O SDSM acabou, mas o desejo descontrolado de escrever permanece.

Por muitos anos, nosso irmão sofreu com a realização de trabalhos de rotina, cruzou os dedos antes de cometer e não teve sono devido a retrocessos noturnos.
Mas os tempos sombrios estão chegando ao fim.
Com este artigo, começarei uma série sobre como vejo a automação.
No processo, trataremos das etapas de automação, armazenando variáveis, formalizando o design, com RestAPI, NETCONF, YANG, YDK e programaremos muito.
Significa para
mim que: a) essa não é uma verdade objetiva, b) não é incondicionalmente a melhor abordagem c) minha opinião pode mudar mesmo durante o movimento do primeiro ao último artigo - para ser sincero, desde a fase de rascunho até a publicação, reescrevi tudo duas vezes.
Conteúdo
- Objetivos
- A rede é como um único organismo
- Teste de configuração
- Versionamento
- Serviços de monitoramento e autocorreção
- Meios
- Sistema de inventário
- Sistema de gerenciamento de espaço IP
- Sistema de descrição de serviços de rede
- Mecanismo de inicialização do dispositivo
- Modelo de configuração independente de fornecedor
- Driver específico do fornecedor
- O mecanismo para entregar a configuração ao dispositivo
- CI / CD
- Mecanismo de backup e desvio
- Sistema de monitoramento
- Conclusão
Vou tentar manter o ADSM em um formato ligeiramente diferente do SDSM. Grandes artigos numerados detalhados continuarão a aparecer e, entre eles, publicarei pequenas notas da experiência cotidiana. Vou tentar combater o perfeccionismo aqui e não lamber cada um deles.
Que engraçado que na segunda vez você tem que seguir o mesmo caminho.
Primeiro, eu tive que escrever artigos sobre a própria rede devido ao fato de eles não estarem no RuNet.
Agora não consegui encontrar um documento abrangente que sistematizasse abordagens para automação e usasse exemplos práticos simples para analisar as tecnologias acima.
Talvez eu esteja enganado, portanto, lance links para recursos adequados. No entanto, isso não mudará minha determinação em escrever, porque o objetivo principal é aprender algo pessoalmente e facilitar a vida do meu vizinho é um bônus agradável que acaricia o gene para a disseminação da experiência.
Vamos tentar pegar um data center de LAN DC de tamanho médio e elaborar todo o esquema de automação.
Farei algumas coisas quase na primeira vez com você.
Nas idéias e ferramentas descritas aqui, não serei original. Dmitry Figol tem um excelente canal com fluxos sobre este tópico .
Artigos em muitos aspectos se sobrepõem a eles.
O controlador de domínio local da LAN possui 4 controladores de domínio, cerca de 250 comutadores, meia dúzia de roteadores e alguns firewalls.
Não é o facebook, mas o suficiente para pensar profundamente sobre automação.
No entanto, existe a opinião de que, se você tiver mais de um dispositivo, já precisará de automação.
De fato, é difícil imaginar que alguém agora possa viver sem pelo menos um monte de roteiros até o joelho.
Embora eu tenha ouvido falar que existem escritórios onde os endereços IP são mantidos no Excel, e cada um dos milhares de dispositivos de rede é configurado manualmente e possui sua própria configuração exclusiva. É claro que isso pode ser considerado arte contemporânea, mas os sentimentos do engenheiro certamente serão ofendidos.
Objetivos
Agora vamos definir os objetivos mais abstratos:
- A rede é como um único organismo
- Teste de configuração
- Versão do status da rede
- Serviços de monitoramento e autocorreção
Mais adiante neste artigo, analisaremos quais meios usaremos e, a seguir, objetivos e meios em detalhes.
A rede é como um único organismo
A frase definidora do ciclo, embora à primeira vista possa não parecer tão significativa:
configuraremos a rede, não os dispositivos individuais .
Nos últimos anos, observamos uma mudança de ênfase no sentido de tratar a rede como uma entidade única; portanto, as
redes definidas por software ,
redes direcionadas por intenções e redes
autônomas entrando em nossas vidas.
Afinal, o que é globalmente necessário para aplicativos da rede: conectividade entre os pontos A e B (bem, às vezes + B-Z) e isolamento de outros aplicativos e usuários.

