 Postado por Lyudmila Dezhkina, arquiteto de soluções, DataArt
Postado por Lyudmila Dezhkina, arquiteto de soluções, DataArtPor cerca de seis meses, nossa equipe trabalha na Plataforma de Manutenção Preditiva - um sistema que deve prever possíveis erros e falhas no equipamento. Essa área fica na interseção da IoT e do Machine Learning, e você precisa trabalhar aqui com hardware e, de fato, com software. Como criamos o ML sem servidor com a biblioteca Scikit-learn na AWS será discutido neste artigo. Vou falar sobre as dificuldades que encontramos e sobre as ferramentas que usei para economizar tempo.
Apenas no caso, um pouco sobre você.Trabalho com programação há mais de 12 anos e, durante esse período, participei de vários projetos. Incluindo jogos, comércio eletrônico, carga alta e Big Data. Há cerca de três anos estou envolvido em projetos relacionados ao Machine Learning e Deep Learning.
 Parecia que os requisitos apresentados pelo cliente desde o início
Parecia que os requisitos apresentados pelo cliente desde o inícioA entrevista com o cliente foi difícil, principalmente falamos sobre aprendizado de máquina, nos perguntaram muito sobre algoritmos e experiência pessoal específica. Mas não serei modesto - nesta parte, inicialmente entendemos muito bem. O primeiro obstáculo foi o hardware que o sistema contém. No entanto, minha experiência com o ferro pessoalmente não é tão diversa.
O cliente nos explicou: "Olha, nós temos um transportador". Eu imediatamente criei uma correia transportadora no caixa de um supermercado. O que e o que pode ser ensinado lá? Mas rapidamente ficou claro que a palavra transportador oculta um centro de triagem com uma área de 300 a 400 metros quadrados. m, e de fato, existem muitos transportadores lá. Ou seja, muitos elementos do equipamento precisam ser conectados: sensores, robôs. Uma ilustração clássica do conceito de
"Revolução Industrial 4.0" , na qual a IoT e a ML estão se unindo.
O tema Manutenção Preditiva certamente aumentará por pelo menos mais dois a três anos. Cada transportador é decomposto em elementos: de um robô ou motor que move uma correia transportadora para um rolamento separado. Além disso, se alguma dessas peças falhar, todo o sistema será interrompido e, em alguns casos, uma hora de transportador inativo pode custar um milhão e meio de dólares (isso não é um exagero!).
Um de nossos clientes está envolvido no transporte e logística de cargas: em sua base, os robôs descarregam 40 caminhões em 8 minutos. Não pode haver atrasos aqui, os carros devem ir e vir de acordo com uma programação muito rigorosa, ninguém está consertando nada durante o processo de descarregamento. Em geral, existem apenas duas ou três pessoas com comprimidos nesta base. Mas há um mundo um pouco diferente, onde tudo não parece tão elegante, e onde a mecânica com luvas e sem computadores está diretamente sobre o objeto.
Nosso primeiro pequeno projeto de protótipo consistiu em aproximadamente 90 sensores e tudo correu bem até que o projeto teve que ser dimensionado. Para equipar a menor parte separada de um centro de classificação real, são necessários cerca de 550 sensores.
CLP e sensores
Controlador lógico programável - um pequeno computador com um programa cíclico embutido - costuma ser usado para automatizar o processo. Na verdade, com a ajuda do PLC, fazemos leituras dos sensores: por exemplo, aceleração e velocidade, nível de tensão, vibração ao longo dos eixos, temperatura (no nosso caso, 17 indicadores). Os sensores geralmente são confundidos. Embora nosso projeto tenha mais de 8 meses, ainda temos nosso próprio laboratório, onde experimentamos sensores, selecionando os modelos mais adequados. Agora, por exemplo, estamos considerando o uso de sensores ultrassônicos.
