Meu nome é Artyom Nesmiyanov, sou desenvolvedor full-stack da Yandex.Practicum, lido principalmente com o frontend. Acreditamos que é possível e necessário estudar programação, análise de dados e outras atividades digitais com prazer. E comece a aprender e continue. Qualquer desenvolvedor que não tenha desistido de si mesmo está sempre "continuando". Nós também. Portanto, percebemos as tarefas de trabalho como um formato de aprendizado. E um dos mais recentes ajudou a mim e aos caras a entender melhor em que direção desenvolver nossa pilha de front-end.

De quem e de que é feito o Workshop
Nossa equipe de desenvolvimento é extremamente compacta. Existem apenas duas pessoas no back-end, quatro no front-end, considerando-me uma pilha cheia. De tempos em tempos, os caras do Yandex.Tutorial se juntam a nós no reforço. Trabalhamos no Scrum com sprints de duas semanas.
Nosso front-end é baseado no React.js em conjunto com o Redux / Redux-Saga, usamos o Express para se comunicar com o back-end. A parte de back-end da pilha está em Python (mais precisamente, Django), o banco de dados é PostgreSQL e, para algumas tarefas, Redis. Usando o Redux, armazenamos armazenamentos de informações, enviamos ações que são processadas pelo Redux e pelo Redux-Saga. Todos os efeitos colaterais, como solicitações de servidor, chamadas para Yandex.Metrica e redirecionamentos, são processados apenas no Redux-Saga. E todas as modificações de dados ocorrem nos redutores Redux.
Como não ignorar um log no seu iframe
Agora, em nossa plataforma, o treinamento está aberto em três profissões: desenvolvedor front-end, desenvolvedor web, analista de dados. E estamos vendo ferramentas ativamente para cada curso.
No curso de seis meses "
Data Analyst ", fizemos um simulador interativo, onde ensinamos aos usuários
como usar o Jupyter Notebook . Este é um shell legal para computação interativa, que é amado com razão pelos cientistas de dados. Todas as operações no ambiente são realizadas dentro do notebook, mas de maneira simples - um notebook (como chamarei mais adiante).
As solicitações de experiência e temos certeza: é importante que as tarefas de treinamento sejam quase reais. Incluindo em termos de ambiente de trabalho. Portanto, era necessário garantir que, dentro da lição, todo o código pudesse ser escrito, executado e verificado diretamente no caderno.
Com a implementação básica das dificuldades não surgiram. O caderno em si foi colocado em um iframe separado, a lógica para checá-lo foi prescrita no back-end.
 O bloco de anotações do aluno (à direita) é apenas um iframe cuja URL leva a um bloco de anotações específico no JupyterHub.
O bloco de anotações do aluno (à direita) é apenas um iframe cuja URL leva a um bloco de anotações específico no JupyterHub.Numa primeira aproximação, tudo funcionou sem problemas, sem problemas. No entanto, durante os testes, surgiram absurdos. Por exemplo, você tem a garantia de conduzir a versão correta do código em um notebook; no entanto, depois de clicar no botão "Tarefa de teste", o servidor responde que a resposta está supostamente incorreta. E por que - um mistério.
Bem, o que está acontecendo, percebemos no mesmo dia em que encontramos um bug: descobriu-se que a solução que não estava voando era a atual, a solução que acabou de ser inserida no formulário Notebook Jupyter, mas a anterior já estava apagada. O notebook em si não teve tempo de sobreviver e diminuímos a velocidade do back-end para que ele verificasse a tarefa nele. O que, é claro, ele não poderia fazer.
Tivemos que nos livrar do rassinhron entre salvar o notebook e enviar uma solicitação ao servidor para verificá-lo. O problema era que era necessário fazer com que o iframe do notebook se comunicasse com a janela principal, ou seja, com o frontend no qual a lição como um todo estava girando. Obviamente, era impossível encaminhar qualquer evento diretamente entre eles: eles vivem em domínios diferentes.
Procurando uma solução, descobri que o Jupyter Notebook permite que seus plugins sejam conectados. Há um objeto Júpiter - um notebook - com o qual você pode operar. Trabalhar com ele envolve eventos, incluindo a preservação do notebook, bem como a chamada da ação apropriada. Tendo descoberto o interior do Jupyter (eu precisava: não existe documentação normal para ele), os caras e eu fizemos - criamos nosso próprio plug-in para ele e, usando o mecanismo postMessage, conseguimos o trabalho coordenado dos elementos dos quais a lição do Workshop foi montada.