E, portanto, nossa tarefa nesta série é
construir um sistema que suporte a configuração atual de
toda a rede , que já está decomposta na configuração atual de cada dispositivo, de acordo com sua função e localização.
O sistema de gerenciamento de rede implica que, para fazer alterações, recorremos a ele e, por sua vez, calcula o estado desejado para cada dispositivo e o configura.
Dessa maneira, minimizamos o uso da CLI em nossas mãos para quase zero - qualquer alteração nas configurações do dispositivo ou no design da rede deve ser formalizada e documentada - e somente então lançamos nos elementos de rede necessários.
Ou seja, por exemplo, se decidirmos que a partir de agora os comutadores de montagem em rack em Kazan devem anunciar duas redes em vez de uma,
- Primeiro, documentamos as mudanças nos sistemas
- Geramos a configuração de destino de todos os dispositivos de rede
- Iniciamos o programa de atualização de configuração de rede, que calcula o que precisa ser removido em cada nó, o que adicionar e leva os nós ao estado desejado.
Ao mesmo tempo, com nossas mãos, fazemos alterações apenas no primeiro passo.
Teste de configuração
Sabe-se que 80% dos problemas ocorrem durante as alterações de configuração - a evidência indireta disso é que, durante os feriados de Ano Novo, tudo fica calmo.
Eu pessoalmente testemunhei dezenas de paradas globais devido a um erro humano: o comando errado, a configuração foi executada no ramo errado, a comunidade esqueceu, demoliu o MPLS globalmente no roteador, configurou cinco pedaços de ferro e não percebeu o sexto erro, cometeu as alterações antigas feitas por outra pessoa . Cenários a escuridão é escura.
A automação nos permitirá cometer menos erros, mas em uma escala maior. Assim, você pode bloquear não um dispositivo, mas toda a rede de uma só vez.
Desde tempos imemoriais, nossos avós verificaram a correção das mudanças feitas com olhos atentos, ovos de aço e a eficiência da rede depois de lançá-las.
Os avós, cujo trabalho levou a tempo de inatividade e perdas catastróficas, deixaram menos filhos e deveriam desaparecer com o tempo, mas a evolução é um processo lento e, portanto, nem todo mundo verifica as mudanças no laboratório antes.
No entanto, na vanguarda daqueles que automatizaram o processo de teste da configuração e sua aplicação adicional à rede. Em outras palavras, peguei emprestado o procedimento de CI / CD (
integração contínua, implantação contínua ) dos desenvolvedores.
Em uma parte, veremos como implementar isso usando um sistema de controle de versão, provavelmente um github.
Assim que você se acostumar com a idéia de rede CI / CD, durante a noite o método de verificar a configuração aplicando-a à rede em funcionamento parecerá uma ignorância medieval precoce. Sobre como martelar uma ogiva com um martelo.
Uma continuação orgânica das idéias sobre
o sistema de gerenciamento de rede e o CI / CD é o versionamento completo da configuração.
Versionamento
Assumiremos que, com quaisquer alterações, mesmo as menores, mesmo em um dispositivo discreto, toda a rede passa de um estado para outro.
E nem sempre executamos o comando no dispositivo, mudamos o estado da rede.
Agora vamos pegar esses estados e chamá-los de versões?
Digamos que a versão atual é 1.0.0.