Pessoalmente, vi o PLC pela primeira vez, somente quando cheguei ao site do cliente. Como desenvolvedor, eu nunca os encontrei antes, e isso foi bastante desagradável: assim que nos aprofundamos em mais de dois, três e quatro motores de uma conversa, comecei a perder a discussão. Cerca de 80% das palavras ainda eram inteligíveis, mas o significado geral teimosamente desapareceu. Em geral, esse é um problema sério, cujas raízes estão em um limite bastante alto para a entrada na programação de CLP - um microcomputador onde você pode realmente fazer algo custa pelo menos US $ 200-300. A programação em si não é complicada e os problemas começam apenas quando o sensor está conectado a um transportador ou motor real.
 Conjunto de sensores padrão 37 em 1
Conjunto de sensores padrão 37 em 1Sensores, como você sabe, são diferentes. Os mais simples que conseguimos encontrar custam US $ 18. A principal característica - “largura de banda e resolução” - quantos dados o sensor transmite em um minuto. Pela minha própria experiência, posso dizer que, se o fabricante reivindicar, digamos, 30 pontos de dados por minuto, na realidade é improvável que seu número seja superior a 15. E isso também representa um problema sério: o tópico está na moda e algumas empresas estão tentando ganhar dinheiro com esse hype. Testamos sensores no valor de US $ 158, cuja largura de banda teoricamente tornou possível simplesmente jogar fora parte do nosso código. Mas, na verdade, eles acabaram sendo um análogo absoluto desses mesmos dispositivos, com US $ 18 cada.
A primeira etapa: conectamos sensores, coletamos dados
Na verdade, a primeira fase do projeto foi a instalação do hardware, a instalação em si é um processo longo e tedioso. Isso também é uma ciência inteira - os dados que ele coleta podem depender de como você conecta o sensor a um motor ou caixa. Tivemos um caso em que um dos dois sensores idênticos foi conectado dentro da caixa e o outro fora. A lógica sugere que a temperatura interna deve ser mais alta, mas os dados coletados indicam o contrário. Aconteceu que o sistema falhou, mas quando o desenvolvedor chegou à fábrica, ele viu que o sensor não estava apenas na caixa, mas diretamente no ventilador localizado lá.
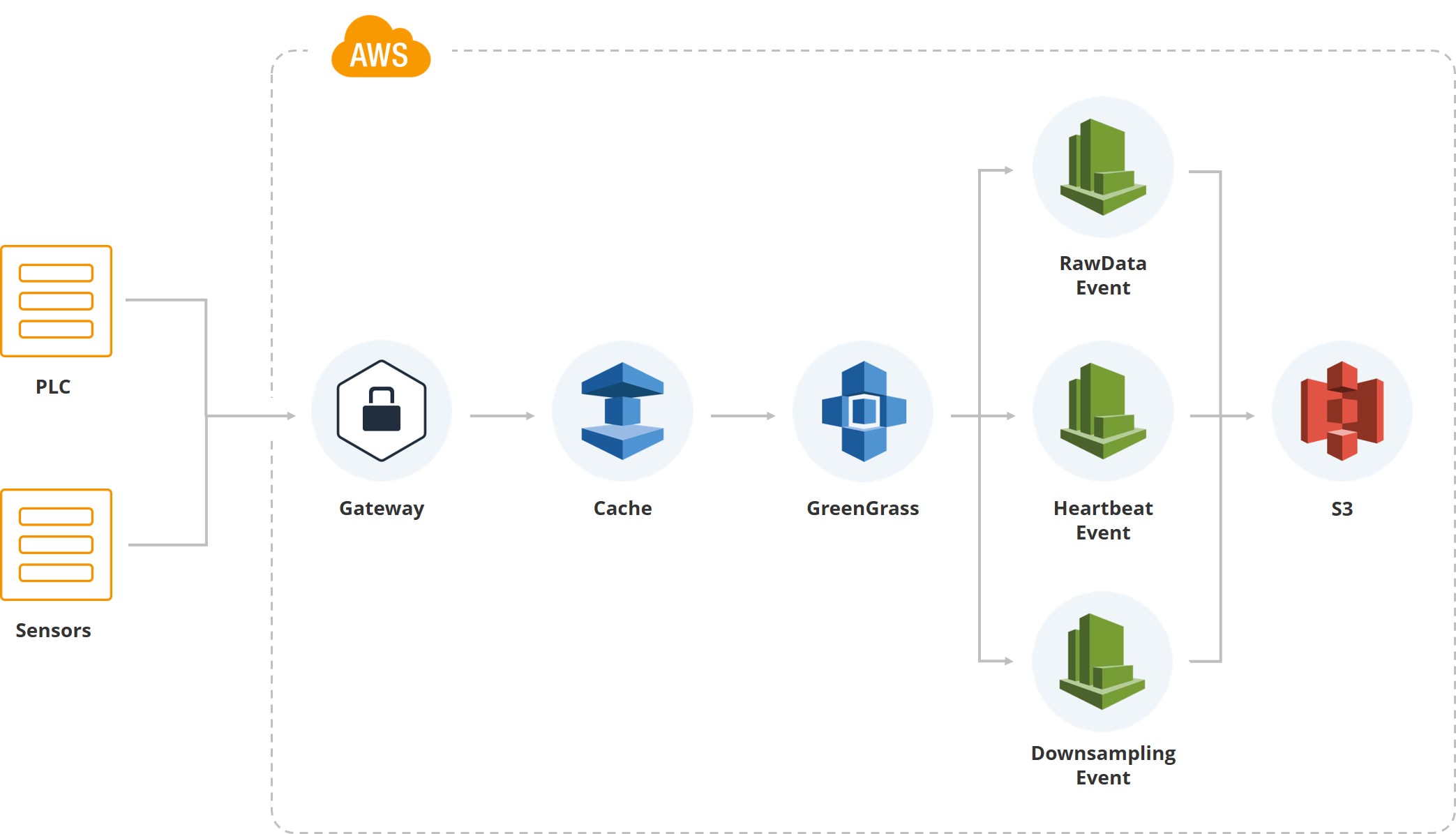
