
Antecedentes
Aconteceu que o servidor foi atacado por um vírus de ransomware, que, por um "golpe", separou parcialmente os arquivos .ibd (arquivos de dados brutos das tabelas innodb), mas criptografou completamente os arquivos .fpm (arquivos de estrutura). Ao mesmo tempo, o .idb pode ser dividido em:
- sujeito a recuperação através de ferramentas e guias padrão. Para tais casos, há um ótimo artigo ;
- tabelas parcialmente criptografadas. Principalmente, são tabelas grandes, nas quais (como eu entendi), os invasores não tinham RAM suficiente para criptografia completa;
- Bem, tabelas totalmente criptografadas que não podem ser recuperadas.
Foi possível determinar a qual opção as tabelas pertencem abrindo em qualquer editor de texto sob a codificação desejada (no meu caso, é UTF8) e simplesmente observando o arquivo quanto à presença de campos de texto, por exemplo:
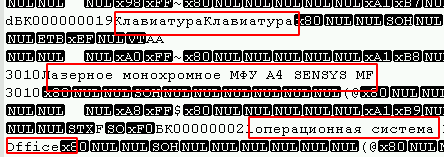
Além disso, no início do arquivo, é possível observar um grande número de 0 bytes e os vírus que usam o algoritmo de criptografia de bloco (o mais comum) geralmente os afetam.

No meu caso, os invasores no final de cada arquivo criptografado deixaram uma sequência de 4 bytes (1, 0, 0, 0), o que simplificou a tarefa. Um script foi suficiente para procurar arquivos não infectados:
def opened(path): files = os.listdir(path) for f in files: if os.path.isfile(path + f): yield path + f for full_path in opened("C:\\some\\path"): file = open(full_path, "rb") last_string = "" for line in file: last_string = line file.close() if (last_string[len(last_string) -4:len(last_string)]) != (1, 0, 0, 0): print(full_path)
Assim, acabou por encontrar arquivos pertencentes ao primeiro tipo. O segundo implica um manual longo, mas já encontrado foi suficiente. Tudo ficaria bem, mas é necessário conhecer a estrutura absolutamente exata e (é claro) que houve um caso em que tive que trabalhar com uma tabela que mudava frequentemente. Ninguém lembrou se o tipo de campo estava mudando ou se uma nova coluna estava sendo adicionada.
Infelizmente, Debri City não pôde ajudar neste caso, portanto, este artigo está sendo escrito.
Vá direto ao ponto
Há uma estrutura de tabela de 3 meses atrás que não coincide com a atual (talvez um campo, mas possivelmente mais). Estrutura da tabela:
CREATE TABLE `table_1` ( `id` INT (11), `date` DATETIME , `description` TEXT , `id_point` INT (11), `id_user` INT (11), `date_start` DATETIME , `date_finish` DATETIME , `photo` INT (1), `id_client` INT (11), `status` INT (1), `lead__time` TIME , `sendstatus` TINYINT (4) );
neste caso, você precisa extrair:
id_point INT (11);id_user INT (11);date_start DATETIME;date_finish DATETIME.
Para recuperação, é usada uma análise de bytes do arquivo .ibd, seguida por sua tradução de forma mais legível. Como para encontrar o que é necessário, basta analisarmos tipos de dados como int e datatime, apenas eles serão descritos no artigo, mas às vezes também se referirão a outros tipos de dados, o que pode ajudar em outros incidentes semelhantes.
Problema 1 : os campos com os tipos DATETIME e TEXT tinham um valor NULL e são simplesmente ignorados no arquivo, por isso, não foi possível determinar a estrutura de recuperação no meu caso. Nas novas colunas, o valor padrão era nulo e algumas das transações poderiam ser perdidas devido à configuração innodb_flush_log_at_trx_commit = 0, portanto, seria necessário um tempo adicional para determinar a estrutura.
