
Muitas pessoas estão acostumadas a classificar um filme no KinoPoisk ou imdb depois de visualizá-lo, e as seções "Também compraram com este produto" e "Produtos populares" estão em qualquer loja on-line. Mas existem tipos menos familiares de recomendações. Neste artigo, falarei sobre quais tarefas são recomendadas pelos sistemas de recomendação, onde executar e o que pesquisar no Google.
O que recomendamos?
E se quisermos recomendar uma
rota que seja
confortável para o usuário ? Diferentes aspectos da viagem são importantes para diferentes usuários: disponibilidade de assentos, tempo de viagem, tráfego, ar condicionado, uma bela vista da janela. Uma tarefa incomum, mas é bem claro como criar um sistema assim.
E se recomendarmos as
notícias ? As notícias rapidamente se tornam obsoletas - você precisa mostrar aos usuários os artigos mais recentes enquanto eles ainda são relevantes. É necessário entender o conteúdo do artigo. Já é mais difícil.
E se recomendamos
restaurantes com base em avaliações? Mas recomendamos não apenas o restaurante, mas também pratos específicos que valem a pena experimentar. Você também pode dar recomendações aos restaurantes sobre o que vale a pena melhorar.
E se
expandirmos a tarefa e tentarmos responder à pergunta: “Qual produto será do interesse do maior grupo de pessoas?”. Está se tornando muito incomum e não está claro imediatamente como resolver isso.
De fato, existem muitas variações da tarefa de recomendações e cada uma possui suas próprias nuances. Você pode recomendar coisas completamente inesperadas. Meu exemplo favorito é recomendar
pré-visualizações no Netflix .

Tarefa mais estreita
Pegue a tarefa familiar e familiar de recomendar música. O que exatamente queremos recomendar?

Nesta colagem, você encontra exemplos de várias recomendações do Spotify, Google e Yandex.
- Destacando interesses homogêneos no Daily Mix
- Radar personalizado para boletins de notícias, Lançamentos recomendados, Estréia
- Seleção pessoal do que você gosta - Playlist do dia
- Seleção pessoal de faixas que o usuário ainda não ouviu - Discover Weekly, Dejavu
- Uma combinação dos dois pontos anteriores com um viés em novas faixas - I'm Feeling Lucky
- Localizada na biblioteca, mas ainda não ouvida - Cache
- Your Top Songs 2018
- As faixas que você ouviu aos 14 anos e que moldaram seu gosto - Your Time Capsule
- Faixas que você pode gostar, mas diferem daquilo que o usuário geralmente ouve - Disjuntores
- Faixas de artistas que se apresentam na sua cidade
- Coleções de estilos
- Seleções de atividade e humor
E com certeza você pode inventar outra coisa. Mesmo se formos absolutamente capazes de prever quais faixas o usuário gosta, a questão ainda permanece de que forma e em que layout eles devem ser emitidos.
Encenação clássica
Na declaração clássica do problema, tudo o que temos é uma matriz de classificação de itens do usuário. É muito escasso e nossa tarefa é preencher os valores ausentes. Normalmente, o RMSE da classificação prevista é usado como uma métrica, no entanto,
existe uma opinião de que isso não está totalmente correto e que as características da recomendação como um todo devem ser levadas em consideração, e não a precisão de prever um número específico.
Como avaliar a qualidade?
Avaliação online
A maneira mais preferível de avaliar a qualidade do sistema é a verificação direta dos usuários no contexto das métricas de negócios. Pode ser a CTR, o tempo gasto no sistema ou o número de compras. Porém, as experiências com os usuários são caras, e eu não quero lançar um algoritmo ruim para um pequeno grupo de usuários, para que eles usem métricas de qualidade offline antes dos testes on-line.
Avaliação offline
Métricas de classificação, como MAP @ ke nDCG @ k, geralmente são usadas como métricas de qualidade.
Relevance no contexto de
MAP@k é um valor binário e, no contexto de
nDCG@k pode haver uma escala de classificação.
Mas, além da precisão da previsão, podemos estar interessados em outras coisas:
- cobertura - a parcela de bens emitida pelo recomendador,
- personalização - quão diferentes são as recomendações entre usuários,
- diversidade - quão diversos os produtos estão dentro da recomendação.