Esta ilustração mostra como os primeiros dados entraram no sistema. Temos um gateway, existem PLC e sensores associados a ele. Além disso, é claro, o cache - o equipamento geralmente roda em cartões móveis e todos os dados são transmitidos via Internet móvel. Como um dos centros de classificação do cliente está localizado em uma área onde geralmente há furacões e a conexão pode ser interrompida, acumulamos dados no gateway até que ele seja restaurado.
Em seguida, usamos o serviço Greengrass da Amazon, que envia dados dentro do sistema de nuvem (AWS).
Assim que os dados estão dentro da nuvem, vários eventos são acionados. Por exemplo, temos um evento para dados brutos que salva os dados do sistema de arquivos. Há um "batimento cardíaco" para indicar o desempenho normal do sistema. Há uma "redução de amostra", usada para exibição na interface do usuário e para processamento (o valor médio, por exemplo, por minuto para um determinado indicador) é obtido. Ou seja, além dos dados brutos, temos dados de amostragem reduzida que caem nas telas dos usuários que monitoram o sistema.
Os dados brutos são armazenados em formato parquet. No início, escolhemos o JSON, depois experimentamos o CSV, mas no final chegamos à conclusão de que a equipe de análise e a equipe de desenvolvimento estão satisfeitas com o "parquet".
Na verdade, a primeira versão do sistema foi criada no DynamoDB e não quero dizer nada de ruim sobre esse banco de dados. Só que, assim que obtivemos análises - matemáticos que deveriam trabalhar com os dados obtidos -, a linguagem de consulta no DynamoDB ficou muito complicada para eles. Eles tiveram que preparar dados especialmente para ML e análises. Portanto, decidimos pelo Athena, o editor de consultas da AWS. Para nós, suas vantagens são que ele permite ler dados do Parquet, escrever SQL e coletar os resultados em um arquivo CSV. Apenas o que a equipe de análise precisa.
Segunda etapa: o que analisamos?
Assim, a partir de um pequeno objeto, coletamos cerca de 3 GB de dados brutos. Agora sabemos muito sobre temperatura, vibração e aceleração axial. Portanto, é hora de nossos matemáticos se reunirem para entender como e, de fato, o que estamos tentando prever com base nessas informações.