Elaboramos uma solução alternativa, levando em consideração o fato de que nossa pilha inclui inicialmente o já mencionado Redux-Saga - para simplificar, o middleware sobre o Redux, o que torna possível trabalhar de forma mais flexível com efeitos colaterais. Por exemplo, salvar um notebook é algo como esse efeito colateral. Enviamos algo para o back-end, esperamos por algo, obtemos algo. Todo esse movimento é processado dentro do Redux-Saga: lança os eventos para o front-end, ditando a ele como exibir o que na interface do usuário.
Qual é o resultado? O PostMessage é criado e enviado para o iframe com um notebook. Quando um iframe vê que algo veio de fora, analisa a string recebida. Percebendo que ele precisa manter o notebook, ele executa essa ação e, por sua vez, envia uma resposta postMessage sobre a execução da solicitação.
Quando clicamos no botão "Verificar tarefa", o evento correspondente é enviado para a Redux Store: "Assim e assim, fomos verificados". Redux-Saga vê a ação chegar e postMessage em um iframe. Agora ela está esperando o iframe dar uma resposta. Enquanto isso, nosso aluno vê o indicador de download no botão "Verificar a tarefa" e entende que o simulador não trava, mas "pensa". E somente quando o postMessage volta dizendo que o salvamento está completo, o Redux-Saga continua trabalhando e envia uma solicitação ao back-end. No servidor, a tarefa é verificada - a solução certa ou não, se erros são cometidos, qual, etc., e essas informações são armazenadas ordenadamente no Redux Store. E a partir daí, o script de front-end o puxa para a interface da lição.
Aqui está o circuito resultante:
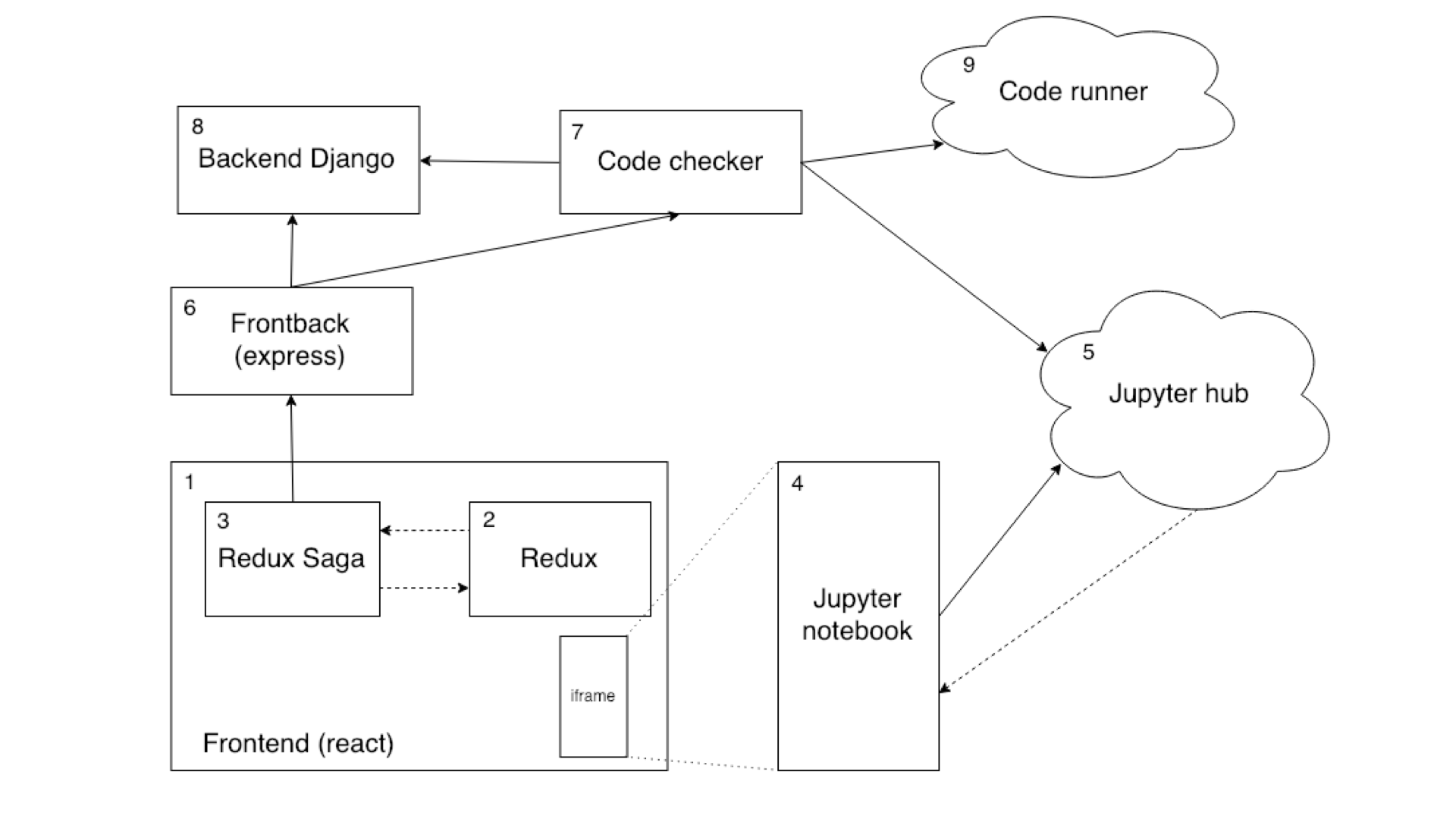 (1) Pressionamos o botão "Verificar tarefa" (Verificar) → (2) Enviamos a ação CHECK_NOTEBOOK_REQUEST → (3) Enviamos a ação da verificação → (2) Enviamos a ação SAVE_NOTEBOOK_REQUEST → (3) Captamos a ação e enviamos postMessage no iframe → salvar evento (4) Receber mensagem → (5) Notebook é salvo → (4) Receber evento da API do Jupyter em que o notebook foi salvo e enviar postMessage salvo no notebook → (1) Receber evento → (2) Enviar ação SAVE_NOTEBOOK_SUCCESS → (3) Capturamos a ação e envie uma solicitação para verificar o notebook → (6) → (7) Verifique se este notebook está no banco de dados → (8) → (7) Acesse o código do notebook → (5) Retorne o código → (7) Execute a verificação do código → (9) ) → (7) Recebemos um corte verificação tat → (6) → (3) enviamos ação CHECK_NOTEBOOK_SUCCESS → (2) para baixo para verificar a resposta do lado → (1) Desenhe resultado