Em geral, há uma boa revisão das métricas.Qual
é o seu sistema de recomendação? Uma pesquisa sobre avaliações em recomendação . Um exemplo de formalização de métricas de novidade pode ser encontrado em
Classificação e relevância em Métricas de novidade e diversidade para sistemas de recomendação .
Dados
Feedback explícito
A matriz de classificação é um exemplo de dados explícitos. Gostar, não gostar, classificação - o próprio usuário expressou claramente o grau de seu interesse no item. Esses dados são geralmente escassos. Por exemplo, no
Rekko Challenge nos dados de teste, apenas 34% dos usuários têm pelo menos uma marca.
Feedback implícito
Há muito mais informações sobre preferências implícitas - visualizações, cliques, favoritos, configuração de notificações. Mas se o usuário assistiu ao filme - isso significa apenas que antes de assistir ao filme parecia interessante o suficiente para ele. Não podemos tirar conclusões diretas sobre se o filme foi apreciado ou não.
Funções de perda para aprendizado
Para usar feedback implícito, criamos métodos de ensino apropriados.
Classificação personalizada bayesiana
Artigo originalSabe-se com quais itens o usuário interagiu. Assumimos que estes são exemplos positivos de que ele gostou. Ainda existem muitos itens com os quais o usuário não interagiu. Não sabemos quais deles serão do interesse do usuário e quais não, mas certamente sabemos que nem todos esses exemplos serão positivos. Fazemos uma generalização grosseira e consideramos a ausência de interação como um exemplo negativo.
Amostraremos triplos {usuário, item positivo, item negativo} e multaremos o modelo se um exemplo negativo for classificado como superior a positivo.
Classificação aproximada ponderada em pares
Adicione à ideia anterior a taxa de aprendizado adaptativo. Avaliaremos o treinamento do sistema com base no número de amostras que tivemos que procurar para encontrar um exemplo negativo para o par determinado {usuário, exemplo positivo}, que o sistema classificou como mais alto que positivo.
Se encontramos esse exemplo pela primeira vez, a multa deve ser grande. Se você precisou procurar por um longo tempo, o sistema já está funcionando bem e você não precisa multar tanto.
No que mais vale a pena pensar?
Arranque a frio
Assim que aprendemos a fazer previsões para usuários e produtos existentes, surgem duas perguntas: - "Como recomendar um produto que ninguém ainda viu?" e "O que devo recomendar a um usuário que ainda não possui uma única classificação?". Para resolver esse problema, eles tentam extrair informações de outras fontes. Podem ser dados sobre um usuário de outros serviços, um questionário durante o registro, informações sobre um item de seu conteúdo.
Nesse caso, há tarefas para as quais o estado de partida a frio é constante. Nos Recomendadores com base em sessão, você precisa ter tempo para entender algo sobre o usuário durante o tempo em que ele estiver no site. Novos itens estão aparecendo constantemente nos recomendadores de notícias ou produtos de moda, enquanto itens antigos rapidamente se tornam obsoletos.
Cauda longa
Se, para cada item, calcularmos sua popularidade na forma do número de usuários que interagiram com ele ou deram uma classificação positiva, muitas vezes obteremos um gráfico como na imagem:
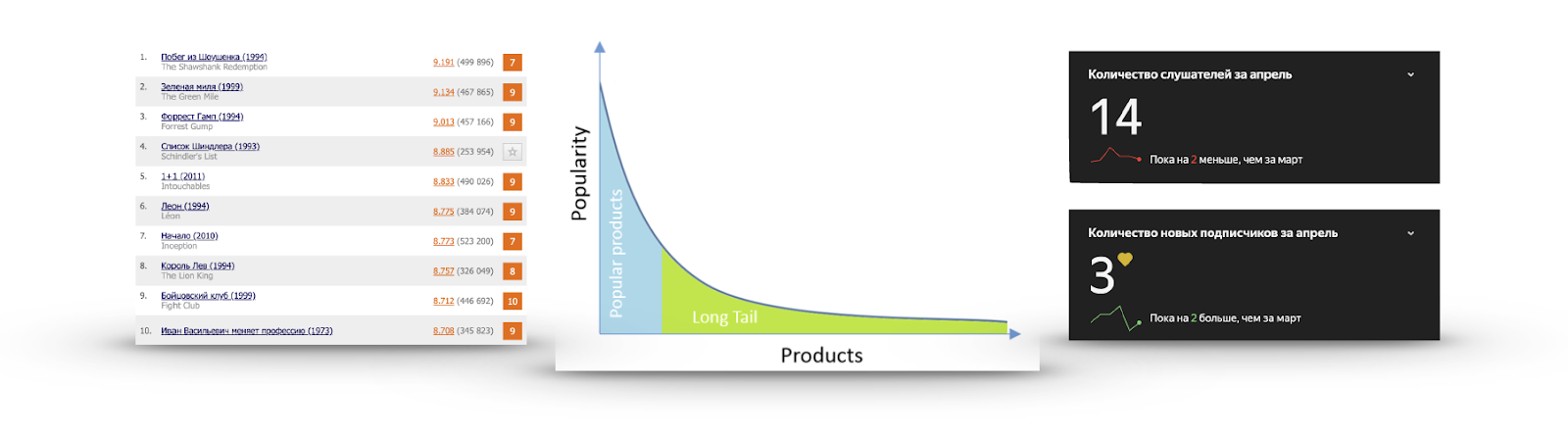
Há um número muito pequeno de itens que todos conhecem. Não há sentido em recomendá-los, porque o usuário provavelmente já os viu e simplesmente não deu uma classificação, sabe sobre eles e vai vê-los, ou decidiu firmemente não assistir. Eu assisti o trailer da Lista de Schindler mais de uma vez, mas não estava vendo.