O endereço IP da interface de loopback foi alterado em um dos ToRs? Esta é uma versão secundária - obtenha o número 1.0.1.
Revisou as políticas de importação de rota no BGP - um pouco mais sério - já 1.1.0
Decidimos nos livrar do IGP e mudar apenas para o BGP - esta é uma mudança radical no design - 2.0.0.
Ao mesmo tempo, diferentes controladores de domínio podem ter versões diferentes - a rede está em desenvolvimento, novos equipamentos estão sendo instalados, em algum lugar novos níveis de coluna são adicionados, em algum lugar - não, etc.
Falaremos sobre
versões semânticas em um artigo separado.
Repito - qualquer alteração (exceto os comandos de depuração) é uma atualização da versão. Os administradores devem ser notificados sobre qualquer desvio da versão atual.
O mesmo se aplica à reversão de alterações - essa não é a abolição dos últimos comandos, não é uma reversão pelo sistema operacional do dispositivo - está trazendo toda a rede para uma nova versão (antiga).
Serviços de monitoramento e autocorreção
Essa tarefa evidente em redes modernas vai para um novo nível.
Freqüentemente, grandes provedores de serviços praticam a abordagem de que um serviço caído deve ser rapidamente finalizado e um novo, criado, em vez de descobrir o que aconteceu.
"Muito" significa que por todos os lados é necessário manchar profusamente o monitoramento, que em segundos detectará os menores desvios da norma.
E aqui não há métricas familiares suficientes, como carregar uma interface ou acessibilidade de um nó. Não há rastreamento manual e suficiente do oficial de serviço para eles.
Para muitas coisas, geralmente deve haver
Autocura - os controles acenderam em vermelho e saíram da bananeira, onde dói.
E aqui também monitoramos não apenas dispositivos individuais, mas também a saúde da rede como um todo, tanto a caixa branca, que é relativamente clara, quanto a caixa preta, que já é mais complicada.
O que precisamos para implementar planos tão ambiciosos?
- Tenha uma lista de todos os dispositivos da rede, localização, funções, modelos e versões de software.
kazan-leaf-1.lmu.net, Kazan, folha, Juniper QFX 5120, R18.3.
- Tenha um sistema para descrever os serviços de rede.
IGP, BGP, L2 / 3VPN, política, ACL, NTP, SSH. - Ser capaz de inicializar o dispositivo.
Nome do host, IP de gerenciamento, rota de gerenciamento, usuários, chaves RSA, LLDP, NETCONF - Configure o dispositivo e traga a configuração para a versão desejada (incluindo a antiga).
- Configuração de teste
- Verifique periodicamente o status de todos os dispositivos quanto a desvios do atual e informe quem deve.
À noite, alguém silenciosamente adicionou uma regra à ACL . - Monitore o desempenho.
Meios
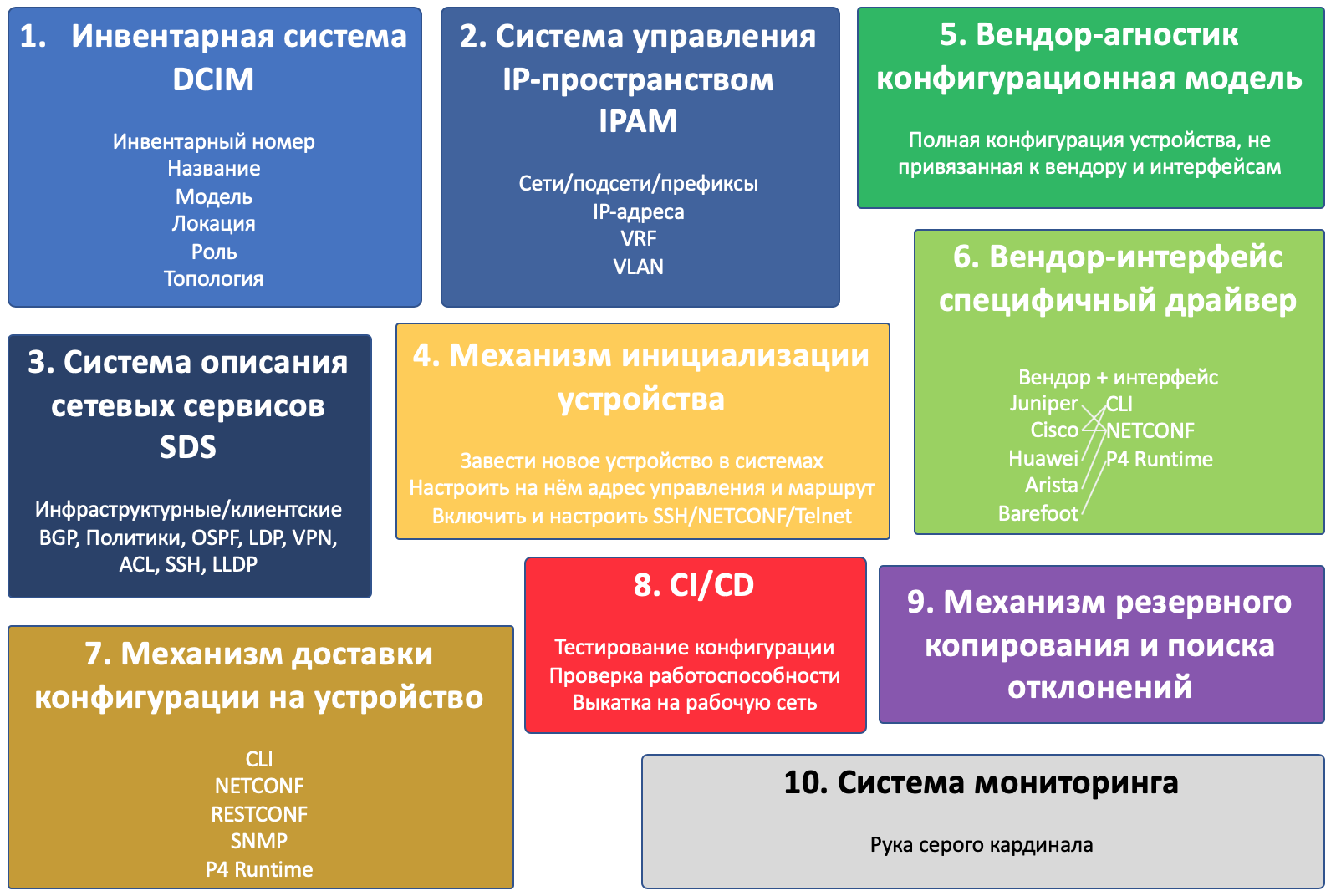
Parece complicado o suficiente para começar a decompor um projeto em componentes.
E haverá dez deles:
- Sistema de inventário
- Sistema de gerenciamento de espaço IP
- Sistema de descrição de serviços de rede
- Mecanismo de inicialização do dispositivo
- Modelo de configuração independente de fornecedor
- Driver específico do fornecedor
- O mecanismo para entregar a configuração ao dispositivo
- CI / CD
- Mecanismo de backup e desvio
- Sistema de monitoramento
A propósito, este é um exemplo de como a visão sobre os objetivos do ciclo mudou - havia quatro componentes nos componentes de rascunho.

