Olá, cidadãos de Habrovsk!
O curso
Golang Developer já está começando no OTUS hoje e consideramos uma ótima ocasião para compartilhar outro post útil sobre o assunto. Hoje vamos falar sobre a abordagem da Go aos erros. Vamos começar!

Dominar o tratamento pragmático de erros no seu código Go
 Esta postagem faz parte da série Antes de Começar, onde exploramos o mundo de Golang, compartilhamos dicas e idéias que você deve saber ao escrever código no Go, para que você não precise preencher seus próprios inchaços.
Esta postagem faz parte da série Antes de Começar, onde exploramos o mundo de Golang, compartilhamos dicas e idéias que você deve saber ao escrever código no Go, para que você não precise preencher seus próprios inchaços.Suponho que você já tenha pelo menos uma experiência básica com o Go, mas se, em algum momento, encontrou um material de discussão desconhecido, não hesite em fazer uma pausa, explorar o tópico e voltar.
Agora que abrimos o caminho, vamos lá!
A abordagem da Go ao tratamento de erros é um dos recursos mais controversos e mal utilizados. Neste artigo, você aprenderá a abordagem dos erros de Go e entenderá como eles funcionam "sob o capô". Você aprenderá algumas abordagens diferentes, examinará o código-fonte Go e a biblioteca padrão para descobrir como os erros são tratados e como trabalhar com eles. Você aprenderá por que as asserções de tipo desempenham um papel importante no tratamento delas e verá as próximas alterações no tratamento de erros que planeja introduzir no Go 2.

Entrada
Primeiras coisas primeiro: erros no Go não são excepção.
Dave Cheney escreveu um
post épico no blog sobre isso, então eu o refiro e resumo: em outros idiomas, você não pode ter certeza se uma função pode gerar uma exceção ou não. Em vez de lançar exceções, as funções Go suportam
vários valores de retorno e, por convenção, esse recurso geralmente é usado para retornar o resultado de uma função junto com uma variável de erro.

Se, por algum motivo, sua função falhar, provavelmente você deve retornar o tipo de
error declarado anteriormente. Por convenção, retornar um erro sinaliza ao chamador sobre o problema e retornar zero não é considerado um erro. Assim, você fará com que o chamador entenda que um problema surgiu e ele precisa lidar com isso: quem chama sua função, ele sabe que não deve confiar no resultado antes de verificar se há um erro. Se o erro não for nulo, ele é obrigado a verificá-lo e processá-lo (registrar, retornar, manter, chamar algum tipo de mecanismo de nova tentativa / limpeza, etc.).
 (3 // tratamento de erros
(3 // tratamento de erros
5 // continuação)Esses snippets são muito comuns no Go, e alguns os consideram como código padrão. O compilador trata variáveis não utilizadas como erros de compilação; portanto, se você não deseja verificar se há erros, deve atribuí-los a
um identificador vazio . Porém, por mais conveniente que seja, os erros não devem ser ignorados.
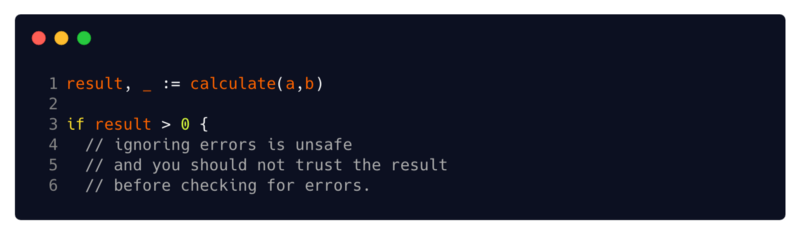 (4 // ignorar erros não é seguro e você não deve confiar no resultado antes de verificar se há erros)o resultado não pode ser confiável até a verificação de erros
(4 // ignorar erros não é seguro e você não deve confiar no resultado antes de verificar se há erros)o resultado não pode ser confiável até a verificação de errosO retorno do erro junto com os resultados, junto com o sistema estrito do tipo Go, complica bastante a gravação do código marcado. Você sempre deve assumir que o valor de uma função está corrompido, a menos que tenha verificado o erro que ela retornou e, ao atribuir o erro a um identificador vazio, ignora explicitamente que o valor da sua função pode estar corrompido.
 O id vazio é escuro e cheio de horrores.