Problema 2 : deve-se notar que as linhas excluídas por DELETE estarão todas exatamente no arquivo ibd, mas com ALTER TABLE sua estrutura não será atualizada. Como resultado, a estrutura de dados pode variar desde o início do arquivo até o final. Se você costuma usar OPTIMIZE TABLE, é improvável que encontre um problema semelhante.
Observe que a versão do DBMS afeta a maneira como os dados são armazenados e este exemplo pode não funcionar para outras versões principais. No meu caso, a versão do Windows mariadb 10.1.24 foi usada. Além disso, embora no mariadb você trabalhe com tabelas do InnoDB, na verdade elas são XtraDB , o que exclui a aplicabilidade do método com o InnoDB mysql.
Análise de arquivo
Em python, o tipo de dados bytes () exibe dados em Unicode, em vez do conjunto usual de números. Embora você possa considerar o arquivo neste formulário, mas por conveniência, pode converter bytes em um formato numérico, traduzindo a matriz de bytes em uma matriz regular (lista (matriz_do_exemplo)). De qualquer forma, ambos os métodos são úteis para análise.
Depois de analisar vários arquivos ibd, você pode encontrar o seguinte:
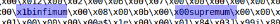
Além disso, se você dividir o arquivo por essas palavras-chave, obterá principalmente blocos de dados simples. Usaremos o mínimo como um divisor.
table = table.split("infimum".encode())
Uma observação interessante, para tabelas com uma pequena quantidade de dados, entre o mínimo e o supremo, existe um ponteiro para o número de linhas no bloco.
 - mesa de teste com 1ª fila
- mesa de teste com 1ª fila
 - tabela de teste com 2 linhas
- tabela de teste com 2 linhas
A tabela de matriz de linhas [0] pode ser ignorada. Tendo analisado, ainda não consegui encontrar os dados brutos das tabelas. Muito provavelmente, esse bloco é usado para armazenar índices e chaves.
Começando com a tabela [1] e convertendo-a em uma matriz numérica, você já pode notar alguns padrões, a saber:

Esses são valores int armazenados em uma sequência. O primeiro byte indica se o número é positivo ou negativo. No meu caso, todos os números são positivos. Dos 3 bytes restantes, você pode determinar o número usando a seguinte função. Script:
def find_int(val: str):
Por exemplo, 128, 0, 0, 1 = 1 ou 128, 0, 75, 108 = 19308 .
A tabela tinha uma chave primária com incremento automático e aqui você também pode encontrá-la

Comparando os dados das tabelas de teste, foi revelado que o objeto DATETIME consiste em 5 bytes, começando com 153 (provavelmente indicando intervalos anuais). Como o intervalo DATTIME é '1000-01-01' a '9999-12-31', acho que o número de bytes pode variar, mas no meu caso, os dados caem no período de 2016 a 2019, portanto, assumimos que 5 bytes são suficientes .
