Outro usuário deseja gravar um novo dado no disco rígido, mas ele não tem espaço livre suficiente para isso. Também não quero excluir nada, pois "tudo é muito importante e necessário". E o que devemos fazer com isso?
Ele não tem esse problema. Terabytes de informações repousam em nossos discos rígidos, e esse valor não tende a diminuir. Mas como é único? No final, afinal, todos os arquivos são apenas conjuntos de bits de um determinado comprimento e, muito provavelmente, o novo não é muito diferente daquele que já está armazenado.
É claro que procurar por informações já armazenadas no disco rígido é uma tarefa, se não uma falha, pelo menos não é eficaz. Por outro lado, porque se a diferença é pequena, você pode ajustar um pouco ...

TL; DR - a segunda tentativa de falar sobre um método estranho de otimizar dados usando arquivos JPEG, agora de uma forma mais compreensível.
Sobre bits e diferença
Se pegarmos dois dados completamente aleatórios, então, em média, metade dos bits contidos coincide neles. De fato, entre os layouts possíveis para cada par ('00, 01, 10, 11 '), exatamente a metade tem os mesmos valores, tudo aqui é simples.
Mas é claro que, se pegarmos apenas dois arquivos e colocarmos um sob o segundo, perderemos um deles. Se mantivermos as alterações, simplesmente reinventaremos a codificação delta , que mesmo sem nós existe perfeitamente, embora geralmente não seja usada para o mesmo objetivo. Você pode tentar incorporar uma sequência menor a uma maior, mas, mesmo assim, corremos o risco de perder segmentos de dados críticos quando usados com imprudência em tudo.
Entre o que e o que então pode ser eliminada a diferença? Bem, isto é, um novo arquivo gravado pelo usuário é apenas uma sequência de bits com a qual não podemos fazer nada por si só. Então você só precisa encontrar esses bits no disco rígido para que possam ser alterados sem precisar armazenar a diferença, para que você possa sobreviver à perda deles sem consequências sérias. Sim, e faz sentido alterar não apenas o arquivo em si no FS, mas algumas informações menos sensíveis dentro dele. Mas qual e como?
Métodos de ajuste
Arquivos compactados com perdas vêm para o resgate. Todos esses jpeg, mp3 e outros, embora sejam compactação com perdas, contêm vários bits disponíveis para alterações seguras. Você pode usar técnicas avançadas, modificando discretamente seus componentes em diferentes áreas da codificação. Espere um momento. Técnicas avançadas ... modificação discreta ... alguns bits para outros ... sim, é quase esteganografia !
De fato, incorporar uma informação em outra se assemelha a seus métodos, não importa o quê. Também impressiona a invisibilidade das mudanças feitas nos sentidos humanos. É aí que os caminhos divergem - é um segredo: nossa tarefa é adicionar informações adicionais ao disco rígido do usuário, isso só o prejudicará. Esqueça mais.
Portanto, embora possamos usá-los, precisamos fazer algumas modificações. E então mostrarei e mostrarei no exemplo de um dos métodos existentes e no formato de arquivo comum.
Sobre os chacais
Se você comprimir, o mais compressível do mundo. É claro que estamos falando de arquivos JPEG. Não apenas existem inúmeras ferramentas e métodos existentes para incorporar dados, como também é o formato gráfico mais popular neste planeta.

No entanto, para não se envolver na criação de cães, você precisa limitar seu campo de atividade em arquivos desse formato. Ninguém gosta de quadrados monocromáticos que surgem devido à compactação excessiva; portanto, você precisa se limitar a trabalhar com um arquivo já compactado, evitando a transcodificação . Mais especificamente, com coeficientes inteiros que permanecem após as operações responsáveis pela perda de dados - DCT e quantização, que são perfeitamente exibidos no esquema de codificação (graças ao wiki da Biblioteca Nacional de Bauman):