O objetivo é minimizar o tempo de inatividade do equipamento. As pessoas entram nesta fábrica de Coca-Cola apenas quando recebem um sinal de avaria, vazamento de óleo ou, digamos, uma poça no chão. O custo de um robô começa com US $ 30.000, mas quase toda a produção é construída sobre eles
As pessoas entram nesta fábrica de Coca-Cola apenas quando recebem um sinal de avaria, vazamento de óleo ou, digamos, uma poça no chão. O custo de um robô começa com US $ 30.000, mas quase toda a produção é construída sobre eles Cerca de 10.000 pessoas trabalham em seis fábricas de Tesla e, para a produção dessa escala, isso é muito pouco. Curiosamente, as fábricas da Mercedes são ainda mais automatizadas. É claro que todos os robôs envolvidos precisam de monitoramento constante
Cerca de 10.000 pessoas trabalham em seis fábricas de Tesla e, para a produção dessa escala, isso é muito pouco. Curiosamente, as fábricas da Mercedes são ainda mais automatizadas. É claro que todos os robôs envolvidos precisam de monitoramento constanteQuanto mais caro o robô, menos sua parte de trabalho vibra. Com ações simples, isso pode não ser decisivo, mas operações mais sutis, digamos com o gargalo da garrafa, exigem que ela seja minimizada. Obviamente, o nível de vibração de carros caros deve ser constantemente monitorado.
Serviços que economizam tempo
Lançamos a primeira instalação em pouco mais de três meses e acho rápida.
 Na verdade, esses são os cinco principais pontos que permitiram economizar esforços de desenvolvimento
Na verdade, esses são os cinco principais pontos que permitiram economizar esforços de desenvolvimentoA primeira coisa que reduzimos o cronograma é que a maior parte do sistema é construída na AWS, que é dimensionada por si só. Assim que o número de usuários exceder um determinado limite, o dimensionamento automático é acionado e nenhuma equipe precisa gastar tempo com isso.
Gostaria de chamar a atenção para duas nuances. Primeiro, trabalhamos com grandes volumes de dados e, na primeira versão do sistema, tínhamos pipelines para fazer backups. Depois de algum tempo, os dados se tornaram demais e a manutenção de cópias para eles se tornou muito cara. Em seguida, deixamos os dados brutos no intervalo somente leitura, proibindo a exclusão deles e recusamos os backups.
Nosso sistema envolve integração contínua, para oferecer suporte a um novo site e uma nova instalação não leva muito tempo.
É claro que o tempo real se baseia em eventos. Embora, é claro, surjam dificuldades devido ao fato de alguns eventos funcionarem duas vezes ou o sistema perder contato, por exemplo, devido às condições climáticas.
A criptografia de dados, conforme exigido pelo cliente, é feita automaticamente na AWS. Cada cliente tem seu próprio bucket e não fazemos o que criptografamos.
Encontro com analistas
Recebemos o primeiro código em formato PDF, juntamente com uma solicitação para implementar um ou outro modelo. Até começarmos a receber o código na forma de .ipynb, era alarmante, mas o fato é que os analistas são matemáticos que estão longe de programar. Todas as nossas operações ocorrem na nuvem, não permitimos o download de dados. Juntos, todos esses pontos nos levaram a experimentar a plataforma SageMaker.
O SageMaker permite que você use cerca de 80 algoritmos prontos para uso, incluindo estruturas: Caffe2, Mxnet, Gluon, TensorFlow, Pytorch, kit de ferramentas cognitivas da Microsoft. No momento, usamos o Keras + TensorFlow, mas todos, exceto o kit de ferramentas cognitivas da Microsoft, tentaram. Uma cobertura tão ampla nos permite não limitar nossa própria equipe analítica.

Nos primeiros três a quatro meses, as pessoas fizeram todo o trabalho com a ajuda da matemática simples, realmente não havia ML. Parte do sistema é baseada em leis puramente matemáticas e foi projetada para dados estatísticos. Ou seja, monitoramos o nível médio de temperatura e, se percebermos que está fora de escala, os alertas são acionados.