(1) Pressionamos o botão "Verificar tarefa" (Verificar) → (2) Enviamos a ação CHECK_NOTEBOOK_REQUEST → (3) Enviamos a ação da verificação → (2) Enviamos a ação SAVE_NOTEBOOK_REQUEST → (3) Captamos a ação e enviamos postMessage no iframe → salvar evento (4) Receber mensagem → (5) Notebook é salvo → (4) Receber evento da API do Jupyter em que o notebook foi salvo e enviar postMessage salvo no notebook → (1) Receber evento → (2) Enviar ação SAVE_NOTEBOOK_SUCCESS → (3) Capturamos a ação e envie uma solicitação para verificar o notebook → (6) → (7) Verifique se este notebook está no banco de dados → (8) → (7) Acesse o código do notebook → (5) Retorne o código → (7) Execute a verificação do código → (9) ) → (7) Recebemos um corte verificação tat → (6) → (3) enviamos ação CHECK_NOTEBOOK_SUCCESS → (2) para baixo para verificar a resposta do lado → (1) Desenhe resultadoVamos ver como tudo isso funciona no contexto do código.
Temos no front-end trainer_type_jupyter.jsx - o script da página em que nosso caderno é desenhado.
<div className="trainer__right-column"> {notebookLinkIsLoading ? ( <iframe className="trainer__jupiter-frame" ref={this.onIframeRef} src={notebookLink} /> ) : ( <Spin size="l" mix="trainer__jupiter-spin" /> )} </div>
Depois de clicar no botão "Verificar trabalho", o método handleCheckTasks é chamado.
handleCheckTasks = () => { const {checkNotebook, lesson} = this.props; checkNotebook({id: lesson.id, iframe: this.iframeRef}); };
De fato, handleCheckTasks serve para invocar a ação Redux com os parâmetros passados.
export const checkNotebook = getAsyncActionsFactory(CHECK_NOTEBOOK).request;
Essa é uma ação comum projetada para Redux-Saga e métodos assíncronos. Aqui, getAsyncActionsFactory gera três ações:
// utils / help-store / async.js
export function getAsyncActionsFactory(type) { const ASYNC_CONSTANTS = getAsyncConstants(type); return { request: payload => ({type: ASYNC_CONSTANTS.REQUEST, payload}), error: (response, request) => ({type: ASYNC_CONSTANTS.ERROR, response, request}), success: (response, request) => ({type: ASYNC_CONSTANTS.SUCCESS, response, request}), } }
Assim, getAsyncConstants gera três constantes no formato * _REQUEST, * _SUCCESS e * _ERROR.