Por outro lado, a popularidade está caindo muito rapidamente e quase ninguém viu a grande maioria dos itens. Fazer recomendações desta parte é mais útil: existe um conteúdo interessante que é improvável que o usuário se encontre. Por exemplo, à direita estão as estatísticas de escuta de um dos meus grupos favoritos no Yandex.Music.
Exploração vs Exploração
Digamos que sabemos exatamente o que o usuário gosta. Isso significa que devemos recomendar a mesma coisa? Há uma sensação de que essas recomendações rapidamente se tornarão chatas e, às vezes, vale a pena mostrar algo novo. Quando recomendamos o que exatamente deveria gostar é a exploração. Se tentarmos adicionar algo menos popular às recomendações ou de alguma forma diversificá-las - isso é exploração. Eu quero equilibrar essas coisas.
Recomendações não personalizadas
A opção mais fácil é recomendar a mesma coisa para todos.
Classificar por popularidade
Pontuação = (Avaliações positivas) - (Avaliações negativas)
Você pode subtrair desgostos de gostos e classificá-los. Mas, neste caso, não levamos em consideração a proporção percentual. Há uma sensação de que 200 curtidas de 50 não gostam não são iguais a 1200 curtidas e 1050 curtidas.
Pontuação = (classificações positivas) / (classificações totais)
Você pode dividir o número de curtidas pelo número de não curtidas, mas, neste caso, não levamos em conta o número de classificações e um produto com uma classificação de 5 pontos será classificado como superior a um produto muito popular com uma classificação média de 4,8.
Como
não classificar pela classificação média e considerar o número de classificações? Calcule o intervalo de confiança: "Com base nas estimativas disponíveis, a probabilidade de 95% da verdadeira parcela das classificações positivas é pelo menos o quê?" A resposta a esta pergunta foi dada por Edwin Wilson em 1927.
WilsonScore = \ frac {\ widehat {p} + \ frac {z_ {\ frac {\ alpha} {2}} ^ {2}} {2n} \ pm z _ {\ frac {\ alpha} {2}} \ sqrt {\ frac {\ widehat {p} (1- \ widehat {p}) + \ frac {z _ {\ frac {\ alpha} {2}} ^ {2}} {4n}} {n}}} {{ 1+ \ frac {z_ {\ frac {\ alpha} {2}} ^ {2}} {n}}
- participação observada de classificações positivas
- quantil 1-alfa da distribuição normal
Compatibilidade
A seleção dos conjuntos de produtos encontrados com frequência inclui todo um grupo de tarefas de mineração de padrões: mineração
periódica de padrões ,
mineração de regras sequencial, mineração de padrões sequenciais ,
mineração de conjuntos de itens de alta utilidade ,
mineração frequente de conjuntos de itens (análise de cesta) . Cada tarefa específica terá seus próprios
métodos , mas, se for generalizada, os algoritmos para encontrar conjuntos frequentes realizam uma busca abreviada em termos de amplitude, tentando não resolver as opções obviamente ruins.
Conjuntos raros são cortados no suporte de limite fornecido - o número ou a frequência de ocorrência do conjunto nos dados.