O id vazio é escuro e cheio de horrores.O Go possui mecanismos de
panic e
recover , que também são descritos em
outra postagem detalhada do blog do Go . Mas eles não pretendem simular exceções. De acordo com Dave,
"quando você entra em pânico no Go, você realmente entra em pânico: isso não é problema de outra pessoa, ele já é um jogador". Eles são fatais e levam a uma falha no seu programa. Rob Pike cunhou o ditado "Não entre em pânico", que fala por si: você provavelmente deve evitar esses mecanismos e retornar erros.
"Erros são os significados."
"Não apenas verifique se há erros, mas lide com eles com elegância."
"Não entre em pânico"
todas as palavras de Rob Pike
Sob o capô
Interface de erroSob o capô, o tipo de erro é uma
interface simples com um método , e se você não estiver familiarizado com ele, recomendo ver
esta postagem no blog oficial do Go.
 interface de erro da fonte
interface de erro da fonteCometer seus próprios erros não é difícil. Existem várias abordagens para estruturas de usuário que implementam o método de
string Error() . Qualquer estrutura que implemente esse método único é considerada um valor de erro válido e pode ser retornada como tal.
Vejamos algumas dessas abordagens.
Estrutura errorString interna
A implementação mais comum e amplamente usada da interface de erro é a estrutura
errorString . Essa é a implementação mais fácil que você pode imaginar.
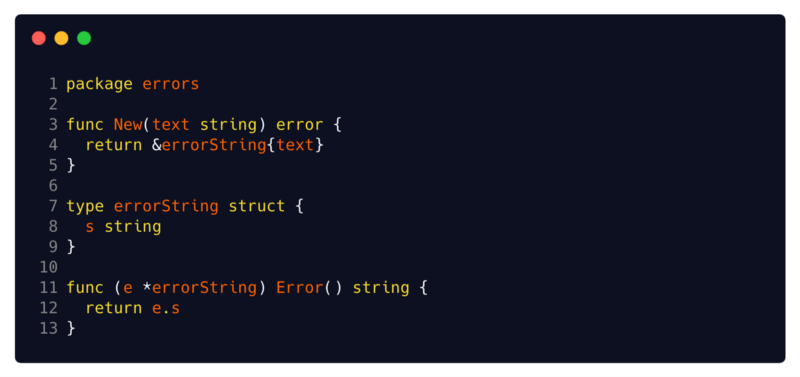
Fonte:
código fonte GoVocê pode ver sua implementação simplificada
aqui . Tudo o que faz é conter uma
string e essa sequência é retornada pelo método
Error . Esse erro de string pode ser formatado por nós com base em alguns dados, digamos, usando
fmt.Sprintf . Mas, além disso, ele não contém outros recursos. Se você aplicou
errors.New ou
fmt.Errorf , você já o
usou .
 (13 // saída :)tentar
(13 // saída :)tentargithub.com/pkg/errors
Outro exemplo simples é o
pacote pkg / errors . Para não ser confundido com o pacote de
errors interno que você aprendeu anteriormente, este pacote fornece recursos importantes adicionais, como quebra de erros, expansão, formatação e gravação de rastreamento de pilha. Você pode instalar o pacote executando
go get github.com/pkg/errors .

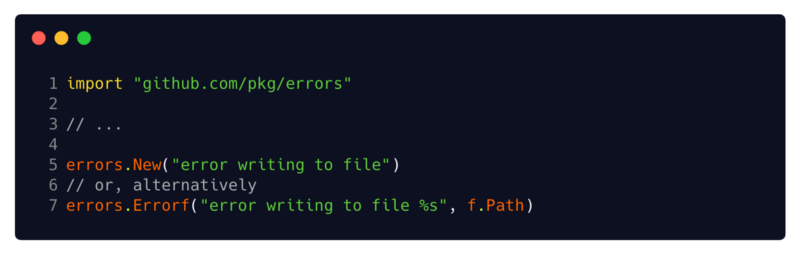
Nos casos em que você precisa anexar o rastreamento de pilha ou as informações de depuração necessárias aos seus erros, o uso das
Errorf New ou
Errorf deste pacote fornece erros que já foram gravados no rastreamento de pilha e você também pode anexar metadados simples usando-os recursos de formatação.
Errorf implementa a interface
fmt.Formatter , ou seja, você pode formatá-la usando as runas do pacote
fmt (
%s ,
%v ,
%+v , etc.).
 (// 6 ou alternativa)
(// 6 ou alternativa)Este pacote também apresenta as
errors.Wrapf e
errors.Wrapf . Essas funções adicionam contexto ao erro usando uma mensagem e um rastreamento de pilha no local em que foram chamados. Portanto, em vez de simplesmente retornar o erro, você pode envolvê-lo com contexto e dados importantes de depuração.