Agora vamos ver como nossa Redux-Saga lidará com toda essa economia:
// trainer.saga.js
function* watchCheckNotebook() { const watcher = createAsyncActionSagaWatcher({ type: CHECK_NOTEBOOK, apiMethod: Api.checkNotebook, preprocessRequestGenerator: function* ({id, iframe}) { yield put(trainerActions.saveNotebook({iframe})); yield take(getAsyncConstants(SAVE_NOTEBOOK).SUCCESS); return {id}; }, successHandlerGenerator: function* ({response}) { const {completed_tests: completedTests} = response; for (let id of completedTests) { yield put(trainerActions.setTaskSolved(id)); } }, errorHandlerGenerator: function* ({response: error}) { yield put(appActions.setNetworkError(error)); } }); yield watcher(); }
A magia? Nada de extraordinário. Como você pode ver, createAsyncActionSagaWatcher simplesmente cria um marcador de água que pode pré-processar os dados que entram na ação, fazer uma solicitação em um URL específico, despachar a ação * _REQUEST e despachar * _SUCCESS e * _ERROR após uma resposta bem-sucedida do servidor. Além disso, é claro, para cada opção, os manipuladores são fornecidos dentro do relógio.
Você provavelmente percebeu que no pré-processador de dados chamamos outro Redux-Saga, espere até que termine com SUCCESS e só então continue trabalhando. E, é claro, os iframes não precisam ser enviados ao servidor, portanto, apenas fornecemos o ID.
Dê uma olhada na função saveNotebook:
function* saveNotebook({payload: {iframe}}) { iframe.contentWindow.postMessage(JSON.stringify({ type: 'save-notebook' }), '*'); yield; }
Atingimos o mecanismo mais importante na interação de iframes com o frontend - postMessage. O fragmento de código fornecido envia uma ação com o tipo save-notebook, que é processado dentro do iframe.
Eu já mencionei que precisávamos escrever um plug-in para o Jupyter Notebook, que seria carregado dentro do notebook. Esses plugins são mais ou menos assim:
define([ 'base/js/namespace', 'base/js/events' ], function( Jupyter, events ) {...});
Para criar essas extensões, você deve lidar com a própria API do Jupyter Notebook. Infelizmente, não há documentação clara sobre isso. Mas os
códigos-fonte estão disponíveis e eu os examinei. É bom que o código seja legível lá.
O plugin deve ser ensinado a se comunicar com a janela principal na frente da lição: afinal, a dessincronização entre eles é a causa do erro na verificação da tarefa. Antes de tudo, assinamos todas as mensagens que recebemos:
window.addEventListener('message', actionListener);
Agora iremos fornecer o seu processamento:
function actionListener({data: eventString}) { let event = ''; try { event = JSON.parse(eventString); } catch(e) { return; } switch (event.type) { case 'save-notebook': Jupyter.actions.call('jupyter-notebook:save-notebook'); Break; ... default: break; } }
Todos os eventos que não se encaixam no nosso formato são ignorados.
Vemos que o evento save-notebook chega até nós e chamamos a ação para salvar o notebook. Resta apenas enviar uma mensagem de que o notebook foi preservado:
events.on('notebook_saved.Notebook', actionDispatcher); function actionDispatcher(event) { switch (event.type) { case 'select': const selectedCell = Jupyter.notebook.get_selected_cell(); dispatchEvent({ type: event.type, data: {taskId: getCellTaskId(selectedCell)} }); return; case 'notebook_saved': default: dispatchEvent({type: event.type}); } } function dispatchEvent(event) { return window.parent.postMessage( typeof event === 'string' ? event : JSON.stringify(event), '*' ); }
Em outras palavras, basta enviar {type: 'notebook_saved'} para cima. Isso significa que o notebook foi preservado.
