
Recentemente, houve vários artigos criticando o ImageNet, talvez o conjunto de imagens mais famoso usado para treinar redes neurais.
No primeiro artigo, Aproximando CNNs com modelos de saco de recursos locais funciona surpreendentemente bem no ImageNet, os autores adotam um modelo semelhante ao saco de palavras e usam fragmentos da imagem como “palavras”. Esses fragmentos podem ter até 9x9 pixels. E, ao mesmo tempo, nesse modelo, onde qualquer informação sobre o arranjo espacial desses fragmentos está completamente ausente, os autores obtêm uma precisão de 70 a 86% (por exemplo, a precisão de um ResNet-50 regular é de ~ 93%).
No segundo artigo das CNNs treinadas pela ImageNet são tendenciosas em relação à textura, os autores concluem que todo o conjunto de dados da ImageNet e a maneira como as pessoas e as redes neurais percebem as imagens são falhas e sugerem o uso de um novo conjunto de dados - Stylized-ImageNet.
Mais detalhadamente sobre o que as pessoas veem nas fotos e quais redes neurais
ImageNet
O conjunto de dados ImageNet começou a ser criado em 2006 pelos esforços do professor Fei-Fei Li e continua a evoluir até hoje. No momento, ele contém cerca de 14 milhões de imagens pertencentes a mais de 20 mil categorias diferentes.
Desde 2010, um subconjunto desse conjunto de dados, conhecido como ImageNet 1K com ~ 1 milhão de imagens e milhares de classes, tem sido usado no Desafio de reconhecimento visual do ImageNet em grande escala (ILSVRC). Nesta competição, em 2012, a AlexNet, uma rede neural convolucional, alcançou a precisão máxima de 1% em 60% e a faixa 5 em 80%.
É nesse subconjunto do conjunto de dados que as pessoas do ambiente acadêmico medem seu SOTA quando oferecem novas arquiteturas de rede.
Um pouco sobre o processo de aprendizado neste conjunto de dados. Falaremos sobre o protocolo de treinamento no ImageNet no ambiente acadêmico. Ou seja, quando nos são mostrados os resultados de alguma rede SE, ResNeXt ou DenseNet, o processo se parece com o seguinte: a rede aprende por 90 eras, a velocidade de aprendizado diminui nas 30a e 60a, a cada 10 vezes, como um otimizador um SGD comum com uma pequena redução de peso é selecionado, apenas RandomCrop e HorizontalFlip são usados em aprimoramentos, a imagem geralmente é redimensionada para 224x224 pixels.
Aqui está um exemplo de script pytorch para treinamento no ImageNet.
BagNet
Voltemos aos artigos mencionados anteriormente. No primeiro deles, os autores queriam um modelo mais fácil de interpretar do que as redes profundas comuns. Inspirados na idéia de modelos de bolsa de recursos, eles criam sua própria família de modelos - BagNets. Utilizando como base a rede ResNet-50 usual.
Substituindo algumas convoluções 3x3 por 1x1 no ResNet-50, elas garantem que o campo receptivo dos neurônios na última camada convolucional seja significativamente reduzido, até 9x9 pixels. Assim, eles limitam as informações disponíveis para um neurônio individual a um fragmento muito pequeno de toda a imagem - um fragmento de vários pixels. Deve-se observar que, para o novo ResNet-50, o tamanho do campo receptivo é superior a 400 pixels, o que cobre completamente a imagem, que geralmente é redimensionada para 224x224 pixels.
Esse patch é o fragmento máximo da imagem da qual o modelo pode extrair dados espaciais. No final do modelo, todos os dados foram simplesmente resumidos e o modelo não conseguiu saber onde cada patch está localizado em relação a outros patches.
No total, foram testadas três variantes de redes com campo receptivo 9x9, 17x17 e 33x33. E, apesar da completa falta de informações espaciais, esses modelos foram capazes de obter boa precisão na classificação no ImageNet. A precisão das 5 principais para os patches 9x9 foi de 70%, para 17x17 - 80%, para 33x33 - 86%. Para comparação, a precisão do top 5 da ResNet-50 é de aproximadamente 93%.