Para determinar o tempo sem segundos, as seguintes funções foram gravadas. Script:
day_ = lambda x: x % 64 // 2
Durante um ano e um mês, não foi possível escrever uma função de trabalho saudável, então tive que codificar. Script:
ym_list = {'2016, 1': '153, 152, 64', '2016, 2': '153, 152, 128', '2016, 3': '153, 152, 192', '2016, 4': '153, 153, 0', '2016, 5': '153, 153, 64', '2016, 6': '153, 153, 128', '2016, 7': '153, 153, 192', '2016, 8': '153, 154, 0', '2016, 9': '153, 154, 64', '2016, 10': '153, 154, 128', '2016, 11': '153, 154, 192', '2016, 12': '153, 155, 0', '2017, 1': '153, 155, 128', '2017, 2': '153, 155, 192', '2017, 3': '153, 156, 0', '2017, 4': '153, 156, 64', '2017, 5': '153, 156, 128', '2017, 6': '153, 156, 192', '2017, 7': '153, 157, 0', '2017, 8': '153, 157, 64', '2017, 9': '153, 157, 128', '2017, 10': '153, 157, 192', '2017, 11': '153, 158, 0', '2017, 12': '153, 158, 64', '2018, 1': '153, 158, 192', '2018, 2': '153, 159, 0', '2018, 3': '153, 159, 64', '2018, 4': '153, 159, 128', '2018, 5': '153, 159, 192', '2018, 6': '153, 160, 0', '2018, 7': '153, 160, 64', '2018, 8': '153, 160, 128', '2018, 9': '153, 160, 192', '2018, 10': '153, 161, 0', '2018, 11': '153, 161, 64', '2018, 12': '153, 161, 128', '2019, 1': '153, 162, 0', '2019, 2': '153, 162, 64', '2019, 3': '153, 162, 128', '2019, 4': '153, 162, 192', '2019, 5': '153, 163, 0', '2019, 6': '153, 163, 64', '2019, 7': '153, 163, 128', '2019, 8': '153, 163, 192', '2019, 9': '153, 164, 0', '2019, 10': '153, 164, 64', '2019, 11': '153, 164, 128', '2019, 12': '153, 164, 192', '2020, 1': '153, 165, 64', '2020, 2': '153, 165, 128', '2020, 3': '153, 165, 192','2020, 4': '153, 166, 0', '2020, 5': '153, 166, 64', '2020, 6': '153, 1, 128', '2020, 7': '153, 166, 192', '2020, 8': '153, 167, 0', '2020, 9': '153, 167, 64','2020, 10': '153, 167, 128', '2020, 11': '153, 167, 192', '2020, 12': '153, 168, 0'} def year_month(x1, x2):
Estou certo de que, se você gastar o número de vezes, esse mal-entendido poderá ser corrigido.
Em seguida, a função retorna um objeto datetime de uma string. Script:
def find_data_time(val:str): val = [int(v) for v in val.split(", ")] day = day_(val[2]) hour = hour_(val[2], val[3]) minutes = min_(val[3], val[4]) year, month = year_month(val[1], val[2]) return datetime(year, month, day, hour, minutes)
Foi possível detectar valores repetidos frequentemente de int, int, datetime, datetime 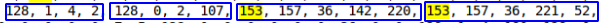 Parece que é disso que você precisa. Além disso, essa sequência não é repetida duas vezes por linha.
Parece que é disso que você precisa. Além disso, essa sequência não é repetida duas vezes por linha.
Usando uma expressão regular, encontramos os dados necessários:
fined = re.findall(r'128, \d*, \d*, \d*, 128, \d*, \d*, \d*, 153, 1[6,5,4,3]\d, \d*, \d*, \d*, 153, 1[6,5,4,3]\d, \d*, \d*, \d*', int_array)
Observe que, ao procurar esta expressão, não será possível determinar valores NULL nos campos obrigatórios, mas, no meu caso, isso não é crítico. Depois de percorrermos o encontrado. Script:
result = [] for val in fined: pre_result = [] bd_int = re.findall(r"128, \d*, \d*, \d*", val) bd_date= re.findall(r"(153, 1[6,5,4,3]\d, \d*, \d*, \d*)", val) for it in bd_int: pre_result.append(find_int(bd_int[it])) for bd in bd_date: pre_result.append(find_data_time(bd)) result.append(pre_result)
Na verdade, tudo, dados da matriz de resultados, são os dados que precisamos. ### PS. ###
Entendo que esse método não é adequado para todos, mas o principal objetivo do artigo é agir rapidamente, em vez de resolver todos os seus problemas. Eu acho que a solução mais correta seria começar a estudar o código fonte do próprio mariadb , mas devido ao tempo limitado, o método atual parecia o mais rápido.
Em alguns casos, após analisar o arquivo, você pode determinar a estrutura aproximada e restaurar um dos métodos padrão nos links acima. Será muito mais correto e causará menos problemas.