Vamos voltar ao nosso componente:
//trainer_type_jupyter.jsx
componentDidMount() { const {getNotebookLink, lesson} = this.props; getNotebookLink({id: lesson.id}); window.addEventListener('message', this.handleWindowMessage); }
Ao montar o componente, solicitamos ao servidor um link para o notebook e assinamos todas as ações que podem ser executadas para nós:
handleWindowMessage = ({data: eventString}) => { const {activeTaskId, history, match: {params}, setNotebookSaved, tasks} = this.props; let event = null; try { event = JSON.parse(eventString); } catch(e) { return; } const {type, data} = event; switch (type) { case 'app_initialized': this.selectTaskCell({taskId: activeTaskId}) return; case 'notebook_saved': setNotebookSaved(); return; case 'select': { const taskId = data && data.taskId; if (!taskId) { return } const task = tasks.find(({id}) => taskId === id); if (task && task.status === TASK_STATUSES.DISABLED) { this.selectTaskCell({taskId: null}) return; } history.push(reversePath(urls.trainerTask, {...params, taskId})); return; } default: break; } };
É aqui que o envio de ação setNotebookSaved é chamado, o que permitirá ao Redux-Saga continuar trabalhando e salvando o notebook.
Falhas de escolha
Lidamos com o bug de preservação do notebook. E imediatamente mudou para um novo problema. Era necessário aprender a bloquear tarefas (tarefas), às quais o aluno ainda não havia alcançado. Em outras palavras, era necessário sincronizar a navegação entre nosso simulador interativo e o Jupyter Notebook: em uma lição, tínhamos um caderno com várias tarefas no iframe, cujas transições precisavam ser coordenadas com as alterações na interface da lição como um todo. Por exemplo, para que, ao clicar na segunda tarefa na interface da lição no bloco de notas, ocorra a mudança para a célula correspondente à segunda tarefa. E vice-versa: se no quadro do Jupyter Notebook você selecionar uma célula vinculada à terceira tarefa, o URL na barra de endereços do navegador deve mudar imediatamente e, consequentemente, o texto que acompanha a teoria da terceira tarefa deve ser exibido na interface da lição.
Houve uma tarefa mais difícil. O fato é que nosso programa de treinamento foi desenvolvido para a passagem consistente de lições e tarefas. Enquanto isso, por padrão, no bloco de anotações de Júpiter, nada impede que o usuário abra qualquer célula. E no nosso caso, cada célula é uma tarefa separada. Acabou que você pode resolver a primeira e a terceira tarefas e pular a segunda. O risco de aprovação não linear da lição teve que ser eliminado.
A solução foi baseada no mesmo postMessage. Somente tivemos que nos aprofundar na API do Jupyter Notebook, mais especificamente, no que o próprio objeto Jupiter pode fazer. E crie um mecanismo para verificar a qual tarefa a célula está conectada. Na sua forma mais geral, é o seguinte. Na estrutura do notebook, as células vão seqüencialmente uma após a outra. Eles podem ter metadados. O campo "Tags" é fornecido nos metadados, e tags são apenas identificadores de tarefas dentro da lição. Além disso, usando células de marcação, você pode determinar se elas devem ser bloqueadas pelo aluno até o momento. Como resultado, de acordo com o modelo atual do simulador, clicando na célula, começamos a enviar postMessage do iframe para o front-end, que, por sua vez, vai para o Redux Store e verifica, com base nas propriedades da tarefa, se ele está disponível para nós agora. Se indisponível, mudamos para a célula ativa anterior.
Portanto, concluímos que é impossível selecionar uma célula em um notebook que não deva ser acessível pela linha do tempo do treinamento. É verdade que isso deu origem a um erro acrítico, mas crítico: você tenta clicar em uma célula com uma tarefa inacessível e ela pisca rapidamente: fica claro que foi ativada por um momento, mas foi imediatamente bloqueada. Embora não tenhamos eliminado essa aspereza, ela não interfere nas lições, mas, em segundo plano, continuamos a pensar em como lidar com isso (a propósito, há algum pensamento?).
Um pouco sobre como modificamos nosso front-end para resolver o problema. Vamos voltar a trainer_type_jupyter.jsx novamente - focaremos em app_initialized e selecionaremos.
Com app_initialized, tudo é elementar: o notebook foi carregado e queremos fazer alguma coisa. Por exemplo, selecione a célula atual, dependendo da tarefa selecionada. O plug-in é descrito para que você possa passar taskId e alternar para a primeira célula correspondente a este taskId.