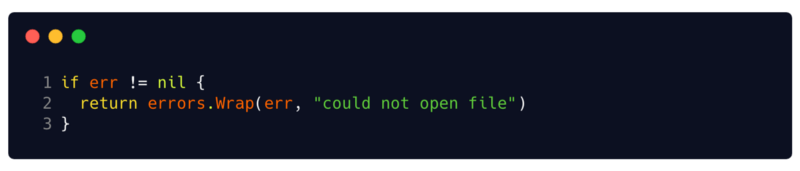
Os invólucros de erro de outros erros suportam o método de
Cause() error , que retorna seu erro interno. Além disso, eles podem ser usados com
errors.Cause(err error) error Função de
errors.Cause(err error) error , que extrai o principal erro interno do erro de
errors.Cause(err error) error .
Tratamento de erros
Homologação de tipo
As asserções de
tipo desempenham um papel importante ao lidar com erros. Você os usará para extrair informações do valor da interface e, como o tratamento de erros está associado às implementações do usuário na interface de
error , a implementação de instruções de
error é uma ferramenta muito conveniente.
Sua sintaxe é a mesma para todos os fins -
x.(T) se
x tiver um tipo de interface.
x.(T) afirma que
x não
x nil e que o valor armazenado em
x é do tipo
T Nas próximas seções, consideraremos duas maneiras de usar instruções de tipo - com um tipo específico
T e com uma interface do tipo
T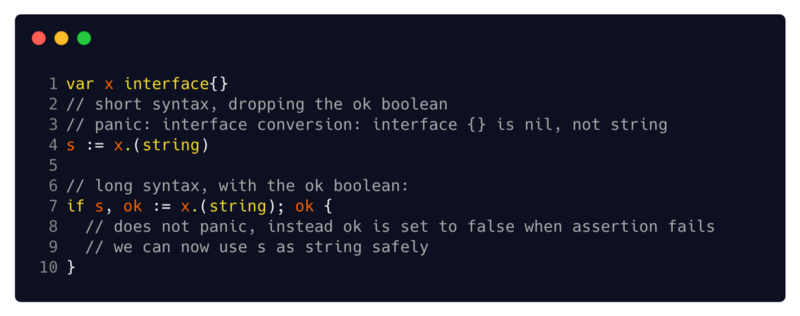 (2 // sintaxe abreviada pulando a variável booleana ok
(2 // sintaxe abreviada pulando a variável booleana ok
3 // panic: conversão de interface: interface {} é nula, não string
6 // sintaxe estendida com booleano ok
8 // não entra em pânico; em vez disso, define ok false quando a instrução é false
9 // agora podemos usar s como uma string)sandbox: pânico com sintaxe abreviada , sintaxe estendida seguraNota adicional sobre sintaxe: uma asserção de tipo pode ser usada com uma sintaxe abreviada (que entra em pânico quando uma instrução falha) ou com uma sintaxe estendida (que usa o valor lógico OK para indicar sucesso ou falha). Eu sempre recomendo tomar alongado em vez de encurtado, pois prefiro verificar a variável OK e não lidar com pânico.
Aprovação do tipo T
Uma declaração do tipo
x.(T) com uma interface do tipo
T confirma que
x implementa a interface de
T Assim, você pode garantir que o valor da interface implemente a interface e, somente se for o caso, poderá usar seus métodos.
 (5 ... // afirma que x implementa a interface do resolvedor
(5 ... // afirma que x implementa a interface do resolvedor
6 ... // aqui já podemos usar esse método com segurança)Para entender como isso pode ser usado, vamos dar uma olhada no
pkg/errors novamente. Você já conhece esse pacote de erros, então vamos nos aprofundar na função de
errors.Cause(err error) error .
Essa função recebe um erro e extrai o erro mais interno que ele sofre (aquele que não serve mais como invólucro para outro erro). Isso pode parecer primitivo, mas há muitas coisas excelentes que você pode aprender com esta implementação:

fonte:
pkg / errorsA função recebe o valor do erro e não pode assumir que o argumento
err que recebe é um erro de wrapper (suportado pelo método
Cause ). Portanto, antes de chamar o método
Cause , você precisa verificar se está lidando com um erro que implementa esse método. Ao executar uma instrução de tipo em cada iteração do loop for, você pode garantir que a variável de
cause dê suporte ao método
Cause e continue a extrair erros internos até encontrar um erro que não tenha
Cause .