Na ilustração, descrevi todos os componentes e o próprio dispositivo.
Os componentes de interseção interagem entre si.
Quanto maior o bloco, mais atenção você precisará prestar a este componente.
Componente 1. Sistema de inventário
Obviamente, queremos saber em que equipamento, onde fica, a que está conectado.
O sistema de inventário é parte integrante de qualquer empresa.
Na maioria dos casos, para dispositivos de rede, a empresa possui um sistema de inventário separado que resolve tarefas mais específicas.
Como parte de uma série de artigos, o chamaremos de DCIM - Data Center Infrastructure Management. Embora o próprio termo DCIM, a rigor, inclua muito mais.
Para nossas tarefas, armazenaremos as seguintes informações sobre o dispositivo:
- Número de inventário
- Título / Descrição
- Modelo ( Huawei CE12800, Juniper QFX5120, etc. )
- Parâmetros típicos ( placas, interfaces, etc. )
- Função ( Folha, Coluna, Roteador de Fronteira, etc. )
- Localização ( região, cidade, data center, rack, unidade )
- Interconexões entre dispositivos
- Topologia de rede

É perfeitamente claro que nós mesmos queremos saber tudo isso.
Mas isso ajudará na automação?
Claro.
Por exemplo, sabemos que neste data center em switches Leaf, se for Huawei, as ACLs para filtrar determinado tráfego devem ser aplicadas na VLAN e, se for Juniper, na unidade 0 da interface física.
Ou você precisa implantar um novo servidor Syslog para todos os pensionistas da região.
Nele, armazenaremos dispositivos de rede virtual, como roteadores virtuais ou refletores de raiz. Podemos adicionar um servidor DNS, NTP, Syslog e, geralmente, tudo o que de alguma forma se relaciona à rede.
Componente 2. Sistema de Gerenciamento de Espaço IP
Sim, e em nosso tempo há equipes de pessoas que controlam prefixos e endereços IP em um arquivo do Excel. Mas a abordagem moderna ainda é um banco de dados, com um frontend no nginx / apache, uma API e amplas funções para levar em conta os endereços IP e as redes com separação no VRF.
IPAM - Gerenciamento de Endereço IP.
Para nossas tarefas, armazenaremos as seguintes informações:
- VLAN
- VRF
- Redes / Sub-redes
- Endereços IP
- Vinculando endereços a dispositivos, redes a locais e números de VLAN