Ou seja:
// trainer_type_jupyter.jsx
selectTaskCell = ({taskId}) => { const {selectCell} = this.props; if (!this.iframeRef) { return; } selectCell({iframe: this.iframeRef, taskId}); };
// trainer.actions.js
export const selectCell = ({iframe, taskId}) => ({ type: SELECT_CELL, iframe, taskId });
// trainer.saga.js
function* selectCell({iframe, taskId}) { iframe.contentWindow.postMessage(JSON.stringify({ type: 'select-cell', data: {taskId} }), '*'); yield; } function* watchSelectCell() { yield takeEvery(SELECT_CELL, selectCell); }
// custom.js (plugin do Jupyter)
function getCellTaskId(cell) { const notebook = Jupyter.notebook; while (cell) { const tags = cell.metadata.tags; const taskId = tags && tags[0]; if (taskId) { return taskId; } cell = notebook.get_prev_cell(cell); } return null; } function selectCell({taskId}) { const notebook = Jupyter.notebook; const selectedCell = notebook.get_selected_cell(); if (!taskId) { selectedCell.unselect(); return; } if (selectedCell && selectedCell.selected && getCellTaskId(selectedCell) === taskId) { return; } const index = notebook.get_cells() .findIndex(cell => getCellTaskId(cell) === taskId); if (index < 0) { return; } notebook.select(index); const cell = notebook.get_cell(index); cell.element[0].scrollIntoView({ behavior: 'smooth', block: 'start' }); } function actionListener({data: eventString}) { ... case 'select-cell': selectCell(event.data); break;
Agora você pode trocar de célula e aprender com o iframe que a célula foi trocada.
Ao alternar a célula, alteramos a URL e caímos em outra tarefa. Resta apenas fazer o oposto - ao escolher outra tarefa na interface, alterne a célula. Fácil:
componentDidUpdate({match: {params: {prevTaskId}}) { const {match: {params: {taskId}}} = this.props; if (taskId !== prevTaskId) { this.selectTaskCell({taskId});
Caldeira separada para perfeccionistas
Seria legal nos gabarmos de como estamos bem. A solução na linha inferior é eficaz, embora pareça um pouco confusa: se resumirmos, temos um método que processa qualquer mensagem vinda de fora (no nosso caso, de um iframe). Mas no sistema que construímos, há coisas que eu e meus colegas não gostamos muito.
• Não há flexibilidade na interação dos elementos: sempre que desejamos adicionar novas funcionalidades, teremos que alterar o plug-in para suportar o antigo e o novo formato de comunicação. Não existe um único mecanismo isolado para trabalhar entre o iframe e nosso componente front-end, que renderiza o Jupyter Notebook na interface da lição e trabalha com nossas tarefas. Globalmente - há um desejo de tornar um sistema mais flexível para que no futuro seja fácil adicionar novas ações, eventos e processá-los. E no caso não apenas do notebook Júpiter, mas também de qualquer iframe nos simuladores. Então, estamos procurando passar o código do plug-in através do postMessage e renderizá-lo (eval) dentro do plug-in.
• Fragmentos de código que resolvem problemas estão espalhados por todo o projeto. A comunicação com iframes é realizada tanto no Redux-Saga quanto no componente, o que certamente não é o ideal.
• O iframe em si com a renderização do Jupyter Notebook está em outro serviço. A edição é um pouco problemática, especialmente em conformidade com o princípio de compatibilidade com versões anteriores. Por exemplo, se queremos mudar algum tipo de lógica no front-end e no próprio notebook, temos que fazer um trabalho duplo.
Muitos gostariam de implementar mais facilmente. Tome pelo menos reagir. Ele possui vários métodos de ciclo de vida e cada um deles precisa ser processado. Além disso, estou confuso com a ligação com o React. Idealmente, eu gostaria de poder trabalhar com nossos iframes, independentemente da sua estrutura front-end. Em geral, a interseção das tecnologias que escolhemos impõe limitações: o mesmo Redux-Saga espera que as ações do Redux sejam nossas, e não pós-mensagem.
Portanto, definitivamente não vamos parar no que foi alcançado. Um dilema do livro didático: você pode ir para o lado da beleza, mas sacrificar a otimização do desempenho ou vice-versa. Ainda não encontramos a melhor solução.
Talvez as idéias surjam com você?