A estrutura do modelo é mostrada na figura acima. Cada patch de qxqx3 pixels cortado da imagem é transformado em um vetor 2048 pela rede.Em seguida, esse vetor é alimentado à entrada de um classificador linear, que produz pontuações para cada uma das 1000 classes. Ao coletar pontuações de cada patch em uma matriz 2D, você pode obter um mapa de calor para cada classe e cada pixel da imagem original. As pontuações finais para a imagem foram obtidas somando o mapa de calor de cada classe.
Exemplos de mapas de calor para algumas classes:

Como você pode ver, a maior contribuição para o benefício de uma classe específica é feita por patches localizados nas bordas dos objetos. Patches do plano de fundo são quase ignorados. Até agora, tudo está indo bem.
Vejamos os patches mais informativos:

Por exemplo, os autores participaram de quatro aulas. Para cada um deles, foram selecionados 2x7 patches mais significativos (ou seja, patches em que a pontuação dessa classe foi mais alta). A linha superior dos 7 patches é obtida de imagens apenas da classe correspondente, a parte inferior - de toda a amostra de imagens.
O que pode ser visto nessas fotos é notável. Por exemplo, para a classe de tenca (tenca, peixe), os dedos são uma característica. Sim, dedos humanos comuns sobre um fundo verde. E tudo porque há um pescador em quase todas as imagens dessa classe, que de fato segura esse peixe nas mãos, exibindo um troféu.
Para computadores laptop, um recurso característico são as teclas de letras. As teclas da máquina de escrever também contam para essa classe.
Uma característica da capa de um livro são as letras em um fundo colorido. Que seja uma inscrição em uma camiseta ou em uma bolsa.
Parece que esse problema não deve nos incomodar. Uma vez que é inerente apenas a uma classe estreita de redes com um campo receptivo muito limitado. Além disso, os autores calcularam a correlação entre os logits (saídas de rede antes do softmax final) atribuídos a cada classe BagNet com campo receptivo diferente e os logits do VGG-16, que possui um campo receptivo suficientemente grande. E eles a acharam bem alta.
Correlação entre BagNets e VGG-16 Os autores se perguntaram se o BagNet contém dicas sobre como outras redes tomam decisões.
Para um dos testes, eles usaram uma técnica como Image Scrambling. Que consistia em usar um gerador de textura baseado em matrizes de grama para compor uma imagem em que as texturas são salvas, mas faltam informações espaciais.

O VGG-16, treinado em imagens completas comuns, lidou muito bem com essas imagens embaralhadas. Sua precisão no top 5 caiu de 90% para 80%. Ou seja, mesmo redes com um campo receptivo bastante amplo ainda preferem lembrar texturas e ignorar informações espaciais. Portanto, sua precisão não caiu muito nas imagens embaralhadas.
Os autores realizaram uma série de experimentos em que compararam quais partes das imagens são mais significativas para BagNet e outras redes (VGG-16, ResNet-50, ResNet-152 e DenseNet-169). Tudo indicava que outras redes, como a BagNet, confiam em pequenos fragmentos de imagens e cometem os mesmos erros ao tomar decisões. Isso foi especialmente notável para redes não muito profundas, como a VGG.
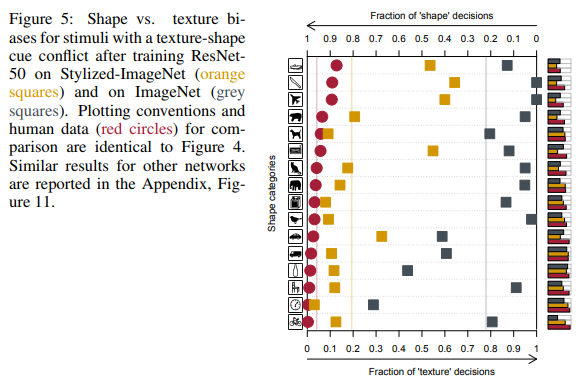
Essa tendência das redes de tomar decisões baseadas em texturas, diferentemente de nós, pessoas que preferem a forma (veja a figura abaixo), levou os autores do segundo artigo a criar um novo conjunto de dados baseado no ImageNet.
ImageNet estilizado
Antes de tudo, os autores do artigo, usando a transferência de estilos, criaram um conjunto de imagens em que a forma (dados espaciais) e as texturas de uma imagem se contradiziam. E comparamos os resultados de pessoas e redes profundas de convolução de diferentes arquiteturas em um conjunto de dados sintetizados de 16 classes.

Na figura da extrema direita, as pessoas veem um gato, uma rede - um elefante.

Comparação dos resultados de pessoas e redes neurais.
Como você pode ver, as pessoas ao atribuir um objeto a uma classe específica confiavam na forma dos objetos, nas redes neurais nas texturas. Na figura acima, as pessoas viram um gato, uma rede - um elefante.
Sim, aqui você pode encontrar falhas no fato de que as redes também estão certas e isso, por exemplo, pode ser um elefante fotografado de perto com uma tatuagem de um gato amado. Mas o fato de as redes ao tomarem decisões se comportarem de maneira diferente das pessoas, os autores consideraram o problema e começaram a procurar maneiras de resolvê-lo.
Como mencionado acima, confiando apenas em texturas, a rede é capaz de obter um bom resultado com uma precisão de 86% entre as 5 melhores. E não se trata de várias classes, nas quais as texturas ajudam a classificar as imagens corretamente, mas da maioria das classes.
O problema está no próprio ImageNet, pois será mostrado mais adiante que a rede é capaz de aprender o formulário, mas não o faz, porque as texturas são suficientes para esse conjunto de dados e os neurônios responsáveis pelas texturas estão em camadas rasas, que são muito mais fáceis de treinar.
Usando esse tempo, um mecanismo de transferência de estilo rápido AdaIN ligeiramente diferente, os autores criaram um novo conjunto de dados - o Stylized ImageNet. A forma dos objetos foi tirada do ImageNet e o conjunto de texturas dessa competição no Kaggle . O script para geração está disponível no link .