Depois de destacar o conjunto de itens frequentes, a qualidade de sua dependência é avaliada usando as métricas Elevação ou Confindência (a, b) / Confiança (! A, b). Eles visam remover dependências falsas.
Por exemplo, bananas podem ser encontradas frequentemente na cesta de compras, juntamente com produtos enlatados. Mas o ponto não está em alguma conexão especial, mas no fato de que as bananas são populares por si mesmas, e isso deve ser levado em consideração ao procurar por combinações.
Recomendações personalizadas
Baseado em conteúdo
A idéia de uma abordagem baseada em conteúdo é criar para ele um vetor de suas preferências no espaço de objetos com base no histórico de ações do usuário e recomendar produtos próximos a esse vetor.
Ou seja, o item deve ter uma descrição característica. Por exemplo, esses podem ser gêneros de filmes. A história de gostos e desgostos de filmes forma um vetor de preferência,
destacando alguns gêneros e evitando outros. Ao comparar o vetor do usuário e o vetor do item, você pode fazer uma classificação e obter recomendações.
Filtragem colaborativa

A filtragem colaborativa assume uma matriz de avaliação de itens do usuário. A idéia é encontrar os "vizinhos" mais semelhantes para cada usuário e preencher as lacunas de um usuário específico, ponderando a média das classificações de "vizinhos".
Da mesma forma, você pode observar a semelhança de itens, acreditando que itens semelhantes são apreciados por pessoas semelhantes. Tecnicamente, isso será simplesmente uma consideração da matriz de estimativas transposta.
Os usuários usam a escala de classificação de maneira diferente - alguém nunca a coloca acima de oito e alguém usa a escala inteira. Isso é útil para levar em consideração e, portanto, é possível prever não a classificação em si, mas um desvio em relação à classificação média.
Ou você pode normalizar as estimativas antecipadamente.
Fatoração matricial
Da matemática,
sabemos que qualquer matriz pode ser decomposta no produto de três matrizes. Mas a matriz de classificações é muito esparsa, 99% é comum. E o SVD não sabe o que são lacunas. Preenchê-los com um valor médio não é muito desejável. E, em geral, não estamos muito interessados na matriz de valores singulares - queremos apenas ter uma visão oculta de usuários e objetos, que, quando multiplicados, aproximam a classificação real. Você pode se decompor imediatamente em duas matrizes.
O que fazer com passes? Martele neles. Aconteceu que você pode treinar para aproximar classificações por métrica RMSE usando SGD ou ALS, ignorando completamente as omissões. O primeiro desses algoritmos é o
Funk SVD , que foi inventado em 2006 no decorrer da solução da concorrência da Netflix.
Prêmio Netflix
Prêmio Netflix - um evento significativo que deu um forte impulso ao desenvolvimento de sistemas de recomendação. O objetivo da competição é ultrapassar o sistema de recomendação Cinematch RMSE existente em 10%. Para esse fim, um grande conjunto de dados contendo 100 milhões de classificações foi fornecido naquele momento. A tarefa pode não parecer tão difícil, mas, para alcançar a qualidade exigida, foi necessário redescobrir a competição duas vezes - uma solução foi recebida apenas por três anos de competição. Se fosse necessário obter uma melhoria de 15%, talvez isso não fosse possível com os dados fornecidos.
Durante a competição,
algumas características
interessantes foram encontradas nos dados. O gráfico mostra a classificação média dos filmes, dependendo da data em que foram exibidos no catálogo da Netflix. A aparente lacuna está associada ao fato de que a Netflix passou de uma escala objetiva (um filme ruim, um bom filme) para uma subjetiva (eu não gostei, gostei muito). As pessoas são menos críticas ao expressar sua avaliação, em vez de caracterizar um objeto.
Este gráfico mostra como a classificação média do filme muda após o lançamento. Pode-se observar que, em 2000 dias, a pontuação aumenta 0,2. Ou seja, depois que o filme deixa de ser novo, aqueles que estão bastante confiantes de que ele gostará do filme, o que aumenta a classificação, começam a assisti-lo.
O primeiro prêmio intermediário foi concedido por uma equipe de especialistas da AT&T - Korbell. Após 2000 horas de trabalho e compilando um conjunto de 107 algoritmos, eles conseguiram uma melhoria de 8,43%.