Em seguida, segue o treinamento do modelo. Tudo parece fácil e simples e, portanto, parece antes do início da implementação.
Construir, treinar, implantar ...

Descreverei brevemente como saímos da situação. Veja a segunda coluna: coletamos dados, processamos, limpamos, usamos bucket S3 e Glue para iniciar eventos e criar "partições". Temos todos os dados organizados em partições para o Athena, essa também é uma nuance importante, porque o Athena é construído sobre o S3. Athena em si é muito barato. Mas pagamos pela leitura dos dados e pela saída do S3, pois cada solicitação pode ser muito cara. Portanto, temos um grande sistema de partições.
Temos um downtimer. E o Amazon EMR, que permite coletar dados rapidamente. Na verdade, para a engenharia de recursos, em nossa nuvem, para cada analista, um Notebook Jupyter foi criado - essa é a instância deles. E eles analisam tudo diretamente na própria nuvem.
Graças ao SageMaker, conseguimos pular a fase Clusters de treinamento. Se não usássemos essa plataforma, teríamos que criar clusters na Amazon e um dos engenheiros do DevOps teria que segui-los. O SageMaker permite usar os parâmetros do método, a imagem no Docker para aumentar o cluster, resta apenas indicar o número de instâncias no parâmetro que você deseja usar.
Além disso, não precisamos lidar com o dimensionamento. Se queremos processar algum tipo de algoritmo grande ou se precisamos calcular algo com urgência, ativamos o escalonamento automático (tudo depende se você deseja usar uma CPU ou GPU).
Além disso, todos os nossos modelos são criptografados: isso também sai da caixa no SageMaker - os binários que estão no S3.
Implantação do modelo
Estamos nos aproximando do primeiro modelo implantado em um ambiente. Na verdade, o SageMaker permite salvar artefatos de modelo, mas nesse estágio tivemos muita controvérsia, porque o SageMaker possui seu próprio formato de modelo. Queríamos nos afastar, nos livrando das restrições, para que nossos modelos sejam armazenados em formato de picles, para que pudéssemos usar até o Keras, até o TensorFlow ou qualquer outra coisa, se desejado. Embora tenhamos usado o primeiro modelo do SageMaker, como ele é, por meio da API nativa.
O SageMaker permite simplificar o trabalho em três etapas. Toda vez que você tenta prever algo, precisa iniciar um determinado processo, fornecer dados e obter valores de previsão. Tudo correu bem até que algoritmos personalizados foram necessários.

Os analistas sabem que possuem um IC e um repositório. Há uma pasta no repositório do IC em que eles devem colocar três arquivos. Serve.py é um arquivo que permite ao SageMaker aumentar o serviço Flask e se comunicar com o próprio SageMaker. Train.py é uma classe com o método train, na qual eles devem colocar tudo o que é necessário para o modelo. Finalmente, predict.py - com sua ajuda, eles aumentam essa classe, dentro da qual existe um método. Tendo acesso, eles levantam todos os tipos de recursos do S3 a partir daí - no SageMaker, temos uma imagem que permite executar qualquer coisa a partir da interface e programaticamente (não os limitamos).
No SageMaker, obtemos acesso a predict.py - a imagem interna é apenas um aplicativo Flask que permite ligar para prever ou treinar com determinados parâmetros. Tudo isso está ligado ao S3 e, além disso, eles têm a capacidade de salvar modelos do Notebook Jupyter. Ou seja, no Jupyter Notebook, os analistas têm acesso a todos os dados e podem fazer algum tipo de experimentação.
Na produção, tudo isso cai da seguinte maneira. Temos usuários, existem valores-limite previstos. Os dados estão no S3 e vão para o Athena. A cada duas horas, é lançado um algoritmo que calcula uma previsão para as próximas duas horas. Essa etapa do tempo se deve ao fato de que, no nosso caso, cerca de 6 horas de análise são suficientes para dizer que algo está errado com o motor. Mesmo no momento da ligação, o motor aquece de 5 a 10 minutos e não ocorrem saltos agudos.
Em sistemas críticos, digamos, quando a Air France verifica turbinas de aeronaves, a previsão é feita na taxa de 10 minutos. Nesse caso, a precisão é de 96,5%.