Além disso, por uma questão de brevidade, o ImageNet será referido como IN , o ImageNet estilizado como SIN .
Os autores utilizaram o ResNet-50 e três BagNet com campo receptivo diferente e treinaram em um modelo separado para cada conjunto de dados.
E aqui está o que eles fizeram:
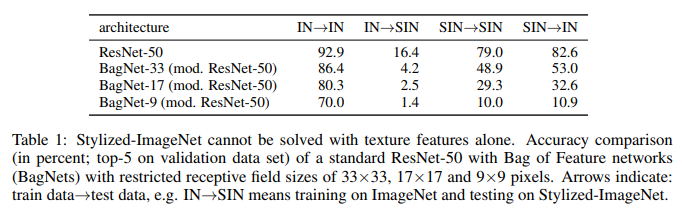
O que vemos aqui. O ResNet-50 treinado em IN é completamente incapacitado no SIN. O que confirma parcialmente que, durante o treinamento em IN, a rede se adapta às texturas e ignora a forma dos objetos. Ao mesmo tempo, o ResNet-50 treinado no SIN lida perfeitamente com o SIN e com o IN. Ou seja, se é privado de um caminho simples, a rede segue um caminho difícil - ensina a forma dos objetos.
O BagNet finalmente começou a se comportar como esperado, especialmente em pequenas correções, pois não tem nada a que se agarrar - as informações de textura estão simplesmente ausentes do SIN.
Nas dezesseis aulas mencionadas anteriormente, o ResNet-50, treinado no SIN, começou a dar respostas mais semelhantes às que as pessoas dão:
Além de simplesmente treinar o ResNet-50 no SIN, os autores tentaram treinar a rede em um conjunto misto de SIN e IN, incluindo o ajuste fino separadamente em IN puro.

Como você pode ver, ao usar o SIN + IN para treinamento, os resultados melhoraram não apenas na tarefa principal - classificação de imagens no ImageNet, mas também na tarefa de detectar objetos no conjunto de dados PASCAL VOC 2007.
Além disso, as redes treinadas pelo SIN se tornaram mais resistentes a vários ruídos nos dados.
Conclusão
Mesmo agora, em 2019, após sete anos de sucesso com a AlexNet, quando as redes neurais são amplamente usadas na visão computacional, quando o ImageNet 1K de fato se tornou o padrão para avaliar o desempenho de modelos no ambiente acadêmico, o mecanismo de como as redes neurais tomam decisões não está totalmente claro. . E como os conjuntos de dados nos quais essas redes foram treinadas influenciam isso.
Os autores do primeiro artigo tentaram esclarecer como essas decisões são tomadas em redes com arquitetura de saco de recursos com um campo receptivo limitado, mais fácil de interpretar. E, comparando as respostas da BagNet e as redes neurais profundas usuais, chegamos à conclusão de que os processos de tomada de decisão nelas são bastante semelhantes.
Os autores do segundo artigo compararam como as pessoas e as redes neurais percebem imagens em que formas e texturas se contradizem. E eles sugeriram o uso de um novo conjunto de dados, o Stylized ImageNet, para reduzir as diferenças de percepção. Tendo recebido como bônus um aumento na precisão da classificação no ImageNet e detecção em conjuntos de dados de terceiros.
A principal conclusão pode ser feita da seguinte forma: redes que aprendem com imagens, com a capacidade de lembrar propriedades espaciais de objetos de nível superior, preferem uma maneira mais fácil de atingir a meta - superestimar as texturas. Se o conjunto de dados no qual eles treinam permitir isso.
Além do interesse acadêmico, o problema da adaptação excessiva de texturas é importante para todos nós que usamos modelos pré-treinados para transferir o aprendizado em suas tarefas.
Uma conseqüência importante de tudo isso para nós é que você não deve confiar no peso dos modelos que geralmente são pré-treinados no ImageNet, já que para a maioria deles foram usados aprimoramentos bastante simples, que de forma alguma contribuem para se livrar do excesso de ajuste. E é melhor, se possível, ter modelos treinados com aprimoramentos mais graves ou estilizados ImageNet + ImageNet no ninho. Sempre poder comparar qual é o mais adequado para a nossa tarefa atual.