Olá, queridos leitores de Habr. Meu nome é Rustem e sou o principal desenvolvedor da empresa de TI do Cazaquistão DAR. Neste artigo, mostrarei o que você precisa saber antes de passar para os modelos de Event Sourcing e CQRS usando o kit de ferramentas Akka.
Por volta de 2015, começamos a projetar nosso ecossistema. Após a análise e com base na experiência com Scala e Akka, decidimos parar no kit de ferramentas Akka. Tivemos implementações bem-sucedidas de modelos de Sourcing de Eventos com CQRS e não. A acumulação de conhecimentos nesta área, que quero compartilhar com os leitores. Veremos como a Akka implementa esses padrões, bem como quais ferramentas estão disponíveis e falaremos sobre as armadilhas da Akka. Espero que, depois de ler este artigo, você tenha mais compreensão dos riscos de mudar para o kit de ferramentas Akka.
Sobre assuntos do CQRS e Event Sourcing, muitos artigos sobre Habré e outros recursos foram escritos. Este artigo é destinado a leitores que já entendem o que são CQRS e Event Sourcing. No artigo, quero me concentrar na Akka.
Design orientado a domínio
Muito material foi escrito sobre DDD (Domain-Driven Design). Existem oponentes e apoiadores dessa abordagem. Quero acrescentar por mim mesmo que, se você decidir mudar para Event Sourcing e CQRS, não será supérfluo estudar o DDD. Além disso, a filosofia DDD é sentida em todas as ferramentas Akka.
De fato, o Event Sourcing e o CQRS são apenas uma pequena parte do cenário geral chamado Design Orientado a Domínio. Ao projetar e desenvolver, você pode ter muitas perguntas sobre como implementar adequadamente esses modelos e integrar-se ao ecossistema, e saber que o DDD facilitará sua vida.
Neste artigo, o termo entidade (entidade por DDD) significará um ator de persistência que possui um identificador exclusivo.
Por que Scala?
Muitas vezes nos perguntam por que Scala, e não Java. Uma razão é Akka. A estrutura em si, escrita na linguagem Scala, com suporte para a linguagem Java. Aqui devo dizer que também há uma implementação no .NET , mas esse é outro tópico. Para não causar discussão, não escreverei por que o Scala é melhor ou pior que o Java. Vou apenas citar alguns exemplos que, na minha opinião, o Scala tem uma vantagem sobre o Java ao trabalhar com o Akka:
- Objetos imutáveis. Em Java, você precisa escrever objetos imutáveis. Acredite, não é fácil nem muito conveniente escrever constantemente os parâmetros finais. Na
case class Scala já case class imutável com a função de copy integrada - Estilo de codificação. Quando implementado em Java, você ainda escreverá no estilo Scala, ou seja, funcionalmente.
Aqui está um exemplo de implementação do ator no Scala e Java:
Scala:
object DemoActor { def props(magicNumber: Int): Props = Props(new DemoActor(magicNumber)) } class DemoActor(magicNumber: Int) extends Actor { def receive = { case x: Int => sender() ! (x + magicNumber) } } class SomeOtherActor extends Actor { context.actorOf(DemoActor.props(42), "demo")
Java:
static class DemoActor extends AbstractActor { static Props props(Integer magicNumber) { return Props.create(DemoActor.class, () -> new DemoActor(magicNumber)); } private final Integer magicNumber; public DemoActor(Integer magicNumber) { this.magicNumber = magicNumber; } @Override public Receive createReceive() { return receiveBuilder() .match( Integer.class, i -> { getSender().tell(i + magicNumber, getSelf()); }) .build(); } } static class SomeOtherActor extends AbstractActor { ActorRef demoActor = getContext().actorOf(DemoActor.props(42), "demo");
(Exemplo retirado daqui )
Preste atenção na implementação do método createReceive() usando o exemplo da linguagem Java. Internamente, através da fábrica do ReceiveBuilder , a correspondência de padrões é implementada. receiveBuilder() é um método da Akka para suportar expressões lambda, ou seja, correspondência de padrões em Java. Em Scala, isso é implementado nativamente. Concordo, o código no Scala é mais curto e fácil de ler.