Novamente, é claro que queremos ter certeza de que, ao alocar um novo endereço IP para o loopback do ToR, não tropeçaremos no fato de que ele já foi atribuído a alguém. Ou que usamos o mesmo prefixo duas vezes em extremidades diferentes da rede.
Mas como isso ajuda na automação?
Fácil.
Solicitamos um prefixo no sistema com a função Loopbacks, na qual existem endereços IP disponíveis para alocação - se houver, selecione o endereço; caso contrário, solicitamos a criação de um novo prefixo.
Ou, ao criar uma configuração de dispositivo, do mesmo sistema podemos descobrir em qual VRF a interface deve estar.
E quando você inicia um novo servidor, o script entra no sistema, descobre em qual servidor o switch, em qual porta e qual sub-rede está atribuída à interface - ele selecionará o endereço do servidor.
Ele implora o desejo do DCIM e do IPAM de se combinarem em um sistema para não duplicar funções e não servir para duas entidades similares.
Então vamos fazer.
Componente 3. Sistema de descrição dos serviços de rede
Se os dois primeiros sistemas armazenam variáveis que ainda precisam ser usadas, o terceiro descreve para cada função de dispositivo como deve ser configurada.
Vale destacar dois tipos diferentes de serviços de rede:
Os primeiros foram projetados para fornecer conectividade básica e gerenciamento de dispositivos. Isso inclui VTY, SNMP, NTP, Syslog, AAA, protocolos de roteamento, CoPP, etc.
Os segundos organizam o serviço para o cliente: MPLS L2 / L3VPN, GRE, VXLAN, VLAN, L2TP, etc.
Claro, também existem casos limítrofes - onde incluir o MPLS LDP, BGP? Sim, e protocolos de roteamento podem ser usados para clientes. Mas isso não é importante.
Ambos os tipos de serviços são decompostos em primitivas de configuração:
- interfaces físicas e lógicas (tag / anteg, mtu)
- Endereços IP e VRF (IP, IPv6, VRF)
- ACLs e políticas de manipulação de tráfego
- Protocolos (IGP, BGP, MPLS)
- Políticas de roteamento (listas de prefixos, comunidade, filtros ASN).
- Serviços de serviço (SSH, NTP, LLDP, Syslog ...)
- Etc.
Como exatamente faremos isso, ainda não decidirei. Trataremos de um artigo separado.

Se um pouco mais perto da vida, poderíamos descrever que
Um switch folha deve ter sessões BGP com todos os switches Spine conectados, importar redes conectadas ao processo e aceitar apenas redes de um prefixo específico dos switches Spine. Limite o CoPP IPv6 ND a 10 pps, etc.
Por sua vez, os spins realizam sessões com todos os corpos conectados, atuando como refletores de raiz, e recebem deles apenas rotas de um certo comprimento e com uma certa comunidade.
Componente 4. Mecanismo de inicialização do dispositivo
Sob esse cabeçalho, eu combino as muitas ações que devem ocorrer para que o dispositivo apareça nos radares e seja acessado remotamente.
- Inicie o dispositivo no sistema de inventário.
- Destaque o endereço IP de gerenciamento.
- Configure o acesso básico a ele:
Nome do host, endereço IP de gerenciamento, rota para a rede de gerenciamento, usuários, chaves SSH, protocolos - telnet / SSH / NETCONF
Existem três abordagens:
- Tudo é completamente manual. O dispositivo é colocado em um ponto em que uma pessoa orgânica comum o leva ao sistema, se conecta ao console e configura. Pode funcionar em pequenas redes estáticas.
- ZTP - Provisionamento Zero Touch. Iron veio, levantou-se, recebeu um endereço via DHCP, foi para um servidor especial e se configurou.
- A infraestrutura dos servidores do console, em que a configuração inicial ocorre através da porta do console no modo automático.
Falaremos sobre os três em um artigo separado.