Se percebermos que algo está errado, o sistema de notificação será ativado. Em seguida, um dos muitos usuários em um relógio ou outro dispositivo recebe uma notificação de que um determinado motor está se comportando de maneira anormal. Ele vai e verifica sua condição.
Gerenciar instâncias do notebook
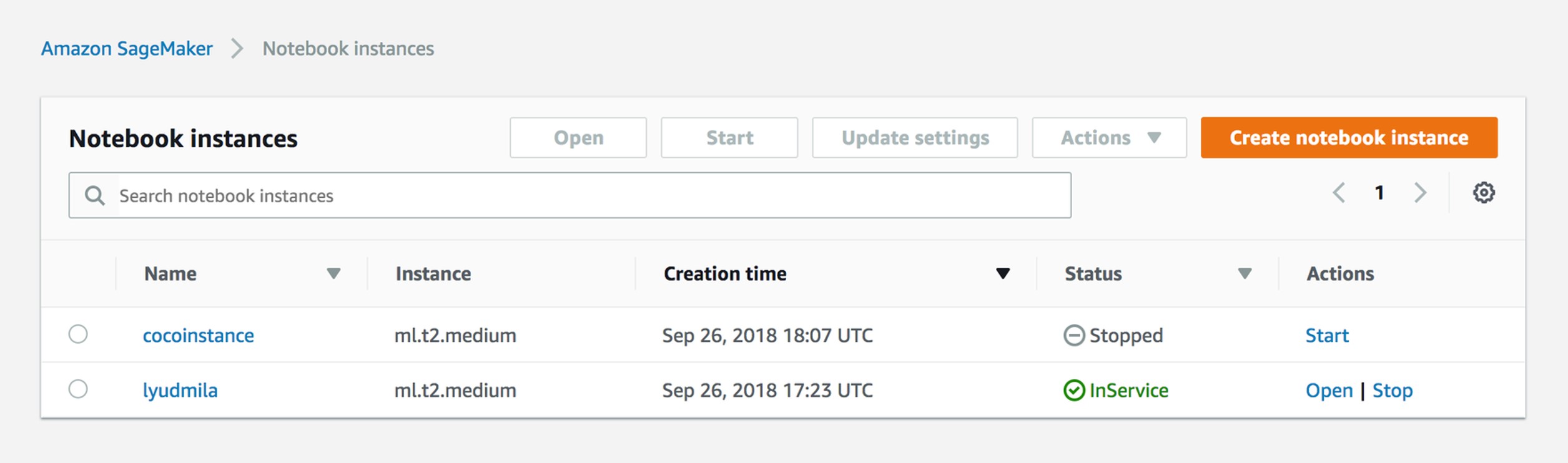
De fato, tudo é muito simples. Chegando ao trabalho, o analista lança uma instância no Jupyter Notebook. Ele recebe a função e a sessão, então duas pessoas não podem editar o mesmo arquivo. Na verdade, agora temos uma instância para cada analista.
Criar trabalho de treinamento
O SageMaker entende os trabalhos de treinamento. Seu resultado, se você usar apenas uma API - um binário armazenado no S3: a partir dos parâmetros fornecidos, seu modelo será obtido.