- Documentação e exemplos. Apesar do fato de que na documentação oficial existem exemplos em Java, na Internet, quase todos os exemplos estão em Scala. Além disso, será mais fácil navegar nas fontes da biblioteca Akka.
Em termos de desempenho, não haverá diferença entre Scala e Java, pois tudo gira na JVM.
Armazenamento
Antes de implementar o Event Sourcing com Akka Persistence, recomendo que você pré-selecione um banco de dados para armazenamento permanente de dados. A escolha da base depende dos requisitos do sistema, de seus desejos e preferências. Os dados podem ser armazenados no NoSQL e RDBMS e em um sistema de arquivos, por exemplo, LevelDB do Google .
É importante observar que o Akka Persistence não é responsável por escrever e ler dados do banco de dados, mas por meio de um plug-in que deve implementar a API do Akka Persistence.
Depois de escolher uma ferramenta para armazenar dados, você precisa selecionar um plug - in da lista ou gravá-lo. A segunda opção, eu não recomendo por que reinventar a roda.
Para armazenamento permanente de dados, decidimos ficar no Cassandra. O fato é que precisávamos de uma base confiável, rápida e distribuída. Além disso, o Typesafe acompanha o plug - in , que implementa completamente a API do Akka Persistence . É constantemente atualizado e, em comparação com outros, o plug-in Cassandra escreveu uma documentação mais completa.
Vale ressaltar que o plugin também possui vários problemas. Por exemplo, ainda não existe uma versão estável (no momento da redação deste documento, a versão mais recente é 0,97). Para nós, o maior incômodo que encontramos ao usar este plug-in foi a perda de eventos ao ler a Consulta Persistente para algumas entidades. Para uma imagem completa, abaixo está o gráfico do CQRS:
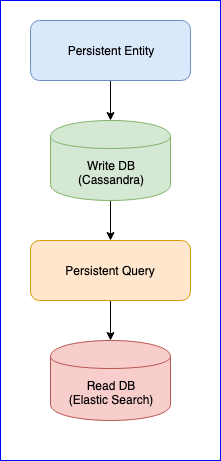
A entidade persistente distribui os eventos da entidade em tags usando o algoritmo de hash consistente (por exemplo, 10 shards):
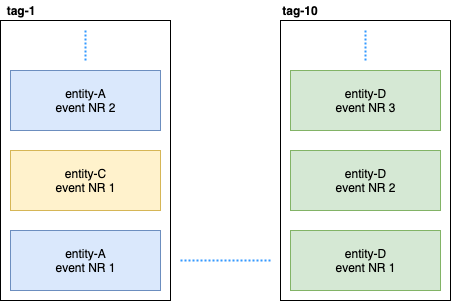
Em seguida, a consulta persistente assina essas tags e inicia um fluxo que adiciona dados à pesquisa elástica. Como o Cassandra está em um cluster, os eventos serão espalhados pelos nós. Alguns nós podem ceder e responderão mais lentamente que outros. Não há garantia de que você receberá eventos em ordem estrita. Para resolver esse problema, o plug-in é implementado para que, se ele receber um evento não ordenado, por exemplo, o entity-A event NR 2 , aguarde um certo tempo pelo evento inicial e, se não o receber, simplesmente ignorará todos os eventos dessa entidade. Mesmo sobre isso, houve discussões sobre Gitter. Se alguém estiver interessado, você pode ler a correspondência entre o @kotdv e os desenvolvedores do plugin: Gitter
Como esse mal-entendido pode ser resolvido:
- Você precisa atualizar o plug-in para a versão mais recente. Nas versões recentes, os desenvolvedores do Typesafe resolveram muitos problemas relacionados à consistência eventual. Mas ainda estamos esperando por uma versão estável
- Configurações mais precisas foram adicionadas para o componente responsável por receber eventos. Você pode tentar aumentar o tempo limite de eventos não ordenados para uma operação mais confiável do plug-in: c
assandra-query-journal.events-by-tag.eventual-consistency.delay=10s - Configure o Cassandra conforme recomendado pelo DataStax. Coloque o coletor de lixo G1 e aloque o máximo de memória possível para o Cassandra .