Entre os modelos, havia uma variação de SVD e RBM, que por si só forneciam a maior parte da entrada. Os 105 algoritmos restantes melhoraram apenas um centésimo da métrica. A Netflix adaptou esses dois algoritmos para seus volumes de dados e ainda os usa como parte do sistema.
No segundo ano da competição, as duas equipes se fundiram e agora o prêmio foi conquistado pela Bellkor no BigChaos. Eles atacaram um total de 207 algoritmos e melhoraram a precisão em outro centésimo, atingindo um valor de 0,8616. A qualidade exigida ainda não é alcançada, mas já está claro que no próximo ano tudo deverá dar certo.
Terceiro ano Combinando com outra equipe, renomeando o Caos Pragmático de Bellkor e alcançando a qualidade exigida, ligeiramente inferior ao The Ensemble. Mas essa é apenas a parte pública do conjunto de dados.
No lado oculto, verificou-se que a precisão dessas equipes coincide com a quarta casa decimal, portanto o vencedor foi determinado por uma diferença de commits de 20 minutos.
A Netflix pagou o milhão prometido aos vencedores, mas nunca
usou a solução resultante . A implementação do conjunto acabou por ser muito cara e não há muitos benefícios - afinal, apenas dois algoritmos já fornecem a maior parte do aumento na precisão. E o mais importante - no final do concurso em 2009, a Netflix já havia começado a se envolver em seu serviço de streaming, além de alugar um DVD por dois anos. Eles tinham muitas outras tarefas e dados que poderiam usar em seu sistema. No entanto, o serviço de aluguel de correio em DVD ainda
atende 2,7 milhões de assinantes satisfeitos .
Redes neurais
Nos modernos sistemas de recomendação, uma pergunta frequente é como levar em consideração várias fontes de informação explícitas e implícitas. Muitas vezes, existem dados adicionais sobre o usuário ou item e você deseja usá-los. As redes neurais são uma boa maneira de contabilizar essas informações.
Sobre a questão do uso de redes para recomendações, você deve prestar atenção à revisão do
Sistema de Recomendadores baseado em Aprendizado Profundo: Uma Pesquisa e Novas Perspectivas . Ele descreve exemplos de uso de um grande número de arquiteturas para várias tarefas.
Existem muitas arquiteturas e abordagens. Um dos nomes repetidos é
DSSM . Eu também gostaria de mencionar a
Attentive Collaborative Filtering .
O ACF propõe introduzir dois níveis de atenuação:
- Mesmo com as mesmas classificações, alguns itens contribuem mais para suas preferências do que outros.
- Os itens não são atômicos, mas compostos de componentes. Alguns têm maior impacto na avaliação do que outros. O filme pode ser interessante apenas devido à presença de um ator favorito.
Bandidos com várias armas são um dos tópicos mais populares dos últimos tempos. O que são bandidos com várias armas pode ser lido em um artigo sobre
Habré ou sobre o
Medium .
Quando aplicada a recomendações, a tarefa Contextual-Bandit será mais ou menos assim: "Alimentamos os vetores de contexto do usuário e do item à entrada do sistema, queremos maximizar a probabilidade de interação (cliques, compras) para todos os usuários ao longo do tempo, fazendo atualizações frequentes na política de recomendações". Essa formulação resolve naturalmente o problema de exploração versus exploração e permite que você implante rapidamente estratégias ideais para todos os usuários.
Após a popularidade da arquitetura do transformador, também há tentativas de usá-los nas recomendações.
O próximo item A recomendação com atenção pessoal tenta combinar preferências de usuário recentes e de longo prazo para melhorar as recomendações.
As ferramentas
As recomendações não são um tópico tão popular como o CV ou a PNL; portanto, para usar as arquiteturas de grade mais recentes, você precisará implementá-las por conta própria ou esperar que a implementação do autor seja bastante conveniente e compreensível. No entanto, algumas ferramentas básicas ainda estão lá:
Conclusão
Os sistemas de recomendação foram muito longe da declaração padrão sobre o preenchimento da matriz de avaliações, e cada área específica terá suas próprias nuances. Isso introduz dificuldades, mas também acrescenta interesse. Além disso, pode ser difícil separar o sistema de recomendação do produto como um todo. De fato, não apenas a lista de itens é importante, mas também o método e o contexto da submissão. O que, como, para quem e quando recomendar. Tudo isso determina a impressão de interação com o serviço.