Criando uma interface local simples que contém apenas os métodos necessários e aplicando asserções, seu código é separado de outras dependências. O argumento que você recebeu não precisa ser uma estrutura conhecida, apenas um erro. Qualquer tipo que implemente os métodos
Error e
Cause funcionará. Portanto, se você implementar o método
Cause no seu tipo de erro, poderá usar esta função com ele sem lentidão.
No entanto, há uma pequena desvantagem a ser lembrada: as interfaces podem mudar, portanto, você deve manter cuidadosamente o código para que suas instruções não sejam violadas. Não se esqueça de definir suas interfaces onde você as usa, para mantê-las esbeltas e organizadas, e você ficará bem.
Finalmente, se você precisar de apenas um método, às vezes é mais conveniente fazer uma declaração em uma interface anônima que contenha apenas o método em que você confia, ou seja
v, ok := x.(interface{ F() (int, error) }) . O uso de interfaces anônimas pode ajudar a separar seu código de possíveis dependências e protegê-lo de possíveis alterações nas interfaces.
Aprovação do tipo T e do comutador de tipo
Eu prefácio esta seção introduzindo dois padrões semelhantes de tratamento de erros que sofrem de várias falhas e armadilhas. Isso não significa que eles não sejam comuns. Ambos podem ser ferramentas convenientes em pequenos projetos, mas não são bem dimensionados.
A primeira é a segunda versão da asserção de tipo: uma asserção do tipo
x.(T) com um tipo específico
T é executada. Ele afirma que o valor de
x é do tipo
T ou pode ser convertido para o tipo
T (2 // podemos usar v como mypkg.SomeErrorType)
(2 // podemos usar v como mypkg.SomeErrorType)Outro é o padrão de
troca de tipo . A opção Type Switch combina uma instrução switch com uma instrução type usando a palavra-chave
type reservada. Eles são especialmente comuns no tratamento de erros, onde o conhecimento do tipo básico de um erro variável pode ser muito útil.
 (3 // processando ...
(3 // processando ...
5 // processando ...)A grande desvantagem de ambas as abordagens é que ambas levam à ligação de código com suas dependências. Ambos os exemplos devem estar familiarizados com a estrutura
SomeErrorType (que obviamente deve ser exportada) e deve importar o pacote
mypkg .
Nas duas abordagens, ao manipular seus erros, você deve estar familiarizado com o tipo e importar seu pacote. A situação é agravada quando você lida com erros em wrappers, nos quais a causa do erro pode ser um erro decorrente de uma dependência interna que você não conhece e não deve conhecer.
 (7 // processando ...
(7 // processando ...
9 // processando ...)A opção Tipo alterna entre
*MyStruct e
MyStruct . Portanto, se você não tiver certeza se está lidando com um ponteiro ou uma instância real de uma estrutura, precisará fornecer as duas opções. Além disso, como no caso de comutadores regulares, os casos no comutador de tipo não falham, mas, diferentemente do comutador de tipo usual, o uso de
fallthrough proibido no comutador de tipo, portanto, você deve usar uma vírgula e fornecer as duas opções, o que é fácil de esquecer.

Resumir
Isso é tudo! Agora você está familiarizado com os erros e deve estar preparado para corrigir quaisquer erros que seu aplicativo Go possa lançar (ou realmente retornar) ao seu caminho!
Os dois pacotes de
errors fornecem abordagens simples, mas importantes, dos erros do Go e, se atenderem às suas necessidades, serão uma ótima opção. Você pode implementar facilmente suas próprias estruturas de erro e tirar proveito do tratamento de erros Go combinando-os com
pkg/errors .
Quando você dimensiona erros simples, o uso correto de instruções de tipo pode ser uma ótima ferramenta para lidar com vários erros. Usando o Type Switch, ou validando o comportamento do erro e verificando as interfaces que ele implementa.
O que vem a seguir?
O tratamento de erros no Go agora é muito relevante. Agora que você já conhece o básico, pode estar se perguntando o que temos pela frente para lidarmos com os erros do Go!
A próxima versão do Go 2 presta muita atenção a isso, e você já pode dar uma olhada na
versão preliminar . Além disso, durante o
dotGo 2019, Marcel van Lojuizen teve uma excelente conversa sobre um tópico que eu simplesmente não posso deixar de recomendar -
“GO 2 valores de erro hoje” .
Obviamente, existem muitas outras abordagens, dicas e truques, e não posso incluí-las todas em um post! Apesar disso, espero que tenham gostado, e até o próximo episódio
de Antes de começar !
E agora tradicionalmente aguardando seus comentários.