sagemaker = boto3.client('sagemaker') sagemaker.create_training_job(**create_training_params) status = sagemaker.describe_training_job(TrainingJobName=job_name)['TrainingJobStatus'] print(status) try: sagemaker.get_waiter('training_job_completed_or_stopped').wait(TrainingJobName=job_name) finally: status = sagemaker.describe_training_job(TrainingJobName=job_name)['TrainingJobStatus'] print("Training job ended with status: " + status) if status == 'Failed': message = sagemaker.describe_training_job(TrainingJobName=job_name)['FailureReason'] print('Training failed with the following error: {}'.format(message)) raise Exception('Training job failed')
Exemplo de Parâmetros de Treinamento
{ "AlgorithmSpecification": { "TrainingImage": image, "TrainingInputMode": "File" }, "RoleArn": role, "OutputDataConfig": { "S3OutputPath": output_location }, "ResourceConfig": { "InstanceCount": 2, "InstanceType": "ml.c4.8xlarge", "VolumeSizeInGB": 50 }, "TrainingJobName": job_name, "HyperParameters": { "k": "10", "feature_dim": "784", "mini_batch_size": "500", "force_dense": "True" }, "StoppingCondition": { "MaxRuntimeInSeconds": 60 * 60 }, "InputDataConfig": [ { "ChannelName": "train", "DataSource": { "S3DataSource": { "S3DataType": "S3Prefix", "S3Uri": data_location, "S3DataDistributionType": "FullyReplicated" } }, "CompressionType": "None", "RecordWrapperType": "None" } ] }
Parâmetros A primeira é a função: você deve indicar a que sua instância do SageMaker tem acesso. Ou seja, no nosso caso, se o analista trabalha com duas produções diferentes, ele deve ver um balde e não o outro. A configuração de saída é onde você salva todos os metadados do modelo.
Ignoramos a escala automática e podemos simplesmente especificar o número de instâncias nas quais você deseja executar este trabalho de treinamento. Inicialmente, geralmente usamos instâncias intermediárias sem TensorFlow ou Keras, e isso foi suficiente.
Hiperparâmetros Você especifica a imagem do Docker na qual deseja iniciar. Como regra, a Amazon fornece uma lista de algoritmos e suas imagens, ou seja, você deve especificar hiperparâmetros - os parâmetros do próprio algoritmo.
Criar modelo
%%time import boto3 from time import gmtime, strftime job_name = 'kmeans-lowlevel-' + strftime("%Y-%m-%d-%H-%M-%S", gmtime()) print("Training job", job_name) from sagemaker.amazon.amazon_estimator import get_image_uri image = get_image_uri(boto3.Session().region_name, 'kmeans') output_location = 's3://{}/kmeans_example/output'.format(bucket) print('training artifacts will be uploaded to: {}'.format(output_location)) create_training_params = \ { "AlgorithmSpecification": { "TrainingImage": image, "TrainingInputMode": "File" }, "RoleArn": role, "OutputDataConfig": { "S3OutputPath": output_location }, "ResourceConfig": { "InstanceCount": 2, "InstanceType": "ml.c4.8xlarge", "VolumeSizeInGB": 50 }, "TrainingJobName": job_name, "HyperParameters": { "k": "10", "feature_dim": "784", "mini_batch_size": "500", "force_dense": "True" }, "StoppingCondition": { "MaxRuntimeInSeconds": 60 * 60 }, "InputDataConfig": [ { "ChannelName": "train", "DataSource": { "S3DataSource": { "S3DataType": "S3Prefix", "S3Uri": data_location, "S3DataDistributionType": "FullyReplicated" } }, "CompressionType": "None", "RecordWrapperType": "None" } ] } sagemaker = boto3.client('sagemaker') sagemaker.create_training_job(**create_training_params) status = sagemaker.describe_training_job(TrainingJobName=job_name)['TrainingJobStatus'] print(status) try: sagemaker.get_waiter('training_job_completed_or_stopped').wait(TrainingJobName=job_name) finally: status = sagemaker.describe_training_job(TrainingJobName=job_name)['TrainingJobStatus'] print("Training job ended with status: " + status) if status == 'Failed': message = sagemaker.describe_training_job(TrainingJobName=job_name)['FailureReason'] print('Training failed with the following error: {}'.format(message)) raise Exception('Training job failed') %%time import boto3 from time import gmtime, strftime model_name=job_name print(model_name) info = sagemaker.describe_training_job(TrainingJobName=job_name) model_data = info['ModelArtifacts']['S3ModelArtifacts'] print(info['ModelArtifacts']) primary_container = { 'Image': image, 'ModelDataUrl': model_data } create_model_response = sagemaker.create_model( ModelName = model_name, ExecutionRoleArn = role, PrimaryContainer = primary_container) print(create_model_response['ModelArn'])
Criar um modelo é o resultado de um trabalho de treinamento. Depois que o último é concluído, e quando você o monitora, ele é salvo no S3 e você pode usá-lo.