No final, resolvemos o problema com os eventos ausentes, mas agora há um atraso de dados estável no lado da Consulta de Persistência (de cinco a dez segundos). Foi decidido deixar a abordagem para os dados usados para análise e, onde a velocidade é importante, publicamos eventos manualmente no barramento. O principal é escolher o mecanismo apropriado para processar ou publicar dados: pelo menos uma vez ou no máximo uma vez. Uma boa descrição da Akka pode ser encontrada aqui . Era importante para nós manter a consistência dos dados e, portanto, após gravar com sucesso os dados no banco de dados, introduzimos um estado de transição que controla a publicação bem-sucedida de dados no barramento. A seguir, é apresentado um código de exemplo:
object SomeEntity { sealed trait Event { def uuid: String } case class DidSomething(uuid: String) extends Event /** * , . */ case class LastEventPublished(uuid: String) extends Event /** * , . * @param unpublishedEvents – , . */ case class State(unpublishedEvents: Seq[Event]) object State { def updated(event: Event): State = event match { case evt: DidSomething => copy( unpublishedEvents = unpublishedEvents :+ evt ) case evt: LastEventPublished => copy( unpublishedEvents = unpublishedEvents.filter(_.uuid != evt.uuid) ) } } } class SomeEntity extends PersistentActor { … persist(newEvent) { evt => updateState(evt) publishToEventBus(evt) } … }
Se, por algum motivo, não foi possível publicar o evento, no próximo início de SomeEntity , ele saberá que o evento DidSomething não chegou ao barramento e tentará republicar os dados novamente.
Serializer
A serialização é um ponto igualmente importante no uso do Akka. Ele tem um módulo interno - Akka Serialization . Este módulo é usado para serializar mensagens ao trocá-las entre atores e ao armazená-las através da API Persistence. Por padrão, o Java serializer é usado, mas é recomendável usar outro. O problema é que o Java Serializer é lento e ocupa muito espaço. Existem duas soluções populares - estas são JSON e Protobuf. O JSON, embora lento, é mais fácil de implementar e manter. Se você precisar minimizar o custo de serialização e armazenamento de dados, poderá parar no Protobuf, mas o processo de desenvolvimento será mais lento. Além do modelo de domínio, você precisará escrever outro modelo de dados. Não se esqueça da versão dos dados. Esteja preparado para escrever constantemente o mapeamento entre o Modelo de Domínio e o Modelo de Dados.
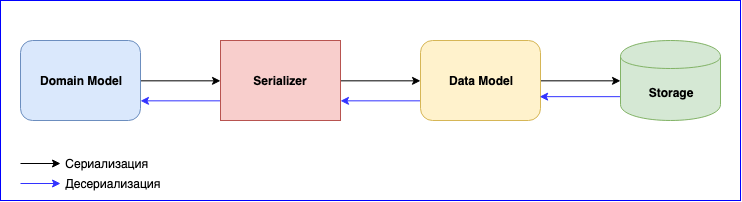
Adicionado um novo evento - mapeamento de gravação. Mudou a estrutura de dados - escreva uma nova versão do Modelo de Dados e altere a função de mapeamento. Não se esqueça dos testes para serializadores. Em geral, haverá muito trabalho, mas no final você obterá componentes fracamente acoplados.
Conclusões
- Estude cuidadosamente e escolha uma base e um plug-in adequados para si. Eu recomendo escolher um plugin que seja bem mantido e não pare de se desenvolver. A área é relativamente nova, ainda há um monte de falhas que ainda precisam ser resolvidas
- Se você selecionar o armazenamento distribuído, terá que resolver o problema com um atraso de até 10 segundos, ou suportá-lo
- A complexidade da serialização. Você pode sacrificar a velocidade e parar no JSON, ou escolher Protobuf e escrever muitos adaptadores e suportá-los.
- Há vantagens nesse modelo: são componentes fracamente acoplados e equipes de desenvolvimento independentes que constroem um grande sistema.