa função finish_hash (hash_2b):
>>> r = finish_hash(0x44CC) >>> print(hex(r)) 0x4840
Estamos procurando a chave certa 1
A chave correta é essa chave cujo hash final é
0xCB4C (encontrado acima). Daí a pergunta: qual deve ser o primeiro hash para a final se tornar
0xCB4C ?
Agora é fácil descobrir:
def find_CB4C(): result = [] for hash_2b in range(0xFFFF+1): final_hash = finish_hash(hash_2b) if final_hash == 0xCB4C: result.append(hash_2b) return result >>> r = find_CB4C() >>> print(r)
A saída do programa sugere que há apenas uma opção: o primeiro hash deve ser
0xFEDC .
Quais caracteres precisamos para que seu primeiro hash seja
0xFEDC ?
Como
0xFEDC = __4_ ^ __4_ , você precisa encontrar apenas o
__4_ , porque o
__4_ = __4_ ^ 0xFEDC . E então decodifique os dois hashes.
O algoritmo é o seguinte:
def get_first_half(): from collections import deque from random import randint def get_pairs(): pairs = [] for i in range(0xFFFF + 1): pair = (i, i ^ 0xFEDC) pairs.append(pair) pairs = deque(pairs) pairs.rotate(randint(0, 0xFFFF)) return list(pairs) pairs = get_pairs() for pair in pairs: key_4s_0 = decode_hash_4s(pair[0]) key_4s_1 = decode_hash_4s(pair[1]) hash_2b_0 = get_hash_2b(key_4s_0) hash_2b_1 = get_hash_2b(key_4s_1) if hash_2b_0 == pair[0] and hash_2b_1 == pair[1]: return key_4s_0, key_4s_1
Um monte de opções, escolha qualquer.
Estamos procurando a chave certa 2
A primeira metade da chave está pronta, e a segunda?
Esta é a parte mais fácil.
O código responsável está localizado em
0x00FF2012 , cheguei a ele por rastreamento manual, começando com o endereço
0x00001F16 beg.w loc_20EA (validação da primeira metade da chave). No registro
a0 é o endereço de correio,
loc_FF2012 é um ciclo, porque
bne.s loc_FF2012 . É executado enquanto houver
*(a0+d0) (o próximo byte do correio).
E a instrução
jsr (a3) chama a já conhecida função
get_hash_2b , que agora trabalha com a segunda metade da chave.
Vamos deixar o código mais claro:
while(d1 != 0x20){ d2++ d1 = d1 & 0xFF d3 = d3 + d1 d0 = 0 d0 = d2 d1 = *(a0+d0) } d0 = get_hash_2b(key_byte_8) d3 = d0^d3 d0 = get_hash_2b(key_byte_12) d2 = d2 - 1 d2 = d2 << 8 d2 = d0^d2 if (d2 == d3) success_branch
No registro
d2 -
( -1) << 8 . Em
d3 , a soma de bytes dos caracteres de email.
O critério de correção é o seguinte:
__ ^ d2 == ___2 ^ d3 .
Escrevemos a função de seleção da segunda metade da tecla:
def get_second_half(email): from collections import deque from random import randint def get_koeff(): k1 = sum([ord(c) for c in email]) k2 = (len(email) - 1) << 8 return k1, k2 def get_pairs(k1, k2): pairs = [] for a in range(0xFFFF + 1): pair = (a, (a ^ k1) ^ k2) pairs.append(pair) pairs = deque(pairs) pairs.rotate(randint(0, 0xFFFF)) return list(pairs) k1, k2 = get_koeff() pairs = get_pairs(k1, k2) for pair in pairs: key_4s_0 = decode_hash_4s(pair[0]) key_4s_1 = decode_hash_4s(pair[1]) hash_2b_0 = get_hash_2b(key_4s_0) hash_2b_1 = get_hash_2b(key_4s_1) if hash_2b_0 == pair[0] and hash_2b_1 == pair[1]: return key_4s_0, key_4s_1
Keygen
O correio deve ser uma cápsula.
def keygen(email): first_half = get_first_half() second_half = get_second_half(email) return "".join(first_half) + "".join(second_half) >>> email = "M.GAYANOV@GMAIL.COM" >>> print(keygen(email)) 2A4FD493BA32AD75
Obrigado pela atenção! Todo o código está disponível
aqui .