É assim que parece do ponto de vista dos analistas. Nossos analistas vão aos modelos e dizem: nesta imagem, quero lançar esse modelo. Eles simplesmente apontam para a pasta S3, Imagem e inserem os parâmetros na interface gráfica. Como existem nuances e dificuldades, passamos a algoritmos personalizados.
Criar ponto final
%%time import time endpoint_name = 'KMeansEndpoint-' + strftime("%Y-%m-%d-%H-%M-%S", gmtime()) print(endpoint_name) create_endpoint_response = sagemaker.create_endpoint( EndpointName=endpoint_name, EndpointConfigName=endpoint_config_name) print(create_endpoint_response['EndpointArn']) resp = sagemaker.describe_endpoint(EndpointName=endpoint_name) status = resp['EndpointStatus'] print("Status: " + status) try: sagemaker.get_waiter('endpoint_in_service').wait(EndpointName=endpoint_name) finally: resp = sagemaker.describe_endpoint(EndpointName=endpoint_name) status = resp['EndpointStatus'] print("Arn: " + resp['EndpointArn']) print("Create endpoint ended with status: " + status) if status != 'InService': message = sagemaker.describe_endpoint(EndpointName=endpoint_name)['FailureReason'] print('Training failed with the following error: {}'.format(message)) raise Exception('Endpoint creation did not succeed')
É necessário muito código para criar um Endpoint que se contrai de qualquer lambda e de fora. A cada duas horas, é acionado um evento que puxa o Endpoint.
Visualização de ponto final

É assim que os analistas veem. Eles simplesmente indicam o algoritmo, o tempo e o puxam com as mãos da interface.
Chamar ponto final
import json payload = np2csv(train_set[0][30:31]) response = runtime.invoke_endpoint(EndpointName=endpoint_name, ContentType='text/csv', Body=payload) result = json.loads(response['Body'].read().decode()) print(result)
E é assim que é feito a partir de lambda. Ou seja, temos um endpoint interno e a cada duas horas enviamos uma carga útil para fazer uma previsão.
Links úteis para o SageMaker: links do github
Esses são links muito importantes. Honestamente, depois que começamos a usar a GUI habitual do Sagemaker, todos entenderam que mais cedo ou mais tarde chegaríamos a um algoritmo personalizado, e tudo isso seria montado manualmente. Usando esses links, você pode encontrar não apenas o uso de algoritmos, mas também a montagem de imagens personalizadas:
github.com/awslabs/amazon-sagemaker-examplesgithub.com/aws-samples/aws-ml-vision-end2endgithub.com/juliensimongithub.com/aws/sagemaker-sparkO que vem a seguir?
Abordamos a quarta produção e agora, além da análise, temos dois caminhos de desenvolvimento. Primeiramente, estamos tentando obter logs da mecânica, ou seja, estamos tentando começar o treinamento com suporte. Os primeiros registros de Mantainence que recebemos são assim: algo quebrou na segunda-feira, cheguei lá na quarta-feira e comecei a consertá-lo na sexta-feira. Agora, estamos tentando fornecer ao cliente o CMS - um sistema de gerenciamento de conteúdo que permitirá o registro de eventos de falha.
Como isso é feito? Como regra, assim que ocorre um colapso, o mecânico chega e muda a peça muito rapidamente, mas ele pode preencher todos os tipos de formulários em papel, digamos, em uma semana. A essa altura, a pessoa simplesmente esquece o que exatamente aconteceu com a parte. O CMS, é claro, nos leva a um novo nível de interação com a mecânica.
Em segundo lugar, vamos instalar sensores ultrassônicos nos motores que lêem som e estão envolvidos na análise espectral.
É possível que abandonemos o Athena, porque em big data, o uso do S3 é caro. Ao mesmo tempo, a Microsoft anunciou recentemente seus próprios serviços, e um de nossos clientes quer tentar fazer a mesma coisa no Azure. Na verdade, uma das vantagens do nosso sistema é que ele pode ser desmontado e montado em outro local, como cubos.