No “Espelho Negro”, houve uma série (S2E1), na qual eles criaram robôs semelhantes a pessoas mortas, usando o histórico de correspondência nas redes sociais para treinamento. Quero contar como tentei fazer algo semelhante e o que aconteceu. Não haverá teoria, apenas prática.

A idéia era simples - levar a história de seus bate-papos do Telegram e, com base em eles, treinar a rede seq2seq, capaz de prever sua conclusão no início do diálogo. Essa rede pode operar em três modos:
- Preveja a conclusão da frase do usuário com base no histórico de conversas
- Trabalhar no modo chatbot
- Sintetizar logs de conversação inteiros
Foi o que eu consegui
Bot oferece conclusão de frase
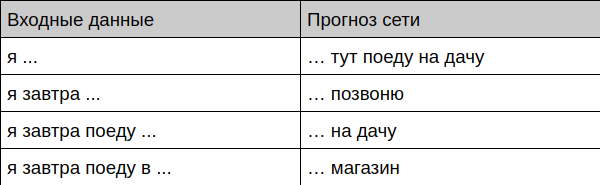
Bot oferece conclusão do diálogo
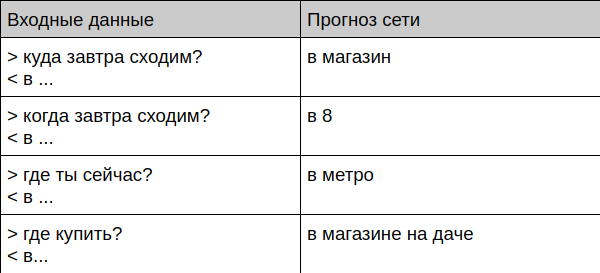
Bot se comunica com uma pessoa viva
User: Bot: User: ? Bot: User: ? Bot: User: ? Bot: User: ? Bot: User: ? Bot:
A seguir, mostrarei como preparar os dados e treinar você mesmo esse robô.
Como se ensinar
Preparação de dados
Primeiro de tudo, você precisa ter muitas conversas em algum lugar. Levei toda a minha correspondência no Telegram, pois o cliente para a área de trabalho permite baixar o arquivo completo no formato JSON. Depois joguei fora todas as mensagens que contêm aspas, links e arquivos, e transferi os textos restantes para minúsculas e joguei fora todos os caracteres raros, deixando apenas um conjunto simples de letras, números e sinais de pontuação - é mais fácil aprender a rede.
Então eu trouxe as conversas para este formulário:
=== > < > < ! === > ? <
Aqui, as mensagens que começam com o símbolo ">" são uma pergunta para mim, o símbolo "<" marca minha resposta de acordo e a linha "===" serve para separar os diálogos entre si. O fato de que um diálogo terminou e o outro começou, eu determinei pelo tempo (se mais de 15 minutos se passaram entre as mensagens, então achamos que essa é uma nova conversa. Você pode ver o script para converter a história no github .
Como uso ativamente os telegramas há muito tempo, houve muitas mensagens no final - havia 443 mil linhas no arquivo final.
Seleção de modelo
Prometi que não haveria teoria hoje, então tentarei explicar o mais breve possível em meus dedos.
Eu escolhi o seq2seq clássico com base no GRU. Esse modelo de entrada recebe o texto letra por letra e também gera uma letra por vez. O processo de aprendizado é baseado no fato de ensinarmos a rede a prever a última letra do texto, por exemplo, damos "liderança" à entrada e aguardamos a saída do "rebite" .
Para gerar textos longos, é usado um truque simples - o resultado da previsão anterior é enviado de volta à rede e assim por diante até que o comprimento necessário do texto seja gerado.
Os módulos GRU podem ser muito, muito simplificados como um "perceptron astuto com memória e atenção", mais detalhes sobre eles podem ser encontrados, por exemplo, aqui .
O modelo foi baseado no exemplo bem conhecido da tarefa de gerar textos de Shakespeare.
Treinamento
Quem já se deparou com redes neurais provavelmente sabe que aprendê-las na CPU é muito chato. Felizmente, o Google resgata o serviço Colab - nele, você pode executar seu código no notebook jupyter gratuitamente usando uma CPU, GPU e até TPU . No meu caso, o treinamento na placa de vídeo cabe em 30 minutos, embora os resultados sãos estejam disponíveis após 10. O principal é lembrar de alternar o tipo de hardware (no menu Tempo de execução -> Alterar tipo de tempo de execução).
Teste
Após o treinamento, você pode prosseguir com a verificação do modelo - escrevi vários exemplos que permitem acessar o modelo em diferentes modos - da geração de texto ao chat ao vivo. Todos eles estão no github .
O método para gerar texto possui um parâmetro de temperatura - quanto mais alto, mais diverso o texto (e sem sentido) produzirá um bot. Este parâmetro faz sentido para configurar mãos para uma tarefa específica.
Uso adicional
Por que essa rede pode ser usada? O mais óbvio é desenvolver um bot (ou teclado inteligente) que possa oferecer ao usuário respostas prontas antes mesmo de ele ser gravado. Um recurso semelhante existe há muito tempo no Gmail e na maioria dos teclados, mas não leva em consideração o contexto da conversa e a maneira como um usuário em particular conduz a correspondência. Por exemplo, o G-Keyboard oferece-me opções completamente sem sentido, por exemplo, "Eu vou com ... respeito" no lugar em que eu gostaria de ter a opção "Eu vou da dacha", que eu definitivamente usei muitas vezes.
O bot de bate-papo tem futuro? Em sua forma pura, ele definitivamente não está lá, possui muitos dados pessoais, ninguém sabe em que momento ele dará ao interlocutor o número do seu cartão de crédito que você jogou para um amigo. Além disso, esse bot não está totalmente ajustado, é muito difícil executá-lo para executar tarefas específicas ou responder corretamente a uma pergunta específica. Em vez disso, esse chatbot poderia funcionar em conjunto com outros tipos de bots, fornecendo um diálogo mais conectado "sobre nada" - ele lida bem com isso. (E, no entanto, um especialista externo na pessoa de sua esposa disse que o estilo de comunicação do bot é muito semelhante a mim. E os tópicos com os quais ele se importa são claramente os mesmos - bugs, correções, confirmações e outras alegrias e tristezas do desenvolvedor constantemente aparecem nos textos).
O que mais o aconselha a tentar se esse tópico é interessante para você?
- Transferir aprendizado (para treinar em um grande número de diálogos de outras pessoas e depois terminar por conta própria)
- Alterar modelo - aumente, altere o tipo (por exemplo, no LSTM).
- Tente trabalhar com TPU. Na sua forma pura, este modelo não funcionará, mas pode ser adaptado. A aceleração teórica da aprendizagem deve ser dez vezes.
- Porta para uma plataforma móvel, por exemplo, usando o Tensorflow mobile.
Link do PS para o github