Componente 5. Modelo de configuração independente de fornecedor
Até agora, todos os sistemas estavam espalhados, fornecendo variáveis e uma descrição declarativa do que gostaríamos de ver na rede. Mas, mais cedo ou mais tarde, você precisa lidar com detalhes.
Nesse estágio, para cada dispositivo específico, primitivas, serviços e variáveis são combinadas em um modelo de configuração que realmente descreve a configuração completa de um dispositivo específico, apenas de maneira independente do fornecedor.
O que dá esse passo? Por que não configurar imediatamente o dispositivo, que você pode simplesmente preencher?
De fato, isso nos permite resolver três problemas:
- Não se adapte a uma interface específica para interagir com o dispositivo. Seja CLI, NETCONF, RESTCONF, SNMP - o modelo será o mesmo.
- Não mantenha o número de modelos / scripts pelo número de fornecedores na rede e, no caso de uma alteração no design, altere o mesmo em vários locais.
- Faça o download da configuração do dispositivo (backup), coloque-a exatamente no mesmo modelo e compare diretamente a configuração de destino e a disponível para calcular o delta e preparar o patch de configuração, que mudará apenas as partes necessárias ou para detectar desvios.

Como resultado desse estágio, obtemos uma configuração independente do fornecedor.
Componente 6. Driver específico da interface do fornecedor
Não se console com esperanças de que, uma vez que você possa configurar um tsiska, isso será possível da mesma maneira que um jumper, enviando-o exatamente para as mesmas chamadas. Apesar da crescente popularidade das caixas brancas e do surgimento de suporte para NETCONF, RESTCONF, OpenConfig, o conteúdo específico que esses protocolos entregam é diferente do fornecedor para o fornecedor, e essa é uma das diferenças competitivas que eles simplesmente não desistem.
É o mesmo que o OpenContrail e o OpenStack, que têm RestAPI como interface NorthBound, esperam chamadas completamente diferentes.
Portanto, na quinta etapa, o modelo independente do fornecedor deve assumir a forma em que irá para o ferro.
E aqui, todos os meios são bons (não): CLI, NETCONF, RESTCONF, SNMP em uma queda simples.
, : CLI , XML.

7.
- , — , , .
- , , ? :
- CLI (telnet, ssh)
SNMP- NETCONF
- RESTCONF
- REST API
- OpenFlow ( , FIB, )
. CLI — . SNMP… -.
RESTCONF — , REST API . NETCONF.
, , — , .
- , ?
:
- . ncclient asyncIO . , ?
- Ansible .
- Salt Napalm.
- Napalm, , .
- Nornir — , .
— .
? .
. .
, commit , .
NETCONF — .
RFP . , 32*100GE . ?

8. CI/CD
.
« », . , . , .
, , , -, .
Pipeline CI/CD.
CI/CD Continuous Integration, Continuous Deployment. , , , (Deployment) , , (Integration).
, , , , , , — .
, CI/CD Pipeline — .

9.
.
.
— - . - , , -, , .
, - , , . — , - , , , , .
, . . , .
, IP, — .

10.
— , . , . .
— CI/CD. , , .
, — , , BGP-, OSPF-, End-to-End .
, SFlow-, , - ?
.

Conclusão
— L3 Clos Fabric BGP .
Juniper, JunOs — .
Open Source — .
:
. , , , .
: , , .
.
, , .
.
, . :)
Links úteis
. .
. .