Existem muitos métodos possíveis de otimização para arquivos jpeg. Existe otimização sem perdas (jpegtran), existe uma otimização sem perdas , que de fato ainda contribui, mas elas não nos incomodam. De fato, se um usuário está pronto para incorporar uma informação em outra, a fim de aumentar o espaço livre em disco, ele otimiza suas imagens por um longo tempo ou não deseja fazer isso por medo de perda de qualidade.
F5
Sob tais condições, uma família inteira de algoritmos é adequada, o que pode ser encontrado nesta boa apresentação . O mais avançado deles é o algoritmo F5 , de autoria de Andreas Westfeld, que trabalha com os coeficientes do componente de brilho, já que o olho humano é o menos sensível a suas alterações. Além disso, ele usa uma técnica de incorporação baseada na codificação matricial, que permite fazer menos alterações ao incorporar a mesma quantidade de informações, maior o tamanho do contêiner usado.
As mudanças em si se resumem a uma diminuição no valor absoluto dos coeficientes por unidade sob certas condições (ou seja, nem sempre), o que torna possível usar o F5 para otimizar o armazenamento de dados no disco rígido. O fato é que o coeficiente após essa alteração provavelmente ocupará um número menor de bits após a codificação de Huffman devido à distribuição estatística dos valores em JPEG, e novos zeros se beneficiarão da codificação usando RLE.
As modificações necessárias se resumem a eliminar a parte responsável pelo sigilo (permutação de senha), que permite economizar recursos e tempo de execução e adicionar um mecanismo para trabalhar com muitos arquivos em vez de um de cada vez. Mais detalhadamente, é improvável que o processo de mudar o leitor seja interessante, por isso passamos à descrição da implementação.
Alta tecnologia
Para demonstrar o trabalho dessa abordagem, implementei o método em C puro e realizei várias otimizações em termos de velocidade e memória (você não pode imaginar o quanto essas imagens pesam sem compactação antes mesmo do DCT). O desempenho de plataforma cruzada é alcançado usando uma combinação das bibliotecas libjpeg , pcre e tinydir , pelas quais agradeço. Tudo isso será feito pelo make, para que os usuários do Windows desejem instalar algum Cygwin para avaliação ou lidar com o Visual Studio e as bibliotecas por conta própria.
A implementação está disponível na forma de um utilitário de console e uma biblioteca. Mais informações sobre o uso deste último podem ser encontradas no leia-me no repositório no github, um link ao qual anexarei no final do post.
Como usar?
Com cautela. As imagens usadas para o empacotamento são selecionadas pela pesquisa de expressão regular no diretório raiz especificado. No final do arquivo, você pode mover, renomear e copiar conforme desejado, alterar o arquivo e os sistemas operacionais, etc. No entanto, você deve ser extremamente cuidadoso e não alterar o conteúdo imediato. A perda do valor de um bit pode levar à incapacidade de restaurar informações.
Após a conclusão do trabalho, o utilitário deixa um arquivo especial contendo todas as informações necessárias para descompactar, incluindo dados sobre as imagens utilizadas. Por si só, pesa cerca de dois kilobytes e não tem nenhum efeito significativo no espaço em disco ocupado.
Você pode analisar a capacidade possível usando o sinalizador '-a': './f5ar -a [pasta de pesquisa] [Expressão regular compatível com Perl]'. A compactação é feita com o comando './f5ar -p [pasta de pesquisa] [expressão regular compatível com Perl] [arquivo compactado] [nome do arquivo]' e descompactada com './f5ar -u [arquivo morto] [nome do arquivo restaurado]' .
Demonstração de trabalho
Para mostrar a eficácia do método, baixei uma coleção de 225 fotos absolutamente gratuitas de cães do serviço Unsplash e desenterrei um pdf grande por 45 metros nos documentos do segundo volume da Arte de Programação Knut.
A sequência é bem simples:
$ du -sh knuth.pdf dogs/ 44M knuth.pdf 633M dogs/ $ ./f5ar -p dogs/ .*jpg knuth.pdf dogs.f5ar Reading compressing file... ok Initializing the archive... ok Analysing library capacity... done in 17.0s Detected somewhat guaranteed capacity of 48439359 bytes Detected possible capacity of upto 102618787 bytes Compressing... done in 39.4s Saving the archive... ok $ ./f5ar -u dogs/dogs.f5ar knuth_unpacked.pdf Initializing the archive... ok Reading the archive file... ok Filling the archive with files... done in 1.4s Decompressing... done in 21.0s Writing extracted data... ok $ sha1sum knuth.pdf knuth_unpacked.pdf 5bd1f496d2e45e382f33959eae5ab15da12cd666 knuth.pdf 5bd1f496d2e45e382f33959eae5ab15da12cd666 knuth_unpacked.pdf $ du -sh dogs/ 551M dogs/
Capturas de tela para fãs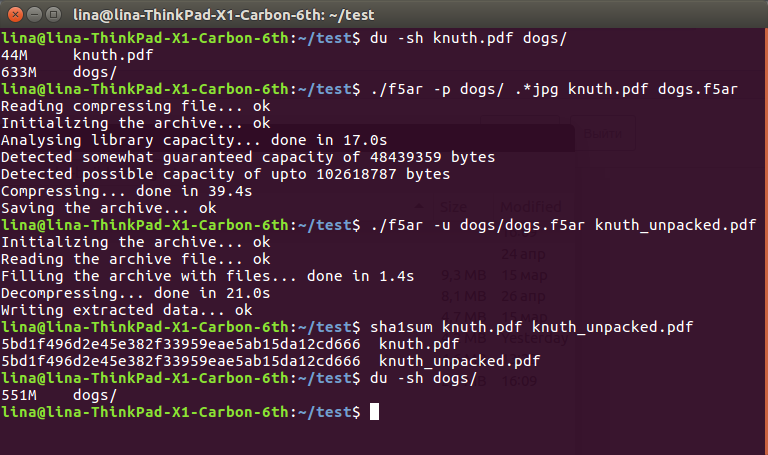
O arquivo descompactado ainda é possível e deve ser lido:

Como você pode ver, dos 633 + 36 == 669 megabytes de dados originais no disco rígido, chegamos a 551 mais agradáveis. Essa diferença radical é explicada pela diminuição dos valores do coeficiente, que afetam a compressão subsequente sem perda: uma diminuição de apenas um por um pode ser calma " corte "alguns bytes do arquivo resultante. No entanto, isso ainda é perda de dados, embora extremamente pequena, que você precisa suportar.
Felizmente, eles não são completamente visíveis aos olhos. Sob o spoiler (porque o habrastorage não pode lidar com arquivos grandes), o leitor pode avaliar a diferença tanto pelos olhos quanto por sua intensidade, obtida subtraindo os valores do componente alterado do original: o original , com as informações contidas , a diferença (quanto mais escura a cor, menor a diferença no bloco )
Em vez de uma conclusão
Analisar todas essas dificuldades, comprar um disco rígido ou carregar tudo na nuvem pode parecer uma solução muito mais simples para o problema. Mas, apesar de vivermos em um momento tão maravilhoso, não há garantias de que amanhã ainda será possível ficar on-line e enviar para algum lugar todos os seus dados extras. Ou vá até a loja e compre outro disco rígido de mil terabytes. Mas você sempre pode usar casas já deitadas.
-> github